1213 lines
45 KiB
Markdown
1213 lines
45 KiB
Markdown
---
|
||
title: SQL语法基础知识总结
|
||
category: 数据库
|
||
tag:
|
||
- 数据库基础
|
||
- SQL
|
||
---
|
||
|
||
> 本文整理完善自下面这两份资料:
|
||
>
|
||
> - [SQL 语法速成手册](https://juejin.cn/post/6844903790571700231)
|
||
> - [MySQL 超全教程](https://www.begtut.com/mysql/mysql-tutorial.html)
|
||
|
||
## 基本概念
|
||
|
||
### 数据库术语
|
||
|
||
- `数据库(database)` - 保存有组织的数据的容器(通常是一个文件或一组文件)。
|
||
- `数据表(table)` - 某种特定类型数据的结构化清单。
|
||
- `模式(schema)` - 关于数据库和表的布局及特性的信息。模式定义了数据在表中如何存储,包含存储什么样的数据,数据如何分解,各部分信息如何命名等信息。数据库和表都有模式。
|
||
- `列(column)` - 表中的一个字段。所有表都是由一个或多个列组成的。
|
||
- `行(row)` - 表中的一个记录。
|
||
- `主键(primary key)` - 一列(或一组列),其值能够唯一标识表中每一行。
|
||
|
||
### SQL 语法
|
||
|
||
SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,从而称为 ANSI SQL。各个 DBMS 都有自己的实现,如 PL/SQL、Transact-SQL 等。
|
||
|
||
#### SQL 语法结构
|
||
|
||
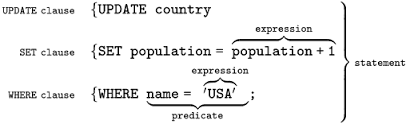
|
||
|
||
SQL 语法结构包括:
|
||
|
||
- **`子句`** - 是语句和查询的组成成分。(在某些情况下,这些都是可选的。)
|
||
- **`表达式`** - 可以产生任何标量值,或由列和行的数据库表
|
||
- **`谓词`** - 给需要评估的 SQL 三值逻辑(3VL)(true/false/unknown)或布尔真值指定条件,并限制语句和查询的效果,或改变程序流程。
|
||
- **`查询`** - 基于特定条件检索数据。这是 SQL 的一个重要组成部分。
|
||
- **`语句`** - 可以持久地影响纲要和数据,也可以控制数据库事务、程序流程、连接、会话或诊断。
|
||
|
||
#### SQL 语法要点
|
||
|
||
- **SQL 语句不区分大小写**,但是数据库表名、列名和值是否区分,依赖于具体的 DBMS 以及配置。例如:`SELECT` 与 `select`、`Select` 是相同的。
|
||
- **多条 SQL 语句必须以分号(`;`)分隔**。
|
||
- 处理 SQL 语句时,**所有空格都被忽略**。
|
||
|
||
SQL 语句可以写成一行,也可以分写为多行。
|
||
|
||
```sql
|
||
-- 一行 SQL 语句
|
||
|
||
UPDATE user SET username='robot', password='robot' WHERE username = 'root';
|
||
|
||
-- 多行 SQL 语句
|
||
UPDATE user
|
||
SET username='robot', password='robot'
|
||
WHERE username = 'root';
|
||
```
|
||
|
||
SQL 支持三种注释:
|
||
|
||
```sql
|
||
## 注释1
|
||
-- 注释2
|
||
/* 注释3 */
|
||
```
|
||
|
||
### SQL 分类
|
||
|
||
#### 数据定义语言(DDL)
|
||
|
||
数据定义语言(Data Definition Language,DDL)是 SQL 语言集中负责数据结构定义与数据库对象定义的语言。
|
||
|
||
DDL 的主要功能是**定义数据库对象**。
|
||
|
||
DDL 的核心指令是 `CREATE`、`ALTER`、`DROP`。
|
||
|
||
#### 数据操纵语言(DML)
|
||
|
||
数据操纵语言(Data Manipulation Language, DML)是用于数据库操作,对数据库其中的对象和数据运行访问工作的编程语句。
|
||
|
||
DML 的主要功能是 **访问数据**,因此其语法都是以**读写数据库**为主。
|
||
|
||
DML 的核心指令是 `INSERT`、`UPDATE`、`DELETE`、`SELECT`。这四个指令合称 CRUD(Create, Read, Update, Delete),即增删改查。
|
||
|
||
#### 事务控制语言(TCL)
|
||
|
||
事务控制语言 (Transaction Control Language, TCL) 用于**管理数据库中的事务**。这些用于管理由 DML 语句所做的更改。它还允许将语句分组为逻辑事务。
|
||
|
||
TCL 的核心指令是 `COMMIT`、`ROLLBACK`。
|
||
|
||
#### 数据控制语言(DCL)
|
||
|
||
数据控制语言 (Data Control Language, DCL) 是一种可对数据访问权进行控制的指令,它可以控制特定用户账户对数据表、查看表、预存程序、用户自定义函数等数据库对象的控制权。
|
||
|
||
DCL 的核心指令是 `GRANT`、`REVOKE`。
|
||
|
||
DCL 以**控制用户的访问权限**为主,因此其指令作法并不复杂,可利用 DCL 控制的权限有:`CONNECT`、`SELECT`、`INSERT`、`UPDATE`、`DELETE`、`EXECUTE`、`USAGE`、`REFERENCES`。
|
||
|
||
根据不同的 DBMS 以及不同的安全性实体,其支持的权限控制也有所不同。
|
||
|
||
**我们先来介绍 DML 语句用法。 DML 的主要功能是读写数据库实现增删改查。**
|
||
|
||
## 增删改查
|
||
|
||
增删改查,又称为 CRUD,数据库基本操作中的基本操作。
|
||
|
||
### 插入数据
|
||
|
||
`INSERT INTO` 语句用于向表中插入新记录。
|
||
|
||
**插入完整的行**
|
||
|
||
```sql
|
||
# 插入一行
|
||
INSERT INTO user
|
||
VALUES (10, 'root', 'root', 'xxxx@163.com');
|
||
# 插入多行
|
||
INSERT INTO user
|
||
VALUES (10, 'root', 'root', 'xxxx@163.com'), (12, 'user1', 'user1', 'xxxx@163.com'), (18, 'user2', 'user2', 'xxxx@163.com');
|
||
```
|
||
|
||
**插入行的一部分**
|
||
|
||
```sql
|
||
INSERT INTO user(username, password, email)
|
||
VALUES ('admin', 'admin', 'xxxx@163.com');
|
||
```
|
||
|
||
**插入查询出来的数据**
|
||
|
||
```sql
|
||
INSERT INTO user(username)
|
||
SELECT name
|
||
FROM account;
|
||
```
|
||
|
||
### 更新数据
|
||
|
||
`UPDATE` 语句用于更新表中的记录。
|
||
|
||
```sql
|
||
UPDATE user
|
||
SET username='robot', password='robot'
|
||
WHERE username = 'root';
|
||
```
|
||
|
||
### 删除数据
|
||
|
||
- `DELETE` 语句用于删除表中的记录。
|
||
- `TRUNCATE TABLE` 可以清空表,也就是删除所有行。
|
||
|
||
**删除表中的指定数据**
|
||
|
||
```sql
|
||
DELETE FROM user
|
||
WHERE username = 'robot';
|
||
```
|
||
|
||
**清空表中的数据**
|
||
|
||
```sql
|
||
TRUNCATE TABLE user;
|
||
```
|
||
|
||
### 查询数据
|
||
|
||
`SELECT` 语句用于从数据库中查询数据。
|
||
|
||
`DISTINCT` 用于返回唯一不同的值。它作用于所有列,也就是说所有列的值都相同才算相同。
|
||
|
||
`LIMIT` 限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。
|
||
|
||
- `ASC`:升序(默认)
|
||
- `DESC`:降序
|
||
|
||
**查询单列**
|
||
|
||
```sql
|
||
SELECT prod_name
|
||
FROM products;
|
||
```
|
||
|
||
**查询多列**
|
||
|
||
```sql
|
||
SELECT prod_id, prod_name, prod_price
|
||
FROM products;
|
||
```
|
||
|
||
**查询所有列**
|
||
|
||
```sql
|
||
SELECT *
|
||
FROM products;
|
||
```
|
||
|
||
**查询不同的值**
|
||
|
||
```sql
|
||
SELECT DISTINCT
|
||
vend_id FROM products;
|
||
```
|
||
|
||
**限制查询结果**
|
||
|
||
```sql
|
||
-- 返回前 5 行
|
||
SELECT * FROM mytable LIMIT 5;
|
||
SELECT * FROM mytable LIMIT 0, 5;
|
||
-- 返回第 3 ~ 5 行
|
||
SELECT * FROM mytable LIMIT 2, 3;
|
||
```
|
||
|
||
## 排序
|
||
|
||
`order by` 用于对结果集按照一个列或者多个列进行排序。默认按照升序对记录进行排序,如果需要按照降序对记录进行排序,可以使用 `desc` 关键字。
|
||
|
||
`order by` 对多列排序的时候,先排序的列放前面,后排序的列放后面。并且,不同的列可以有不同的排序规则。
|
||
|
||
```sql
|
||
SELECT * FROM products
|
||
ORDER BY prod_price DESC, prod_name ASC;
|
||
```
|
||
|
||
## 分组
|
||
|
||
**`group by`**:
|
||
|
||
- `group by` 子句将记录分组到汇总行中。
|
||
- `group by` 为每个组返回一个记录。
|
||
- `group by` 通常还涉及聚合`count`,`max`,`sum`,`avg` 等。
|
||
- `group by` 可以按一列或多列进行分组。
|
||
- `group by` 按分组字段进行排序后,`order by` 可以以汇总字段来进行排序。
|
||
|
||
**分组**
|
||
|
||
```sql
|
||
SELECT cust_name, COUNT(cust_address) AS addr_num
|
||
FROM Customers GROUP BY cust_name;
|
||
```
|
||
|
||
**分组后排序**
|
||
|
||
```sql
|
||
SELECT cust_name, COUNT(cust_address) AS addr_num
|
||
FROM Customers GROUP BY cust_name
|
||
ORDER BY cust_name DESC;
|
||
```
|
||
|
||
**`having`**:
|
||
|
||
- `having` 用于对汇总的 `group by` 结果进行过滤。
|
||
- `having` 一般都是和 `group by` 连用。
|
||
- `where` 和 `having` 可以在相同的查询中。
|
||
|
||
**使用 WHERE 和 HAVING 过滤数据**
|
||
|
||
```sql
|
||
SELECT cust_name, COUNT(*) AS num
|
||
FROM Customers
|
||
WHERE cust_email IS NOT NULL
|
||
GROUP BY cust_name
|
||
HAVING COUNT(*) >= 1;
|
||
```
|
||
|
||
**`having` vs `where`**:
|
||
|
||
- `where`:过滤过滤指定的行,后面不能加聚合函数(分组函数)。`where` 在`group by` 前。
|
||
- `having`:过滤分组,一般都是和 `group by` 连用,不能单独使用。`having` 在 `group by` 之后。
|
||
|
||
## 子查询
|
||
|
||
子查询是嵌套在较大查询中的 SQL 查询,也称内部查询或内部选择,包含子查询的语句也称为外部查询或外部选择。简单来说,子查询就是指将一个 `select` 查询(子查询)的结果作为另一个 SQL 语句(主查询)的数据来源或者判断条件。
|
||
|
||
子查询可以嵌入 `SELECT`、`INSERT`、`UPDATE` 和 `DELETE` 语句中,也可以和 `=`、`<`、`>`、`IN`、`BETWEEN`、`EXISTS` 等运算符一起使用。
|
||
|
||
子查询常用在 `WHERE` 子句和 `FROM` 子句后边:
|
||
|
||
- 当用于 `WHERE` 子句时,根据不同的运算符,子查询可以返回单行单列、多行单列、单行多列数据。子查询就是要返回能够作为 `WHERE` 子句查询条件的值。
|
||
- 当用于 `FROM` 子句时,一般返回多行多列数据,相当于返回一张临时表,这样才符合 `FROM` 后面是表的规则。这种做法能够实现多表联合查询。
|
||
|
||
> 注意:MYSQL 数据库从 4.1 版本才开始支持子查询,早期版本是不支持的。
|
||
|
||
用于 `WHERE` 子句的子查询的基本语法如下:
|
||
|
||
```sql
|
||
select column_name [, column_name ]
|
||
from table1 [, table2 ]
|
||
where column_name operator
|
||
(select column_name [, column_name ]
|
||
from table1 [, table2 ]
|
||
[where])
|
||
```
|
||
|
||
- 子查询需要放在括号`( )`内。
|
||
- `operator` 表示用于 where 子句的运算符。
|
||
|
||
用于 `FROM` 子句的子查询的基本语法如下:
|
||
|
||
```sql
|
||
select column_name [, column_name ]
|
||
from (select column_name [, column_name ]
|
||
from table1 [, table2 ]
|
||
[where]) as temp_table_name
|
||
where condition
|
||
```
|
||
|
||
用于 `FROM` 的子查询返回的结果相当于一张临时表,所以需要使用 AS 关键字为该临时表起一个名字。
|
||
|
||
**子查询的子查询**
|
||
|
||
```sql
|
||
SELECT cust_name, cust_contact
|
||
FROM customers
|
||
WHERE cust_id IN (SELECT cust_id
|
||
FROM orders
|
||
WHERE order_num IN (SELECT order_num
|
||
FROM orderitems
|
||
WHERE prod_id = 'RGAN01'));
|
||
```
|
||
|
||
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
|
||
|
||
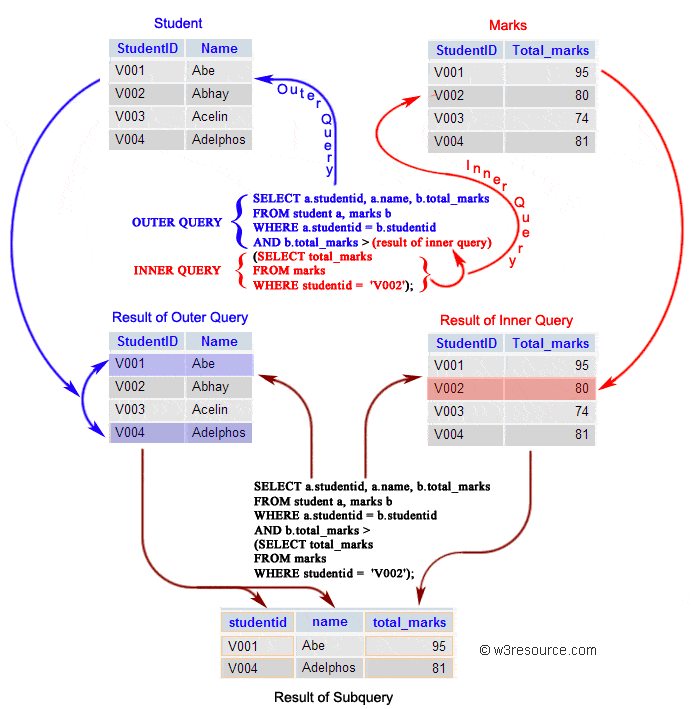
|
||
|
||
### WHERE
|
||
|
||
- `WHERE` 子句用于过滤记录,即缩小访问数据的范围。
|
||
- `WHERE` 后跟一个返回 `true` 或 `false` 的条件。
|
||
- `WHERE` 可以与 `SELECT`,`UPDATE` 和 `DELETE` 一起使用。
|
||
- 可以在 `WHERE` 子句中使用的操作符。
|
||
|
||
| 运算符 | 描述 |
|
||
| ------- | ------------------------------------------------------ |
|
||
| = | 等于 |
|
||
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
|
||
| > | 大于 |
|
||
| < | 小于 |
|
||
| >= | 大于等于 |
|
||
| <= | 小于等于 |
|
||
| BETWEEN | 在某个范围内 |
|
||
| LIKE | 搜索某种模式 |
|
||
| IN | 指定针对某个列的多个可能值 |
|
||
|
||
**`SELECT` 语句中的 `WHERE` 子句**
|
||
|
||
```ini
|
||
SELECT * FROM Customers
|
||
WHERE cust_name = 'Kids Place';
|
||
```
|
||
|
||
**`UPDATE` 语句中的 `WHERE` 子句**
|
||
|
||
```ini
|
||
UPDATE Customers
|
||
SET cust_name = 'Jack Jones'
|
||
WHERE cust_name = 'Kids Place';
|
||
```
|
||
|
||
**`DELETE` 语句中的 `WHERE` 子句**
|
||
|
||
```ini
|
||
DELETE FROM Customers
|
||
WHERE cust_name = 'Kids Place';
|
||
```
|
||
|
||
### IN 和 BETWEEN
|
||
|
||
- `IN` 操作符在 `WHERE` 子句中使用,作用是在指定的几个特定值中任选一个值。
|
||
- `BETWEEN` 操作符在 `WHERE` 子句中使用,作用是选取介于某个范围内的值。
|
||
|
||
**IN 示例**
|
||
|
||
```sql
|
||
SELECT *
|
||
FROM products
|
||
WHERE vend_id IN ('DLL01', 'BRS01');
|
||
```
|
||
|
||
**BETWEEN 示例**
|
||
|
||
```sql
|
||
SELECT *
|
||
FROM products
|
||
WHERE prod_price BETWEEN 3 AND 5;
|
||
```
|
||
|
||
### AND、OR、NOT
|
||
|
||
- `AND`、`OR`、`NOT` 是用于对过滤条件的逻辑处理指令。
|
||
- `AND` 优先级高于 `OR`,为了明确处理顺序,可以使用 `()`。
|
||
- `AND` 操作符表示左右条件都要满足。
|
||
- `OR` 操作符表示左右条件满足任意一个即可。
|
||
- `NOT` 操作符用于否定一个条件。
|
||
|
||
**AND 示例**
|
||
|
||
```ini
|
||
SELECT prod_id, prod_name, prod_price
|
||
FROM products
|
||
WHERE vend_id = 'DLL01' AND prod_price <= 4;
|
||
```
|
||
|
||
**OR 示例**
|
||
|
||
```ini
|
||
SELECT prod_id, prod_name, prod_price
|
||
FROM products
|
||
WHERE vend_id = 'DLL01' OR vend_id = 'BRS01';
|
||
```
|
||
|
||
**NOT 示例**
|
||
|
||
```sql
|
||
SELECT *
|
||
FROM products
|
||
WHERE prod_price NOT BETWEEN 3 AND 5;
|
||
```
|
||
|
||
### LIKE
|
||
|
||
- `LIKE` 操作符在 `WHERE` 子句中使用,作用是确定字符串是否匹配模式。
|
||
- 只有字段是文本值时才使用 `LIKE`。
|
||
- `LIKE` 支持两个通配符匹配选项:`%` 和 `_`。
|
||
- 不要滥用通配符,通配符位于开头处匹配会非常慢。
|
||
- `%` 表示任何字符出现任意次数。
|
||
- `_` 表示任何字符出现一次。
|
||
|
||
**% 示例**
|
||
|
||
```sql
|
||
SELECT prod_id, prod_name, prod_price
|
||
FROM products
|
||
WHERE prod_name LIKE '%bean bag%';
|
||
```
|
||
|
||
**\_ 示例**
|
||
|
||
```sql
|
||
SELECT prod_id, prod_name, prod_price
|
||
FROM products
|
||
WHERE prod_name LIKE '__ inch teddy bear';
|
||
```
|
||
|
||
## 连接
|
||
|
||
JOIN 是“连接”的意思,顾名思义,SQL JOIN 子句用于将两个或者多个表联合起来进行查询。
|
||
|
||
连接表时需要在每个表中选择一个字段,并对这些字段的值进行比较,值相同的两条记录将合并为一条。**连接表的本质就是将不同表的记录合并起来,形成一张新表。当然,这张新表只是临时的,它仅存在于本次查询期间**。
|
||
|
||
使用 `JOIN` 连接两个表的基本语法如下:
|
||
|
||
```sql
|
||
select table1.column1, table2.column2...
|
||
from table1
|
||
join table2
|
||
on table1.common_column1 = table2.common_column2;
|
||
```
|
||
|
||
`table1.common_column1 = table2.common_column2` 是连接条件,只有满足此条件的记录才会合并为一行。您可以使用多个运算符来连接表,例如 =、>、<、<>、<=、>=、!=、`between`、`like` 或者 `not`,但是最常见的是使用 =。
|
||
|
||
当两个表中有同名的字段时,为了帮助数据库引擎区分是哪个表的字段,在书写同名字段名时需要加上表名。当然,如果书写的字段名在两个表中是唯一的,也可以不使用以上格式,只写字段名即可。
|
||
|
||
另外,如果两张表的关联字段名相同,也可以使用 `USING`子句来代替 `ON`,举个例子:
|
||
|
||
```sql
|
||
# join....on
|
||
select c.cust_name, o.order_num
|
||
from Customers c
|
||
inner join Orders o
|
||
on c.cust_id = o.cust_id
|
||
order by c.cust_name;
|
||
|
||
# 如果两张表的关联字段名相同,也可以使用USING子句:join....using()
|
||
select c.cust_name, o.order_num
|
||
from Customers c
|
||
inner join Orders o
|
||
using(cust_id)
|
||
order by c.cust_name;
|
||
```
|
||
|
||
**`ON` 和 `WHERE` 的区别**:
|
||
|
||
- 连接表时,SQL 会根据连接条件生成一张新的临时表。`ON` 就是连接条件,它决定临时表的生成。
|
||
- `WHERE` 是在临时表生成以后,再对临时表中的数据进行过滤,生成最终的结果集,这个时候已经没有 JOIN-ON 了。
|
||
|
||
所以总结来说就是:**SQL 先根据 ON 生成一张临时表,然后再根据 WHERE 对临时表进行筛选**。
|
||
|
||
SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不同类型的连接,如下表所示:
|
||
|
||
| 连接类型 | 说明 |
|
||
| ---------------------------------------- | --------------------------------------------------------------------------------------------- |
|
||
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
|
||
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
|
||
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
|
||
| FULL JOIN / FULL OUTER JOIN 全(外)连接 | 只要其中有一个表存在满足条件的记录,就返回行。 |
|
||
| SELF JOIN | 将一个表连接到自身,就像该表是两个表一样。为了区分两个表,在 SQL 语句中需要至少重命名一个表。 |
|
||
| CROSS JOIN | 交叉连接,从两个或者多个连接表中返回记录集的笛卡尔积。 |
|
||
|
||
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
|
||
|
||
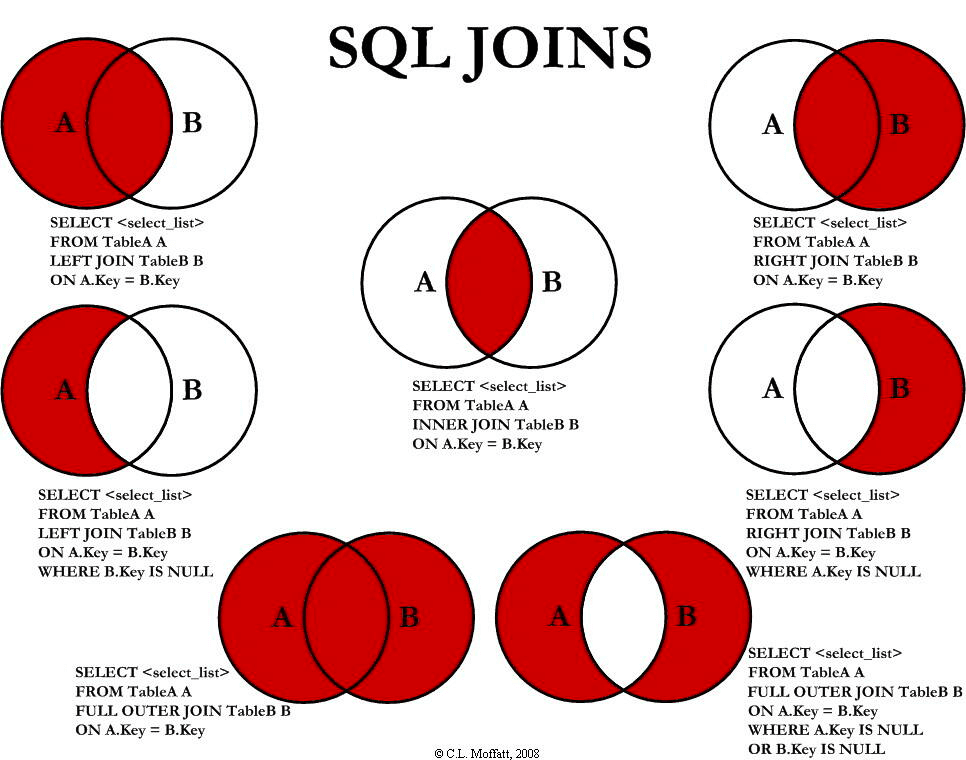
|
||
|
||
如果不加任何修饰词,只写 `JOIN`,那么默认为 `INNER JOIN`
|
||
|
||
对于 `INNER JOIN` 来说,还有一种隐式的写法,称为 “**隐式内连接**”,也就是没有 `INNER JOIN` 关键字,使用 `WHERE` 语句实现内连接的功能
|
||
|
||
```sql
|
||
# 隐式内连接
|
||
select c.cust_name, o.order_num
|
||
from Customers c, Orders o
|
||
where c.cust_id = o.cust_id
|
||
order by c.cust_name;
|
||
|
||
# 显式内连接
|
||
select c.cust_name, o.order_num
|
||
from Customers c inner join Orders o
|
||
using(cust_id)
|
||
order by c.cust_name;
|
||
```
|
||
|
||
## 组合
|
||
|
||
`UNION` 运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自 `UNION` 中参与查询的提取行。
|
||
|
||
`UNION` 基本规则:
|
||
|
||
- 所有查询的列数和列顺序必须相同。
|
||
- 每个查询中涉及表的列的数据类型必须相同或兼容。
|
||
- 通常返回的列名取自第一个查询。
|
||
|
||
默认地,`UNION` 操作符选取不同的值。如果允许重复的值,请使用 `UNION ALL`。
|
||
|
||
```sql
|
||
SELECT column_name(s) FROM table1
|
||
UNION ALL
|
||
SELECT column_name(s) FROM table2;
|
||
```
|
||
|
||
`UNION` 结果集中的列名总是等于 `UNION` 中第一个 `SELECT` 语句中的列名。
|
||
|
||
`JOIN` vs `UNION`:
|
||
|
||
- `JOIN` 中连接表的列可能不同,但在 `UNION` 中,所有查询的列数和列顺序必须相同。
|
||
- `UNION` 将查询之后的行放在一起(垂直放置),但 `JOIN` 将查询之后的列放在一起(水平放置),即它构成一个笛卡尔积。
|
||
|
||
## 函数
|
||
|
||
不同数据库的函数往往各不相同,因此不可移植。本节主要以 MySQL 的函数为例。
|
||
|
||
### 文本处理
|
||
|
||
| 函数 | 说明 |
|
||
| -------------------- | ---------------------- |
|
||
| `LEFT()`、`RIGHT()` | 左边或者右边的字符 |
|
||
| `LOWER()`、`UPPER()` | 转换为小写或者大写 |
|
||
| `LTRIM()`、`RTRIM()` | 去除左边或者右边的空格 |
|
||
| `LENGTH()` | 长度,以字节为单位 |
|
||
| `SOUNDEX()` | 转换为语音值 |
|
||
|
||
其中, **`SOUNDEX()`** 可以将一个字符串转换为描述其语音表示的字母数字模式。
|
||
|
||
```sql
|
||
SELECT *
|
||
FROM mytable
|
||
WHERE SOUNDEX(col1) = SOUNDEX('apple')
|
||
```
|
||
|
||
### 日期和时间处理
|
||
|
||
- 日期格式:`YYYY-MM-DD`
|
||
- 时间格式:`HH:MM:SS`
|
||
|
||
| 函 数 | 说 明 |
|
||
| --------------- | ------------------------------ |
|
||
| `AddDate()` | 增加一个日期(天、周等) |
|
||
| `AddTime()` | 增加一个时间(时、分等) |
|
||
| `CurDate()` | 返回当前日期 |
|
||
| `CurTime()` | 返回当前时间 |
|
||
| `Date()` | 返回日期时间的日期部分 |
|
||
| `DateDiff()` | 计算两个日期之差 |
|
||
| `Date_Add()` | 高度灵活的日期运算函数 |
|
||
| `Date_Format()` | 返回一个格式化的日期或时间串 |
|
||
| `Day()` | 返回一个日期的天数部分 |
|
||
| `DayOfWeek()` | 对于一个日期,返回对应的星期几 |
|
||
| `Hour()` | 返回一个时间的小时部分 |
|
||
| `Minute()` | 返回一个时间的分钟部分 |
|
||
| `Month()` | 返回一个日期的月份部分 |
|
||
| `Now()` | 返回当前日期和时间 |
|
||
| `Second()` | 返回一个时间的秒部分 |
|
||
| `Time()` | 返回一个日期时间的时间部分 |
|
||
| `Year()` | 返回一个日期的年份部分 |
|
||
|
||
### 数值处理
|
||
|
||
| 函数 | 说明 |
|
||
| ------ | ------ |
|
||
| SIN() | 正弦 |
|
||
| COS() | 余弦 |
|
||
| TAN() | 正切 |
|
||
| ABS() | 绝对值 |
|
||
| SQRT() | 平方根 |
|
||
| MOD() | 余数 |
|
||
| EXP() | 指数 |
|
||
| PI() | 圆周率 |
|
||
| RAND() | 随机数 |
|
||
|
||
### 汇总
|
||
|
||
| 函 数 | 说 明 |
|
||
| --------- | ---------------- |
|
||
| `AVG()` | 返回某列的平均值 |
|
||
| `COUNT()` | 返回某列的行数 |
|
||
| `MAX()` | 返回某列的最大值 |
|
||
| `MIN()` | 返回某列的最小值 |
|
||
| `SUM()` | 返回某列值之和 |
|
||
|
||
`AVG()` 会忽略 NULL 行。
|
||
|
||
使用 `DISTINCT` 可以让汇总函数值汇总不同的值。
|
||
|
||
```sql
|
||
SELECT AVG(DISTINCT col1) AS avg_col
|
||
FROM mytable
|
||
```
|
||
|
||
**接下来,我们来介绍 DDL 语句用法。DDL 的主要功能是定义数据库对象(如:数据库、数据表、视图、索引等)**
|
||
|
||
## 数据定义
|
||
|
||
### 数据库(DATABASE)
|
||
|
||
#### 创建数据库
|
||
|
||
```sql
|
||
CREATE DATABASE test;
|
||
```
|
||
|
||
#### 删除数据库
|
||
|
||
```sql
|
||
DROP DATABASE test;
|
||
```
|
||
|
||
#### 选择数据库
|
||
|
||
```sql
|
||
USE test;
|
||
```
|
||
|
||
### 数据表(TABLE)
|
||
|
||
#### 创建数据表
|
||
|
||
**普通创建**
|
||
|
||
```sql
|
||
CREATE TABLE user (
|
||
id int(10) unsigned NOT NULL COMMENT 'Id',
|
||
username varchar(64) NOT NULL DEFAULT 'default' COMMENT '用户名',
|
||
password varchar(64) NOT NULL DEFAULT 'default' COMMENT '密码',
|
||
email varchar(64) NOT NULL DEFAULT 'default' COMMENT '邮箱'
|
||
) COMMENT='用户表';
|
||
```
|
||
|
||
**根据已有的表创建新表**
|
||
|
||
```sql
|
||
CREATE TABLE vip_user AS
|
||
SELECT * FROM user;
|
||
```
|
||
|
||
#### 删除数据表
|
||
|
||
```sql
|
||
DROP TABLE user;
|
||
```
|
||
|
||
#### 修改数据表
|
||
|
||
**添加列**
|
||
|
||
```sql
|
||
ALTER TABLE user
|
||
ADD age int(3);
|
||
```
|
||
|
||
**删除列**
|
||
|
||
```sql
|
||
ALTER TABLE user
|
||
DROP COLUMN age;
|
||
```
|
||
|
||
**修改列**
|
||
|
||
```sql
|
||
ALTER TABLE `user`
|
||
MODIFY COLUMN age tinyint;
|
||
```
|
||
|
||
**添加主键**
|
||
|
||
```sql
|
||
ALTER TABLE user
|
||
ADD PRIMARY KEY (id);
|
||
```
|
||
|
||
**删除主键**
|
||
|
||
```sql
|
||
ALTER TABLE user
|
||
DROP PRIMARY KEY;
|
||
```
|
||
|
||
### 视图(VIEW)
|
||
|
||
定义:
|
||
|
||
- 视图是基于 SQL 语句的结果集的可视化的表。
|
||
- 视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。对视图的操作和对普通表的操作一样。
|
||
|
||
作用:
|
||
|
||
- 简化复杂的 SQL 操作,比如复杂的联结;
|
||
- 只使用实际表的一部分数据;
|
||
- 通过只给用户访问视图的权限,保证数据的安全性;
|
||
- 更改数据格式和表示。
|
||
|
||
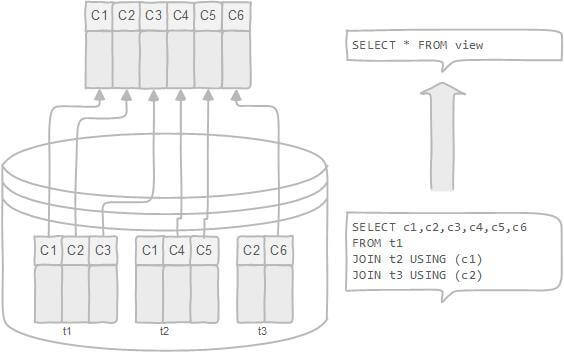
|
||
|
||
#### 创建视图
|
||
|
||
```sql
|
||
CREATE VIEW top_10_user_view AS
|
||
SELECT id, username
|
||
FROM user
|
||
WHERE id < 10;
|
||
```
|
||
|
||
#### 删除视图
|
||
|
||
```sql
|
||
DROP VIEW top_10_user_view;
|
||
```
|
||
|
||
### 索引(INDEX)
|
||
|
||
**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
|
||
|
||
索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
|
||
|
||
**优点**:
|
||
|
||
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
|
||
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
|
||
|
||
**缺点**:
|
||
|
||
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
|
||
- 索引需要使用物理文件存储,也会耗费一定空间。
|
||
|
||
但是,**使用索引一定能提高查询性能吗?**
|
||
|
||
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
|
||
|
||
关于索引的详细介绍,请看我写的 [MySQL 索引详解](https://javaguide.cn/database/mysql/mysql-index.html) 这篇文章。
|
||
|
||
#### 创建索引
|
||
|
||
```sql
|
||
CREATE INDEX user_index
|
||
ON user (id);
|
||
```
|
||
|
||
#### 添加索引
|
||
|
||
```sql
|
||
ALTER table user ADD INDEX user_index(id)
|
||
```
|
||
|
||
#### 创建唯一索引
|
||
|
||
```sql
|
||
CREATE UNIQUE INDEX user_index
|
||
ON user (id);
|
||
```
|
||
|
||
#### 删除索引
|
||
|
||
```sql
|
||
ALTER TABLE user
|
||
DROP INDEX user_index;
|
||
```
|
||
|
||
### 约束
|
||
|
||
SQL 约束用于规定表中的数据规则。
|
||
|
||
如果存在违反约束的数据行为,行为会被约束终止。
|
||
|
||
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
|
||
|
||
约束类型:
|
||
|
||
- `NOT NULL` - 指示某列不能存储 NULL 值。
|
||
- `UNIQUE` - 保证某列的每行必须有唯一的值。
|
||
- `PRIMARY KEY` - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
|
||
- `FOREIGN KEY` - 保证一个表中的数据匹配另一个表中的值的参照完整性。
|
||
- `CHECK` - 保证列中的值符合指定的条件。
|
||
- `DEFAULT` - 规定没有给列赋值时的默认值。
|
||
|
||
创建表时使用约束条件:
|
||
|
||
```sql
|
||
CREATE TABLE Users (
|
||
Id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增Id',
|
||
Username VARCHAR(64) NOT NULL UNIQUE DEFAULT 'default' COMMENT '用户名',
|
||
Password VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT '密码',
|
||
Email VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT '邮箱地址',
|
||
Enabled TINYINT(4) DEFAULT NULL COMMENT '是否有效',
|
||
PRIMARY KEY (Id)
|
||
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
|
||
```
|
||
|
||
**接下来,我们来介绍 TCL 语句用法。TCL 的主要功能是管理数据库中的事务。**
|
||
|
||
## 事务处理
|
||
|
||
不能回退 `SELECT` 语句,回退 `SELECT` 语句也没意义;也不能回退 `CREATE` 和 `DROP` 语句。
|
||
|
||
**MySQL 默认是隐式提交**,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 `START TRANSACTION` 语句时,会关闭隐式提交;当 `COMMIT` 或 `ROLLBACK` 语句执行后,事务会自动关闭,重新恢复隐式提交。
|
||
|
||
通过 `set autocommit=0` 可以取消自动提交,直到 `set autocommit=1` 才会提交;`autocommit` 标记是针对每个连接而不是针对服务器的。
|
||
|
||
指令:
|
||
|
||
- `START TRANSACTION` - 指令用于标记事务的起始点。
|
||
- `SAVEPOINT` - 指令用于创建保留点。
|
||
- `ROLLBACK TO` - 指令用于回滚到指定的保留点;如果没有设置保留点,则回退到 `START TRANSACTION` 语句处。
|
||
- `COMMIT` - 提交事务。
|
||
|
||
```sql
|
||
-- 开始事务
|
||
START TRANSACTION;
|
||
|
||
-- 插入操作 A
|
||
INSERT INTO `user`
|
||
VALUES (1, 'root1', 'root1', 'xxxx@163.com');
|
||
|
||
-- 创建保留点 updateA
|
||
SAVEPOINT updateA;
|
||
|
||
-- 插入操作 B
|
||
INSERT INTO `user`
|
||
VALUES (2, 'root2', 'root2', 'xxxx@163.com');
|
||
|
||
-- 回滚到保留点 updateA
|
||
ROLLBACK TO updateA;
|
||
|
||
-- 提交事务,只有操作 A 生效
|
||
COMMIT;
|
||
```
|
||
|
||
**接下来,我们来介绍 DCL 语句用法。DCL 的主要功能是控制用户的访问权限。**
|
||
|
||
## 权限控制
|
||
|
||
要授予用户帐户权限,可以用`GRANT`命令。要撤销用户的权限,可以用`REVOKE`命令。这里以 MySQL 为例,介绍权限控制实际应用。
|
||
|
||
`GRANT`授予权限语法:
|
||
|
||
```sql
|
||
GRANT privilege,[privilege],.. ON privilege_level
|
||
TO user [IDENTIFIED BY password]
|
||
[REQUIRE tsl_option]
|
||
[WITH [GRANT_OPTION | resource_option]];
|
||
```
|
||
|
||
简单解释一下:
|
||
|
||
1. 在`GRANT`关键字后指定一个或多个权限。如果授予用户多个权限,则每个权限由逗号分隔。
|
||
2. `ON privilege_level` 确定权限应用级别。MySQL 支持 global(`*.*`),database(`database.*`),table(`database.table`)和列级别。如果使用列权限级别,则必须在每个权限之后指定一个或逗号分隔列的列表。
|
||
3. `user` 是要授予权限的用户。如果用户已存在,则`GRANT`语句将修改其权限。否则,`GRANT`语句将创建一个新用户。可选子句`IDENTIFIED BY`允许您为用户设置新的密码。
|
||
4. `REQUIRE tsl_option`指定用户是否必须通过 SSL,X059 等安全连接连接到数据库服务器。
|
||
5. 可选 `WITH GRANT OPTION` 子句允许您授予其他用户或从其他用户中删除您拥有的权限。此外,您可以使用`WITH`子句分配 MySQL 数据库服务器的资源,例如,设置用户每小时可以使用的连接数或语句数。这在 MySQL 共享托管等共享环境中非常有用。
|
||
|
||
`REVOKE` 撤销权限语法:
|
||
|
||
```sql
|
||
REVOKE privilege_type [(column_list)]
|
||
[, priv_type [(column_list)]]...
|
||
ON [object_type] privilege_level
|
||
FROM user [, user]...
|
||
```
|
||
|
||
简单解释一下:
|
||
|
||
1. 在 `REVOKE` 关键字后面指定要从用户撤消的权限列表。您需要用逗号分隔权限。
|
||
2. 指定在 `ON` 子句中撤销特权的特权级别。
|
||
3. 指定要撤消 `FROM` 子句中的权限的用户帐户。
|
||
|
||
`GRANT` 和 `REVOKE` 可在几个层次上控制访问权限:
|
||
|
||
- 整个服务器,使用 `GRANT ALL` 和 `REVOKE ALL`;
|
||
- 整个数据库,使用 `ON database.*`;
|
||
- 特定的表,使用 `ON database.table`;
|
||
- 特定的列;
|
||
- 特定的存储过程。
|
||
|
||
新创建的账户没有任何权限。账户用 `username@host` 的形式定义,`username@%` 使用的是默认主机名。MySQL 的账户信息保存在 mysql 这个数据库中。
|
||
|
||
```sql
|
||
USE mysql;
|
||
SELECT user FROM user;
|
||
```
|
||
|
||
下表说明了可用于`GRANT`和`REVOKE`语句的所有允许权限:
|
||
|
||
| **特权** | **说明** | **级别** | | | | | |
|
||
| ----------------------- | ------------------------------------------------------------------------------------------------------- | -------- | ------ | -------- | -------- | --- | --- |
|
||
| **全局** | 数据库 | **表** | **列** | **程序** | **代理** | | |
|
||
| ALL [PRIVILEGES] | 授予除 GRANT OPTION 之外的指定访问级别的所有权限 | | | | | | |
|
||
| ALTER | 允许用户使用 ALTER TABLE 语句 | X | X | X | | | |
|
||
| ALTER ROUTINE | 允许用户更改或删除存储的例程 | X | X | | | X | |
|
||
| CREATE | 允许用户创建数据库和表 | X | X | X | | | |
|
||
| CREATE ROUTINE | 允许用户创建存储的例程 | X | X | | | | |
|
||
| CREATE TABLESPACE | 允许用户创建,更改或删除表空间和日志文件组 | X | | | | | |
|
||
| CREATE TEMPORARY TABLES | 允许用户使用 CREATE TEMPORARY TABLE 创建临时表 | X | X | | | | |
|
||
| CREATE USER | 允许用户使用 CREATE USER,DROP USER,RENAME USER 和 REVOKE ALL PRIVILEGES 语句。 | X | | | | | |
|
||
| CREATE VIEW | 允许用户创建或修改视图。 | X | X | X | | | |
|
||
| DELETE | 允许用户使用 DELETE | X | X | X | | | |
|
||
| DROP | 允许用户删除数据库,表和视图 | X | X | X | | | |
|
||
| EVENT | 启用事件计划程序的事件使用。 | X | X | | | | |
|
||
| EXECUTE | 允许用户执行存储的例程 | X | X | X | | | |
|
||
| FILE | 允许用户读取数据库目录中的任何文件。 | X | | | | | |
|
||
| GRANT OPTION | 允许用户拥有授予或撤消其他帐户权限的权限。 | X | X | X | | X | X |
|
||
| INDEX | 允许用户创建或删除索引。 | X | X | X | | | |
|
||
| INSERT | 允许用户使用 INSERT 语句 | X | X | X | X | | |
|
||
| LOCK TABLES | 允许用户对具有 SELECT 权限的表使用 LOCK TABLES | X | X | | | | |
|
||
| PROCESS | 允许用户使用 SHOW PROCESSLIST 语句查看所有进程。 | X | | | | | |
|
||
| PROXY | 启用用户代理。 | | | | | | |
|
||
| REFERENCES | 允许用户创建外键 | X | X | X | X | | |
|
||
| RELOAD | 允许用户使用 FLUSH 操作 | X | | | | | |
|
||
| REPLICATION CLIENT | 允许用户查询以查看主服务器或从属服务器的位置 | X | | | | | |
|
||
| REPLICATION SLAVE | 允许用户使用复制从属从主服务器读取二进制日志事件。 | X | | | | | |
|
||
| SELECT | 允许用户使用 SELECT 语句 | X | X | X | X | | |
|
||
| SHOW DATABASES | 允许用户显示所有数据库 | X | | | | | |
|
||
| SHOW VIEW | 允许用户使用 SHOW CREATE VIEW 语句 | X | X | X | | | |
|
||
| SHUTDOWN | 允许用户使用 mysqladmin shutdown 命令 | X | | | | | |
|
||
| SUPER | 允许用户使用其他管理操作,例如 CHANGE MASTER TO,KILL,PURGE BINARY LOGS,SET GLOBAL 和 mysqladmin 命令 | X | | | | | |
|
||
| TRIGGER | 允许用户使用 TRIGGER 操作。 | X | X | X | | | |
|
||
| UPDATE | 允许用户使用 UPDATE 语句 | X | X | X | X | | |
|
||
| USAGE | 相当于“没有特权” | | | | | | |
|
||
|
||
### 创建账户
|
||
|
||
```sql
|
||
CREATE USER myuser IDENTIFIED BY 'mypassword';
|
||
```
|
||
|
||
### 修改账户名
|
||
|
||
```sql
|
||
UPDATE user SET user='newuser' WHERE user='myuser';
|
||
FLUSH PRIVILEGES;
|
||
```
|
||
|
||
### 删除账户
|
||
|
||
```sql
|
||
DROP USER myuser;
|
||
```
|
||
|
||
### 查看权限
|
||
|
||
```sql
|
||
SHOW GRANTS FOR myuser;
|
||
```
|
||
|
||
### 授予权限
|
||
|
||
```sql
|
||
GRANT SELECT, INSERT ON *.* TO myuser;
|
||
```
|
||
|
||
### 删除权限
|
||
|
||
```sql
|
||
REVOKE SELECT, INSERT ON *.* FROM myuser;
|
||
```
|
||
|
||
### 更改密码
|
||
|
||
```sql
|
||
SET PASSWORD FOR myuser = 'mypass';
|
||
```
|
||
|
||
## 存储过程
|
||
|
||
存储过程可以看成是对一系列 SQL 操作的批处理。存储过程可以由触发器,其他存储过程以及 Java, Python,PHP 等应用程序调用。
|
||
|
||
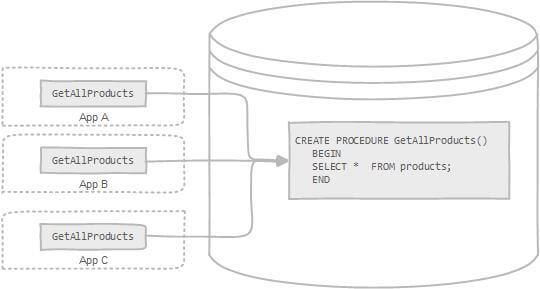
|
||
|
||
使用存储过程的好处:
|
||
|
||
- 代码封装,保证了一定的安全性;
|
||
- 代码复用;
|
||
- 由于是预先编译,因此具有很高的性能。
|
||
|
||
创建存储过程:
|
||
|
||
- 命令行中创建存储过程需要自定义分隔符,因为命令行是以 `;` 为结束符,而存储过程中也包含了分号,因此会错误把这部分分号当成是结束符,造成语法错误。
|
||
- 包含 `in`、`out` 和 `inout` 三种参数。
|
||
- 给变量赋值都需要用 `select into` 语句。
|
||
- 每次只能给一个变量赋值,不支持集合的操作。
|
||
|
||
需要注意的是:**阿里巴巴《Java 开发手册》强制禁止使用存储过程。因为存储过程难以调试和扩展,更没有移植性。**
|
||
|
||

|
||
|
||
至于到底要不要在项目中使用,还是要看项目实际需求,权衡好利弊即可!
|
||
|
||
### 创建存储过程
|
||
|
||
```sql
|
||
DROP PROCEDURE IF EXISTS `proc_adder`;
|
||
DELIMITER ;;
|
||
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)
|
||
BEGIN
|
||
DECLARE c int;
|
||
if a is null then set a = 0;
|
||
end if;
|
||
|
||
if b is null then set b = 0;
|
||
end if;
|
||
|
||
set sum = a + b;
|
||
END
|
||
;;
|
||
DELIMITER ;
|
||
```
|
||
|
||
### 使用存储过程
|
||
|
||
```less
|
||
set @b=5;
|
||
call proc_adder(2,@b,@s);
|
||
select @s as sum;
|
||
```
|
||
|
||
## 游标
|
||
|
||
游标(cursor)是一个存储在 DBMS 服务器上的数据库查询,它不是一条 `SELECT` 语句,而是被该语句检索出来的结果集。
|
||
|
||
在存储过程中使用游标可以对一个结果集进行移动遍历。
|
||
|
||
游标主要用于交互式应用,其中用户需要滚动屏幕上的数据,并对数据进行浏览或做出更改。
|
||
|
||
使用游标的几个明确步骤:
|
||
|
||
- 在使用游标前,必须声明(定义)它。这个过程实际上没有检索数据, 它只是定义要使用的 `SELECT` 语句和游标选项。
|
||
|
||
- 一旦声明,就必须打开游标以供使用。这个过程用前面定义的 SELECT 语句把数据实际检索出来。
|
||
|
||
- 对于填有数据的游标,根据需要取出(检索)各行。
|
||
|
||
- 在结束游标使用时,必须关闭游标,可能的话,释放游标(有赖于具
|
||
|
||
体的 DBMS)。
|
||
|
||
```sql
|
||
DELIMITER $
|
||
CREATE PROCEDURE getTotal()
|
||
BEGIN
|
||
DECLARE total INT;
|
||
-- 创建接收游标数据的变量
|
||
DECLARE sid INT;
|
||
DECLARE sname VARCHAR(10);
|
||
-- 创建总数变量
|
||
DECLARE sage INT;
|
||
-- 创建结束标志变量
|
||
DECLARE done INT DEFAULT false;
|
||
-- 创建游标
|
||
DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age>30;
|
||
-- 指定游标循环结束时的返回值
|
||
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
|
||
SET total = 0;
|
||
OPEN cur;
|
||
FETCH cur INTO sid, sname, sage;
|
||
WHILE(NOT done)
|
||
DO
|
||
SET total = total + 1;
|
||
FETCH cur INTO sid, sname, sage;
|
||
END WHILE;
|
||
|
||
CLOSE cur;
|
||
SELECT total;
|
||
END $
|
||
DELIMITER ;
|
||
|
||
-- 调用存储过程
|
||
call getTotal();
|
||
```
|
||
|
||
## 触发器
|
||
|
||
触发器是一种与表操作有关的数据库对象,当触发器所在表上出现指定事件时,将调用该对象,即表的操作事件触发表上的触发器的执行。
|
||
|
||
我们可以使用触发器来进行审计跟踪,把修改记录到另外一张表中。
|
||
|
||
使用触发器的优点:
|
||
|
||
- SQL 触发器提供了另一种检查数据完整性的方法。
|
||
- SQL 触发器可以捕获数据库层中业务逻辑中的错误。
|
||
- SQL 触发器提供了另一种运行计划任务的方法。通过使用 SQL 触发器,您不必等待运行计划任务,因为在对表中的数据进行更改之前或之后会自动调用触发器。
|
||
- SQL 触发器对于审计表中数据的更改非常有用。
|
||
|
||
使用触发器的缺点:
|
||
|
||
- SQL 触发器只能提供扩展验证,并且不能替换所有验证。必须在应用程序层中完成一些简单的验证。例如,您可以使用 JavaScript 在客户端验证用户的输入,或者使用服务器端脚本语言(如 JSP,PHP,ASP.NET,Perl)在服务器端验证用户的输入。
|
||
- 从客户端应用程序调用和执行 SQL 触发器是不可见的,因此很难弄清楚数据库层中发生了什么。
|
||
- SQL 触发器可能会增加数据库服务器的开销。
|
||
|
||
MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储过程。
|
||
|
||
> 注意:在 MySQL 中,分号 `;` 是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。
|
||
>
|
||
> 这时就会用到 `DELIMITER` 命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:`DELIMITER new_delimiter`。`new_delimiter` 可以设为 1 个或多个长度的符号,默认的是分号 `;`,我们可以把它修改为其他符号,如 `$` - `DELIMITER $` 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 `$`,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
|
||
|
||
在 MySQL 5.7.2 版之前,可以为每个表定义最多六个触发器。
|
||
|
||
- `BEFORE INSERT` - 在将数据插入表格之前激活。
|
||
- `AFTER INSERT` - 将数据插入表格后激活。
|
||
- `BEFORE UPDATE` - 在更新表中的数据之前激活。
|
||
- `AFTER UPDATE` - 更新表中的数据后激活。
|
||
- `BEFORE DELETE` - 在从表中删除数据之前激活。
|
||
- `AFTER DELETE` - 从表中删除数据后激活。
|
||
|
||
但是,从 MySQL 版本 5.7.2+开始,可以为同一触发事件和操作时间定义多个触发器。
|
||
|
||
**`NEW` 和 `OLD`**:
|
||
|
||
- MySQL 中定义了 `NEW` 和 `OLD` 关键字,用来表示触发器的所在表中,触发了触发器的那一行数据。
|
||
- 在 `INSERT` 型触发器中,`NEW` 用来表示将要(`BEFORE`)或已经(`AFTER`)插入的新数据;
|
||
- 在 `UPDATE` 型触发器中,`OLD` 用来表示将要或已经被修改的原数据,`NEW` 用来表示将要或已经修改为的新数据;
|
||
- 在 `DELETE` 型触发器中,`OLD` 用来表示将要或已经被删除的原数据;
|
||
- 使用方法:`NEW.columnName` (columnName 为相应数据表某一列名)
|
||
|
||
### 创建触发器
|
||
|
||
> 提示:为了理解触发器的要点,有必要先了解一下创建触发器的指令。
|
||
|
||
`CREATE TRIGGER` 指令用于创建触发器。
|
||
|
||
语法:
|
||
|
||
```sql
|
||
CREATE TRIGGER trigger_name
|
||
trigger_time
|
||
trigger_event
|
||
ON table_name
|
||
FOR EACH ROW
|
||
BEGIN
|
||
trigger_statements
|
||
END;
|
||
```
|
||
|
||
说明:
|
||
|
||
- `trigger_name`:触发器名
|
||
- `trigger_time` : 触发器的触发时机。取值为 `BEFORE` 或 `AFTER`。
|
||
- `trigger_event` : 触发器的监听事件。取值为 `INSERT`、`UPDATE` 或 `DELETE`。
|
||
- `table_name` : 触发器的监听目标。指定在哪张表上建立触发器。
|
||
- `FOR EACH ROW`: 行级监视,Mysql 固定写法,其他 DBMS 不同。
|
||
- `trigger_statements`: 触发器执行动作。是一条或多条 SQL 语句的列表,列表内的每条语句都必须用分号 `;` 来结尾。
|
||
|
||
当触发器的触发条件满足时,将会执行 `BEGIN` 和 `END` 之间的触发器执行动作。
|
||
|
||
示例:
|
||
|
||
```sql
|
||
DELIMITER $
|
||
CREATE TRIGGER `trigger_insert_user`
|
||
AFTER INSERT ON `user`
|
||
FOR EACH ROW
|
||
BEGIN
|
||
INSERT INTO `user_history`(user_id, operate_type, operate_time)
|
||
VALUES (NEW.id, 'add a user', now());
|
||
END $
|
||
DELIMITER ;
|
||
```
|
||
|
||
### 查看触发器
|
||
|
||
```sql
|
||
SHOW TRIGGERS;
|
||
```
|
||
|
||
### 删除触发器
|
||
|
||
```sql
|
||
DROP TRIGGER IF EXISTS trigger_insert_user;
|
||
```
|
||
|
||
## 文章推荐
|
||
|
||
- [后端程序员必备:SQL 高性能优化指南!35+条优化建议立马 GET!](https://mp.weixin.qq.com/s/I-ZT3zGTNBZ6egS7T09jyQ)
|
||
- [后端程序员必备:书写高质量 SQL 的 30 条建议](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486461&idx=1&sn=60a22279196d084cc398936fe3b37772&chksm=cea24436f9d5cd20a4fa0e907590f3e700d7378b3f608d7b33bb52cfb96f503b7ccb65a1deed&token=1987003517&lang=zh_CN#rd)
|
||
|
||
<!-- @include: @article-footer.snippet.md -->
|