2023-06-13 21:47:00 +08:00
---
title: 分布式锁常见实现方案总结
category: 分布式
---
2023-07-27 23:41:50 +08:00
<!-- @include: @small -advertisement.snippet.md -->
2023-06-13 21:47:00 +08:00
通常情况下,我们一般会选择基于 Redis 或者 ZooKeeper 实现分布式锁,
## 基于 Redis 实现分布式锁
### 如何基于 Redis 实现一个最简易的分布式锁?
不论是本地锁还是分布式锁,核心都在于“互斥”。
在 Redis 中, `SETNX` 命令是可以帮助我们实现互斥。`SETNX` 即 **SET** if **N**ot e**X**ists (对应 Java 中的 `setIfAbsent` 方法),如果 key 不存在的话,才会设置 key 的值。如果 key 已经存在, `SETNX` 啥也不做。
```bash
> SETNX lockKey uniqueValue
(integer) 1
> SETNX lockKey uniqueValue
(integer) 0
```
释放锁的话,直接通过 `DEL` 命令删除对应的 key 即可。
```bash
> DEL lockKey
(integer) 1
```
为了防止误删到其他的锁,这里我们建议使用 Lua 脚本通过 key 对应的 value( )
选用 Lua 脚本是为了保证解锁操作的原子性。因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
```lua
// 释放锁时,先比较锁对应的 value 值是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
```

这是一种最简易的 Redis 分布式锁实现,实现方式比较简单,性能也很高效。不过,这种方式实现分布式锁存在一些问题。就比如应用程序遇到一些问题比如释放锁的逻辑突然挂掉,可能会导致锁无法被释放,进而造成共享资源无法再被其他线程/进程访问。
### 为什么要给锁设置一个过期时间?
为了避免锁无法被释放,我们可以想到的一个解决办法就是:**给这个 key( )
```bash
127.0.0.1:6379> SET lockKey uniqueValue EX 3 NX
OK
```
- **lockKey**:加锁的锁名;
- **uniqueValue**:能够唯一标示锁的随机字符串;
- **NX**:只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
- **EX**: ( ) ( ) ,
**一定要保证设置指定 key 的值和过期时间是一个原子操作!!!** 不然的话,依然可能会出现锁无法被释放的问题。
这样确实可以解决问题,不过,这种解决办法同样存在漏洞:**如果操作共享资源的时间大于过期时间,就会出现锁提前过期的问题,进而导致分布式锁直接失效。如果锁的超时时间设置过长,又会影响到性能。**
你或许在想:**如果操作共享资源的操作还未完成,锁过期时间能够自己续期就好了!**
### 如何实现锁的优雅续期?
对于 Java 开发的小伙伴来说,已经有了现成的解决方案:**[Redisson](https://github.com/redisson/redisson)** 。其他语言的解决方案,可以在 Redis 官方文档中找到,地址:< https: / / redis . io / topics / distlock > 。

Redisson 是一个开源的 Java 语言 Redis 客户端, , ,
Redisson 中的分布式锁自带自动续期机制,使用起来非常简单,原理也比较简单,其提供了一个专门用来监控和续期锁的 **Watch Dog( , ,

看门狗名字的由来于 `getLockWatchdogTimeout()` 方法,这个方法返回的是看门狗给锁续期的过期时间,默认为 30 秒([redisson-3.17.6](https://github.com/redisson/redisson/releases/tag/redisson-3.17.6))。
```java
//默认 30秒,
private long lockWatchdogTimeout = 30 * 1000;
public Config setLockWatchdogTimeout(long lockWatchdogTimeout) {
this.lockWatchdogTimeout = lockWatchdogTimeout;
return this;
}
public long getLockWatchdogTimeout() {
return lockWatchdogTimeout;
}
```
`renewExpiration()` 方法包含了看门狗的主要逻辑:
```java
private void renewExpiration() {
//......
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//......
// 异步续期,基于 Lua 脚本
CompletionStage< Boolean > future = renewExpirationAsync(threadId);
future.whenComplete((res, e) -> {
if (e != null) {
// 无法续期
log.error("Can't update lock " + getRawName() + " expiration", e);
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
return;
}
if (res) {
// 递归调用实现续期
renewExpiration();
} else {
// 取消续期
cancelExpirationRenewal(null);
}
});
}
// 延迟 internalLockLeaseTime/3( , )
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
```
默认情况下,每过 10 秒,看门狗就会执行续期操作,将锁的超时时间设置为 30 秒。看门狗续期前也会先判断是否需要执行续期操作,需要才会执行续期,否则取消续期操作。
Watch Dog 通过调用 `renewExpirationAsync()` 方法实现锁的异步续期:
```java
protected CompletionStage< Boolean > renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
// 判断是否为持锁线程,如果是就执行续期操作,就锁的过期时间设置为 30s( )
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
}
```
可以看出, `renewExpirationAsync` 方法其实是调用 Lua 脚本实现的续期,这样做主要是为了保证续期操作的原子性。
我这里以 Redisson 的分布式可重入锁 `RLock` 为例来说明如何使用 Redisson 实现分布式锁:
```java
// 1.获取指定的分布式锁对象
RLock lock = redisson.getLock("lock");
// 2.拿锁且不设置锁超时时间,具备 Watch Dog 自动续期机制
lock.lock();
// 3.执行业务
...
// 4.释放锁
lock.unlock();
```
只有未指定锁超时时间,才会使用到 Watch Dog 自动续期机制。
```java
// 手动给锁设置过期时间,不具备 Watch Dog 自动续期机制
lock.lock(10, TimeUnit.SECONDS);
```
如果使用 Redis 来实现分布式锁的话,还是比较推荐直接基于 Redisson 来做的。
### 如何实现可重入锁?
所谓可重入锁指的是在一个线程中可以多次获取同一把锁,比如一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法即可重入 ,而无需重新获得锁。像 Java 中的 `synchronized` 和 `ReentrantLock` 都属于可重入锁。
**不可重入的分布式锁基本可以满足绝大部分业务场景了,一些特殊的场景可能会需要使用可重入的分布式锁。**
可重入分布式锁的实现核心思路是线程在获取锁的时候判断是否为自己的锁,如果是的话,就不用再重新获取了。为此,我们可以为每个锁关联一个可重入计数器和一个占有它的线程。当可重入计数器大于 0 时,则锁被占有,需要判断占有该锁的线程和请求获取锁的线程是否为同一个。
实际项目中,我们不需要自己手动实现,推荐使用我们上面提到的 **Redisson** , ( ) ( ) ( ) ( ) ( ) ( )
### Redis 如何解决集群情况下分布式锁的可靠性?
为了避免单点故障,生产环境下的 Redis 服务通常是集群化部署的。
Redis 集群下,上面介绍到的分布式锁的实现会存在一些问题。由于 Redis 集群数据同步到各个节点时是异步的,如果在 Redis 主节点获取到锁后, ,
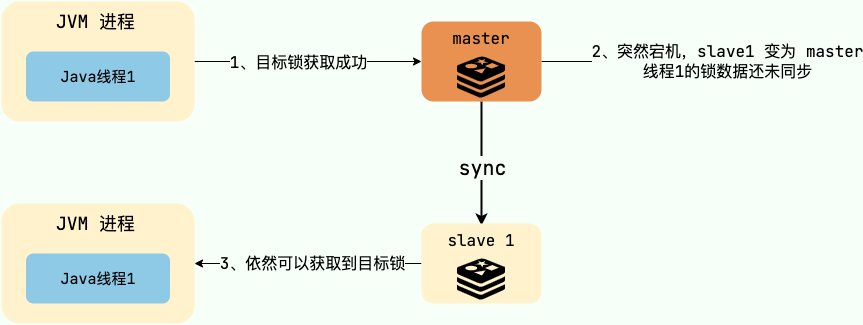
针对这个问题, Redlock 算法 ](https://redis.io/topics/distlock ) 来解决。

Redlock 算法的思想是让客户端向 Redis 集群中的多个独立的 Redis 实例依次请求申请加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
即使部分 Redis 节点出现问题,只要保证 Redis 集群中有半数以上的 Redis 节点可用,分布式锁服务就是正常的。
Redlock 是直接操作 Redis 节点的,并不是通过 Redis 集群操作的,这样才可以避免 Redis 集群主从切换导致的锁丢失问题。
Redlock 实现比较复杂,性能比较差,发生时钟变迁的情况下还存在安全性隐患。《数据密集型应用系统设计》一书的作者 Martin Kleppmann 曾经专门发文([How to do distributed locking - Martin Kleppmann - 2016](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html))怼过 Redlock, & mid=2247505097& idx=1& sn=5c03cb769c4458350f4d4a321ad51f5a& source=41#wechat_redirect)这篇文章,有详细介绍到 antirez 和 Martin Kleppmann 关于 Redlock 的激烈辩论。
实际项目中不建议使用 Redlock 算法,成本和收益不成正比。
如果不是非要实现绝对可靠的分布式锁的话,其实单机版 Redis 就完全够了,实现简单,性能也非常高。如果你必须要实现一个绝对可靠的分布式锁的话,可以基于 ZooKeeper 来做,只是性能会差一些。
## 基于 ZooKeeper 实现分布式锁
Redis 实现分布式锁性能较高,
### 如何基于 ZooKeeper 实现分布式锁?
ZooKeeper 分布式锁是基于 **临时顺序节点** 和 **Watcher( ) 实现的。
获取锁:
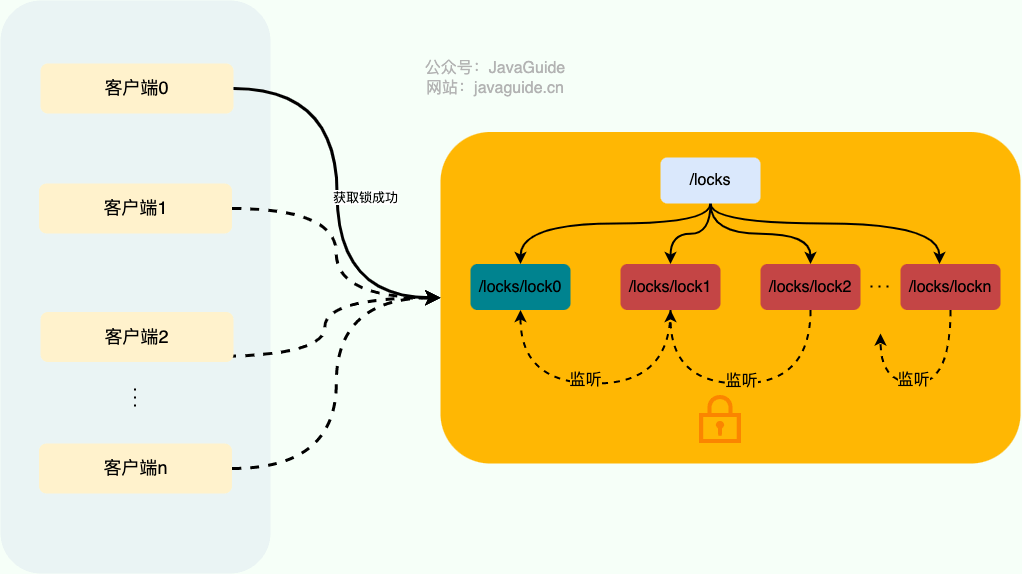
1. 首先我们要有一个持久节点`/locks`,客户端获取锁就是在`locks`下创建临时顺序节点。
2. 假设客户端 1 创建了`/locks/lock1`节点,创建成功之后,会判断 `lock1` 是否是 `/locks` 下最小的子节点。
3. 如果 `lock1` 是最小的子节点,则获取锁成功。否则,获取锁失败。
4. 如果获取锁失败,则说明有其他的客户端已经成功获取锁。客户端 1 并不会不停地循环去尝试加锁,而是在前一个节点比如`/locks/lock0`上注册一个事件监听器。这个监听器的作用是当前一个节点释放锁之后通知客户端 1( ) ,
释放锁:
1. 成功获取锁的客户端在执行完业务流程之后,会将对应的子节点删除。
2. 成功获取锁的客户端在出现故障之后,对应的子节点由于是临时顺序节点,也会被自动删除,避免了锁无法被释放。
3. 我们前面说的事件监听器其实监听的就是这个子节点删除事件,子节点删除就意味着锁被释放。
实际项目中,推荐使用 Curator 来实现 ZooKeeper 分布式锁。Curator 是 Netflix 公司开源的一套 ZooKeeper Java 客户端框架,相比于 ZooKeeper 自带的客户端 zookeeper 来说,
`Curator` 主要实现了下面四种锁:
- `InterProcessMutex` :分布式可重入排它锁
- `InterProcessSemaphoreMutex` :分布式不可重入排它锁
- `InterProcessReadWriteLock` :分布式读写锁
- `InterProcessMultiLock` :将多个锁作为单个实体管理的容器,获取锁的时候获取所有锁,释放锁也会释放所有锁资源(忽略释放失败的锁)。
```java
CuratorFramework client = ZKUtils.getClient();
client.start();
// 分布式可重入排它锁
InterProcessLock lock1 = new InterProcessMutex(client, lockPath1);
// 分布式不可重入排它锁
InterProcessLock lock2 = new InterProcessSemaphoreMutex(client, lockPath2);
// 将多个锁作为一个整体
InterProcessMultiLock lock = new InterProcessMultiLock(Arrays.asList(lock1, lock2));
if (!lock.acquire(10, TimeUnit.SECONDS)) {
throw new IllegalStateException("不能获取多锁");
}
System.out.println("已获取多锁");
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
try {
// 资源操作
resource.use();
} finally {
System.out.println("释放多个锁");
lock.release();
}
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
client.close();
```
### 为什么要用临时顺序节点?
每个数据节点在 ZooKeeper 中被称为 **znode** ,它是 ZooKeeper 中数据的最小单元。
我们通常是将 znode 分为 4 大类:
- **持久( )
- **临时( ) **客户端会话( ) 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
- **持久顺序( ) : ( ) , `/node1/app0000000001` 、`/node1/app0000000002` 。
- **临时顺序( ) : ( ) ,
可以看出,临时节点相比持久节点,最主要的是对会话失效的情况处理不一样,临时节点会话消失则对应的节点消失。这样的话,如果客户端发生异常导致没来得及释放锁也没关系,会话失效节点自动被删除,不会发生死锁的问题。
使用 Redis 实现分布式锁的时候,我们是通过过期时间来避免锁无法被释放导致死锁问题的,而 ZooKeeper 直接利用临时节点的特性即可。
2023-07-04 15:38:37 +08:00
假设不使用顺序节点的话,所有尝试获取锁的客户端都会对持有锁的子节点加监听器。当该锁被释放之后,势必会造成所有尝试获取锁的客户端来争夺锁,这样对性能不友好。使用顺序节点之后,只需要监听前一个节点就好了,对性能更友好。
2023-06-13 21:47:00 +08:00
### 为什么要设置对前一个节点的监听?
> Watcher( ) , , ,
同一时间段内,可能会有很多客户端同时获取锁,但只有一个可以获取成功。如果获取锁失败,则说明有其他的客户端已经成功获取锁。获取锁失败的客户端并不会不停地循环去尝试加锁,而是在前一个节点注册一个事件监听器。
这个事件监听器的作用是:**当前一个节点对应的客户端释放锁之后( , ) , ( , `wait/notifyAll` ),让它尝试去获取锁,然后就成功获取锁了。**
### 如何实现可重入锁?
这里以 Curator 的 `InterProcessMutex` 对可重入锁的实现来介绍(源码地址:[InterProcessMutex.java](https://github.com/apache/curator/blob/master/curator-recipes/src/main/java/org/apache/curator/framework/recipes/locks/InterProcessMutex.java))。
当我们调用 `InterProcessMutex#acquire` 方法获取锁的时候,会调用`InterProcessMutex#internalLock`方法。
```java
// 获取可重入互斥锁,直到获取成功为止
@Override
public void acquire() throws Exception {
if (!internalLock(-1, null)) {
throw new IOException("Lost connection while trying to acquire lock: " + basePath);
}
}
```
`internalLock` 方法会先获取当前请求锁的线程,然后从 `threadData` ( `ConcurrentMap<Thread, LockData>` 类型)中获取当前线程对应的 `lockData` 。 `lockData` 包含锁的信息和加锁的次数,是实现可重入锁的关键。
第一次获取锁的时候,`lockData`为 `null` 。获取锁成功之后,会将当前线程和对应的 `lockData` 放到 `threadData` 中
```java
private boolean internalLock(long time, TimeUnit unit) throws Exception {
// 获取当前请求锁的线程
Thread currentThread = Thread.currentThread();
// 拿对应的 lockData
LockData lockData = threadData.get(currentThread);
// 第一次获取锁的话,
if (lockData != null) {
// 当前线程获取过一次锁之后
// 因为当前线程的锁存在, lockCount 自增后返回,实现锁重入.
lockData.lockCount.incrementAndGet();
return true;
}
// 尝试获取锁
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
if (lockPath != null) {
LockData newLockData = new LockData(currentThread, lockPath);
// 获取锁成功之后,将当前线程和对应的 lockData 放到 threadData 中
threadData.put(currentThread, newLockData);
return true;
}
return false;
}
```
`LockData` 是 `InterProcessMutex` 中的一个静态内部类。
```java
private final ConcurrentMap< Thread , LockData > threadData = Maps.newConcurrentMap();
private static class LockData
{
// 当前持有锁的线程
final Thread owningThread;
// 锁对应的子节点
final String lockPath;
// 加锁的次数
final AtomicInteger lockCount = new AtomicInteger(1);
private LockData(Thread owningThread, String lockPath)
{
this.owningThread = owningThread;
this.lockPath = lockPath;
}
}
```
如果已经获取过一次锁,后面再来获取锁的话,直接就会在 `if (lockData != null)` 这里被拦下了,然后就会执行`lockData.lockCount.incrementAndGet();` 将加锁次数加 1。
整个可重入锁的实现逻辑非常简单,直接在客户端判断当前线程有没有获取锁,有的话直接将加锁次数加 1 就可以了。
## 总结
2023-11-29 23:27:36 +08:00
在这篇文章中,我介绍了实现分布式锁的两种常见方式: Redis 和 ZooKeeper。至于具体选择 Redis 还是 ZooKeeper 来实现分布式锁,还是要看业务的具体需求。
- 如果对性能要求比较高的话,建议使用 Redis 实现分布式锁(优先选择 Redisson 提供的现成的分布式锁,而不是自己实现)。
2023-12-30 17:14:13 +08:00
- 如果对可靠性要求比较高的话,建议使用 ZooKeeper 实现分布式锁(推荐基于 Curator 框架实现)。不过,现在很多项目都不会用到 ZooKeeper,
2023-11-29 23:27:36 +08:00
最后,再分享两篇我觉得写的还不错的文章:
- [分布式锁实现原理与最佳实践 - 阿里云开发者 ](https://mp.weixin.qq.com/s/JzCHpIOiFVmBoAko58ZuGw )
- [聊聊分布式锁 - 字节跳动技术团队 ](https://mp.weixin.qq.com/s/-N4x6EkxwAYDGdJhwvmZLw )
2023-08-07 18:56:33 +08:00
2023-10-27 06:44:02 +08:00
<!-- @include: @article -footer.snippet.md -->