chore: update deps
This commit is contained in:
parent
face018817
commit
f9a11d3399
|
|
@ -0,0 +1,28 @@
|
|||
export default {
|
||||
config: {
|
||||
default: true,
|
||||
MD003: {
|
||||
style: "atx",
|
||||
},
|
||||
MD004: {
|
||||
style: "dash",
|
||||
},
|
||||
MD010: false,
|
||||
MD013: false,
|
||||
MD024: {
|
||||
allow_different_nesting: true,
|
||||
},
|
||||
MD035: {
|
||||
style: "---",
|
||||
},
|
||||
MD036: false,
|
||||
MD040: false,
|
||||
MD045: false,
|
||||
MD046: false,
|
||||
},
|
||||
ignores: [
|
||||
"**/node_modules/**",
|
||||
// markdown import demo
|
||||
"**/*.snippet.md",
|
||||
],
|
||||
};
|
||||
|
|
@ -1,20 +0,0 @@
|
|||
{
|
||||
"default": true,
|
||||
"MD003": {
|
||||
"style": "atx"
|
||||
},
|
||||
"MD004": {
|
||||
"style": "dash"
|
||||
},
|
||||
"MD013": false,
|
||||
"MD024": {
|
||||
"allow_different_nesting": true
|
||||
},
|
||||
"MD035": {
|
||||
"style": "---"
|
||||
},
|
||||
"MD040": false,
|
||||
"MD045": false,
|
||||
"MD046": false,
|
||||
"MD049": false
|
||||
}
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
**/node_modules/**
|
||||
|
||||
# markdown snippets
|
||||
*.snippet.md
|
||||
|
|
@ -103,7 +103,7 @@
|
|||
|
||||
### JVM (必看 :+1:)
|
||||
|
||||
JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) 和周志明老师的[《深入理解 Java 虚拟机(第 3 版)》](https://book.douban.com/subject/34907497/) (强烈建议阅读多遍!)。
|
||||
JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) 和周志明老师的[《深入理解 Java 虚拟机(第 3 版)》](https://book.douban.com/subject/34907497/) (强烈建议阅读多遍!)。
|
||||
|
||||
- **[Java 内存区域](./docs/java/jvm/memory-area.md)**
|
||||
- **[JVM 垃圾回收](./docs/java/jvm/jvm-garbage-collection.md)**
|
||||
|
|
@ -183,8 +183,8 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
|
||||
**常见算法问题总结**:
|
||||
|
||||
- [几道常见的字符串算法题总结 ](./docs/cs-basics/algorithms/string-algorithm-problems.md)
|
||||
- [几道常见的链表算法题总结 ](./docs/cs-basics/algorithms/linkedlist-algorithm-problems.md)
|
||||
- [几道常见的字符串算法题总结](./docs/cs-basics/algorithms/string-algorithm-problems.md)
|
||||
- [几道常见的链表算法题总结](./docs/cs-basics/algorithms/linkedlist-algorithm-problems.md)
|
||||
- [剑指 offer 部分编程题](./docs/cs-basics/algorithms/the-sword-refers-to-offer.md)
|
||||
- [十大经典排序算法](./docs/cs-basics/algorithms/10-classical-sorting-algorithms.md)
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,4 @@
|
|||
import { defineUserConfig } from "vuepress";
|
||||
import { searchPlugin } from "@vuepress/plugin-search";
|
||||
import theme from "./theme.js";
|
||||
|
||||
export default defineUserConfig({
|
||||
|
|
@ -48,38 +47,6 @@ export default defineUserConfig({
|
|||
|
||||
theme,
|
||||
|
||||
plugins: [
|
||||
searchPlugin({
|
||||
// https://v2.vuepress.vuejs.org/zh/reference/plugin/search.html
|
||||
// 排除首页
|
||||
isSearchable: (page) => page.path !== "/",
|
||||
maxSuggestions: 10,
|
||||
hotKeys: ["s", "/"],
|
||||
// 用于在页面的搜索索引中添加额外字段
|
||||
getExtraFields: () => [],
|
||||
locales: {
|
||||
"/": {
|
||||
placeholder: "搜索",
|
||||
},
|
||||
},
|
||||
}),
|
||||
// searchProPlugin({
|
||||
// indexContent: true,
|
||||
// indexOptions: {
|
||||
// tokenize: (text, fieldName) =>
|
||||
// fieldName === "id" ? [text] : cut(text, true),
|
||||
// },
|
||||
// customFields: [
|
||||
// {
|
||||
// getter: ({ frontmatter }) =>
|
||||
// <string | undefined>frontmatter.category ?? null,
|
||||
// formatter: "分类: $content",
|
||||
// },
|
||||
// ],
|
||||
// suggestDelay: 60,
|
||||
// }),
|
||||
],
|
||||
|
||||
pagePatterns: ["**/*.md", "!**/*.snippet.md", "!.vuepress", "!node_modules"],
|
||||
|
||||
shouldPrefetch: false,
|
||||
|
|
|
|||
|
|
@ -87,5 +87,10 @@ export default hopeTheme({
|
|||
},
|
||||
tasklist: true,
|
||||
},
|
||||
|
||||
search: {
|
||||
isSearchable: (page) => page.path !== "/",
|
||||
maxSuggestions: 10,
|
||||
},
|
||||
},
|
||||
});
|
||||
|
|
|
|||
|
|
@ -20,15 +20,15 @@ tag:
|
|||
|
||||
### LeetCode
|
||||
|
||||
455.分发饼干:https://leetcode.cn/problems/assign-cookies/
|
||||
455.分发饼干:<https://leetcode.cn/problems/assign-cookies/>
|
||||
|
||||
121.买卖股票的最佳时机:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/
|
||||
121.买卖股票的最佳时机:<https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/>
|
||||
|
||||
122.买卖股票的最佳时机 II:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-ii/
|
||||
122.买卖股票的最佳时机 II:<https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-ii/>
|
||||
|
||||
55.跳跃游戏:https://leetcode.cn/problems/jump-game/
|
||||
55.跳跃游戏:<https://leetcode.cn/problems/jump-game/>
|
||||
|
||||
45.跳跃游戏 II:https://leetcode.cn/problems/jump-game-ii/
|
||||
45.跳跃游戏 II:<https://leetcode.cn/problems/jump-game-ii/>
|
||||
|
||||
## 动态规划
|
||||
|
||||
|
|
@ -48,17 +48,17 @@ tag:
|
|||
|
||||
### LeetCode
|
||||
|
||||
509.斐波那契数:https://leetcode.cn/problems/fibonacci-number/
|
||||
509.斐波那契数:<https://leetcode.cn/problems/fibonacci-number/>
|
||||
|
||||
746.使用最小花费爬楼梯:https://leetcode.cn/problems/min-cost-climbing-stairs/
|
||||
746.使用最小花费爬楼梯:<https://leetcode.cn/problems/min-cost-climbing-stairs/>
|
||||
|
||||
416.分割等和子集:https://leetcode.cn/problems/partition-equal-subset-sum/
|
||||
416.分割等和子集:<https://leetcode.cn/problems/partition-equal-subset-sum/>
|
||||
|
||||
518.零钱兑换:https://leetcode.cn/problems/coin-change-ii/
|
||||
518.零钱兑换:<https://leetcode.cn/problems/coin-change-ii/>
|
||||
|
||||
647.回文子串:https://leetcode.cn/problems/palindromic-substrings/
|
||||
647.回文子串:<https://leetcode.cn/problems/palindromic-substrings/>
|
||||
|
||||
516.最长回文子序列:https://leetcode.cn/problems/longest-palindromic-subsequence/
|
||||
516.最长回文子序列:<https://leetcode.cn/problems/longest-palindromic-subsequence/>
|
||||
|
||||
## 回溯算法
|
||||
|
||||
|
|
@ -78,17 +78,17 @@ tag:
|
|||
|
||||
### leetcode
|
||||
|
||||
77.组合:https://leetcode.cn/problems/combinations/
|
||||
77.组合:<https://leetcode.cn/problems/combinations/>
|
||||
|
||||
39.组合总和:https://leetcode.cn/problems/combination-sum/
|
||||
39.组合总和:<https://leetcode.cn/problems/combination-sum/>
|
||||
|
||||
40.组合总和 II:https://leetcode.cn/problems/combination-sum-ii/
|
||||
40.组合总和 II:<https://leetcode.cn/problems/combination-sum-ii/>
|
||||
|
||||
78.子集:https://leetcode.cn/problems/subsets/
|
||||
78.子集:<https://leetcode.cn/problems/subsets/>
|
||||
|
||||
90.子集 II:https://leetcode.cn/problems/subsets-ii/
|
||||
90.子集 II:<https://leetcode.cn/problems/subsets-ii/>
|
||||
|
||||
51.N 皇后:https://leetcode.cn/problems/n-queens/
|
||||
51.N 皇后:<https://leetcode.cn/problems/n-queens/>
|
||||
|
||||
## 分治算法
|
||||
|
||||
|
|
@ -106,9 +106,8 @@ tag:
|
|||
|
||||
### LeetCode
|
||||
|
||||
108.将有序数组转换成二叉搜索数:https://leetcode.cn/problems/convert-sorted-array-to-binary-search-tree/
|
||||
108.将有序数组转换成二叉搜索数:<https://leetcode.cn/problems/convert-sorted-array-to-binary-search-tree/>
|
||||
|
||||
148.排序列表:https://leetcode.cn/problems/sort-list/
|
||||
|
||||
23.合并 k 个升序链表:https://leetcode.cn/problems/merge-k-sorted-lists/
|
||||
148.排序列表:<https://leetcode.cn/problems/sort-list/>
|
||||
|
||||
23.合并 k 个升序链表:<https://leetcode.cn/problems/merge-k-sorted-lists/>
|
||||
|
|
|
|||
|
|
@ -7,61 +7,58 @@ tag:
|
|||
|
||||
## 数组
|
||||
|
||||
704.二分查找:https://leetcode.cn/problems/binary-search/
|
||||
704.二分查找:<https://leetcode.cn/problems/binary-search/>
|
||||
|
||||
80.删除有序数组中的重复项 II:https://leetcode.cn/problems/remove-duplicates-from-sorted-array-ii
|
||||
80.删除有序数组中的重复项 II:<https://leetcode.cn/problems/remove-duplicates-from-sorted-array-ii>
|
||||
|
||||
977.有序数组的平方:https://leetcode.cn/problems/squares-of-a-sorted-array/
|
||||
977.有序数组的平方:<https://leetcode.cn/problems/squares-of-a-sorted-array/>
|
||||
|
||||
## 链表
|
||||
|
||||
707.设计链表:https://leetcode.cn/problems/design-linked-list/
|
||||
707.设计链表:<https://leetcode.cn/problems/design-linked-list/>
|
||||
|
||||
206.反转链表:https://leetcode.cn/problems/reverse-linked-list/
|
||||
206.反转链表:<https://leetcode.cn/problems/reverse-linked-list/>
|
||||
|
||||
92.反转链表 II:https://leetcode.cn/problems/reverse-linked-list-ii/
|
||||
92.反转链表 II:<https://leetcode.cn/problems/reverse-linked-list-ii/>
|
||||
|
||||
61.旋转链表:https://leetcode.cn/problems/rotate-list/
|
||||
61.旋转链表:<https://leetcode.cn/problems/rotate-list/>
|
||||
|
||||
## 栈与队列
|
||||
|
||||
232.用栈实现队列:https://leetcode.cn/problems/implement-queue-using-stacks/
|
||||
232.用栈实现队列:<https://leetcode.cn/problems/implement-queue-using-stacks/>
|
||||
|
||||
225.用队列实现栈:https://leetcode.cn/problems/implement-stack-using-queues/
|
||||
225.用队列实现栈:<https://leetcode.cn/problems/implement-stack-using-queues/>
|
||||
|
||||
347.前 K 个高频元素:https://leetcode.cn/problems/top-k-frequent-elements/
|
||||
347.前 K 个高频元素:<https://leetcode.cn/problems/top-k-frequent-elements/>
|
||||
|
||||
239.滑动窗口最大值:https://leetcode.cn/problems/sliding-window-maximum/
|
||||
239.滑动窗口最大值:<https://leetcode.cn/problems/sliding-window-maximum/>
|
||||
|
||||
## 二叉树
|
||||
|
||||
105.从前序与中序遍历构造二叉树:https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/
|
||||
105.从前序与中序遍历构造二叉树:<https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/>
|
||||
|
||||
117.填充每个节点的下一个右侧节点指针 II:https://leetcode.cn/problems/populating-next-right-pointers-in-each-node-ii
|
||||
117.填充每个节点的下一个右侧节点指针 II:<https://leetcode.cn/problems/populating-next-right-pointers-in-each-node-ii>
|
||||
|
||||
236.二叉树的最近公共祖先:https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree/
|
||||
236.二叉树的最近公共祖先:<https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree/>
|
||||
|
||||
129.求根节点到叶节点数字之和:https://leetcode.cn/problems/sum-root-to-leaf-numbers/
|
||||
129.求根节点到叶节点数字之和:<https://leetcode.cn/problems/sum-root-to-leaf-numbers/>
|
||||
|
||||
102.二叉树的层序遍历:https://leetcode.cn/problems/binary-tree-level-order-traversal/
|
||||
102.二叉树的层序遍历:<https://leetcode.cn/problems/binary-tree-level-order-traversal/>
|
||||
|
||||
530.二叉搜索树的最小绝对差:https://leetcode.cn/problems/minimum-absolute-difference-in-bst/
|
||||
530.二叉搜索树的最小绝对差:<https://leetcode.cn/problems/minimum-absolute-difference-in-bst/>
|
||||
|
||||
## 图
|
||||
|
||||
200.岛屿数量:https://leetcode.cn/problems/number-of-islands/
|
||||
200.岛屿数量:<https://leetcode.cn/problems/number-of-islands/>
|
||||
|
||||
207.课程表:https://leetcode.cn/problems/course-schedule/
|
||||
207.课程表:<https://leetcode.cn/problems/course-schedule/>
|
||||
|
||||
210.课程表 II:https://leetcode.cn/problems/course-schedule-ii/
|
||||
210.课程表 II:<https://leetcode.cn/problems/course-schedule-ii/>
|
||||
|
||||
## 堆
|
||||
|
||||
215. 数组中的第 K 个最大元素:https://leetcode.cn/problems/kth-largest-element-in-an-array/
|
||||
|
||||
215. 数据流的中位数:https://leetcode.cn/problems/find-median-from-data-stream/
|
||||
|
||||
215. 前 K 个高频元素:https://leetcode.cn/problems/top-k-frequent-elements/
|
||||
|
||||
215.数组中的第 K 个最大元素:<https://leetcode.cn/problems/kth-largest-element-in-an-array/>
|
||||
|
||||
216.数据流的中位数:<https://leetcode.cn/problems/find-median-from-data-stream/>
|
||||
|
||||
217.前 K 个高频元素:<https://leetcode.cn/problems/top-k-frequent-elements/>
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ tag:
|
|||
|
||||
Leetcode 官方详细解答地址:
|
||||
|
||||
https://leetcode-cn.com/problems/add-two-numbers/solution/
|
||||
<https://leetcode-cn.com/problems/add-two-numbers/solution/>
|
||||
|
||||
> 要对头结点进行操作时,考虑创建哑节点 dummy,使用 dummy->next 表示真正的头节点。这样可以避免处理头节点为空的边界问题。
|
||||
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ tag:
|
|||
|
||||
> 作者:wwwxmu
|
||||
>
|
||||
> 原文地址:https://www.weiweiblog.cn/13string/
|
||||
> 原文地址:<https://www.weiweiblog.cn/13string/>
|
||||
|
||||
## 1. KMP 算法
|
||||
|
||||
|
|
@ -25,7 +25,7 @@ tag:
|
|||
**除此之外,再来了解一下 BM 算法!**
|
||||
|
||||
> BM 算法也是一种精确字符串匹配算法,它采用从右向左比较的方法,同时应用到了两种启发式规则,即坏字符规则 和好后缀规则 ,来决定向右跳跃的距离。基本思路就是从右往左进行字符匹配,遇到不匹配的字符后从坏字符表和好后缀表找一个最大的右移值,将模式串右移继续匹配。
|
||||
> 《字符串匹配的 KMP 算法》:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
|
||||
> 《字符串匹配的 KMP 算法》:<http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html>
|
||||
|
||||
## 2. 替换空格
|
||||
|
||||
|
|
@ -98,56 +98,56 @@ str.toString().replace(" ","%20");
|
|||
|
||||
```java
|
||||
public class Main {
|
||||
public static String replaceSpace(String[] strs) {
|
||||
public static String replaceSpace(String[] strs) {
|
||||
|
||||
// 如果检查值不合法及就返回空串
|
||||
if (!checkStrs(strs)) {
|
||||
return "";
|
||||
}
|
||||
// 数组长度
|
||||
int len = strs.length;
|
||||
// 用于保存结果
|
||||
StringBuilder res = new StringBuilder();
|
||||
// 给字符串数组的元素按照升序排序(包含数字的话,数字会排在前面)
|
||||
Arrays.sort(strs);
|
||||
int m = strs[0].length();
|
||||
int n = strs[len - 1].length();
|
||||
int num = Math.min(m, n);
|
||||
for (int i = 0; i < num; i++) {
|
||||
if (strs[0].charAt(i) == strs[len - 1].charAt(i)) {
|
||||
res.append(strs[0].charAt(i));
|
||||
} else
|
||||
break;
|
||||
// 如果检查值不合法及就返回空串
|
||||
if (!checkStrs(strs)) {
|
||||
return "";
|
||||
}
|
||||
// 数组长度
|
||||
int len = strs.length;
|
||||
// 用于保存结果
|
||||
StringBuilder res = new StringBuilder();
|
||||
// 给字符串数组的元素按照升序排序(包含数字的话,数字会排在前面)
|
||||
Arrays.sort(strs);
|
||||
int m = strs[0].length();
|
||||
int n = strs[len - 1].length();
|
||||
int num = Math.min(m, n);
|
||||
for (int i = 0; i < num; i++) {
|
||||
if (strs[0].charAt(i) == strs[len - 1].charAt(i)) {
|
||||
res.append(strs[0].charAt(i));
|
||||
} else
|
||||
break;
|
||||
|
||||
}
|
||||
return res.toString();
|
||||
}
|
||||
return res.toString();
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
private static boolean checkStrs(String[] strs) {
|
||||
boolean flag = false;
|
||||
if (strs != null) {
|
||||
// 遍历strs检查元素值
|
||||
for (int i = 0; i < strs.length; i++) {
|
||||
if (strs[i] != null && strs[i].length() != 0) {
|
||||
flag = true;
|
||||
} else {
|
||||
flag = false;
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
return flag;
|
||||
}
|
||||
private static boolean checkStrs(String[] strs) {
|
||||
boolean flag = false;
|
||||
if (strs != null) {
|
||||
// 遍历strs检查元素值
|
||||
for (int i = 0; i < strs.length; i++) {
|
||||
if (strs[i] != null && strs[i].length() != 0) {
|
||||
flag = true;
|
||||
} else {
|
||||
flag = false;
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
return flag;
|
||||
}
|
||||
|
||||
// 测试
|
||||
public static void main(String[] args) {
|
||||
String[] strs = { "customer", "car", "cat" };
|
||||
// String[] strs = { "customer", "car", null };//空串
|
||||
// String[] strs = {};//空串
|
||||
// String[] strs = null;//空串
|
||||
System.out.println(Main.replaceSpace(strs));// c
|
||||
}
|
||||
// 测试
|
||||
public static void main(String[] args) {
|
||||
String[] strs = { "customer", "car", "cat" };
|
||||
// String[] strs = { "customer", "car", null };//空串
|
||||
// String[] strs = {};//空串
|
||||
// String[] strs = null;//空串
|
||||
System.out.println(Main.replaceSpace(strs));// c
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
|
@ -158,8 +158,8 @@ public class Main {
|
|||
|
||||
> LeetCode: 给定一个包含大写字母和小写字母的字符串,找到通过这些字母构造成的最长的回文串。在构造过程中,请注意区分大小写。比如`"Aa"`不能当做一个回文字符串。注
|
||||
> 意:假设字符串的长度不会超过 1010。
|
||||
|
||||
> 回文串:“回文串”是一个正读和反读都一样的字符串,比如“level”或者“noon”等等就是回文串。——百度百科 地址:https://baike.baidu.com/item/%E5%9B%9E%E6%96%87%E4%B8%B2/1274921?fr=aladdin
|
||||
>
|
||||
> 回文串:“回文串”是一个正读和反读都一样的字符串,比如“level”或者“noon”等等就是回文串。——百度百科 地址:<https://baike.baidu.com/item/%E5%9B%9E%E6%96%87%E4%B8%B2/1274921?fr=aladdin>
|
||||
|
||||
示例 1:
|
||||
|
||||
|
|
@ -327,7 +327,7 @@ class Solution {
|
|||
|
||||
一个可能的最长回文子序列为 "bb"。
|
||||
|
||||
**动态规划:** dp[i][j] = dp[i+1][j-1] + 2 if s.charAt(i) == s.charAt(j) otherwise, dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1])
|
||||
**动态规划:** `dp[i][j] = dp[i+1][j-1] + 2 if s.charAt(i) == s.charAt(j) otherwise, dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1])`
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
|
|
@ -357,14 +357,14 @@ class Solution {
|
|||
> 2. 如果"X"和"Y"都是合法的括号匹配序列,"XY"也是一个合法的括号匹配序列
|
||||
> 3. 如果"X"是一个合法的括号匹配序列,那么"(X)"也是一个合法的括号匹配序列
|
||||
> 4. 每个合法的括号序列都可以由以上规则生成。
|
||||
|
||||
>
|
||||
> 例如: "","()","()()","((()))"都是合法的括号序列
|
||||
> 对于一个合法的括号序列我们又有以下定义它的深度:
|
||||
>
|
||||
> 1. 空串""的深度是 0
|
||||
> 2. 如果字符串"X"的深度是 x,字符串"Y"的深度是 y,那么字符串"XY"的深度为 max(x,y)
|
||||
> 3. 如果"X"的深度是 x,那么字符串"(X)"的深度是 x+1
|
||||
|
||||
> 1. 空串""的深度是 0
|
||||
> 2. 如果字符串"X"的深度是 x,字符串"Y"的深度是 y,那么字符串"XY"的深度为 max(x,y)
|
||||
> 3. 如果"X"的深度是 x,那么字符串"(X)"的深度是 x+1
|
||||
>
|
||||
> 例如: "()()()"的深度是 1,"((()))"的深度是 3。牛牛现在给你一个合法的括号序列,需要你计算出其深度。
|
||||
|
||||
```plain
|
||||
|
|
|
|||
|
|
@ -229,7 +229,7 @@ public String replaceSpace(StringBuffer str) {
|
|||
这道题算是比较麻烦和难一点的一个了。我这里采用的是**二分幂**思想,当然也可以采用**快速幂**。
|
||||
更具剑指 offer 书中细节,该题的解题思路如下:1.当底数为 0 且指数<0 时,会出现对 0 求倒数的情况,需进行错误处理,设置一个全局变量; 2.判断底数是否等于 0,由于 base 为 double 型,所以不能直接用==判断 3.优化求幂函数(二分幂)。
|
||||
当 n 为偶数,a^n =(a^n/2)_(a^n/2);
|
||||
当 n 为奇数,a^n = a^[(n-1)/2] _ a^[(n-1)/2] \* a。时间复杂度 O(logn)
|
||||
当 n 为奇数,a^n = a^[(n-1)/2]_ a^[(n-1)/2] \* a。时间复杂度 O(logn)
|
||||
|
||||
**时间复杂度**:O(logn)
|
||||
|
||||
|
|
@ -624,7 +624,7 @@ public class Solution {
|
|||
|
||||
这道题想了半天没有思路,参考了 Alias 的答案,他的思路写的也很详细应该很容易看懂。
|
||||
作者:Alias
|
||||
https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106
|
||||
<https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106>
|
||||
来源:牛客网
|
||||
|
||||
【思路】借用一个辅助的栈,遍历压栈顺序,先讲第一个放入栈中,这里是 1,然后判断栈顶元素是不是出栈顺序的第一个元素,这里是 4,很显然 1≠4,所以我们继续压栈,直到相等以后开始出栈,出栈一个元素,则将出栈顺序向后移动一位,直到不相等,这样循环等压栈顺序遍历完成,如果辅助栈还不为空,说明弹出序列不是该栈的弹出顺序。
|
||||
|
|
|
|||
|
|
@ -243,20 +243,20 @@ System.out.println(filter.mightContain(2));
|
|||
|
||||
### 介绍
|
||||
|
||||
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍:https://redis.io/modules
|
||||
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍:<https://redis.io/modules>
|
||||
|
||||
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom
|
||||
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:<https://github.com/RedisBloom/RedisBloom>
|
||||
其他还有:
|
||||
|
||||
- redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
|
||||
- pyreBloom(Python 中的快速 Redis 布隆过滤器):https://github.com/seomoz/pyreBloom
|
||||
- redis-lua-scaling-bloom-filter(lua 脚本实现):<https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter>
|
||||
- pyreBloom(Python 中的快速 Redis 布隆过滤器):<https://github.com/seomoz/pyreBloom>
|
||||
- ……
|
||||
|
||||
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
|
||||
|
||||
### 使用 Docker 安装
|
||||
|
||||
如果我们需要体验 Redis 中的布隆过滤器非常简单,通过 Docker 就可以了!我们直接在 Google 搜索 **docker redis bloomfilter** 然后在排除广告的第一条搜素结果就找到了我们想要的答案(这是我平常解决问题的一种方式,分享一下),具体地址:https://hub.docker.com/r/redislabs/rebloom/ (介绍的很详细 )。
|
||||
如果我们需要体验 Redis 中的布隆过滤器非常简单,通过 Docker 就可以了!我们直接在 Google 搜索 **docker redis bloomfilter** 然后在排除广告的第一条搜素结果就找到了我们想要的答案(这是我平常解决问题的一种方式,分享一下),具体地址:<https://hub.docker.com/r/redislabs/rebloom/> (介绍的很详细 )。
|
||||
|
||||
**具体操作如下:**
|
||||
|
||||
|
|
|
|||
|
|
@ -115,8 +115,8 @@ tag:
|
|||
>
|
||||
> 有效字符串需满足:
|
||||
>
|
||||
> 1. 左括号必须用相同类型的右括号闭合。
|
||||
> 2. 左括号必须以正确的顺序闭合。
|
||||
> 1. 左括号必须用相同类型的右括号闭合。
|
||||
> 2. 左括号必须以正确的顺序闭合。
|
||||
>
|
||||
> 比如 "()"、"()[]{}"、"{[]}" 都是有效字符串,而 "(]"、"([)]" 则不是。
|
||||
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ tag:
|
|||
|
||||
红黑树的诞生就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
|
||||
|
||||
## **红黑树特点**
|
||||
## **红黑树特点**
|
||||
|
||||
1. 每个节点非红即黑。黑色决定平衡,红色不决定平衡。这对应了 2-3 树中一个节点内可以存放 1~2 个节点。
|
||||
2. 根节点总是黑色的。
|
||||
|
|
@ -31,7 +31,6 @@ tag:
|
|||
|
||||
正是这些特点才保证了红黑树的平衡,让红黑树的高度不会超过 2log(n+1)。
|
||||
|
||||
|
||||
## 红黑树数据结构
|
||||
|
||||
建立在 BST 二叉搜索树的基础上,AVL、2-3 树、红黑树都是自平衡二叉树(统称 B-树)。但相比于 AVL 树,高度平衡所带来的时间复杂度,红黑树对平衡的控制要宽松一些,红黑树只需要保证黑色节点平衡即可。
|
||||
|
|
@ -51,7 +50,7 @@ public class Node {
|
|||
public int height;
|
||||
// 红黑树所需属性
|
||||
public Color color = Color.RED;
|
||||
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -60,11 +60,11 @@ SMTP 协议这块涉及的内容比较多,下面这两个问题比较重要:
|
|||
|
||||
**电子邮件的发送过程?**
|
||||
|
||||
比如我的邮箱是“dabai@cszhinan.com”,我要向“xiaoma@qq.com”发送邮件,整个过程可以简单分为下面几步:
|
||||
比如我的邮箱是“<dabai@cszhinan.com>”,我要向“<xiaoma@qq.com>”发送邮件,整个过程可以简单分为下面几步:
|
||||
|
||||
1. 通过 **SMTP** 协议,我将我写好的邮件交给 163 邮箱服务器(邮局)。
|
||||
2. 163 邮箱服务器发现我发送的邮箱是 qq 邮箱,然后它使用 SMTP 协议将我的邮件转发到 qq 邮箱服务器。
|
||||
3. qq 邮箱服务器接收邮件之后就通知邮箱为“xiaoma@qq.com”的用户来收邮件,然后用户就通过 **POP3/IMAP** 协议将邮件取出。
|
||||
3. qq 邮箱服务器接收邮件之后就通知邮箱为“<xiaoma@qq.com>”的用户来收邮件,然后用户就通过 **POP3/IMAP** 协议将邮件取出。
|
||||
|
||||
**如何判断邮箱是真正存在的?**
|
||||
|
||||
|
|
@ -77,9 +77,9 @@ SMTP 协议这块涉及的内容比较多,下面这两个问题比较重要:
|
|||
|
||||
推荐几个在线邮箱是否有效检测工具:
|
||||
|
||||
1. https://verify-email.org/
|
||||
2. http://tool.chacuo.net/mailverify
|
||||
3. https://www.emailcamel.com/
|
||||
1. <https://verify-email.org/>
|
||||
2. <http://tool.chacuo.net/mailverify>
|
||||
3. <https://www.emailcamel.com/>
|
||||
|
||||
## POP3/IMAP:邮件接收的协议
|
||||
|
||||
|
|
@ -138,6 +138,6 @@ DNS(Domain Name System,域名管理系统)基于 UDP 协议,用于解决
|
|||
## 参考
|
||||
|
||||
- 《计算机网络自顶向下方法》(第七版)
|
||||
- RTP 协议介绍:https://mthli.xyz/rtp-introduction/
|
||||
- RTP 协议介绍:<https://mthli.xyz/rtp-introduction/>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -11,9 +11,9 @@ tag:
|
|||
|
||||
开始阅读这篇文章之前,你可以先看看下面几个问题:
|
||||
|
||||
1. **ARP 协议在协议栈中的位置?** ARP 协议在协议栈中的位置非常重要,在理解了它的工作原理之后,也很难说它到底是网络层协议,还是链路层协议,因为它恰恰串联起了网络层和链路层。国外的大部分教程通常将 ARP 协议放在网络层。
|
||||
2. **ARP 协议解决了什么问题,地位如何?** ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
|
||||
3. **ARP 工作原理?** 只希望大家记住几个关键词:**ARP 表、广播问询、单播响应**。
|
||||
1. **ARP 协议在协议栈中的位置?** ARP 协议在协议栈中的位置非常重要,在理解了它的工作原理之后,也很难说它到底是网络层协议,还是链路层协议,因为它恰恰串联起了网络层和链路层。国外的大部分教程通常将 ARP 协议放在网络层。
|
||||
2. **ARP 协议解决了什么问题,地位如何?** ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
|
||||
3. **ARP 工作原理?** 只希望大家记住几个关键词:**ARP 表、广播问询、单播响应**。
|
||||
|
||||
## MAC 地址
|
||||
|
||||
|
|
|
|||
|
|
@ -97,8 +97,8 @@ foo.example.com. A 192.0.2.23
|
|||
|
||||
## 参考
|
||||
|
||||
- DNS 服务器类型:https://www.cloudflare.com/zh-cn/learning/dns/dns-server-types/
|
||||
- DNS Message Resource Record Field Formats:http://www.tcpipguide.com/free/t_DNSMessageResourceRecordFieldFormats-2.htm
|
||||
- Understanding Different Types of Record in DNS Server:https://www.mustbegeek.com/understanding-different-types-of-record-in-dns-server/
|
||||
- DNS 服务器类型:<https://www.cloudflare.com/zh-cn/learning/dns/dns-server-types/>
|
||||
- DNS Message Resource Record Field Formats:<http://www.tcpipguide.com/free/t_DNSMessageResourceRecordFieldFormats-2.htm>
|
||||
- Understanding Different Types of Record in DNS Server:<https://www.mustbegeek.com/understanding-different-types-of-record-in-dns-server/>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -64,9 +64,9 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||
|
||||
### 参考
|
||||
|
||||
- https://www.restapitutorial.com/httpstatuscodes.html
|
||||
- https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
|
||||
- https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
|
||||
- https://segmentfault.com/a/1190000018264501
|
||||
- <https://www.restapitutorial.com/httpstatuscodes.html>
|
||||
- <https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status>
|
||||
- <https://en.wikipedia.org/wiki/List_of_HTTP_status_codes>
|
||||
- <https://segmentfault.com/a/1190000018264501>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -53,7 +53,7 @@ HTTP/1.1 的缓存机制在 HTTP/1.0 的基础上,大大增加了灵活性和
|
|||
|
||||
## Host 头处理
|
||||
|
||||
域名系统(DNS)允许多个主机名绑定到同一个 IP 地址上,但是 HTTP/1.0 并没有考虑这个问题,假设我们有一个资源 URL 是http://example1.org/home.html,HTTP/1.0 的请求报文中,将会请求的是`GET /home.html HTTP/1.0`.也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
|
||||
域名系统(DNS)允许多个主机名绑定到同一个 IP 地址上,但是 HTTP/1.0 并没有考虑这个问题,假设我们有一个资源 URL 是<http://example1.org/home.html,HTTP/1.0> 的请求报文中,将会请求的是`GET /home.html HTTP/1.0`.也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
|
||||
|
||||
因此,HTTP/1.1 在请求头中加入了`Host`字段。加入`Host`字段的报文头部将会是:
|
||||
|
||||
|
|
|
|||
|
|
@ -199,13 +199,13 @@ DNS Flood 对传统上基于放大的攻击方法做出了改变。借助轻易
|
|||
可以使用 netcat 工具来建立 TCP 连接,这个工具很多操作系统都预装了。打开第一个终端窗口,运行以下命令:
|
||||
|
||||
```bash
|
||||
$ nc -nvl 8000
|
||||
nc -nvl 8000
|
||||
```
|
||||
|
||||
这个命令会启动一个 TCP 服务,监听端口为 `8000`。接着再打开第二个终端窗口,运行以下命令:
|
||||
|
||||
```bash
|
||||
$ nc 127.0.0.1 8000
|
||||
nc 127.0.0.1 8000
|
||||
```
|
||||
|
||||
该命令会尝试与上面的服务建立连接,在其中一个窗口输入一些字符,就会通过 TCP 连接发送给另一个窗口并打印出来。
|
||||
|
|
@ -328,7 +328,7 @@ DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实
|
|||
|
||||
**SM1 和 SM4**
|
||||
|
||||
之前几种都是国外的,我们国内自行研究了国密 **SM1 **和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可
|
||||
之前几种都是国外的,我们国内自行研究了国密 **SM1**和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可
|
||||
|
||||
**总结**:
|
||||
|
||||
|
|
@ -462,9 +462,9 @@ CDN 加速,我们可以这么理解:为了减少流氓骚扰,我干脆将
|
|||
|
||||
## 参考
|
||||
|
||||
- HTTP 洪水攻击 - CloudFlare:https://www.cloudflare.com/zh-cn/learning/ddos/http-flood-ddos-attack/
|
||||
- SYN 洪水攻击:https://www.cloudflare.com/zh-cn/learning/ddos/syn-flood-ddos-attack/
|
||||
- 什么是 IP 欺骗?:https://www.cloudflare.com/zh-cn/learning/ddos/glossary/ip-spoofing/
|
||||
- 什么是 DNS 洪水?| DNS 洪水 DDoS 攻击:https://www.cloudflare.com/zh-cn/learning/ddos/dns-flood-ddos-attack/
|
||||
- HTTP 洪水攻击 - CloudFlare:<https://www.cloudflare.com/zh-cn/learning/ddos/http-flood-ddos-attack/>
|
||||
- SYN 洪水攻击:<https://www.cloudflare.com/zh-cn/learning/ddos/syn-flood-ddos-attack/>
|
||||
- 什么是 IP 欺骗?:<https://www.cloudflare.com/zh-cn/learning/ddos/glossary/ip-spoofing/>
|
||||
- 什么是 DNS 洪水?| DNS 洪水 DDoS 攻击:<https://www.cloudflare.com/zh-cn/learning/ddos/dns-flood-ddos-attack/>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -189,7 +189,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
|||
|
||||
## 参考
|
||||
|
||||
- TCP/IP model vs OSI model:https://fiberbit.com.tw/tcpip-model-vs-osi-model/
|
||||
- Data Encapsulation and the TCP/IP Protocol Stack:https://docs.oracle.com/cd/E19683-01/806-4075/ipov-32/index.html
|
||||
- TCP/IP model vs OSI model:<https://fiberbit.com.tw/tcpip-model-vs-osi-model/>
|
||||
- Data Encapsulation and the TCP/IP Protocol Stack:<https://docs.oracle.com/cd/E19683-01/806-4075/ipov-32/index.html>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -106,7 +106,7 @@ tag:
|
|||
|
||||
图解(图片来源:《图解 HTTP》):
|
||||
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/url%E8%BE%93%E5%85%A5%E5%88%B0%E5%B1%95%E7%A4%BA%E5%87%BA%E6%9D%A5%E7%9A%84%E8%BF%87%E7%A8%8B.jpg" style="zoom:50%; " />
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/url%E8%BE%93%E5%85%A5%E5%88%B0%E5%B1%95%E7%A4%BA%E5%87%BA%E6%9D%A5%E7%9A%84%E8%BF%87%E7%A8%8B.jpg" style="zoom:50%" />
|
||||
|
||||
> 上图有一个错误,请注意,是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
|
||||
|
||||
|
|
|
|||
|
|
@ -56,8 +56,8 @@ HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **
|
|||
|
||||
相关证明可以参考下面这两个链接:
|
||||
|
||||
- https://zh.wikipedia.org/zh/HTTP/3
|
||||
- https://datatracker.ietf.org/doc/rfc9114/
|
||||
- <https://zh.wikipedia.org/zh/HTTP/3>
|
||||
- <https://datatracker.ietf.org/doc/rfc9114/>
|
||||
|
||||
### 使用 TCP 的协议有哪些?使用 UDP 的协议有哪些?
|
||||
|
||||
|
|
|
|||
|
|
@ -81,6 +81,6 @@ TCP 是全双工通信,可以双向传输数据。任何一方都可以在数
|
|||
|
||||
- 《图解 HTTP》
|
||||
|
||||
- TCP and UDP Tutorial:https://www.9tut.com/tcp-and-udp-tutorial
|
||||
- TCP and UDP Tutorial:<https://www.9tut.com/tcp-and-udp-tutorial>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -112,7 +112,7 @@ ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
|
|||
3. [https://www.9tut.com/tcp-and-udp-tutorial](https://www.9tut.com/tcp-and-udp-tutorial)
|
||||
4. [https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md](https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md)
|
||||
5. TCP Flow Control—[https://www.brianstorti.com/tcp-flow-control/](https://www.brianstorti.com/tcp-flow-control/)
|
||||
6. TCP 流量控制(Flow Control):https://notfalse.net/24/tcp-flow-control
|
||||
7. TCP 之滑动窗口原理 : https://cloud.tencent.com/developer/article/1857363
|
||||
6. TCP 流量控制(Flow Control):<https://notfalse.net/24/tcp-flow-control>
|
||||
7. TCP 之滑动窗口原理 : <https://cloud.tencent.com/developer/article/1857363>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -166,7 +166,7 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
|
|||
|
||||
下面只是给出了一些比较常用的命令。
|
||||
|
||||
推荐一个 Linux 命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。Linux 命令在线速查手册:https://wangchujiang.com/linux-command/ 。
|
||||
推荐一个 Linux 命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。Linux 命令在线速查手册:<https://wangchujiang.com/linux-command/> 。
|
||||
|
||||
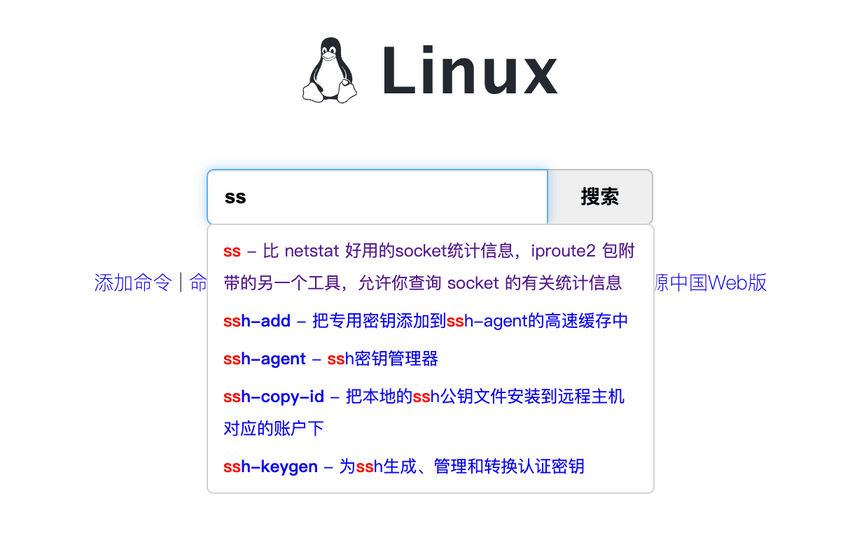
|
||||
|
||||
|
|
|
|||
|
|
@ -454,8 +454,8 @@ Thread[线程 2,5,main]waiting get resource1
|
|||
- 《计算机操作系统—汤小丹》第四版
|
||||
- 《深入理解计算机系统》
|
||||
- 《重学操作系统》
|
||||
- 操作系统为什么要分用户态和内核态:https://blog.csdn.net/chen134225/article/details/81783980
|
||||
- 从根上理解用户态与内核态:https://juejin.cn/post/6923863670132850701
|
||||
- 什么是僵尸进程与孤儿进程:https://blog.csdn.net/a745233700/article/details/120715371
|
||||
- 操作系统为什么要分用户态和内核态:<https://blog.csdn.net/chen134225/article/details/81783980>
|
||||
- 从根上理解用户态与内核态:<https://juejin.cn/post/6923863670132850701>
|
||||
- 什么是僵尸进程与孤儿进程:<https://blog.csdn.net/a745233700/article/details/120715371>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -211,7 +211,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
|
|||
|
||||
#### 单级页表有什么问题?为什么需要多级页表?
|
||||
|
||||
以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,2^20 * 2^2/1024*1024= 4MB。也就是说一个程序啥都不干,页表大小就得占用 4M。
|
||||
以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,`2^20 * 2^2 / 1024 * 1024= 4MB`。也就是说一个程序啥都不干,页表大小就得占用 4M。
|
||||
|
||||
系统运行的应用程序多起来的话,页表的开销还是非常大的。而且,绝大部分应用程序可能只能用到页表中的几项,其他的白白浪费了。
|
||||
|
||||
|
|
@ -404,10 +404,10 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
|
|||
- 《深入理解计算机系统》
|
||||
- 《重学操作系统》
|
||||
- 《现代操作系统原理与实现》
|
||||
- 王道考研操作系统知识点整理:https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html
|
||||
- 内存管理之伙伴系统与 SLAB:https://blog.csdn.net/qq_44272681/article/details/124199068
|
||||
- 为什么 Linux 需要虚拟内存:https://draveness.me/whys-the-design-os-virtual-memory/
|
||||
- 程序员的自我修养(七):内存缺页错误:https://liam.page/2017/09/01/page-fault/
|
||||
- 虚拟内存的那点事儿:https://juejin.cn/post/6844903507594575886
|
||||
- 王道考研操作系统知识点整理:<https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html>
|
||||
- 内存管理之伙伴系统与 SLAB:<https://blog.csdn.net/qq_44272681/article/details/124199068>
|
||||
- 为什么 Linux 需要虚拟内存:<https://draveness.me/whys-the-design-os-virtual-memory/>
|
||||
- 程序员的自我修养(七):内存缺页错误:<https://liam.page/2017/09/01/page-fault/>
|
||||
- 虚拟内存的那点事儿:<https://juejin.cn/post/6844903507594575886>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ tag:
|
|||
- MySQL
|
||||
---
|
||||
|
||||
> 原文地址:https://shockerli.net/post/1000-line-mysql-note/ ,JavaGuide 对本文进行了简答排版,新增了目录。
|
||||
> 原文地址:<https://shockerli.net/post/1000-line-mysql-note/> ,JavaGuide 对本文进行了简答排版,新增了目录。
|
||||
|
||||
非常不错的总结,强烈建议保存下来,需要的时候看一看。
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ tag:
|
|||
|
||||
> 本次测试使用的 MySQL 版本是 `5.7.26`,随着 MySQL 版本的更新某些特性可能会发生改变,本文不代表所述观点和结论于 MySQL 所有版本均准确无误,版本差异请自行甄别。
|
||||
>
|
||||
> 原文:https://www.guitu18.com/post/2019/11/24/61.html
|
||||
> 原文:<https://www.guitu18.com/post/2019/11/24/61.html>
|
||||
|
||||
## 前言
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ tag:
|
|||
|
||||
> 作者:飞天小牛肉
|
||||
>
|
||||
> 原文:https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ
|
||||
> 原文:<https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ>
|
||||
|
||||
众所周知,自增主键可以让聚集索引尽量地保持递增顺序插入,避免了随机查询,从而提高了查询效率。
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ tag:
|
|||
- MySQL
|
||||
---
|
||||
|
||||
> 感谢[WT-AHA](https://github.com/WT-AHA)对本文的完善,相关 PR:https://github.com/Snailclimb/JavaGuide/pull/1648 。
|
||||
> 感谢[WT-AHA](https://github.com/WT-AHA)对本文的完善,相关 PR:<https://github.com/Snailclimb/JavaGuide/pull/1648> 。
|
||||
|
||||
但凡经历过几场面试的小伙伴,应该都清楚,数据库索引这个知识点在面试中出现的频率高到离谱。
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ head:
|
|||
content: 执行计划是指一条 SQL 语句在经过MySQL 查询优化器的优化会后,具体的执行方式。优化 SQL 的第一步应该是读懂 SQL 的执行计划。
|
||||
---
|
||||
|
||||
> 本文来自公号 MySQL 技术,JavaGuide 对其做了补充完善。原文地址:https://mp.weixin.qq.com/s/d5OowNLtXBGEAbT31sSH4g
|
||||
> 本文来自公号 MySQL 技术,JavaGuide 对其做了补充完善。原文地址:<https://mp.weixin.qq.com/s/d5OowNLtXBGEAbT31sSH4g>
|
||||
|
||||
优化 SQL 的第一步应该是读懂 SQL 的执行计划。本篇文章,我们一起来学习下 MySQL `EXPLAIN` 执行计划相关知识。
|
||||
|
||||
|
|
@ -138,7 +138,7 @@ rows 列表示根据表统计信息及选用情况,大致估算出找到所需
|
|||
|
||||
## 参考
|
||||
|
||||
- https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
|
||||
- https://juejin.cn/post/6953444668973514789
|
||||
- <https://dev.mysql.com/doc/refman/5.7/en/explain-output.html>
|
||||
- <https://juejin.cn/post/6953444668973514789>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ tag:
|
|||
- Redis
|
||||
---
|
||||
|
||||
> 本文整理完善自:https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA ,作者:阿 Q 说代码
|
||||
> 本文整理完善自:<https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA> ,作者:阿 Q 说代码
|
||||
|
||||
这篇文章会详细总结一下可能导致 Redis 阻塞的情况,这些情况也是影响 Redis 性能的关键因素,使用 Redis 的时候应该格外注意!
|
||||
|
||||
|
|
@ -172,7 +172,7 @@ Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型
|
|||
|
||||
## 参考
|
||||
|
||||
- Redis 阻塞的 6 大类场景分析与总结:https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew
|
||||
- Redis 开发与运维笔记-Redis 的噩梦-阻塞:https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA
|
||||
- Redis 阻塞的 6 大类场景分析与总结:<https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew>
|
||||
- Redis 开发与运维笔记-Redis 的噩梦-阻塞:<https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -219,8 +219,8 @@ user2
|
|||
|
||||
## 参考
|
||||
|
||||
- Redis Data Structures:https://redis.com/redis-enterprise/data-structures/ 。
|
||||
- Redis Data Structures:<https://redis.com/redis-enterprise/data-structures/> 。
|
||||
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog
|
||||
- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html
|
||||
- 布隆过滤器,位图,HyperLogLog:<https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ Redis 内存碎片产生比较常见的 2 个原因:
|
|||
|
||||
Redis 使用 `zmalloc` 方法(Redis 自己实现的内存分配方法)进行内存分配的时候,除了要分配 `size` 大小的内存之外,还会多分配 `PREFIX_SIZE` 大小的内存。
|
||||
|
||||
`zmalloc` 方法源码如下(源码地址:https://github.com/antirez/redis-tools/blob/master/zmalloc.c):
|
||||
`zmalloc` 方法源码如下(源码地址:<https://github.com/antirez/redis-tools/blob/master/zmalloc.c):>
|
||||
|
||||
```java
|
||||
void *zmalloc(size_t size) {
|
||||
|
|
@ -59,11 +59,11 @@ void *zmalloc(size_t size) {
|
|||
|
||||

|
||||
|
||||
文档地址:https://redis.io/topics/memory-optimization 。
|
||||
文档地址:<https://redis.io/topics/memory-optimization> 。
|
||||
|
||||
## 如何查看 Redis 内存碎片的信息?
|
||||
|
||||
使用 `info memory` 命令即可查看 Redis 内存相关的信息。下图中每个参数具体的含义,Redis 官方文档有详细的介绍:https://redis.io/commands/INFO 。
|
||||
使用 `info memory` 命令即可查看 Redis 内存相关的信息。下图中每个参数具体的含义,Redis 官方文档有详细的介绍:<https://redis.io/commands/INFO> 。
|
||||
|
||||
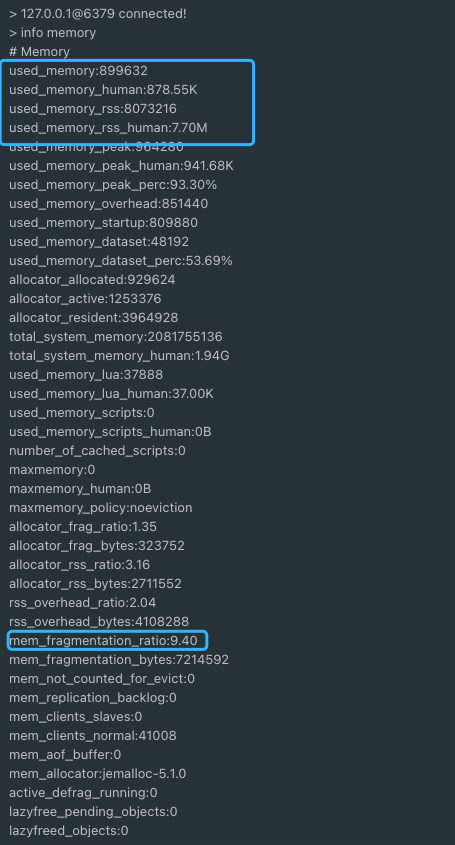
|
||||
|
||||
|
|
@ -117,8 +117,8 @@ config set active-defrag-cycle-max 50
|
|||
|
||||
## 参考
|
||||
|
||||
- Redis 官方文档:https://redis.io/topics/memory-optimization
|
||||
- Redis 核心技术与实战 - 极客时间 - 删除数据后,为什么内存占用率还是很高?:https://time.geekbang.org/column/article/289140
|
||||
- Redis 源码解析——内存分配:<https://shinerio.cc/2020/05/17/redis/Redis 源码解析——内存管理>
|
||||
- Redis 官方文档:<https://redis.io/topics/memory-optimization>
|
||||
- Redis 核心技术与实战 - 极客时间 - 删除数据后,为什么内存占用率还是很高?:<https://time.geekbang.org/column/article/289140>
|
||||
- Redis 源码解析——内存分配:<<https://shinerio.cc/2020/05/17/redis/Redis> 源码解析——内存管理>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而
|
|||
- 只追加文件(append-only file, AOF)
|
||||
- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
|
||||
|
||||
官方文档地址:https://redis.io/topics/persistence 。
|
||||
官方文档地址:<https://redis.io/topics/persistence> 。
|
||||
|
||||

|
||||
|
||||
|
|
@ -163,7 +163,7 @@ AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文
|
|||
|
||||
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
|
||||
|
||||
官方文档地址:https://redis.io/topics/persistence
|
||||
官方文档地址:<https://redis.io/topics/persistence>
|
||||
|
||||

|
||||
|
||||
|
|
@ -191,9 +191,9 @@ AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文
|
|||
## 参考
|
||||
|
||||
- 《Redis 设计与实现》
|
||||
- Redis persistence - Redis 官方文档:https://redis.io/docs/management/persistence/
|
||||
- The difference between AOF and RDB persistence:https://www.sobyte.net/post/2022-04/redis-rdb-and-aof/
|
||||
- Redis AOF 持久化详解 - 程序员历小冰:http://remcarpediem.net/article/376c55d8/
|
||||
- Redis RDB 与 AOF 持久化 · Analyze:https://wingsxdu.com/posts/database/redis/rdb-and-aof/
|
||||
- Redis persistence - Redis 官方文档:<https://redis.io/docs/management/persistence/>
|
||||
- The difference between AOF and RDB persistence:<https://www.sobyte.net/post/2022-04/redis-rdb-and-aof/>
|
||||
- Redis AOF 持久化详解 - 程序员历小冰:<http://remcarpediem.net/article/376c55d8/>
|
||||
- Redis RDB 与 AOF 持久化 · Analyze:<https://wingsxdu.com/posts/database/redis/rdb-and-aof/>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -235,7 +235,7 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
|
|||
|
||||
总的来说,`Stream` 已经可以满足一个消息队列的基本要求了。不过,`Stream` 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
|
||||
|
||||
综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 `Stream`,这是目前相对最优的 Redis 消息队列实现。
|
||||
综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 `Stream`,这是目前相对最优的 Redis 消息队列实现。
|
||||
|
||||
相关阅读:[Redis 消息队列发展历程 - 阿里开发者 - 2022](https://mp.weixin.qq.com/s/gCUT5TcCQRAxYkTJfTRjJw)。
|
||||
|
||||
|
|
@ -303,7 +303,7 @@ Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现
|
|||
|
||||
SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
|
||||
|
||||
Redis7.0 的 SDS 的部分源码如下(https://github.com/redis/redis/blob/7.0/src/sds.h):
|
||||
Redis7.0 的 SDS 的部分源码如下(<https://github.com/redis/redis/blob/7.0/src/sds.h>):
|
||||
|
||||
```c
|
||||
/* Note: sdshdr5 is never used, we just access the flags byte directly.
|
||||
|
|
@ -577,7 +577,7 @@ io-threads-do-reads yes
|
|||
- 通过 `bio_aof_fsync` 后台线程调用 `fsync` 函数将系统内核缓冲区还未同步到到磁盘的数据强制刷到磁盘( AOF 文件)。
|
||||
- 通过 `bio_lazy_free`后台线程释放大对象(已删除)占用的内存空间.
|
||||
|
||||
在`bio.h` 文件中有定义(Redis 6.0 版本,源码地址:https://github.com/redis/redis/blob/6.0/src/bio.h):
|
||||
在`bio.h` 文件中有定义(Redis 6.0 版本,源码地址:<https://github.com/redis/redis/blob/6.0/src/bio.h>):
|
||||
|
||||
```java
|
||||
#ifndef __BIO_H
|
||||
|
|
@ -684,7 +684,7 @@ Redis 提供 6 种数据淘汰策略:
|
|||
|
||||
- 《Redis 开发与运维》
|
||||
- 《Redis 设计与实现》
|
||||
- Redis 命令手册:https://www.redis.com.cn/commands.html
|
||||
- Redis 命令手册:<https://www.redis.com.cn/commands.html>
|
||||
- RedisSearch 终极使用指南,你值得拥有!:<https://mp.weixin.qq.com/s/FA4XVAXJksTOHUXMsayy2g>
|
||||
- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
|
||||
|
||||
|
|
|
|||
|
|
@ -206,7 +206,7 @@ Redis 从 2.6 版本开始支持执行 Lua 脚本,它的功能和事务非常
|
|||
|
||||
使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT。
|
||||
|
||||
另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在`read()`和`write()`系统调用),批量操作还可以减少 socket I/O 成本。这个在官方对 pipeline 的介绍中有提到:https://redis.io/docs/manual/pipelining/ 。
|
||||
另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在`read()`和`write()`系统调用),批量操作还可以减少 socket I/O 成本。这个在官方对 pipeline 的介绍中有提到:<https://redis.io/docs/manual/pipelining/> 。
|
||||
|
||||
#### 原生批量操作命令
|
||||
|
||||
|
|
|
|||
|
|
@ -1027,11 +1027,11 @@ ORDER BY order_date
|
|||
|
||||
`Customers` 表代表顾客信息,`cust_id` 为顾客 id,`cust_email` 为顾客 email
|
||||
|
||||
| cust_id | cust_email |
|
||||
| ------- | --------------- |
|
||||
| cust10 | cust10@cust.com |
|
||||
| cust1 | cust1@cust.com |
|
||||
| cust2 | cust2@cust.com |
|
||||
| cust_id | cust_email |
|
||||
| ------- | ----------------- |
|
||||
| cust10 | <cust10@cust.com> |
|
||||
| cust1 | <cust1@cust.com> |
|
||||
| cust2 | <cust2@cust.com> |
|
||||
|
||||
【问题】返回购买 `prod_id` 为 `BR01` 的产品的所有顾客的电子邮件(`Customers` 表中的 `cust_email`),结果无需排序。
|
||||
|
||||
|
|
@ -1417,11 +1417,11 @@ ORDER BY order_date
|
|||
|
||||
`Customers` 表代表顾客信息,`cust_id` 为顾客 id,`cust_email` 为顾客 email
|
||||
|
||||
| cust_id | cust_email |
|
||||
| ------- | --------------- |
|
||||
| cust10 | cust10@cust.com |
|
||||
| cust1 | cust1@cust.com |
|
||||
| cust2 | cust2@cust.com |
|
||||
| cust_id | cust_email |
|
||||
| ------- | ----------------- |
|
||||
| cust10 | <cust10@cust.com> |
|
||||
| cust1 | <cust1@cust.com> |
|
||||
| cust2 | <cust2@cust.com> |
|
||||
|
||||
【问题】返回购买 `prod_id` 为 BR01 的产品的所有顾客的电子邮件(`Customers` 表中的 `cust_email`),结果无需排序。
|
||||
|
||||
|
|
@ -1779,11 +1779,11 @@ ORDER BY prod_name
|
|||
|
||||
表 `Customers` 含有字段 `cust_name` 顾客名、`cust_contact` 顾客联系方式、`cust_state` 顾客州、`cust_email` 顾客 `email`
|
||||
|
||||
| cust_name | cust_contact | cust_state | cust_email |
|
||||
| --------- | ------------ | ---------- | --------------- |
|
||||
| cust10 | 8695192 | MI | cust10@cust.com |
|
||||
| cust1 | 8695193 | MI | cust1@cust.com |
|
||||
| cust2 | 8695194 | IL | cust2@cust.com |
|
||||
| cust_name | cust_contact | cust_state | cust_email |
|
||||
| --------- | ------------ | ---------- | ----------------- |
|
||||
| cust10 | 8695192 | MI | <cust10@cust.com> |
|
||||
| cust1 | 8695193 | MI | <cust1@cust.com> |
|
||||
| cust2 | 8695194 | IL | <cust2@cust.com> |
|
||||
|
||||
【问题】修正下面错误的 SQL
|
||||
|
||||
|
|
|
|||
|
|
@ -368,7 +368,7 @@ private static class LockData
|
|||
在这篇文章中,我介绍了实现分布式锁的两种常见方式: Redis 和 ZooKeeper。至于具体选择 Redis 还是 ZooKeeper 来实现分布式锁,还是要看业务的具体需求。
|
||||
|
||||
- 如果对性能要求比较高的话,建议使用 Redis 实现分布式锁(优先选择 Redisson 提供的现成的分布式锁,而不是自己实现)。
|
||||
- 如果对可靠性要求比较高的话,建议使用 ZooKeeper 实现分布式锁(推荐基于 Curator 框架实现)。不过,现在很多项目都不会用到 ZooKeeper,如果单纯是因为分布式锁而引入 ZooKeeper 的话,那是不太可取的,不建议这样做,为了一个小小的功能增加了系统的复杂度。
|
||||
- 如果对可靠性要求比较高的话,建议使用 ZooKeeper 实现分布式锁(推荐基于 Curator 框架实现)。不过,现在很多项目都不会用到 ZooKeeper,如果单纯是因为分布式锁而引入 ZooKeeper 的话,那是不太可取的,不建议这样做,为了一个小小的功能增加了系统的复杂度。
|
||||
|
||||
最后,再分享两篇我觉得写的还不错的文章:
|
||||
|
||||
|
|
|
|||
|
|
@ -138,7 +138,7 @@ Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)**
|
|||
|
||||
## 参考
|
||||
|
||||
- 一万字详解 Redis Cluster Gossip 协议:https://segmentfault.com/a/1190000038373546
|
||||
- 一万字详解 Redis Cluster Gossip 协议:<https://segmentfault.com/a/1190000038373546>
|
||||
- 《分布式协议与算法实战》
|
||||
- 《Redis 设计与实现》
|
||||
|
||||
|
|
|
|||
|
|
@ -77,7 +77,7 @@ Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列
|
|||
|
||||
## 参考
|
||||
|
||||
- https://zh.wikipedia.org/wiki/Paxos
|
||||
- 分布式系统中的一致性与共识算法:http://www.xuyasong.com/?p=1970
|
||||
- <https://zh.wikipedia.org/wiki/Paxos>
|
||||
- 分布式系统中的一致性与共识算法:<http://www.xuyasong.com/?p=1970>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -163,9 +163,9 @@ raft 的要求之一就是安全性不依赖于时间:系统不能仅仅因为
|
|||
|
||||
## 6 参考
|
||||
|
||||
- https://tanxinyu.work/raft/
|
||||
- https://github.com/OneSizeFitsQuorum/raft-thesis-zh_cn/blob/master/raft-thesis-zh_cn.md
|
||||
- https://github.com/ongardie/dissertation/blob/master/stanford.pdf
|
||||
- https://knowledge-sharing.gitbooks.io/raft/content/chapter5.html
|
||||
- <https://tanxinyu.work/raft/>
|
||||
- <https://github.com/OneSizeFitsQuorum/raft-thesis-zh_cn/blob/master/raft-thesis-zh_cn.md>
|
||||
- <https://github.com/ongardie/dissertation/blob/master/stanford.pdf>
|
||||
- <https://knowledge-sharing.gitbooks.io/raft/content/chapter5.html>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ tag:
|
|||
- rpc
|
||||
---
|
||||
|
||||
> 本文来自[小白 debug](https://juejin.cn/user/4001878057422087)投稿,原文:https://juejin.cn/post/7121882245605883934 。
|
||||
> 本文来自[小白 debug](https://juejin.cn/user/4001878057422087)投稿,原文:<https://juejin.cn/post/7121882245605883934> 。
|
||||
|
||||
我想起了我刚工作的时候,第一次接触 RPC 协议,当时就很懵,我 HTTP 协议用的好好的,为什么还要用 RPC 协议?
|
||||
|
||||
|
|
|
|||
|
|
@ -67,7 +67,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
|
|||
Dubbo 算的是比较优秀的国产开源项目了,它的源码也是非常值得学习和阅读的!
|
||||
|
||||
- GitHub:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo "https://github.com/apache/incubator-dubbo")
|
||||
- 官网:https://dubbo.apache.org/zh/
|
||||
- 官网:<https://dubbo.apache.org/zh/>
|
||||
|
||||
### Motan
|
||||
|
||||
|
|
|
|||
|
|
@ -63,8 +63,6 @@ category: 高可用
|
|||
|
||||
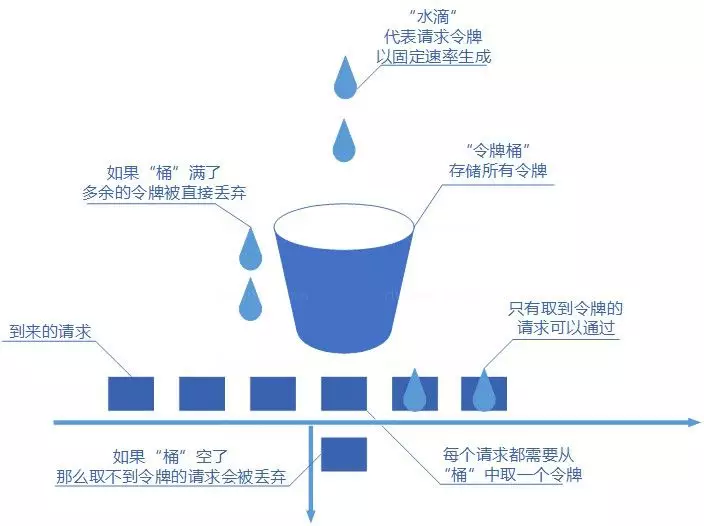
|
||||
|
||||
|
||||
|
||||
令牌桶算法可以限制平均速率和应对突然激增的流量,还可以动态调整生成令牌的速率。不过,如果令牌产生速率和桶的容量设置不合理,可能会出现问题比如大量的请求被丢弃、系统过载。
|
||||
|
||||
## 针对什么来进行限流?
|
||||
|
|
@ -228,7 +226,7 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
|
|||
|
||||

|
||||
|
||||
另外,如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码。
|
||||
另外,如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码。
|
||||
|
||||
Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,比如 Java 中常用的数据结构实现、分布式锁、延迟队列等等。并且,Redisson 还支持 Redis 单机、Redis Sentinel、Redis Cluster 等多种部署架构。
|
||||
|
||||
|
|
@ -241,7 +239,7 @@ RedissonClient redissonClient = Redisson.create();
|
|||
RRateLimiter rateLimiter = redissonClient.getRateLimiter("javaguide.limiter");
|
||||
// 尝试设置限流器的速率为每小时 100 次
|
||||
// RateType 有两种,OVERALL是全局限流,ER_CLIENT是单Client限流(可以认为就是单机限流)
|
||||
rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.HOURS);
|
||||
rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.HOURS);
|
||||
```
|
||||
|
||||
接下来我们调用`acquire()`方法或`tryAcquire()`方法即可获取许可。
|
||||
|
|
@ -249,10 +247,10 @@ rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.HOURS);
|
|||
```java
|
||||
// 获取一个许可,如果超过限流器的速率则会等待
|
||||
// acquire()是同步方法,对应的异步方法:acquireAsync()
|
||||
rateLimiter.acquire(1);
|
||||
rateLimiter.acquire(1);
|
||||
// 尝试在 5 秒内获取一个许可,如果成功则返回 true,否则返回 false
|
||||
// tryAcquire()是同步方法,对应的异步方法:tryAcquireAsync()
|
||||
boolean res = rateLimiter.tryAcquire(1, 5, TimeUnit.SECONDS);
|
||||
boolean res = rateLimiter.tryAcquire(1, 5, TimeUnit.SECONDS);
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ LMAX 公司 2010 年在 QCon 演讲后,Disruptor 获得了业界关注,并
|
|||
|
||||
> “Duke 选择大奖”旨在表彰过去一年里全球个人或公司开发的、最具影响力的 Java 技术应用,由甲骨文公司主办。含金量非常高!
|
||||
|
||||
我专门找到了 Oracle 官方当年颁布获得 Duke's Choice Awards 项目的那篇文章(文章地址:https://blogs.oracle.com/java/post/and-the-winners-arethe-dukes-choice-award) 。从文中可以看出,同年获得此大奖荣誉的还有大名鼎鼎的 Netty、JRebel 等项目。
|
||||
我专门找到了 Oracle 官方当年颁布获得 Duke's Choice Awards 项目的那篇文章(文章地址:<https://blogs.oracle.com/java/post/and-the-winners-arethe-dukes-choice-award)> 。从文中可以看出,同年获得此大奖荣誉的还有大名鼎鼎的 Netty、JRebel 等项目。
|
||||
|
||||
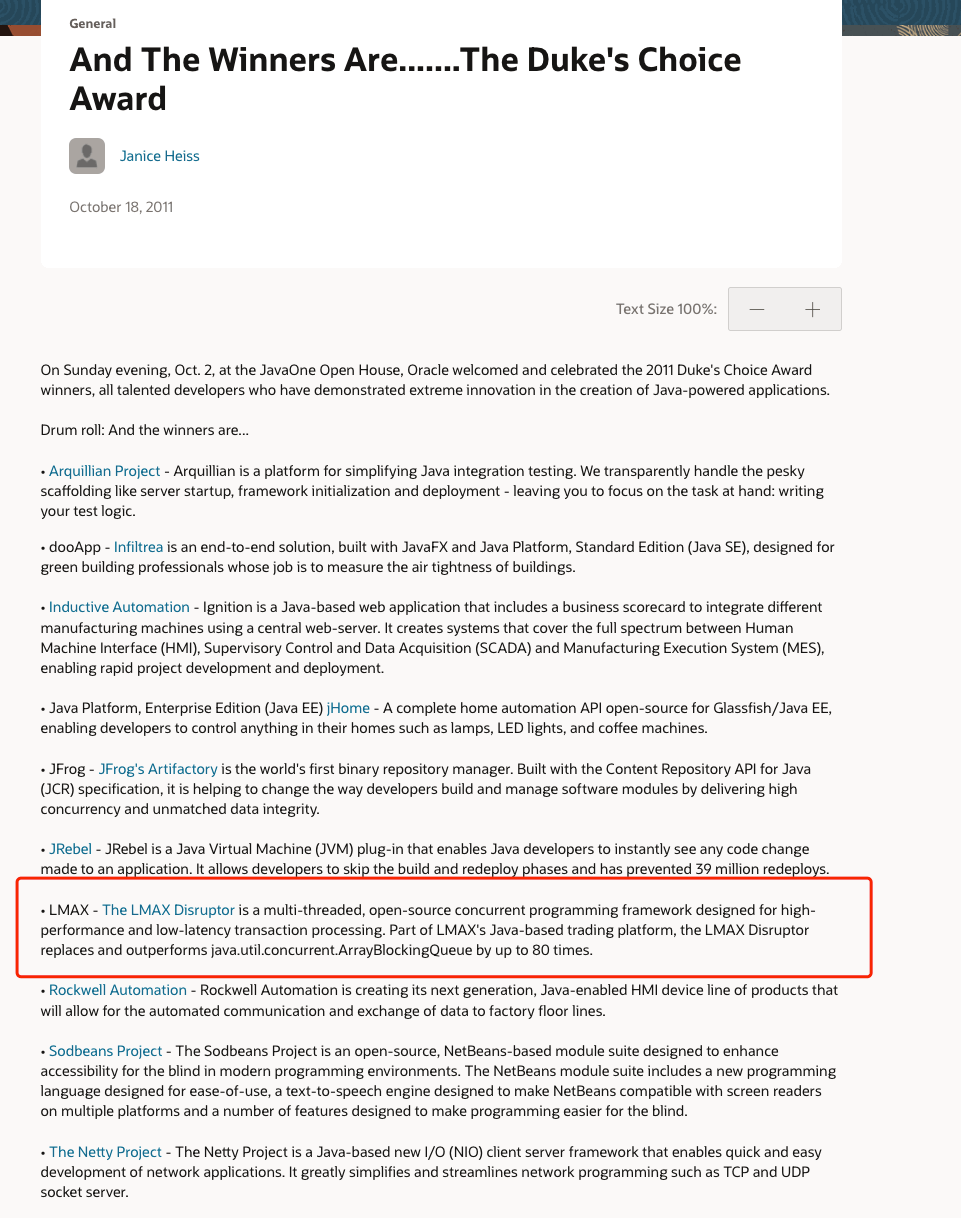
|
||||
|
||||
|
|
@ -134,7 +134,7 @@ CPU 缓存是通过将最近使用的数据存储在高速缓存中来实现更
|
|||
|
||||
## 参考
|
||||
|
||||
- Disruptor 高性能之道-等待策略:<http://wuwenliang.net/2022/02/28/Disruptor 高性能之道-等待策略/>
|
||||
- Disruptor 高性能之道-等待策略:<<http://wuwenliang.net/2022/02/28/Disruptor> 高性能之道-等待策略/>
|
||||
- 《Java 并发编程实战》- 40 | 案例分析(三):高性能队列 Disruptor:<https://time.geekbang.org/column/article/98134>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -99,7 +99,7 @@ Kafka 将生产者发布的消息发送到 **Topic(主题)** 中,需要这
|
|||
|
||||
### Zookeeper 在 Kafka 中的作用是什么?
|
||||
|
||||
> 要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一个 Kafka 环境然后自己进 zookeeper 去看一下有哪些文件夹和 Kafka 有关,每个节点又保存了什么信息。 一定不要光看不实践,这样学来的也终会忘记!这部分内容参考和借鉴了这篇文章:https://www.jianshu.com/p/a036405f989c 。
|
||||
> 要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一个 Kafka 环境然后自己进 zookeeper 去看一下有哪些文件夹和 Kafka 有关,每个节点又保存了什么信息。 一定不要光看不实践,这样学来的也终会忘记!这部分内容参考和借鉴了这篇文章:<https://www.jianshu.com/p/a036405f989c> 。
|
||||
|
||||
下图就是我的本地 Zookeeper ,它成功和我本地的 Kafka 关联上(以下文件夹结构借助 idea 插件 Zookeeper tool 实现)。
|
||||
|
||||
|
|
@ -120,7 +120,7 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
|
|||
|
||||
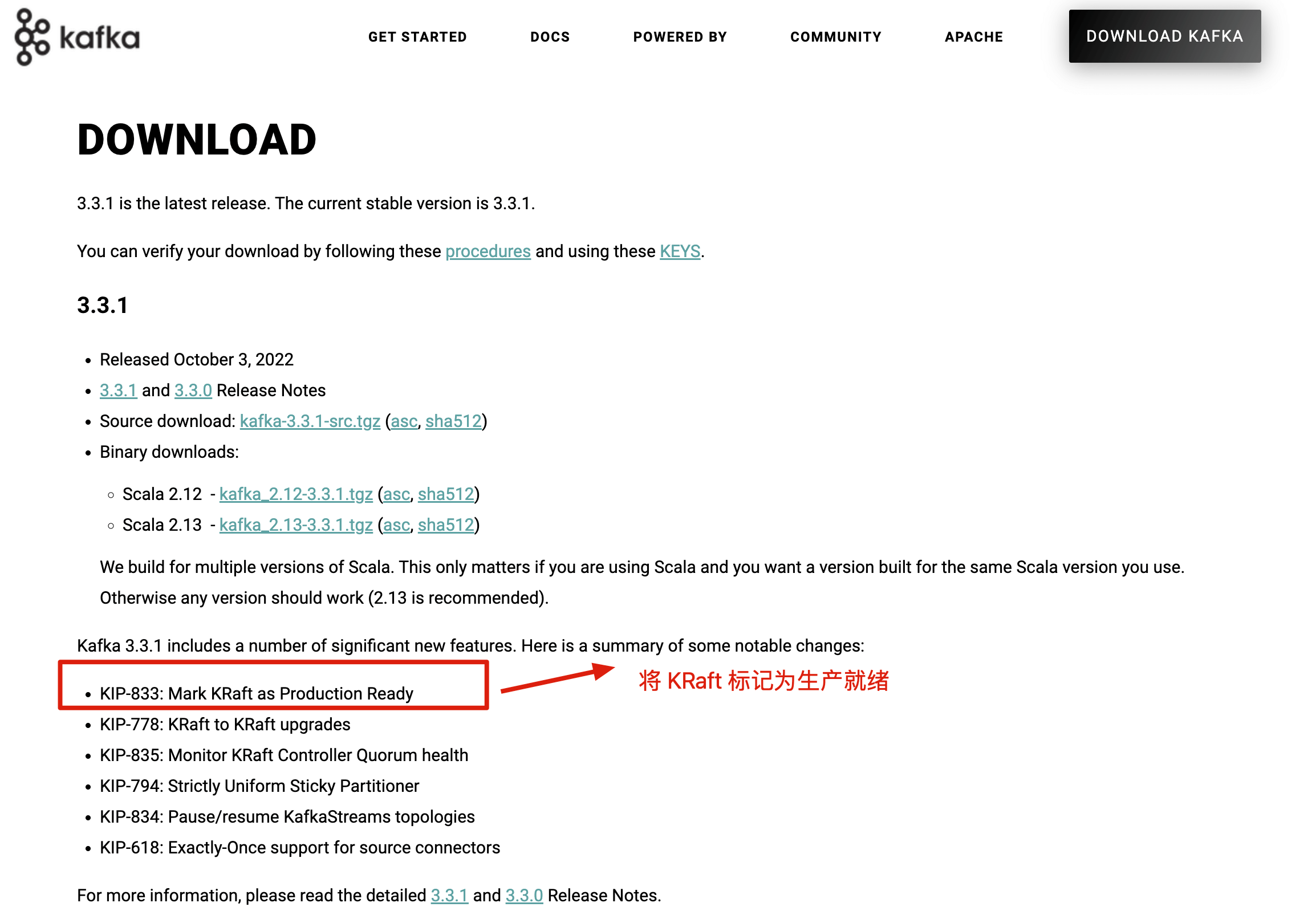
不过,要提示一下:**如果要使用 KRaft 模式的话,建议选择较高版本的 Kafka,因为这个功能还在持续完善优化中。Kafka 3.3.1 版本是第一个将 KRaft(Kafka Raft)共识协议标记为生产就绪的版本。**
|
||||
|
||||
|
||||

|
||||
|
||||
## Kafka 消费顺序、消息丢失和重复消费
|
||||
|
||||
|
|
@ -435,7 +435,7 @@ private void customer(String message) {
|
|||
|
||||
## 参考
|
||||
|
||||
- Kafka 官方文档:https://kafka.apache.org/documentation/
|
||||
- Kafka 官方文档:<https://kafka.apache.org/documentation/>
|
||||
- 极客时间—《Kafka 核心技术与实战》第 11 节:无消息丢失配置怎么实现?
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -35,7 +35,7 @@ tag:
|
|||
|
||||
除了消息队列之外,常见的中间件还有 RPC 框架、分布式组件、HTTP 服务器、任务调度框架、配置中心、数据库层的分库分表工具和数据迁移工具等等。
|
||||
|
||||
关于中间件比较详细的介绍可以参考阿里巴巴淘系技术的一篇回答:https://www.zhihu.com/question/19730582/answer/1663627873 。
|
||||
关于中间件比较详细的介绍可以参考阿里巴巴淘系技术的一篇回答:<https://www.zhihu.com/question/19730582/answer/1663627873> 。
|
||||
|
||||
随着分布式和微服务系统的发展,消息队列在系统设计中有了更大的发挥空间,使用消息队列可以降低系统耦合性、实现任务异步、有效地进行流量削峰,是分布式和微服务系统中重要的组件之一。
|
||||
|
||||
|
|
@ -184,9 +184,9 @@ Kafka 是一个分布式系统,由通过高性能 TCP 网络协议进行通信
|
|||
|
||||

|
||||
|
||||
Kafka 官网:http://kafka.apache.org/
|
||||
Kafka 官网:<http://kafka.apache.org/>
|
||||
|
||||
Kafka 更新记录(可以直观看到项目是否还在维护):https://kafka.apache.org/downloads
|
||||
Kafka 更新记录(可以直观看到项目是否还在维护):<https://kafka.apache.org/downloads>
|
||||
|
||||
#### RocketMQ
|
||||
|
||||
|
|
@ -207,9 +207,9 @@ RocketMQ 的核心特性(摘自 RocketMQ 官网):
|
|||
|
||||
> Apache RocketMQ 自诞生以来,因其架构简单、业务功能丰富、具备极强可扩展性等特点被众多企业开发者以及云厂商广泛采用。历经十余年的大规模场景打磨,RocketMQ 已经成为业内共识的金融级可靠业务消息首选方案,被广泛应用于互联网、大数据、移动互联网、物联网等领域的业务场景。
|
||||
|
||||
RocketMQ 官网:https://rocketmq.apache.org/ (文档很详细,推荐阅读)
|
||||
RocketMQ 官网:<https://rocketmq.apache.org/> (文档很详细,推荐阅读)
|
||||
|
||||
RocketMQ 更新记录(可以直观看到项目是否还在维护):https://github.com/apache/rocketmq/releases
|
||||
RocketMQ 更新记录(可以直观看到项目是否还在维护):<https://github.com/apache/rocketmq/releases>
|
||||
|
||||
#### RabbitMQ
|
||||
|
||||
|
|
@ -228,9 +228,9 @@ RabbitMQ 发展到今天,被越来越多的人认可,这和它在易用性
|
|||
- **易用的管理界面:** RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等。在安装 RabbitMQ 的时候会介绍到,安装好 RabbitMQ 就自带管理界面。
|
||||
- **插件机制:** RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件。感觉这个有点类似 Dubbo 的 SPI 机制
|
||||
|
||||
RabbitMQ 官网:https://www.rabbitmq.com/ 。
|
||||
RabbitMQ 官网:<https://www.rabbitmq.com/> 。
|
||||
|
||||
RabbitMQ 更新记录(可以直观看到项目是否还在维护):https://www.rabbitmq.com/news.html
|
||||
RabbitMQ 更新记录(可以直观看到项目是否还在维护):<https://www.rabbitmq.com/news.html>
|
||||
|
||||
#### Pulsar
|
||||
|
||||
|
|
@ -253,9 +253,9 @@ Pulsar 的关键特性如下(摘自官网):
|
|||
- 基于 Pulsar Functions 的 serverless connector 框架 Pulsar IO 使得数据更易移入、移出 Apache Pulsar。
|
||||
- 分层式存储可在数据陈旧时,将数据从热存储卸载到冷/长期存储(如 S3、GCS)中。
|
||||
|
||||
Pulsar 官网:https://pulsar.apache.org/
|
||||
Pulsar 官网:<https://pulsar.apache.org/>
|
||||
|
||||
Pulsar 更新记录(可以直观看到项目是否还在维护):https://github.com/apache/pulsar/releases
|
||||
Pulsar 更新记录(可以直观看到项目是否还在维护):<https://github.com/apache/pulsar/releases>
|
||||
|
||||
#### ActiveMQ
|
||||
|
||||
|
|
@ -284,7 +284,7 @@ Pulsar 更新记录(可以直观看到项目是否还在维护):https://gi
|
|||
## 参考
|
||||
|
||||
- 《大型网站技术架构 》
|
||||
- KRaft: Apache Kafka Without ZooKeeper:https://developer.confluent.io/learn/kraft/
|
||||
- 消息队列的使用场景是什么样的?:https://mp.weixin.qq.com/s/4V1jI6RylJr7Jr9JsQe73A
|
||||
- KRaft: Apache Kafka Without ZooKeeper:<https://developer.confluent.io/learn/kraft/>
|
||||
- 消息队列的使用场景是什么样的?:<https://mp.weixin.qq.com/s/4V1jI6RylJr7Jr9JsQe73A>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -431,7 +431,7 @@ RocketMQ 服务端 5.x 版本开始,**生产者是匿名的**,无需管理
|
|||
|
||||
RocketMQ 服务端 5.x 版本:上述消费者的消费行为从关联的消费者分组中统一获取,因此,同一分组内所有消费者的消费行为必然是一致的,客户端无需关注。
|
||||
|
||||
RocketMQ 服务端 3.x/4.x 历史版本:上述消费逻辑由消费者客户端接口定义,因此,您需要自己在消费者客户端设置时保证同一分组下的消费者的消费行为一致。[来自官方网站]
|
||||
RocketMQ 服务端 3.x/4.x 历史版本:上述消费逻辑由消费者客户端接口定义,因此,您需要自己在消费者客户端设置时保证同一分组下的消费者的消费行为一致。(来自官方网站)
|
||||
|
||||
## 如何解决顺序消费和重复消费?
|
||||
|
||||
|
|
@ -543,6 +543,7 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
|||
实践中会遇到的问题:事务消息需要一个事务监听器来监听本地事务是否成功,并且事务监听器接口只允许被实现一次。那就意味着需要把各种事务消息的本地事务都写在一个接口方法里面,必将会产生大量的耦合和类型判断。采用函数 Function 接口来包装整个业务过程,作为一个参数传递到监听器的接口方法中。再调用 Function 的 apply() 方法来执行业务,事务也会在 apply() 方法中执行。让监听器与业务之间实现解耦,使之具备了真实生产环境中的可行性。
|
||||
|
||||
1.模拟一个添加用户浏览记录的需求
|
||||
|
||||
```java
|
||||
@PostMapping("/add")
|
||||
@ApiOperation("添加用户浏览记录")
|
||||
|
|
@ -563,6 +564,7 @@ public Result<TransactionSendResult> add(Long userId, Long forecastLogId) {
|
|||
```
|
||||
|
||||
2.发送事务消息的方法
|
||||
|
||||
```java
|
||||
/**
|
||||
* 发送事务消息
|
||||
|
|
@ -585,6 +587,7 @@ public TransactionSendResult sendTransactionMessage(String msgBody, String tag,
|
|||
```
|
||||
|
||||
3.生产者消息监听器,只允许一个类去实现该监听器
|
||||
|
||||
```java
|
||||
@Slf4j
|
||||
@RocketMQTransactionListener
|
||||
|
|
@ -651,6 +654,7 @@ public class TransactionMsgListener implements RocketMQLocalTransactionListener
|
|||
```
|
||||
|
||||
4.模拟的业务场景,这里的方法必须提取出来,放在别的类里面.如果调用方与被调用方在同一个类中,会发生事务失效的问题.
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class ViewHistoryHandler {
|
||||
|
|
@ -700,7 +704,9 @@ public class ViewHistoryHandler {
|
|||
}
|
||||
}
|
||||
```
|
||||
|
||||
5.消费消息,以及幂等处理
|
||||
|
||||
```java
|
||||
@Service
|
||||
@RocketMQMessageListener(topic = MQDestination.TOPIC, selectorExpression = MQDestination.TAG_ADD_VIEW_HISTORY, consumerGroup = MQDestination.TAG_ADD_VIEW_HISTORY)
|
||||
|
|
|
|||
|
|
@ -8,8 +8,6 @@ tag:
|
|||
|
||||
> **推荐语**:Kaito 大佬的一篇文章,很实用的建议!
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址:** <https://mp.weixin.qq.com/s/6hUU6SZsxGPWAIIByq93Rw>
|
||||
|
||||
我想你肯定遇到过这样一类程序员:**他们无论是写代码,还是写文档,又或是和别人沟通,都显得特别专业**。每次遇到这类人,我都在想,他们到底是怎么做到的?
|
||||
|
|
|
|||
|
|
@ -8,8 +8,6 @@ tag:
|
|||
|
||||
> **推荐语**:作者用了很多生动的例子和故事展示了自己在美团的成长和感悟,看了之后受益颇多!
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **内容概览**:
|
||||
>
|
||||
> 本文的作者提出了以下十条建议,希望能对其他职场人有所启发和帮助:
|
||||
|
|
@ -171,4 +169,4 @@ tag:
|
|||
|
||||
## 最后
|
||||
|
||||
写到最后,特别感恩美团三年多的经历。感谢我的 Leader 们,感谢曾经并肩作战过的小伙伴,感谢遇到的每一位和我一样在平凡的岗位,努力想带给身边一片微光的同学。所有的相遇,都是缘分。
|
||||
写到最后,特别感恩美团三年多的经历。感谢我的 Leader 们,感谢曾经并肩作战过的小伙伴,感谢遇到的每一位和我一样在平凡的岗位,努力想带给身边一片微光的同学。所有的相遇,都是缘分。
|
||||
|
|
|
|||
|
|
@ -29,7 +29,7 @@ tag:
|
|||
|
||||
如果你看不太懂官网的文档,你也可以搜索相关的关键词找一些高质量的博客或者视频来看。 **一定不要一上来就想着要搞懂这个技术的原理。**
|
||||
|
||||
就比如说我们在学习 Spring 框架的时候,我建议你在搞懂 Spring 框架所解决的问题之后,不是直接去开始研究 Spring 框架的原理或者源码,而是先实际去体验一下 Spring 框架提供的核心功能 IoC(Inverse of Control:控制反转) 和 AOP(Aspect-Oriented Programming:面向切面编程),使用 Spring 框架写一些 Demo,甚至是使用 Spring 框架做一些小项目。
|
||||
就比如说我们在学习 Spring 框架的时候,我建议你在搞懂 Spring 框架所解决的问题之后,不是直接去开始研究 Spring 框架的原理或者源码,而是先实际去体验一下 Spring 框架提供的核心功能 IoC(Inverse of Control:控制反转) 和 AOP(Aspect-Oriented Programming:面向切面编程),使用 Spring 框架写一些 Demo,甚至是使用 Spring 框架做一些小项目。
|
||||
|
||||
一言以蔽之, **在研究这个技术的原理之前,先要搞懂这个技术是怎么使用的。**
|
||||
|
||||
|
|
@ -48,4 +48,3 @@ tag:
|
|||
很多人一提到八股文,就是一脸不屑。在我看来,如果你不是死记硬背八股文,而是去所思考这些面试题的本质。那你在准备八股文的过程中,同样也能让你加深对这项技术的了解。
|
||||
|
||||
最后,最重要同时也是最难的还是 **知行合一!知行合一!知行合一!** 不论是编程还是其他领域,最重要不是你知道的有多少,而是要尽量做到知行合一。
|
||||
|
||||
|
|
|
|||
|
|
@ -8,8 +8,6 @@ tag:
|
|||
|
||||
> **推荐语**:普通程序员要想成长为高级程序员甚至是专家等更高级别,应该注意在哪些方面注意加强?开发内功修炼号主飞哥在这篇文章中就给出了七条实用的建议。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **内容概览**:
|
||||
>
|
||||
> 1. 刻意加强需求评审能力
|
||||
|
|
|
|||
|
|
@ -8,8 +8,6 @@ tag:
|
|||
|
||||
> **推荐语**:这篇文章的作者有着丰富的工作经验,曾在大厂工作了 12 年。结合自己走过的弯路和接触过的优秀技术人,他总结出了一些对于个人成长具有普遍指导意义的经验和特质。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址:** <https://mp.weixin.qq.com/s/vIIRxznpRr5yd6IVyNUW2w>
|
||||
|
||||
最近这段时间,有好几个年轻的同学和我聊到自己的迷茫。其中有关于技术成长的、有关于晋升的、有关于择业的。我很高兴他们愿意听我这个“过来人”分享自己的经验。
|
||||
|
|
|
|||
|
|
@ -8,8 +8,6 @@ tag:
|
|||
|
||||
> **推荐语**:波波老师的一篇文章,写的非常好,不光是对技术成长有帮助,其他领域也是同样适用的!建议反复阅读,形成一套自己的技术成长策略。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址:** <https://mp.weixin.qq.com/s/YrN8T67s801-MRo01lCHXA>
|
||||
|
||||
## 1. 前言
|
||||
|
|
|
|||
|
|
@ -8,8 +8,6 @@ tag:
|
|||
|
||||
> **推荐语**:这是我在两年前看到的一篇对我触动比较深的文章。确实要学会适应变化,并积累能力。积累解决问题的能力,优化思考方式,拓宽自己的认知。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址:** <https://mp.weixin.qq.com/s/CTbEdi0F4-qFoJT05kNlXA>
|
||||
|
||||
苦海无边,回头无岸。
|
||||
|
|
|
|||
|
|
@ -8,17 +8,13 @@ tag:
|
|||
|
||||
> **推荐语**:从面试官和面试者两个角度探讨了技术面试!非常不错!
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **内容概览:**
|
||||
>
|
||||
> - 实战与理论结合。比如,候选人叙述 JVM 内存模型布局之后,可以接着问:有哪些原因可能会导致 OOM , 有哪些预防措施? 你是否遇到过内存泄露的问题? 如何排查和解决这类问题?
|
||||
> - 项目经历考察不宜超过两个。因为要深入考察一个项目的详情,所占用的时间还是比较大的。一般来说,会让候选人挑选一个他或她觉得最有收获的/最有挑战的/印象最深刻的/自己觉得特有意思的项目。然后围绕这个项目进行发问。通常是从项目背景出发,考察项目的技术栈、项目模块及交互的整体理解、项目中遇到的有挑战性的技术问题及解决方案、排查和解决问题、代码可维护性问题、工程质量保障等。
|
||||
> - 多问少说,让候选者多表现。根据候选者的回答适当地引导或递进或横向移动。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://www.cnblogs.com/lovesqcc/p/15169365.html
|
||||
> **原文地址**:<https://www.cnblogs.com/lovesqcc/p/15169365.html>
|
||||
|
||||
## 灵魂三连问
|
||||
|
||||
|
|
|
|||
|
|
@ -8,9 +8,7 @@ tag:
|
|||
|
||||
> **推荐语**:这篇文章的作者校招最终去了飞书做开发。在这篇文章中,他分享了自己的校招经历以及个人经验。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://www.ihewro.com/archives/1217/
|
||||
> **原文地址**:<https://www.ihewro.com/archives/1217/>
|
||||
|
||||
## 基本情况
|
||||
|
||||
|
|
|
|||
|
|
@ -8,9 +8,7 @@ tag:
|
|||
|
||||
> **推荐语**:经常听到培训班待过的朋友给我说他们的老师是怎么教他们“包装”自己的,不光是培训班,我认识的很多朋友也都会在面试之前“包装”一下自己,所以这个现象是普遍存在的。但是面试官也不都是傻子,通过下面这篇文章来看看面试官是如何甄别应聘者的包装程度。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://my.oschina.net/hooker/blog/3014656
|
||||
> **原文地址**:<https://my.oschina.net/hooker/blog/3014656>
|
||||
|
||||
## 前言
|
||||
|
||||
|
|
|
|||
|
|
@ -8,9 +8,7 @@ tag:
|
|||
|
||||
> **推荐语**:详细介绍了求职者在面试中应该具备哪些能力才会有更大概率脱颖而出。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址:** https://mp.weixin.qq.com/s/M2M808PwQ2JcMqfLQfXQMw
|
||||
> **原文地址:** <https://mp.weixin.qq.com/s/M2M808PwQ2JcMqfLQfXQMw>
|
||||
|
||||
最近我的工作稍微轻松些,就被安排去校招面试了
|
||||
|
||||
|
|
|
|||
|
|
@ -8,11 +8,7 @@ tag:
|
|||
|
||||
> **推荐语**:牛客网热帖,写的很全面!暑期实习,投了阿里、腾讯、字节,拿到了阿里和腾讯的 offer。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址:** https://www.nowcoder.com/discuss/640519
|
||||
>
|
||||
> <br/>
|
||||
> **原文地址:** <https://www.nowcoder.com/discuss/640519>
|
||||
>
|
||||
> **下篇**:[十年饮冰,难凉热血——秋招总结](https://www.nowcoder.com/discuss/804679)
|
||||
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ tag:
|
|||
> - 项目经历考察不宜超过两个。因为要深入考察一个项目的详情,所占用的时间还是比较大的。一般来说,会让候选人挑选一个他或她觉得最有收获的/最有挑战的/印象最深刻的/自己觉得特有意思的项目。然后围绕这个项目进行发问。通常是从项目背景出发,考察项目的技术栈、项目模块及交互的整体理解、项目中遇到的有挑战性的技术问题及解决方案、排查和解决问题、代码可维护性问题、工程质量保障等。
|
||||
> - 多问少说,让候选者多表现。根据候选者的回答适当地引导或递进或横向移动。
|
||||
>
|
||||
> **原文地址:** https://www.cnblogs.com/lovesqcc/p/15169365.html
|
||||
> **原文地址:** <https://www.cnblogs.com/lovesqcc/p/15169365.html>
|
||||
|
||||
## 考察目标和思路
|
||||
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@ tag:
|
|||
> 5. 要善于从失败中学习。正是在杭州四个月空档期的持续学习、思考、积累和提炼,以及面试失败的反思、不断调整对策、完善准备、改善原有的短板,采取更为合理的方式,才在回武汉的短短两个周内拿到比较满意的 offer 。
|
||||
> 6. 面试是通过沟通来理解双方的过程。面试中的问题,千变万化,但有一些问题是需要提前准备好的。
|
||||
>
|
||||
> **原文地址**:https://www.cnblogs.com/lovesqcc/p/14354921.html
|
||||
> **原文地址**:<https://www.cnblogs.com/lovesqcc/p/14354921.html>
|
||||
|
||||
从每一段经历中学习,在每一件事情中修行。善于从挫折中学习。
|
||||
|
||||
|
|
|
|||
|
|
@ -8,9 +8,7 @@ tag:
|
|||
|
||||
> **推荐语**:很实用的面试经验分享!
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://mp.weixin.qq.com/s/HXKg6-H0kGUU2OA1DS43Bw
|
||||
> **原文地址**:<https://mp.weixin.qq.com/s/HXKg6-H0kGUU2OA1DS43Bw>
|
||||
|
||||
突然回想起当年,我也在秋招时也斩获了 20+的互联网各大厂 offer。现在想起来也是有点唏嘘,毕竟拿得再多也只能选择一家。不过许多朋友想让我分享下互联网面试方法,今天就来给大家仔细讲讲打法!
|
||||
|
||||
|
|
|
|||
|
|
@ -8,9 +8,7 @@ tag:
|
|||
|
||||
> **推荐语**:这篇文章讲述了一位中科大的朋友 8 年的经历:从 2013 年毕业之后加入上海航天 x 院某卫星研究所,再到入职华为,从华为离职。除了丰富的经历之外,作者在文章还给出了很多自己对于工作/生活的思考。我觉得非常受用!我在这里,向这位作者表达一下衷心的感谢。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://www.cnblogs.com/scada/p/14259332.html
|
||||
> **原文地址**:<https://www.cnblogs.com/scada/p/14259332.html>
|
||||
|
||||
---
|
||||
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ tag:
|
|||
|
||||
**下文中的“我”,指这位作者本人。**
|
||||
|
||||
> 原文地址:https://zhuanlan.zhihu.com/p/602517682
|
||||
> 原文地址:<https://zhuanlan.zhihu.com/p/602517682>
|
||||
|
||||
研究生毕业后, 一直在腾讯工作,不知不觉就过了四年。个人本身没有刻意总结的习惯,以前只顾着往前奔跑了,忘了停下来思考总结。记得看过一个职业规划文档,说的三年一个阶段,五年一个阶段的说法,现在恰巧是四年,同时又从腾讯离开,该做一个总结了。
|
||||
|
||||
|
|
|
|||
|
|
@ -7,9 +7,7 @@ tag:
|
|||
|
||||
> **推荐语**:一位朋友的华为 OD 工作经历以及腾讯面试经历分享,内容很不错。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://www.cnblogs.com/shoufeng/p/14322931.html
|
||||
> **原文地址**:<https://www.cnblogs.com/shoufeng/p/14322931.html>
|
||||
|
||||
## 时间线
|
||||
|
||||
|
|
@ -94,7 +92,7 @@ d) 你的加班一定要提加班申请电子流换 Double 薪资,不然只能
|
|||
|
||||
**答案是:真的。**
|
||||
|
||||
据各类非官方渠道(比如知乎上的一些分享),转华为自有是有条件的(https://www.zhihu.com/question/356592219/answer/1562692667):
|
||||
据各类非官方渠道(比如知乎上的一些分享),转华为自有是有条件的(<https://www.zhihu.com/question/356592219/answer/1562692667>):
|
||||
|
||||
1)入职时间:一年以上
|
||||
2)绩效要求:连续两次绩效 A
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@ tag:
|
|||
> - 平时积极总结沉淀,多跟别人交流,形成方法论。
|
||||
> - ……
|
||||
>
|
||||
> **原文地址**:https://www.nowcoder.com/discuss/351805
|
||||
> **原文地址**:<https://www.nowcoder.com/discuss/351805>
|
||||
|
||||
先简单交代一下背景吧,某不知名 985 的本硕,17 年毕业加入滴滴,当时找工作时候也是在牛客这里跟大家一起奋战的。今年下半年跳槽到了头条,一直从事后端研发相关的工作。之前没有实习经历,算是两年半的工作经验吧。这两年半之间完成了一次晋升,换了一家公司,有过开心满足的时光,也有过迷茫挣扎的日子,不过还算顺利地从一只职场小菜鸟转变为了一名资深划水员。在这个过程中,总结出了一些还算实用的划水经验,有些是自己领悟到的,有些是跟别人交流学到的,在这里跟大家分享一下。
|
||||
|
||||
|
|
|
|||
|
|
@ -8,9 +8,7 @@ tag:
|
|||
|
||||
> **推荐语**:详细介绍了程序员出书的一些常见问题,强烈建议有出书想法的朋友看看这篇文章。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://www.cnblogs.com/JavaArchitect/p/14128202.html
|
||||
> **原文地址**:<https://www.cnblogs.com/JavaArchitect/p/14128202.html>
|
||||
|
||||
古有三不朽, 所谓立德、立功、立言。程序员出一本属于自己的书,如果说是立言,可能过于高大上,但终究也算一件雅事。
|
||||
|
||||
|
|
|
|||
|
|
@ -8,9 +8,7 @@ tag:
|
|||
|
||||
> **推荐语**:详细介绍了程序员应该如何从头开始出一本自己的书籍。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://www.cnblogs.com/JavaArchitect/p/12195219.html
|
||||
> **原文地址**:<https://www.cnblogs.com/JavaArchitect/p/12195219.html>
|
||||
|
||||
在面试或联系副业的时候,如果能令人信服地证明自己的实力,那么很有可能事半功倍。如何证明自己的实力?最有信服力的是大公司职位背景背书,没有之一,比如在 BAT 担任资深架构,那么其它话甚至都不用讲了。
|
||||
|
||||
|
|
|
|||
|
|
@ -13,9 +13,7 @@ tag:
|
|||
> - 短期打法:找出 1-2 件事,体现出你的独特价值(抓关键事件)。
|
||||
> - 长期打法:通过一步步信任的建立,成为团队的核心人员或者是老板的心腹,具备不可替代性。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://mp.weixin.qq.com/s/D1s8p7z8Sp60c-ndGyh2yQ
|
||||
> **原文地址**:<https://mp.weixin.qq.com/s/D1s8p7z8Sp60c-ndGyh2yQ>
|
||||
|
||||
在新公司度过了一个完整的 Q3 季度,被打了绩效,也给下属打了绩效,感慨颇深。
|
||||
|
||||
|
|
|
|||
|
|
@ -7,9 +7,7 @@ tag:
|
|||
|
||||
> **推荐语**:强烈建议每一位即将入职/在职的小伙伴看看这篇文章,看完之后可以帮助你少踩很多坑。整篇文章逻辑清晰,内容全面!
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址**:https://www.cnblogs.com/hunternet/p/14675348.html
|
||||
> **原文地址**:<https://www.cnblogs.com/hunternet/p/14675348.html>
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -101,19 +101,19 @@ public BigDecimal divide(BigDecimal divisor, int scale, RoundingMode roundingMod
|
|||
public enum RoundingMode {
|
||||
// 2.5 -> 3 , 1.6 -> 2
|
||||
// -1.6 -> -2 , -2.5 -> -3
|
||||
UP(BigDecimal.ROUND_UP),
|
||||
UP(BigDecimal.ROUND_UP),
|
||||
// 2.5 -> 2 , 1.6 -> 1
|
||||
// -1.6 -> -1 , -2.5 -> -2
|
||||
DOWN(BigDecimal.ROUND_DOWN),
|
||||
// 2.5 -> 3 , 1.6 -> 2
|
||||
DOWN(BigDecimal.ROUND_DOWN),
|
||||
// 2.5 -> 3 , 1.6 -> 2
|
||||
// -1.6 -> -1 , -2.5 -> -2
|
||||
CEILING(BigDecimal.ROUND_CEILING),
|
||||
// 2.5 -> 2 , 1.6 -> 1
|
||||
CEILING(BigDecimal.ROUND_CEILING),
|
||||
// 2.5 -> 2 , 1.6 -> 1
|
||||
// -1.6 -> -2 , -2.5 -> -3
|
||||
FLOOR(BigDecimal.ROUND_FLOOR),
|
||||
// 2.5 -> 3 , 1.6 -> 2
|
||||
FLOOR(BigDecimal.ROUND_FLOOR),
|
||||
// 2.5 -> 3 , 1.6 -> 2
|
||||
// -1.6 -> -2 , -2.5 -> -3
|
||||
HALF_UP(BigDecimal.ROUND_HALF_UP),
|
||||
HALF_UP(BigDecimal.ROUND_HALF_UP),
|
||||
//......
|
||||
}
|
||||
```
|
||||
|
|
|
|||
|
|
@ -29,7 +29,7 @@ head:
|
|||
9. 编译与解释并存;
|
||||
10. ……
|
||||
|
||||
> **🐛 修正(参见:[issue#544](https://github.com/Snailclimb/JavaGuide/issues/544))**:C++11 开始(2011 年的时候),C++就引入了多线程库,在 windows、linux、macos 都可以使用`std::thread`和`std::async`来创建线程。参考链接:http://www.cplusplus.com/reference/thread/thread/?kw=thread
|
||||
> **🐛 修正(参见:[issue#544](https://github.com/Snailclimb/JavaGuide/issues/544))**:C++11 开始(2011 年的时候),C++就引入了多线程库,在 windows、linux、macos 都可以使用`std::thread`和`std::async`来创建线程。参考链接:<http://www.cplusplus.com/reference/thread/thread/?kw=thread>
|
||||
|
||||
🌈 拓展一下:
|
||||
|
||||
|
|
@ -166,9 +166,9 @@ JDK 9 引入了一种新的编译模式 **AOT(Ahead of Time Compilation)** 。
|
|||
>
|
||||
> 答:
|
||||
>
|
||||
> 1. OpenJDK 是开源的,开源意味着你可以对它根据你自己的需要进行修改、优化,比如 Alibaba 基于 OpenJDK 开发了 Dragonwell8:[https://github.com/alibaba/dragonwell8](https://github.com/alibaba/dragonwell8)
|
||||
> 2. OpenJDK 是商业免费的(这也是为什么通过 yum 包管理器上默认安装的 JDK 是 OpenJDK 而不是 Oracle JDK)。虽然 Oracle JDK 也是商业免费(比如 JDK 8),但并不是所有版本都是免费的。
|
||||
> 3. OpenJDK 更新频率更快。Oracle JDK 一般是每 6 个月发布一个新版本,而 OpenJDK 一般是每 3 个月发布一个新版本。(现在你知道为啥 Oracle JDK 更稳定了吧,先在 OpenJDK 试试水,把大部分问题都解决掉了才在 Oracle JDK 上发布)
|
||||
> 1. OpenJDK 是开源的,开源意味着你可以对它根据你自己的需要进行修改、优化,比如 Alibaba 基于 OpenJDK 开发了 Dragonwell8:[https://github.com/alibaba/dragonwell8](https://github.com/alibaba/dragonwell8)
|
||||
> 2. OpenJDK 是商业免费的(这也是为什么通过 yum 包管理器上默认安装的 JDK 是 OpenJDK 而不是 Oracle JDK)。虽然 Oracle JDK 也是商业免费(比如 JDK 8),但并不是所有版本都是免费的。
|
||||
> 3. OpenJDK 更新频率更快。Oracle JDK 一般是每 6 个月发布一个新版本,而 OpenJDK 一般是每 3 个月发布一个新版本。(现在你知道为啥 Oracle JDK 更稳定了吧,先在 OpenJDK 试试水,把大部分问题都解决掉了才在 Oracle JDK 上发布)
|
||||
>
|
||||
> 基于以上这些原因,OpenJDK 还是有存在的必要的!
|
||||
|
||||
|
|
@ -1056,9 +1056,9 @@ public class VariableLengthArgument {
|
|||
|
||||
## 参考
|
||||
|
||||
- What is the difference between JDK and JRE?:https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre
|
||||
- Oracle vs OpenJDK:https://www.educba.com/oracle-vs-openjdk/
|
||||
- Differences between Oracle JDK and OpenJDK:https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk
|
||||
- 彻底弄懂 Java 的移位操作符:https://juejin.cn/post/6844904025880526861
|
||||
- What is the difference between JDK and JRE?:<https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre>
|
||||
- Oracle vs OpenJDK:<https://www.educba.com/oracle-vs-openjdk/>
|
||||
- Differences between Oracle JDK and OpenJDK:<https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk>
|
||||
- 彻底弄懂 Java 的移位操作符:<https://juejin.cn/post/6844904025880526861>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -431,8 +431,8 @@ public boolean equals(Object anObject) {
|
|||
|
||||
> ⚠️ 注意:该方法在 **Oracle OpenJDK8** 中默认是 "使用线程局部状态来实现 Marsaglia's xor-shift 随机数生成", 并不是 "地址" 或者 "地址转换而来", 不同 JDK/VM 可能不同在 **Oracle OpenJDK8** 中有六种生成方式 (其中第五种是返回地址), 通过添加 VM 参数: -XX:hashCode=4 启用第五种。参考源码:
|
||||
>
|
||||
> - https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/globals.hpp(1127 行)
|
||||
> - https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/synchronizer.cpp(537 行开始)
|
||||
> - <https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/globals.hpp(1127> 行)
|
||||
> - <https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/synchronizer.cpp(537> 行开始)
|
||||
|
||||
```java
|
||||
public native int hashCode();
|
||||
|
|
@ -509,7 +509,7 @@ abstract class AbstractStringBuilder implements Appendable, CharSequence {
|
|||
count += len;
|
||||
return this;
|
||||
}
|
||||
//...
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -534,7 +534,7 @@ abstract class AbstractStringBuilder implements Appendable, CharSequence {
|
|||
```java
|
||||
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
|
||||
private final char value[];
|
||||
//...
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -572,7 +572,7 @@ public final class String implements java.io.Serializable, Comparable<String>, C
|
|||
>
|
||||
> 如果字符串中包含的汉字超过 Latin-1 可表示范围内的字符,`byte` 和 `char` 所占用的空间是一样的。
|
||||
>
|
||||
> 这是官方的介绍:https://openjdk.java.net/jeps/254 。
|
||||
> 这是官方的介绍:<https://openjdk.java.net/jeps/254> 。
|
||||
|
||||
### 字符串拼接用“+” 还是 StringBuilder?
|
||||
|
||||
|
|
@ -782,6 +782,6 @@ public static String getStr() {
|
|||
## 参考
|
||||
|
||||
- 深入解析 String#intern:<https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html>
|
||||
- R 大(RednaxelaFX)关于常量折叠的回答:https://www.zhihu.com/question/55976094/answer/147302764
|
||||
- R 大(RednaxelaFX)关于常量折叠的回答:<https://www.zhihu.com/question/55976094/answer/147302764>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -560,7 +560,7 @@ Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来
|
|||
```java
|
||||
String[] strs = {"JavaGuide", "公众号:JavaGuide", "博客:https://javaguide.cn/"};
|
||||
for (String s : strs) {
|
||||
System.out.println(s);
|
||||
System.out.println(s);
|
||||
}
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -79,8 +79,8 @@ public class Sub extends Super {
|
|||
|
||||
## 参考
|
||||
|
||||
- https://www.codejava.net/java-core/the-java-language/java-keywords
|
||||
- https://blog.csdn.net/u013393958/article/details/79881037
|
||||
- <https://www.codejava.net/java-core/the-java-language/java-keywords>
|
||||
- <https://blog.csdn.net/u013393958/article/details/79881037>
|
||||
|
||||
# static 关键字详解
|
||||
|
||||
|
|
@ -166,8 +166,8 @@ static {
|
|||
|
||||
静态内部类与非静态内部类之间存在一个最大的区别,我们知道非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围类,但是静态内部类却没有。没有这个引用就意味着:
|
||||
|
||||
1. 它的创建是不需要依赖外围类的创建。
|
||||
2. 它不能使用任何外围类的非 static 成员变量和方法。
|
||||
1. 它的创建是不需要依赖外围类的创建。
|
||||
2. 它不能使用任何外围类的非 static 成员变量和方法。
|
||||
|
||||
Example(静态内部类实现单例模式)
|
||||
|
||||
|
|
@ -302,8 +302,8 @@ public class Test {
|
|||
|
||||
### 参考
|
||||
|
||||
- https://blog.csdn.net/chen13579867831/article/details/78995480
|
||||
- https://www.cnblogs.com/chenssy/p/3388487.html
|
||||
- https://www.cnblogs.com/Qian123/p/5713440.html
|
||||
- <https://blog.csdn.net/chen13579867831/article/details/78995480>
|
||||
- <https://www.cnblogs.com/chenssy/p/3388487.html>
|
||||
- <https://www.cnblogs.com/Qian123/p/5713440.html>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ head:
|
|||
|
||||
> 作者:Hollis
|
||||
>
|
||||
> 原文:https://mp.weixin.qq.com/s/o4XdEMq1DL-nBS-f8Za5Aw
|
||||
> 原文:<https://mp.weixin.qq.com/s/o4XdEMq1DL-nBS-f8Za5Aw>
|
||||
|
||||
语法糖是大厂 Java 面试常问的一个知识点。
|
||||
|
||||
|
|
|
|||
|
|
@ -322,7 +322,7 @@ public class Main {
|
|||
System.out.println("value before putInt: " + main.value);
|
||||
unsafe.putInt(main, offset, 42);
|
||||
System.out.println("value after putInt: " + main.value);
|
||||
System.out.println("value after putInt: " + unsafe.getInt(main, offset));
|
||||
System.out.println("value after putInt: " + unsafe.getInt(main, offset));
|
||||
}
|
||||
|
||||
private static Unsafe reflectGetUnsafe() {
|
||||
|
|
@ -451,7 +451,7 @@ public native int arrayIndexScale(Class<?> arrayClass);
|
|||
|
||||
```java
|
||||
/**
|
||||
* CAS
|
||||
* CAS
|
||||
* @param o 包含要修改field的对象
|
||||
* @param offset 对象中某field的偏移量
|
||||
* @param expected 期望值
|
||||
|
|
|
|||
|
|
@ -84,17 +84,17 @@ num2 = 20
|
|||
代码:
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
public static void main(String[] args) {
|
||||
int[] arr = { 1, 2, 3, 4, 5 };
|
||||
System.out.println(arr[0]);
|
||||
change(arr);
|
||||
System.out.println(arr[0]);
|
||||
}
|
||||
}
|
||||
|
||||
public static void change(int[] array) {
|
||||
public static void change(int[] array) {
|
||||
// 将数组的第一个元素变为0
|
||||
array[0] = 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
|
|
|||
|
|
@ -238,7 +238,7 @@ public class DrainToExample {
|
|||
public abstract class AbstractQueue<E>
|
||||
extends AbstractCollection<E>
|
||||
implements Queue<E> {
|
||||
//...
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -249,11 +249,11 @@ public abstract class AbstractQueue<E>
|
|||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
if (offer(e))
|
||||
return true;
|
||||
else
|
||||
throw new IllegalStateException("Queue full");
|
||||
}
|
||||
if (offer(e))
|
||||
return true;
|
||||
else
|
||||
throw new IllegalStateException("Queue full");
|
||||
}
|
||||
```
|
||||
|
||||
而 `AbstractQueue` 中并没有对 `Queue` 的 `offer` 的实现,很明显这样做的目的是定义好了 `add` 的核心逻辑,将 `offer` 的细节交由其子类即我们的 `ArrayBlockingQueue` 实现。
|
||||
|
|
@ -265,13 +265,13 @@ public boolean add(E e) {
|
|||
```java
|
||||
public interface BlockingQueue<E> extends Queue<E> {
|
||||
|
||||
//元素入队成功返回true,反之则会抛出异常IllegalStateException
|
||||
//元素入队成功返回true,反之则会抛出异常IllegalStateException
|
||||
boolean add(E e);
|
||||
|
||||
//元素入队成功返回true,反之返回false
|
||||
//元素入队成功返回true,反之返回false
|
||||
boolean offer(E e);
|
||||
|
||||
//元素入队成功则直接返回,如果队列已满元素不可入队则将线程阻塞,因为阻塞期间可能会被打断,所以这里方法签名抛出了InterruptedException
|
||||
//元素入队成功则直接返回,如果队列已满元素不可入队则将线程阻塞,因为阻塞期间可能会被打断,所以这里方法签名抛出了InterruptedException
|
||||
void put(E e) throws InterruptedException;
|
||||
|
||||
//和上一个方法一样,只不过队列满时只会阻塞单位为unit,时间为timeout的时长,如果在等待时长内没有入队成功则直接返回false。
|
||||
|
|
@ -281,20 +281,20 @@ public interface BlockingQueue<E> extends Queue<E> {
|
|||
//从队头取出一个元素,如果队列为空则阻塞等待,因为会阻塞线程的缘故,所以该方法可能会被打断,所以签名定义了InterruptedException
|
||||
E take() throws InterruptedException;
|
||||
|
||||
//取出队头的元素并返回,如果当前队列为空则阻塞等待timeout且单位为unit的时长,如果这个时间段没有元素则直接返回null。
|
||||
//取出队头的元素并返回,如果当前队列为空则阻塞等待timeout且单位为unit的时长,如果这个时间段没有元素则直接返回null。
|
||||
E poll(long timeout, TimeUnit unit)
|
||||
throws InterruptedException;
|
||||
|
||||
//获取队列剩余元素个数
|
||||
//获取队列剩余元素个数
|
||||
int remainingCapacity();
|
||||
|
||||
//删除我们指定的对象,如果成功返回true,反之返回false。
|
||||
//删除我们指定的对象,如果成功返回true,反之返回false。
|
||||
boolean remove(Object o);
|
||||
|
||||
//判断队列中是否包含指定元素
|
||||
public boolean contains(Object o);
|
||||
|
||||
//将队列中的元素全部存到指定的集合中
|
||||
//将队列中的元素全部存到指定的集合中
|
||||
int drainTo(Collection<? super E> c);
|
||||
|
||||
//转移maxElements个元素到集合中
|
||||
|
|
@ -306,12 +306,12 @@ public interface BlockingQueue<E> extends Queue<E> {
|
|||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
//AbstractQueue的offer来自下层的ArrayBlockingQueue从BlockingQueue继承并实现的offer方法
|
||||
if (offer(e))
|
||||
return true;
|
||||
else
|
||||
throw new IllegalStateException("Queue full");
|
||||
}
|
||||
//AbstractQueue的offer来自下层的ArrayBlockingQueue从BlockingQueue继承并实现的offer方法
|
||||
if (offer(e))
|
||||
return true;
|
||||
else
|
||||
throw new IllegalStateException("Queue full");
|
||||
}
|
||||
```
|
||||
|
||||
### 初始化
|
||||
|
|
@ -321,17 +321,17 @@ public boolean add(E e) {
|
|||
```java
|
||||
// capacity 表示队列初始容量,fair 表示 锁的公平性
|
||||
public ArrayBlockingQueue(int capacity, boolean fair) {
|
||||
//如果设置的队列大小小于0,则直接抛出IllegalArgumentException
|
||||
if (capacity <= 0)
|
||||
throw new IllegalArgumentException();
|
||||
//初始化一个数组用于存放队列的元素
|
||||
this.items = new Object[capacity];
|
||||
//创建阻塞队列流程控制的锁
|
||||
lock = new ReentrantLock(fair);
|
||||
//用lock锁创建两个条件控制队列生产和消费
|
||||
notEmpty = lock.newCondition();
|
||||
notFull = lock.newCondition();
|
||||
}
|
||||
//如果设置的队列大小小于0,则直接抛出IllegalArgumentException
|
||||
if (capacity <= 0)
|
||||
throw new IllegalArgumentException();
|
||||
//初始化一个数组用于存放队列的元素
|
||||
this.items = new Object[capacity];
|
||||
//创建阻塞队列流程控制的锁
|
||||
lock = new ReentrantLock(fair);
|
||||
//用lock锁创建两个条件控制队列生产和消费
|
||||
notEmpty = lock.newCondition();
|
||||
notFull = lock.newCondition();
|
||||
}
|
||||
```
|
||||
|
||||
这个构造方法里面有两个比较核心的成员变量 `notEmpty`(非空) 和 `notFull` (非满) ,需要我们格外留意,它们是实现生产者和消费者有序工作的关键所在,这一点笔者会在后续的源码解析中详细说明,这里我们只需初步了解一下阻塞队列的构造即可。
|
||||
|
|
@ -349,32 +349,32 @@ public ArrayBlockingQueue(int capacity, boolean fair) {
|
|||
```java
|
||||
public ArrayBlockingQueue(int capacity, boolean fair,
|
||||
Collection<? extends E> c) {
|
||||
//初始化容量和锁的公平性
|
||||
this(capacity, fair);
|
||||
//初始化容量和锁的公平性
|
||||
this(capacity, fair);
|
||||
|
||||
final ReentrantLock lock = this.lock;
|
||||
//上锁并将c中的元素存放到ArrayBlockingQueue底层的数组中
|
||||
lock.lock();
|
||||
try {
|
||||
int i = 0;
|
||||
try {
|
||||
//遍历并添加元素到数组中
|
||||
for (E e : c) {
|
||||
checkNotNull(e);
|
||||
items[i++] = e;
|
||||
}
|
||||
} catch (ArrayIndexOutOfBoundsException ex) {
|
||||
throw new IllegalArgumentException();
|
||||
}
|
||||
//记录当前队列容量
|
||||
count = i;
|
||||
//更新下一次put或者offer或用add方法添加到队列底层数组的位置
|
||||
putIndex = (i == capacity) ? 0 : i;
|
||||
} finally {
|
||||
//完成遍历后释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
final ReentrantLock lock = this.lock;
|
||||
//上锁并将c中的元素存放到ArrayBlockingQueue底层的数组中
|
||||
lock.lock();
|
||||
try {
|
||||
int i = 0;
|
||||
try {
|
||||
//遍历并添加元素到数组中
|
||||
for (E e : c) {
|
||||
checkNotNull(e);
|
||||
items[i++] = e;
|
||||
}
|
||||
} catch (ArrayIndexOutOfBoundsException ex) {
|
||||
throw new IllegalArgumentException();
|
||||
}
|
||||
//记录当前队列容量
|
||||
count = i;
|
||||
//更新下一次put或者offer或用add方法添加到队列底层数组的位置
|
||||
putIndex = (i == capacity) ? 0 : i;
|
||||
} finally {
|
||||
//完成遍历后释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 阻塞式获取和新增元素
|
||||
|
|
@ -402,42 +402,42 @@ public ArrayBlockingQueue(int capacity, boolean fair,
|
|||
|
||||
```java
|
||||
public void put(E e) throws InterruptedException {
|
||||
//确保插入的元素不为null
|
||||
checkNotNull(e);
|
||||
//加锁
|
||||
final ReentrantLock lock = this.lock;
|
||||
//这里使用lockInterruptibly()方法而不是lock()方法是为了能够响应中断操作,如果在等待获取锁的过程中被打断则该方法会抛出InterruptedException异常。
|
||||
lock.lockInterruptibly();
|
||||
try {
|
||||
//如果count等数组长度则说明队列已满,当前线程将被挂起放到AQS队列中,等待队列非满时插入(非满条件)。
|
||||
//在等待期间,锁会被释放,其他线程可以继续对队列进行操作。
|
||||
while (count == items.length)
|
||||
notFull.await();
|
||||
//如果队列可以存放元素,则调用enqueue将元素入队
|
||||
enqueue(e);
|
||||
} finally {
|
||||
//释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
//确保插入的元素不为null
|
||||
checkNotNull(e);
|
||||
//加锁
|
||||
final ReentrantLock lock = this.lock;
|
||||
//这里使用lockInterruptibly()方法而不是lock()方法是为了能够响应中断操作,如果在等待获取锁的过程中被打断则该方法会抛出InterruptedException异常。
|
||||
lock.lockInterruptibly();
|
||||
try {
|
||||
//如果count等数组长度则说明队列已满,当前线程将被挂起放到AQS队列中,等待队列非满时插入(非满条件)。
|
||||
//在等待期间,锁会被释放,其他线程可以继续对队列进行操作。
|
||||
while (count == items.length)
|
||||
notFull.await();
|
||||
//如果队列可以存放元素,则调用enqueue将元素入队
|
||||
enqueue(e);
|
||||
} finally {
|
||||
//释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`put`方法内部调用了 `enqueue` 方法来实现元素入队,我们继续深入查看一下 `enqueue` 方法的实现细节:
|
||||
|
||||
```java
|
||||
private void enqueue(E x) {
|
||||
//获取队列底层的数组
|
||||
final Object[] items = this.items;
|
||||
//将putindex位置的值设置为我们传入的x
|
||||
items[putIndex] = x;
|
||||
//更新putindex,如果putindex等于数组长度,则更新为0
|
||||
if (++putIndex == items.length)
|
||||
putIndex = 0;
|
||||
//队列长度+1
|
||||
count++;
|
||||
//通知队列非空,那些因为获取元素而阻塞的线程可以继续工作了
|
||||
notEmpty.signal();
|
||||
}
|
||||
//获取队列底层的数组
|
||||
final Object[] items = this.items;
|
||||
//将putindex位置的值设置为我们传入的x
|
||||
items[putIndex] = x;
|
||||
//更新putindex,如果putindex等于数组长度,则更新为0
|
||||
if (++putIndex == items.length)
|
||||
putIndex = 0;
|
||||
//队列长度+1
|
||||
count++;
|
||||
//通知队列非空,那些因为获取元素而阻塞的线程可以继续工作了
|
||||
notEmpty.signal();
|
||||
}
|
||||
```
|
||||
|
||||
从源码中可以看到入队操作的逻辑就是在数组中追加一个新元素,整体执行步骤为:
|
||||
|
|
@ -452,20 +452,20 @@ private void enqueue(E x) {
|
|||
|
||||
```java
|
||||
public E take() throws InterruptedException {
|
||||
//获取锁
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lockInterruptibly();
|
||||
try {
|
||||
//如果队列中元素个数为0,则将当前线程打断并存入AQS队列中,等待队列非空时获取并移除元素(非空条件)
|
||||
while (count == 0)
|
||||
notEmpty.await();
|
||||
//如果队列不为空则调用dequeue获取元素
|
||||
return dequeue();
|
||||
} finally {
|
||||
//释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
//获取锁
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lockInterruptibly();
|
||||
try {
|
||||
//如果队列中元素个数为0,则将当前线程打断并存入AQS队列中,等待队列非空时获取并移除元素(非空条件)
|
||||
while (count == 0)
|
||||
notEmpty.await();
|
||||
//如果队列不为空则调用dequeue获取元素
|
||||
return dequeue();
|
||||
} finally {
|
||||
//释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
理解了 `put` 方法再看`take` 方法就很简单了,其核心逻辑和`put` 方法正好是相反的,比如`put` 方法在队列满的时候等待队列非满时插入元素(非满条件),而`take` 方法等待队列非空时获取并移除元素(非空条件)。
|
||||
|
|
@ -474,24 +474,24 @@ public E take() throws InterruptedException {
|
|||
|
||||
```java
|
||||
private E dequeue() {
|
||||
//获取阻塞队列底层的数组
|
||||
final Object[] items = this.items;
|
||||
@SuppressWarnings("unchecked")
|
||||
//从队列中获取takeIndex位置的元素
|
||||
E x = (E) items[takeIndex];
|
||||
//将takeIndex置空
|
||||
items[takeIndex] = null;
|
||||
//takeIndex向后挪动,如果等于数组长度则更新为0
|
||||
if (++takeIndex == items.length)
|
||||
takeIndex = 0;
|
||||
//队列长度减1
|
||||
count--;
|
||||
if (itrs != null)
|
||||
itrs.elementDequeued();
|
||||
//通知那些被打断的线程当前队列状态非满,可以继续存放元素
|
||||
notFull.signal();
|
||||
return x;
|
||||
}
|
||||
//获取阻塞队列底层的数组
|
||||
final Object[] items = this.items;
|
||||
@SuppressWarnings("unchecked")
|
||||
//从队列中获取takeIndex位置的元素
|
||||
E x = (E) items[takeIndex];
|
||||
//将takeIndex置空
|
||||
items[takeIndex] = null;
|
||||
//takeIndex向后挪动,如果等于数组长度则更新为0
|
||||
if (++takeIndex == items.length)
|
||||
takeIndex = 0;
|
||||
//队列长度减1
|
||||
count--;
|
||||
if (itrs != null)
|
||||
itrs.elementDequeued();
|
||||
//通知那些被打断的线程当前队列状态非满,可以继续存放元素
|
||||
notFull.signal();
|
||||
return x;
|
||||
}
|
||||
```
|
||||
|
||||
由于`dequeue` 方法(出队)和上面介绍的 `enqueue` 方法(入队)的步骤大致类似,这里就不重复介绍了。
|
||||
|
|
@ -523,7 +523,7 @@ public boolean offer(E e) {
|
|||
final ReentrantLock lock = this.lock;
|
||||
lock.lock();
|
||||
try {
|
||||
//队列已满直接返回false
|
||||
//队列已满直接返回false
|
||||
if (count == items.length)
|
||||
return false;
|
||||
else {
|
||||
|
|
@ -546,7 +546,7 @@ public E poll() {
|
|||
//上锁
|
||||
lock.lock();
|
||||
try {
|
||||
//如果队列为空直接返回null,反之出队返回元素值
|
||||
//如果队列为空直接返回null,反之出队返回元素值
|
||||
return (count == 0) ? null : dequeue();
|
||||
} finally {
|
||||
lock.unlock();
|
||||
|
|
@ -558,13 +558,13 @@ public E poll() {
|
|||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
//调用下方的add
|
||||
//调用下方的add
|
||||
return super.add(e);
|
||||
}
|
||||
|
||||
|
||||
public boolean add(E e) {
|
||||
//调用offer如果失败直接抛出异常
|
||||
//调用offer如果失败直接抛出异常
|
||||
if (offer(e))
|
||||
return true;
|
||||
else
|
||||
|
|
@ -644,7 +644,7 @@ public E poll(long timeout, TimeUnit unit) throws InterruptedException {
|
|||
final ReentrantLock lock = this.lock;
|
||||
lock.lockInterruptibly();
|
||||
try {
|
||||
//队列为空,循环等待,若时间到还是空的,则直接返回null
|
||||
//队列为空,循环等待,若时间到还是空的,则直接返回null
|
||||
while (count == 0) {
|
||||
if (nanos <= 0)
|
||||
return null;
|
||||
|
|
|
|||
|
|
@ -804,19 +804,19 @@ private static int hugeCapacity(int minCapacity) {
|
|||
```java
|
||||
public class ArraycopyTest {
|
||||
|
||||
public static void main(String[] args) {
|
||||
// TODO Auto-generated method stub
|
||||
int[] a = new int[10];
|
||||
a[0] = 0;
|
||||
a[1] = 1;
|
||||
a[2] = 2;
|
||||
a[3] = 3;
|
||||
System.arraycopy(a, 2, a, 3, 3);
|
||||
a[2]=99;
|
||||
for (int i = 0; i < a.length; i++) {
|
||||
System.out.print(a[i] + " ");
|
||||
}
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
// TODO Auto-generated method stub
|
||||
int[] a = new int[10];
|
||||
a[0] = 0;
|
||||
a[1] = 1;
|
||||
a[2] = 2;
|
||||
a[3] = 3;
|
||||
System.arraycopy(a, 2, a, 3, 3);
|
||||
a[2]=99;
|
||||
for (int i = 0; i < a.length; i++) {
|
||||
System.out.print(a[i] + " ");
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
|
@ -833,9 +833,9 @@ public class ArraycopyTest {
|
|||
|
||||
```java
|
||||
public static int[] copyOf(int[] original, int newLength) {
|
||||
// 申请一个新的数组
|
||||
// 申请一个新的数组
|
||||
int[] copy = new int[newLength];
|
||||
// 调用System.arraycopy,将源数组中的数据进行拷贝,并返回新的数组
|
||||
// 调用System.arraycopy,将源数组中的数据进行拷贝,并返回新的数组
|
||||
System.arraycopy(original, 0, copy, 0,
|
||||
Math.min(original.length, newLength));
|
||||
return copy;
|
||||
|
|
@ -859,14 +859,14 @@ public class ArraycopyTest {
|
|||
```java
|
||||
public class ArrayscopyOfTest {
|
||||
|
||||
public static void main(String[] args) {
|
||||
int[] a = new int[3];
|
||||
a[0] = 0;
|
||||
a[1] = 1;
|
||||
a[2] = 2;
|
||||
int[] b = Arrays.copyOf(a, 10);
|
||||
System.out.println("b.length"+b.length);
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
int[] a = new int[3];
|
||||
a[0] = 0;
|
||||
a[1] = 1;
|
||||
a[2] = 2;
|
||||
int[] b = Arrays.copyOf(a, 10);
|
||||
System.out.println("b.length"+b.length);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -917,17 +917,17 @@ public class ArrayscopyOfTest {
|
|||
|
||||
```java
|
||||
public class EnsureCapacityTest {
|
||||
public static void main(String[] args) {
|
||||
ArrayList<Object> list = new ArrayList<Object>();
|
||||
final int N = 10000000;
|
||||
long startTime = System.currentTimeMillis();
|
||||
for (int i = 0; i < N; i++) {
|
||||
list.add(i);
|
||||
}
|
||||
long endTime = System.currentTimeMillis();
|
||||
System.out.println("使用ensureCapacity方法前:"+(endTime - startTime));
|
||||
public static void main(String[] args) {
|
||||
ArrayList<Object> list = new ArrayList<Object>();
|
||||
final int N = 10000000;
|
||||
long startTime = System.currentTimeMillis();
|
||||
for (int i = 0; i < N; i++) {
|
||||
list.add(i);
|
||||
}
|
||||
long endTime = System.currentTimeMillis();
|
||||
System.out.println("使用ensureCapacity方法前:"+(endTime - startTime));
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ tag:
|
|||
- Java集合
|
||||
---
|
||||
|
||||
> 本文来自公众号:末读代码的投稿,原文地址:https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw 。
|
||||
> 本文来自公众号:末读代码的投稿,原文地址:<https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw> 。
|
||||
|
||||
上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 `ConcurrentHashMap` 了,作为线程安全的 HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
|
||||
|
||||
|
|
|
|||
|
|
@ -198,7 +198,7 @@ public E remove(int index) {
|
|||
// 加锁
|
||||
lock.lock();
|
||||
try {
|
||||
//获取当前array数组
|
||||
//获取当前array数组
|
||||
Object[] elements = getArray();
|
||||
// 获取当前array长度
|
||||
int len = elements.length;
|
||||
|
|
@ -207,7 +207,7 @@ public E remove(int index) {
|
|||
int numMoved = len - index - 1;
|
||||
// 判断删除的是否是最后一个元素
|
||||
if (numMoved == 0)
|
||||
// 如果删除的是最后一个元素,直接复制该元素前的所有元素到新的数组
|
||||
// 如果删除的是最后一个元素,直接复制该元素前的所有元素到新的数组
|
||||
setArray(Arrays.copyOf(elements, len - 1));
|
||||
else {
|
||||
// 分段复制,将index前的元素和index+1后的元素复制到新数组
|
||||
|
|
@ -221,7 +221,7 @@ public E remove(int index) {
|
|||
}
|
||||
return oldValue;
|
||||
} finally {
|
||||
// 解锁
|
||||
// 解锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -267,7 +267,7 @@ public E take() throws InterruptedException {
|
|||
}
|
||||
}
|
||||
} finally {
|
||||
//收尾逻辑:当leader为null,并且队列中有任务时,唤醒等待的获取元素的线程。
|
||||
// 收尾逻辑:当leader为null,并且队列中有任务时,唤醒等待的获取元素的线程。
|
||||
if (leader == null && q.peek() != null)
|
||||
available.signal();
|
||||
//释放锁
|
||||
|
|
|
|||
|
|
@ -180,7 +180,7 @@ static class Entry<K,V> extends HashMap.Node<K,V> {
|
|||
|
||||
```java
|
||||
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
|
||||
//略
|
||||
//略
|
||||
|
||||
}
|
||||
```
|
||||
|
|
@ -346,20 +346,20 @@ void afterNodeRemoval(Node<K,V> p) { }
|
|||
```java
|
||||
void afterNodeRemoval(Node<K,V> e) { // unlink
|
||||
|
||||
//获取当前节点p、以及e的前驱节点b和后继节点a
|
||||
//获取当前节点p、以及e的前驱节点b和后继节点a
|
||||
LinkedHashMap.Entry<K,V> p =
|
||||
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
|
||||
//将p的前驱和后继指针都设置为null,使其和前驱、后继节点断开联系
|
||||
//将p的前驱和后继指针都设置为null,使其和前驱、后继节点断开联系
|
||||
p.before = p.after = null;
|
||||
|
||||
//如果前驱节点为空,则说明当前节点p是链表首节点,让head指针指向后继节点a即可
|
||||
//如果前驱节点为空,则说明当前节点p是链表首节点,让head指针指向后继节点a即可
|
||||
if (b == null)
|
||||
head = a;
|
||||
else
|
||||
//如果前驱节点b不为空,则让b直接指向后继节点a
|
||||
b.after = a;
|
||||
|
||||
//如果后继节点为空,则说明当前节点p在链表末端,所以直接让tail指针指向前驱节点a即可
|
||||
//如果后继节点为空,则说明当前节点p在链表末端,所以直接让tail指针指向前驱节点a即可
|
||||
if (a == null)
|
||||
tail = b;
|
||||
else
|
||||
|
|
@ -393,7 +393,7 @@ void afterNodeRemoval(Node<K,V> e) { // unlink
|
|||
```java
|
||||
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
|
||||
boolean evict) {
|
||||
//略
|
||||
//略
|
||||
if (e != null) { // existing mapping for key
|
||||
V oldValue = e.value;
|
||||
if (!onlyIfAbsent || oldValue == null)
|
||||
|
|
@ -436,7 +436,7 @@ void afterNodeInsertion(boolean evict) { // possibly remove eldest
|
|||
LinkedHashMap.Entry<K,V> first;
|
||||
//如果evict为true且队首元素不为空以及removeEldestEntry返回true,则说明我们需要最老的元素(即在链表首部的元素)移除。
|
||||
if (evict && (first = head) != null && removeEldestEntry(first)) {
|
||||
//获取链表首部的键值对的key
|
||||
//获取链表首部的键值对的key
|
||||
K key = first.key;
|
||||
//调用removeNode将元素从HashMap的bucket中移除,并和LinkedHashMap的双向链表断开,等待gc回收
|
||||
removeNode(hash(key), key, null, false, true);
|
||||
|
|
|
|||
|
|
@ -142,11 +142,11 @@ semaphore.release();
|
|||
|
||||
```java
|
||||
public Semaphore(int permits) {
|
||||
sync = new NonfairSync(permits);
|
||||
sync = new NonfairSync(permits);
|
||||
}
|
||||
|
||||
public Semaphore(int permits, boolean fair) {
|
||||
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
|
||||
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -165,7 +165,7 @@ public Semaphore(int permits, boolean fair) {
|
|||
```java
|
||||
// 获取1个许可证
|
||||
public void acquire() throws InterruptedException {
|
||||
sync.acquireSharedInterruptibly(1);
|
||||
sync.acquireSharedInterruptibly(1);
|
||||
}
|
||||
|
||||
// 获取一个或者多个许可证
|
||||
|
|
@ -219,7 +219,7 @@ final int nonfairTryAcquireShared(int acquires) {
|
|||
```java
|
||||
// 释放一个许可证
|
||||
public void release() {
|
||||
sync.releaseShared(1);
|
||||
sync.releaseShared(1);
|
||||
}
|
||||
|
||||
// 释放一个或者多个许可证
|
||||
|
|
@ -550,9 +550,9 @@ public CyclicBarrier(int parties, Runnable barrierAction) {
|
|||
```java
|
||||
public int await() throws InterruptedException, BrokenBarrierException {
|
||||
try {
|
||||
return dowait(false, 0L);
|
||||
return dowait(false, 0L);
|
||||
} catch (TimeoutException toe) {
|
||||
throw new Error(toe); // cannot happen
|
||||
throw new Error(toe); // cannot happen
|
||||
}
|
||||
}
|
||||
```
|
||||
|
|
|
|||
|
|
@ -398,40 +398,40 @@ currentValue=true, currentMark=true, wCasResult=true
|
|||
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;
|
||||
|
||||
public class AtomicIntegerFieldUpdaterTest {
|
||||
public static void main(String[] args) {
|
||||
AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
|
||||
public static void main(String[] args) {
|
||||
AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
|
||||
|
||||
User user = new User("Java", 22);
|
||||
System.out.println(a.getAndIncrement(user));// 22
|
||||
System.out.println(a.get(user));// 23
|
||||
}
|
||||
User user = new User("Java", 22);
|
||||
System.out.println(a.getAndIncrement(user));// 22
|
||||
System.out.println(a.get(user));// 23
|
||||
}
|
||||
}
|
||||
|
||||
class User {
|
||||
private String name;
|
||||
public volatile int age;
|
||||
private String name;
|
||||
public volatile int age;
|
||||
|
||||
public User(String name, int age) {
|
||||
super();
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
public User(String name, int age) {
|
||||
super();
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
|
||||
public void setName(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
public void setName(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
public int getAge() {
|
||||
return age;
|
||||
}
|
||||
public int getAge() {
|
||||
return age;
|
||||
}
|
||||
|
||||
public void setAge(int age) {
|
||||
this.age = age;
|
||||
}
|
||||
public void setAge(int age) {
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
|
|
|||
|
|
@ -655,7 +655,7 @@ private ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 10,
|
|||
new LinkedBlockingQueue<Runnable>());
|
||||
|
||||
CompletableFuture.runAsync(() -> {
|
||||
//...
|
||||
//...
|
||||
}, executor);
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -149,7 +149,7 @@ private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueu
|
|||
## 参考
|
||||
|
||||
- 《实战 Java 高并发程序设计》
|
||||
- https://javadoop.com/post/java-concurrent-queue
|
||||
- https://juejin.im/post/5aeebd02518825672f19c546
|
||||
- <https://javadoop.com/post/java-concurrent-queue>
|
||||
- <https://juejin.im/post/5aeebd02518825672f19c546>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -197,6 +197,7 @@ try {
|
|||
lock.unlock();
|
||||
}
|
||||
```
|
||||
|
||||
高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。并且,悲观锁还可能会存在死锁问题,影响代码的正常运行。
|
||||
|
||||
### 什么是乐观锁?
|
||||
|
|
@ -268,7 +269,7 @@ Java 语言并没有直接实现 CAS,CAS 相关的实现是通过 C++ 内联
|
|||
|
||||
```java
|
||||
/**
|
||||
* CAS
|
||||
* CAS
|
||||
* @param o 包含要修改field的对象
|
||||
* @param offset 对象中某field的偏移量
|
||||
* @param expected 期望值
|
||||
|
|
@ -700,11 +701,11 @@ Atomic 原子类部分的内容我单独写了一篇文章来总结:[Atomic
|
|||
|
||||
- 《深入理解 Java 虚拟机》
|
||||
- 《实战 Java 高并发程序设计》
|
||||
- Guide to the Volatile Keyword in Java - Baeldung:https://www.baeldung.com/java-volatile
|
||||
- 不可不说的 Java“锁”事 - 美团技术团队:https://tech.meituan.com/2018/11/15/java-lock.html
|
||||
- 在 ReadWriteLock 类中读锁为什么不能升级为写锁?:https://cloud.tencent.com/developer/article/1176230
|
||||
- 高性能解决线程饥饿的利器 StampedLock:https://mp.weixin.qq.com/s/2Acujjr4BHIhlFsCLGwYSg
|
||||
- 理解 Java 中的 ThreadLocal - 技术小黑屋:https://droidyue.com/blog/2016/03/13/learning-threadlocal-in-java/
|
||||
- ThreadLocal (Java Platform SE 8 ) - Oracle Help Center:https://docs.oracle.com/javase/8/docs/api/java/lang/ThreadLocal.html
|
||||
- Guide to the Volatile Keyword in Java - Baeldung:<https://www.baeldung.com/java-volatile>
|
||||
- 不可不说的 Java“锁”事 - 美团技术团队:<https://tech.meituan.com/2018/11/15/java-lock.html>
|
||||
- 在 ReadWriteLock 类中读锁为什么不能升级为写锁?:<https://cloud.tencent.com/developer/article/1176230>
|
||||
- 高性能解决线程饥饿的利器 StampedLock:<https://mp.weixin.qq.com/s/2Acujjr4BHIhlFsCLGwYSg>
|
||||
- 理解 Java 中的 ThreadLocal - 技术小黑屋:<https://droidyue.com/blog/2016/03/13/learning-threadlocal-in-java/>
|
||||
- ThreadLocal (Java Platform SE 8 ) - Oracle Help Center:<https://docs.oracle.com/javase/8/docs/api/java/lang/ThreadLocal.html>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -693,11 +693,11 @@ semaphore.release();
|
|||
|
||||
```java
|
||||
public Semaphore(int permits) {
|
||||
sync = new NonfairSync(permits);
|
||||
sync = new NonfairSync(permits);
|
||||
}
|
||||
|
||||
public Semaphore(int permits, boolean fair) {
|
||||
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
|
||||
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -716,7 +716,7 @@ public Semaphore(int permits, boolean fair) {
|
|||
* 获取1个许可证
|
||||
*/
|
||||
public void acquire() throws InterruptedException {
|
||||
sync.acquireSharedInterruptibly(1);
|
||||
sync.acquireSharedInterruptibly(1);
|
||||
}
|
||||
/**
|
||||
* 共享模式下获取许可证,获取成功则返回,失败则加入阻塞队列,挂起线程
|
||||
|
|
@ -736,7 +736,7 @@ public final void acquireSharedInterruptibly(int arg)
|
|||
```java
|
||||
// 释放一个许可证
|
||||
public void release() {
|
||||
sync.releaseShared(1);
|
||||
sync.releaseShared(1);
|
||||
}
|
||||
|
||||
// 释放共享锁,同时会唤醒同步队列中的一个线程。
|
||||
|
|
@ -885,9 +885,9 @@ public CyclicBarrier(int parties, Runnable barrierAction) {
|
|||
```java
|
||||
public int await() throws InterruptedException, BrokenBarrierException {
|
||||
try {
|
||||
return dowait(false, 0L);
|
||||
return dowait(false, 0L);
|
||||
} catch (TimeoutException toe) {
|
||||
throw new Error(toe); // cannot happen
|
||||
throw new Error(toe); // cannot happen
|
||||
}
|
||||
}
|
||||
```
|
||||
|
|
@ -984,10 +984,10 @@ public int await() throws InterruptedException, BrokenBarrierException {
|
|||
|
||||
- 《深入理解 Java 虚拟机》
|
||||
- 《实战 Java 高并发程序设计》
|
||||
- 带你了解下 SynchronousQueue(并发队列专题):https://juejin.cn/post/7031196740128768037
|
||||
- 阻塞队列 — DelayedWorkQueue 源码分析:https://zhuanlan.zhihu.com/p/310621485
|
||||
- Java 多线程(三)——FutureTask/CompletableFuture:https://www.cnblogs.com/iwehdio/p/14285282.html
|
||||
- Java 并发之 AQS 详解:https://www.cnblogs.com/waterystone/p/4920797.html
|
||||
- Java 并发包基石-AQS 详解:https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
|
||||
- 带你了解下 SynchronousQueue(并发队列专题):<https://juejin.cn/post/7031196740128768037>
|
||||
- 阻塞队列 — DelayedWorkQueue 源码分析:<https://zhuanlan.zhihu.com/p/310621485>
|
||||
- Java 多线程(三)——FutureTask/CompletableFuture:<https://www.cnblogs.com/iwehdio/p/14285282.html>
|
||||
- Java 并发之 AQS 详解:<https://www.cnblogs.com/waterystone/p/4920797.html>
|
||||
- Java 并发包基石-AQS 详解:<https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -295,6 +295,6 @@ server.tomcat.max-threads=1
|
|||
|
||||
解决上述问题比较建议的办法是使用阿里巴巴开源的 `TransmittableThreadLocal`(`TTL`)。`TransmittableThreadLocal`类继承并加强了 JDK 内置的`InheritableThreadLocal`类,在使用线程池等会池化复用线程的执行组件情况下,提供`ThreadLocal`值的传递功能,解决异步执行时上下文传递的问题。
|
||||
|
||||
`TransmittableThreadLocal` 项目地址:https://github.com/alibaba/transmittable-thread-local 。
|
||||
`TransmittableThreadLocal` 项目地址:<https://github.com/alibaba/transmittable-thread-local> 。
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -606,7 +606,7 @@ executorService.shutdown();
|
|||
|
||||
```plain
|
||||
Exception in thread "main" java.util.concurrent.TimeoutException
|
||||
at java.util.concurrent.FutureTask.get(FutureTask.java:205)
|
||||
at java.util.concurrent.FutureTask.get(FutureTask.java:205)
|
||||
```
|
||||
|
||||
#### `shutdown()`VS`shutdownNow()`
|
||||
|
|
@ -661,9 +661,9 @@ Exception in thread "main" java.util.concurrent.TimeoutException
|
|||
|
||||
**上图说明:**
|
||||
|
||||
1. 如果当前运行的线程数小于 `corePoolSize`, 如果再来新任务的话,就创建新的线程来执行任务;
|
||||
2. 当前运行的线程数等于 `corePoolSize` 后, 如果再来新任务的话,会将任务加入 `LinkedBlockingQueue`;
|
||||
3. 线程池中的线程执行完 手头的任务后,会在循环中反复从 `LinkedBlockingQueue` 中获取任务来执行;
|
||||
1. 如果当前运行的线程数小于 `corePoolSize`, 如果再来新任务的话,就创建新的线程来执行任务;
|
||||
2. 当前运行的线程数等于 `corePoolSize` 后, 如果再来新任务的话,会将任务加入 `LinkedBlockingQueue`;
|
||||
3. 线程池中的线程执行完 手头的任务后,会在循环中反复从 `LinkedBlockingQueue` 中获取任务来执行;
|
||||
|
||||
#### 为什么不推荐使用`FixedThreadPool`?
|
||||
|
||||
|
|
|
|||
|
|
@ -160,9 +160,9 @@ JSR 133 引入了 happens-before 这个概念来描述两个操作之间的内
|
|||
我们看下面这段代码:
|
||||
|
||||
```java
|
||||
int userNum = getUserNum(); // 1
|
||||
int teacherNum = getTeacherNum(); // 2
|
||||
int totalNum = userNum + teacherNum; // 3
|
||||
int userNum = getUserNum(); // 1
|
||||
int teacherNum = getTeacherNum(); // 2
|
||||
int totalNum = userNum + teacherNum; // 3
|
||||
```
|
||||
|
||||
- 1 happens-before 2
|
||||
|
|
@ -232,9 +232,9 @@ happens-before 与 JMM 的关系用《Java 并发编程的艺术》这本书中
|
|||
## 参考
|
||||
|
||||
- 《Java 并发编程的艺术》第三章 Java 内存模型
|
||||
- 《深入浅出 Java 多线程》:http://concurrent.redspider.group/RedSpider.html
|
||||
- Java 内存访问重排序的研究:https://tech.meituan.com/2014/09/23/java-memory-reordering.html
|
||||
- 嘿,同学,你要的 Java 内存模型 (JMM) 来了:https://xie.infoq.cn/article/739920a92d0d27e2053174ef2
|
||||
- JSR 133 (Java Memory Model) FAQ:https://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html
|
||||
- 《深入浅出 Java 多线程》:<http://concurrent.redspider.group/RedSpider.html>
|
||||
- Java 内存访问重排序的研究:<https://tech.meituan.com/2014/09/23/java-memory-reordering.html>
|
||||
- 嘿,同学,你要的 Java 内存模型 (JMM) 来了:<https://xie.infoq.cn/article/739920a92d0d27e2053174ef2>
|
||||
- JSR 133 (Java Memory Model) FAQ:<https://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -106,7 +106,7 @@ Java 语言并没有直接实现 CAS,CAS 相关的实现是通过 C++ 内联
|
|||
|
||||
```java
|
||||
/**
|
||||
* CAS
|
||||
* CAS
|
||||
* @param o 包含要修改field的对象
|
||||
* @param offset 对象中某field的偏移量
|
||||
* @param expected 期望值
|
||||
|
|
@ -170,7 +170,7 @@ CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS
|
|||
## 参考
|
||||
|
||||
- 《Java 并发编程核心 78 讲》
|
||||
- 通俗易懂 悲观锁、乐观锁、可重入锁、自旋锁、偏向锁、轻量/重量级锁、读写锁、各种锁及其 Java 实现!:https://zhuanlan.zhihu.com/p/71156910
|
||||
- 一文彻底搞懂 CAS 实现原理 & 深入到 CPU 指令:https://zhuanlan.zhihu.com/p/94976168
|
||||
- 通俗易懂 悲观锁、乐观锁、可重入锁、自旋锁、偏向锁、轻量/重量级锁、读写锁、各种锁及其 Java 实现!:<https://zhuanlan.zhihu.com/p/71156910>
|
||||
- 一文彻底搞懂 CAS 实现原理 & 深入到 CPU 指令:<https://zhuanlan.zhihu.com/p/94976168>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ tag:
|
|||
- Java并发
|
||||
---
|
||||
|
||||
> 本文转载自:https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
|
||||
> 本文转载自:<https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html>
|
||||
>
|
||||
> 作者:美团技术团队
|
||||
|
||||
|
|
@ -33,25 +33,25 @@ synchronized (object) {}
|
|||
public synchronized void test () {}
|
||||
// 4.可重入
|
||||
for (int i = 0; i < 100; i++) {
|
||||
synchronized (this) {}
|
||||
synchronized (this) {}
|
||||
}
|
||||
// **************************ReentrantLock的使用方式**************************
|
||||
public void test () throw Exception {
|
||||
// 1.初始化选择公平锁、非公平锁
|
||||
ReentrantLock lock = new ReentrantLock(true);
|
||||
// 2.可用于代码块
|
||||
lock.lock();
|
||||
try {
|
||||
try {
|
||||
// 3.支持多种加锁方式,比较灵活; 具有可重入特性
|
||||
if(lock.tryLock(100, TimeUnit.MILLISECONDS)){ }
|
||||
} finally {
|
||||
// 4.手动释放锁
|
||||
lock.unlock()
|
||||
}
|
||||
} finally {
|
||||
lock.unlock();
|
||||
}
|
||||
// 1.初始化选择公平锁、非公平锁
|
||||
ReentrantLock lock = new ReentrantLock(true);
|
||||
// 2.可用于代码块
|
||||
lock.lock();
|
||||
try {
|
||||
try {
|
||||
// 3.支持多种加锁方式,比较灵活; 具有可重入特性
|
||||
if(lock.tryLock(100, TimeUnit.MILLISECONDS)){ }
|
||||
} finally {
|
||||
// 4.手动释放锁
|
||||
lock.unlock()
|
||||
}
|
||||
} finally {
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -66,13 +66,13 @@ public void test () throw Exception {
|
|||
|
||||
// 非公平锁
|
||||
static final class NonfairSync extends Sync {
|
||||
...
|
||||
final void lock() {
|
||||
if (compareAndSetState(0, 1))
|
||||
setExclusiveOwnerThread(Thread.currentThread());
|
||||
else
|
||||
acquire(1);
|
||||
}
|
||||
...
|
||||
final void lock() {
|
||||
if (compareAndSetState(0, 1))
|
||||
setExclusiveOwnerThread(Thread.currentThread());
|
||||
else
|
||||
acquire(1);
|
||||
}
|
||||
...
|
||||
}
|
||||
```
|
||||
|
|
@ -101,9 +101,9 @@ static final class NonfairSync extends Sync {
|
|||
|
||||
static final class FairSync extends Sync {
|
||||
...
|
||||
final void lock() {
|
||||
acquire(1);
|
||||
}
|
||||
final void lock() {
|
||||
acquire(1);
|
||||
}
|
||||
...
|
||||
}
|
||||
```
|
||||
|
|
@ -275,13 +275,13 @@ ReentrantLock 中公平锁和非公平锁在底层是相同的,这里以非公
|
|||
// java.util.concurrent.locks.ReentrantLock
|
||||
|
||||
static final class NonfairSync extends Sync {
|
||||
...
|
||||
final void lock() {
|
||||
if (compareAndSetState(0, 1))
|
||||
setExclusiveOwnerThread(Thread.currentThread());
|
||||
else
|
||||
acquire(1);
|
||||
}
|
||||
...
|
||||
final void lock() {
|
||||
if (compareAndSetState(0, 1))
|
||||
setExclusiveOwnerThread(Thread.currentThread());
|
||||
else
|
||||
acquire(1);
|
||||
}
|
||||
...
|
||||
}
|
||||
```
|
||||
|
|
@ -292,8 +292,8 @@ static final class NonfairSync extends Sync {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
public final void acquire(int arg) {
|
||||
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
|
||||
selfInterrupt();
|
||||
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
|
||||
selfInterrupt();
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -303,7 +303,7 @@ public final void acquire(int arg) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
protected boolean tryAcquire(int arg) {
|
||||
throw new UnsupportedOperationException();
|
||||
throw new UnsupportedOperationException();
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -323,21 +323,21 @@ protected boolean tryAcquire(int arg) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
private Node addWaiter(Node mode) {
|
||||
Node node = new Node(Thread.currentThread(), mode);
|
||||
// Try the fast path of enq; backup to full enq on failure
|
||||
Node pred = tail;
|
||||
if (pred != null) {
|
||||
node.prev = pred;
|
||||
if (compareAndSetTail(pred, node)) {
|
||||
pred.next = node;
|
||||
return node;
|
||||
}
|
||||
}
|
||||
enq(node);
|
||||
return node;
|
||||
Node node = new Node(Thread.currentThread(), mode);
|
||||
// Try the fast path of enq; backup to full enq on failure
|
||||
Node pred = tail;
|
||||
if (pred != null) {
|
||||
node.prev = pred;
|
||||
if (compareAndSetTail(pred, node)) {
|
||||
pred.next = node;
|
||||
return node;
|
||||
}
|
||||
}
|
||||
enq(node);
|
||||
return node;
|
||||
}
|
||||
private final boolean compareAndSetTail(Node expect, Node update) {
|
||||
return unsafe.compareAndSwapObject(this, tailOffset, expect, update);
|
||||
return unsafe.compareAndSwapObject(this, tailOffset, expect, update);
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -352,13 +352,13 @@ private final boolean compareAndSetTail(Node expect, Node update) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
static {
|
||||
try {
|
||||
stateOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("state"));
|
||||
headOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
|
||||
tailOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("tail"));
|
||||
waitStatusOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField("waitStatus"));
|
||||
nextOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField("next"));
|
||||
} catch (Exception ex) {
|
||||
try {
|
||||
stateOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("state"));
|
||||
headOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
|
||||
tailOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("tail"));
|
||||
waitStatusOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField("waitStatus"));
|
||||
nextOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField("next"));
|
||||
} catch (Exception ex) {
|
||||
throw new Error(ex);
|
||||
}
|
||||
}
|
||||
|
|
@ -372,19 +372,19 @@ static {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
private Node enq(final Node node) {
|
||||
for (;;) {
|
||||
Node t = tail;
|
||||
if (t == null) { // Must initialize
|
||||
if (compareAndSetHead(new Node()))
|
||||
tail = head;
|
||||
} else {
|
||||
node.prev = t;
|
||||
if (compareAndSetTail(t, node)) {
|
||||
t.next = node;
|
||||
return t;
|
||||
}
|
||||
}
|
||||
}
|
||||
for (;;) {
|
||||
Node t = tail;
|
||||
if (t == null) { // Must initialize
|
||||
if (compareAndSetHead(new Node()))
|
||||
tail = head;
|
||||
} else {
|
||||
node.prev = t;
|
||||
if (compareAndSetTail(t, node)) {
|
||||
t.next = node;
|
||||
return t;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -406,13 +406,13 @@ private Node enq(final Node node) {
|
|||
// java.util.concurrent.locks.ReentrantLock
|
||||
|
||||
public final boolean hasQueuedPredecessors() {
|
||||
// The correctness of this depends on head being initialized
|
||||
// before tail and on head.next being accurate if the current
|
||||
// thread is first in queue.
|
||||
Node t = tail; // Read fields in reverse initialization order
|
||||
Node h = head;
|
||||
Node s;
|
||||
return h != t && ((s = h.next) == null || s.thread != Thread.currentThread());
|
||||
// The correctness of this depends on head being initialized
|
||||
// before tail and on head.next being accurate if the current
|
||||
// thread is first in queue.
|
||||
Node t = tail; // Read fields in reverse initialization order
|
||||
Node h = head;
|
||||
Node s;
|
||||
return h != t && ((s = h.next) == null || s.thread != Thread.currentThread());
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -424,14 +424,14 @@ public final boolean hasQueuedPredecessors() {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer#enq
|
||||
|
||||
if (t == null) { // Must initialize
|
||||
if (compareAndSetHead(new Node()))
|
||||
tail = head;
|
||||
if (compareAndSetHead(new Node()))
|
||||
tail = head;
|
||||
} else {
|
||||
node.prev = t;
|
||||
if (compareAndSetTail(t, node)) {
|
||||
t.next = node;
|
||||
return t;
|
||||
}
|
||||
node.prev = t;
|
||||
if (compareAndSetTail(t, node)) {
|
||||
t.next = node;
|
||||
return t;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -445,8 +445,8 @@ if (t == null) { // Must initialize
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
public final void acquire(int arg) {
|
||||
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
|
||||
selfInterrupt();
|
||||
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
|
||||
selfInterrupt();
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -460,31 +460,31 @@ public final void acquire(int arg) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
final boolean acquireQueued(final Node node, int arg) {
|
||||
// 标记是否成功拿到资源
|
||||
boolean failed = true;
|
||||
try {
|
||||
// 标记等待过程中是否中断过
|
||||
boolean interrupted = false;
|
||||
// 开始自旋,要么获取锁,要么中断
|
||||
for (;;) {
|
||||
// 获取当前节点的前驱节点
|
||||
final Node p = node.predecessor();
|
||||
// 如果p是头结点,说明当前节点在真实数据队列的首部,就尝试获取锁(别忘了头结点是虚节点)
|
||||
if (p == head && tryAcquire(arg)) {
|
||||
// 获取锁成功,头指针移动到当前node
|
||||
setHead(node);
|
||||
p.next = null; // help GC
|
||||
failed = false;
|
||||
return interrupted;
|
||||
}
|
||||
// 说明p为头节点且当前没有获取到锁(可能是非公平锁被抢占了)或者是p不为头结点,这个时候就要判断当前node是否要被阻塞(被阻塞条件:前驱节点的waitStatus为-1),防止无限循环浪费资源。具体两个方法下面细细分析
|
||||
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
|
||||
interrupted = true;
|
||||
}
|
||||
} finally {
|
||||
if (failed)
|
||||
cancelAcquire(node);
|
||||
}
|
||||
// 标记是否成功拿到资源
|
||||
boolean failed = true;
|
||||
try {
|
||||
// 标记等待过程中是否中断过
|
||||
boolean interrupted = false;
|
||||
// 开始自旋,要么获取锁,要么中断
|
||||
for (;;) {
|
||||
// 获取当前节点的前驱节点
|
||||
final Node p = node.predecessor();
|
||||
// 如果p是头结点,说明当前节点在真实数据队列的首部,就尝试获取锁(别忘了头结点是虚节点)
|
||||
if (p == head && tryAcquire(arg)) {
|
||||
// 获取锁成功,头指针移动到当前node
|
||||
setHead(node);
|
||||
p.next = null; // help GC
|
||||
failed = false;
|
||||
return interrupted;
|
||||
}
|
||||
// 说明p为头节点且当前没有获取到锁(可能是非公平锁被抢占了)或者是p不为头结点,这个时候就要判断当前node是否要被阻塞(被阻塞条件:前驱节点的waitStatus为-1),防止无限循环浪费资源。具体两个方法下面细细分析
|
||||
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
|
||||
interrupted = true;
|
||||
}
|
||||
} finally {
|
||||
if (failed)
|
||||
cancelAcquire(node);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -494,32 +494,32 @@ final boolean acquireQueued(final Node node, int arg) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
private void setHead(Node node) {
|
||||
head = node;
|
||||
node.thread = null;
|
||||
node.prev = null;
|
||||
head = node;
|
||||
node.thread = null;
|
||||
node.prev = null;
|
||||
}
|
||||
|
||||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
// 靠前驱节点判断当前线程是否应该被阻塞
|
||||
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
|
||||
// 获取头结点的节点状态
|
||||
int ws = pred.waitStatus;
|
||||
// 说明头结点处于唤醒状态
|
||||
if (ws == Node.SIGNAL)
|
||||
return true;
|
||||
// 通过枚举值我们知道waitStatus>0是取消状态
|
||||
if (ws > 0) {
|
||||
do {
|
||||
// 循环向前查找取消节点,把取消节点从队列中剔除
|
||||
node.prev = pred = pred.prev;
|
||||
} while (pred.waitStatus > 0);
|
||||
pred.next = node;
|
||||
} else {
|
||||
// 设置前任节点等待状态为SIGNAL
|
||||
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
|
||||
}
|
||||
return false;
|
||||
// 获取头结点的节点状态
|
||||
int ws = pred.waitStatus;
|
||||
// 说明头结点处于唤醒状态
|
||||
if (ws == Node.SIGNAL)
|
||||
return true;
|
||||
// 通过枚举值我们知道waitStatus>0是取消状态
|
||||
if (ws > 0) {
|
||||
do {
|
||||
// 循环向前查找取消节点,把取消节点从队列中剔除
|
||||
node.prev = pred = pred.prev;
|
||||
} while (pred.waitStatus > 0);
|
||||
pred.next = node;
|
||||
} else {
|
||||
// 设置前任节点等待状态为SIGNAL
|
||||
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
|
||||
}
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -555,21 +555,21 @@ acquireQueued 方法中的 Finally 代码:
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
final boolean acquireQueued(final Node node, int arg) {
|
||||
boolean failed = true;
|
||||
try {
|
||||
boolean failed = true;
|
||||
try {
|
||||
...
|
||||
for (;;) {
|
||||
final Node p = node.predecessor();
|
||||
if (p == head && tryAcquire(arg)) {
|
||||
...
|
||||
failed = false;
|
||||
for (;;) {
|
||||
final Node p = node.predecessor();
|
||||
if (p == head && tryAcquire(arg)) {
|
||||
...
|
||||
}
|
||||
...
|
||||
} finally {
|
||||
if (failed)
|
||||
cancelAcquire(node);
|
||||
}
|
||||
failed = false;
|
||||
...
|
||||
}
|
||||
...
|
||||
} finally {
|
||||
if (failed)
|
||||
cancelAcquire(node);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -580,37 +580,37 @@ final boolean acquireQueued(final Node node, int arg) {
|
|||
|
||||
private void cancelAcquire(Node node) {
|
||||
// 将无效节点过滤
|
||||
if (node == null)
|
||||
return;
|
||||
if (node == null)
|
||||
return;
|
||||
// 设置该节点不关联任何线程,也就是虚节点
|
||||
node.thread = null;
|
||||
Node pred = node.prev;
|
||||
node.thread = null;
|
||||
Node pred = node.prev;
|
||||
// 通过前驱节点,跳过取消状态的node
|
||||
while (pred.waitStatus > 0)
|
||||
node.prev = pred = pred.prev;
|
||||
while (pred.waitStatus > 0)
|
||||
node.prev = pred = pred.prev;
|
||||
// 获取过滤后的前驱节点的后继节点
|
||||
Node predNext = pred.next;
|
||||
Node predNext = pred.next;
|
||||
// 把当前node的状态设置为CANCELLED
|
||||
node.waitStatus = Node.CANCELLED;
|
||||
node.waitStatus = Node.CANCELLED;
|
||||
// 如果当前节点是尾节点,将从后往前的第一个非取消状态的节点设置为尾节点
|
||||
// 更新失败的话,则进入else,如果更新成功,将tail的后继节点设置为null
|
||||
if (node == tail && compareAndSetTail(node, pred)) {
|
||||
compareAndSetNext(pred, predNext, null);
|
||||
} else {
|
||||
int ws;
|
||||
if (node == tail && compareAndSetTail(node, pred)) {
|
||||
compareAndSetNext(pred, predNext, null);
|
||||
} else {
|
||||
int ws;
|
||||
// 如果当前节点不是head的后继节点,1:判断当前节点前驱节点的是否为SIGNAL,2:如果不是,则把前驱节点设置为SINGAL看是否成功
|
||||
// 如果1和2中有一个为true,再判断当前节点的线程是否为null
|
||||
// 如果上述条件都满足,把当前节点的前驱节点的后继指针指向当前节点的后继节点
|
||||
if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) {
|
||||
Node next = node.next;
|
||||
if (next != null && next.waitStatus <= 0)
|
||||
compareAndSetNext(pred, predNext, next);
|
||||
} else {
|
||||
if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) {
|
||||
Node next = node.next;
|
||||
if (next != null && next.waitStatus <= 0)
|
||||
compareAndSetNext(pred, predNext, next);
|
||||
} else {
|
||||
// 如果当前节点是head的后继节点,或者上述条件不满足,那就唤醒当前节点的后继节点
|
||||
unparkSuccessor(node);
|
||||
}
|
||||
node.next = node; // help GC
|
||||
}
|
||||
unparkSuccessor(node);
|
||||
}
|
||||
node.next = node; // help GC
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -645,7 +645,7 @@ private void cancelAcquire(Node node) {
|
|||
>
|
||||
> ```java
|
||||
> do {
|
||||
> node.prev = pred = pred.prev;
|
||||
> node.prev = pred = pred.prev;
|
||||
> } while (pred.waitStatus > 0);
|
||||
> ```
|
||||
|
||||
|
|
@ -657,7 +657,7 @@ private void cancelAcquire(Node node) {
|
|||
// java.util.concurrent.locks.ReentrantLock
|
||||
|
||||
public void unlock() {
|
||||
sync.release(1);
|
||||
sync.release(1);
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -667,13 +667,13 @@ public void unlock() {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
public final boolean release(int arg) {
|
||||
if (tryRelease(arg)) {
|
||||
Node h = head;
|
||||
if (h != null && h.waitStatus != 0)
|
||||
unparkSuccessor(h);
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
if (tryRelease(arg)) {
|
||||
Node h = head;
|
||||
if (h != null && h.waitStatus != 0)
|
||||
unparkSuccessor(h);
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -684,19 +684,19 @@ public final boolean release(int arg) {
|
|||
|
||||
// 方法返回当前锁是不是没有被线程持有
|
||||
protected final boolean tryRelease(int releases) {
|
||||
// 减少可重入次数
|
||||
int c = getState() - releases;
|
||||
// 当前线程不是持有锁的线程,抛出异常
|
||||
if (Thread.currentThread() != getExclusiveOwnerThread())
|
||||
throw new IllegalMonitorStateException();
|
||||
boolean free = false;
|
||||
// 如果持有线程全部释放,将当前独占锁所有线程设置为null,并更新state
|
||||
if (c == 0) {
|
||||
free = true;
|
||||
setExclusiveOwnerThread(null);
|
||||
}
|
||||
setState(c);
|
||||
return free;
|
||||
// 减少可重入次数
|
||||
int c = getState() - releases;
|
||||
// 当前线程不是持有锁的线程,抛出异常
|
||||
if (Thread.currentThread() != getExclusiveOwnerThread())
|
||||
throw new IllegalMonitorStateException();
|
||||
boolean free = false;
|
||||
// 如果持有线程全部释放,将当前独占锁所有线程设置为null,并更新state
|
||||
if (c == 0) {
|
||||
free = true;
|
||||
setExclusiveOwnerThread(null);
|
||||
}
|
||||
setState(c);
|
||||
return free;
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -706,16 +706,16 @@ protected final boolean tryRelease(int releases) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
public final boolean release(int arg) {
|
||||
// 上边自定义的tryRelease如果返回true,说明该锁没有被任何线程持有
|
||||
if (tryRelease(arg)) {
|
||||
// 获取头结点
|
||||
Node h = head;
|
||||
// 头结点不为空并且头结点的waitStatus不是初始化节点情况,解除线程挂起状态
|
||||
if (h != null && h.waitStatus != 0)
|
||||
unparkSuccessor(h);
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
// 上边自定义的tryRelease如果返回true,说明该锁没有被任何线程持有
|
||||
if (tryRelease(arg)) {
|
||||
// 获取头结点
|
||||
Node h = head;
|
||||
// 头结点不为空并且头结点的waitStatus不是初始化节点情况,解除线程挂起状态
|
||||
if (h != null && h.waitStatus != 0)
|
||||
unparkSuccessor(h);
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -733,23 +733,23 @@ public final boolean release(int arg) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
private void unparkSuccessor(Node node) {
|
||||
// 获取头结点waitStatus
|
||||
int ws = node.waitStatus;
|
||||
if (ws < 0)
|
||||
compareAndSetWaitStatus(node, ws, 0);
|
||||
// 获取当前节点的下一个节点
|
||||
Node s = node.next;
|
||||
// 如果下个节点是null或者下个节点被cancelled,就找到队列最开始的非cancelled的节点
|
||||
if (s == null || s.waitStatus > 0) {
|
||||
s = null;
|
||||
// 就从尾部节点开始找,到队首,找到队列第一个waitStatus<0的节点。
|
||||
for (Node t = tail; t != null && t != node; t = t.prev)
|
||||
if (t.waitStatus <= 0)
|
||||
s = t;
|
||||
}
|
||||
// 如果当前节点的下个节点不为空,而且状态<=0,就把当前节点unpark
|
||||
if (s != null)
|
||||
LockSupport.unpark(s.thread);
|
||||
// 获取头结点waitStatus
|
||||
int ws = node.waitStatus;
|
||||
if (ws < 0)
|
||||
compareAndSetWaitStatus(node, ws, 0);
|
||||
// 获取当前节点的下一个节点
|
||||
Node s = node.next;
|
||||
// 如果下个节点是null或者下个节点被cancelled,就找到队列最开始的非cancelled的节点
|
||||
if (s == null || s.waitStatus > 0) {
|
||||
s = null;
|
||||
// 就从尾部节点开始找,到队首,找到队列第一个waitStatus<0的节点。
|
||||
for (Node t = tail; t != null && t != node; t = t.prev)
|
||||
if (t.waitStatus <= 0)
|
||||
s = t;
|
||||
}
|
||||
// 如果当前节点的下个节点不为空,而且状态<=0,就把当前节点unpark
|
||||
if (s != null)
|
||||
LockSupport.unpark(s.thread);
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -761,18 +761,18 @@ private void unparkSuccessor(Node node) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
private Node addWaiter(Node mode) {
|
||||
Node node = new Node(Thread.currentThread(), mode);
|
||||
// Try the fast path of enq; backup to full enq on failure
|
||||
Node pred = tail;
|
||||
if (pred != null) {
|
||||
node.prev = pred;
|
||||
if (compareAndSetTail(pred, node)) {
|
||||
pred.next = node;
|
||||
return node;
|
||||
}
|
||||
}
|
||||
enq(node);
|
||||
return node;
|
||||
Node node = new Node(Thread.currentThread(), mode);
|
||||
// Try the fast path of enq; backup to full enq on failure
|
||||
Node pred = tail;
|
||||
if (pred != null) {
|
||||
node.prev = pred;
|
||||
if (compareAndSetTail(pred, node)) {
|
||||
pred.next = node;
|
||||
return node;
|
||||
}
|
||||
}
|
||||
enq(node);
|
||||
return node;
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -788,8 +788,8 @@ private Node addWaiter(Node mode) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
private final boolean parkAndCheckInterrupt() {
|
||||
LockSupport.park(this);
|
||||
return Thread.interrupted();
|
||||
LockSupport.park(this);
|
||||
return Thread.interrupted();
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -799,24 +799,24 @@ private final boolean parkAndCheckInterrupt() {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
final boolean acquireQueued(final Node node, int arg) {
|
||||
boolean failed = true;
|
||||
try {
|
||||
boolean interrupted = false;
|
||||
for (;;) {
|
||||
final Node p = node.predecessor();
|
||||
if (p == head && tryAcquire(arg)) {
|
||||
setHead(node);
|
||||
p.next = null; // help GC
|
||||
failed = false;
|
||||
return interrupted;
|
||||
}
|
||||
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
|
||||
interrupted = true;
|
||||
}
|
||||
} finally {
|
||||
if (failed)
|
||||
cancelAcquire(node);
|
||||
}
|
||||
boolean failed = true;
|
||||
try {
|
||||
boolean interrupted = false;
|
||||
for (;;) {
|
||||
final Node p = node.predecessor();
|
||||
if (p == head && tryAcquire(arg)) {
|
||||
setHead(node);
|
||||
p.next = null; // help GC
|
||||
failed = false;
|
||||
return interrupted;
|
||||
}
|
||||
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
|
||||
interrupted = true;
|
||||
}
|
||||
} finally {
|
||||
if (failed)
|
||||
cancelAcquire(node);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -826,7 +826,7 @@ final boolean acquireQueued(final Node node, int arg) {
|
|||
// java.util.concurrent.locks.AbstractQueuedSynchronizer
|
||||
|
||||
static void selfInterrupt() {
|
||||
Thread.currentThread().interrupt();
|
||||
Thread.currentThread().interrupt();
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -873,17 +873,17 @@ ReentrantLock 的可重入性是 AQS 很好的应用之一,在了解完上述
|
|||
// java.util.concurrent.locks.ReentrantLock.FairSync#tryAcquire
|
||||
|
||||
if (c == 0) {
|
||||
if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) {
|
||||
setExclusiveOwnerThread(current);
|
||||
return true;
|
||||
}
|
||||
if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) {
|
||||
setExclusiveOwnerThread(current);
|
||||
return true;
|
||||
}
|
||||
}
|
||||
else if (current == getExclusiveOwnerThread()) {
|
||||
int nextc = c + acquires;
|
||||
if (nextc < 0)
|
||||
throw new Error("Maximum lock count exceeded");
|
||||
setState(nextc);
|
||||
return true;
|
||||
int nextc = c + acquires;
|
||||
if (nextc < 0)
|
||||
throw new Error("Maximum lock count exceeded");
|
||||
setState(nextc);
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -893,17 +893,17 @@ else if (current == getExclusiveOwnerThread()) {
|
|||
// java.util.concurrent.locks.ReentrantLock.Sync#nonfairTryAcquire
|
||||
|
||||
if (c == 0) {
|
||||
if (compareAndSetState(0, acquires)){
|
||||
setExclusiveOwnerThread(current);
|
||||
return true;
|
||||
}
|
||||
if (compareAndSetState(0, acquires)){
|
||||
setExclusiveOwnerThread(current);
|
||||
return true;
|
||||
}
|
||||
}
|
||||
else if (current == getExclusiveOwnerThread()) {
|
||||
int nextc = c + acquires;
|
||||
if (nextc < 0) // overflow
|
||||
throw new Error("Maximum lock count exceeded");
|
||||
setState(nextc);
|
||||
return true;
|
||||
int nextc = c + acquires;
|
||||
if (nextc < 0) // overflow
|
||||
throw new Error("Maximum lock count exceeded");
|
||||
setState(nextc);
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
|
|
@ -1015,7 +1015,7 @@ public class LeeMain {
|
|||
|
||||
## 参考资料
|
||||
|
||||
- Lea D. The java. util. concurrent synchronizer framework[J]. Science of Computer Programming, 2005, 58(3): 293-309.
|
||||
- Lea D. The java. util. concurrent synchronizer framework\[J]. Science of Computer Programming, 2005, 58(3): 293-309.
|
||||
- 《Java 并发编程实战》
|
||||
- [不可不说的 Java“锁”事](https://tech.meituan.com/2018/11/15/java-lock.html)
|
||||
|
||||
|
|
|
|||
|
|
@ -96,7 +96,7 @@ size: 0
|
|||
- **弱引用**:使用 WeakReference 修饰的对象被称为弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
|
||||
- **虚引用**:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用中唯一的作用就是用队列接收对象即将死亡的通知
|
||||
|
||||
接着再来看下代码,我们使用反射的方式来看看`GC`后`ThreadLocal`中的数据情况:(下面代码来源自:https://blog.csdn.net/thewindkee/article/details/103726942 本地运行演示 GC 回收场景)
|
||||
接着再来看下代码,我们使用反射的方式来看看`GC`后`ThreadLocal`中的数据情况:(下面代码来源自:<https://blog.csdn.net/thewindkee/article/details/103726942> 本地运行演示 GC 回收场景)
|
||||
|
||||
```java
|
||||
public class ThreadLocalDemo {
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue