2022-08-02 18:06:55 +08:00
|
|
|
|
---
|
2023-05-04 19:21:48 +08:00
|
|
|
|
title: RabbitMQ常见问题总结
|
2022-08-02 18:06:55 +08:00
|
|
|
|
category: 高性能
|
|
|
|
|
|
tag:
|
|
|
|
|
|
- 消息队列
|
|
|
|
|
|
head:
|
|
|
|
|
|
- - meta
|
|
|
|
|
|
- name: keywords
|
|
|
|
|
|
content: RabbitMQ,AMQP,Broker,Exchange,优先级队列,延迟队列
|
2022-08-04 21:00:03 +08:00
|
|
|
|
- - meta
|
2022-08-02 18:06:55 +08:00
|
|
|
|
- name: description
|
|
|
|
|
|
content: RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
|
|
|
|
|
|
---
|
|
|
|
|
|
|
|
|
|
|
|
> 本篇文章由 JavaGuide 收集自网络,原出处不明。
|
|
|
|
|
|
|
|
|
|
|
|
## RabbitMQ 是什么?
|
|
|
|
|
|
|
2023-04-28 17:31:44 +08:00
|
|
|
|
RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP 等,支持 AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
2023-04-28 17:31:44 +08:00
|
|
|
|
RabbitMQ 是使用 Erlang 编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。它同时实现了一个 Broker 构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load balance)或者数据持久化都有很好的支持。
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
|
|
|
|
|
PS:也可能直接问什么是消息队列?消息队列就是一个使用队列来通信的组件。
|
|
|
|
|
|
|
|
|
|
|
|
## RabbitMQ 特点?
|
|
|
|
|
|
|
|
|
|
|
|
- **可靠性**: RabbitMQ 使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等。
|
2023-09-19 12:03:55 +08:00
|
|
|
|
- **灵活的路由** : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
|
2022-08-02 18:06:55 +08:00
|
|
|
|
- **扩展性**: 多个 RabbitMQ 节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
|
|
|
|
|
|
- **高可用性** : 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。
|
|
|
|
|
|
- **多种协议**: RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP, MQTT 等多种消息 中间件协议。
|
|
|
|
|
|
- **多语言客户端** :RabbitMQ 几乎支持所有常用语言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等。
|
|
|
|
|
|
- **管理界面** : RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等。
|
|
|
|
|
|
- **插件机制** : RabbitMQ 提供了许多插件 , 以实现从多方面进行扩展,当然也可以编写自 己的插件。
|
|
|
|
|
|
|
2023-05-04 15:02:43 +08:00
|
|
|
|
## RabbitMQ 核心概念?
|
|
|
|
|
|
|
|
|
|
|
|
RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收件人的手上,RabbitMQ 就好比由邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说,RabbitMQ 模型更像是一种交换机模型。
|
|
|
|
|
|
|
|
|
|
|
|
RabbitMQ 的整体模型架构如下:
|
|
|
|
|
|
|
|
|
|
|
|
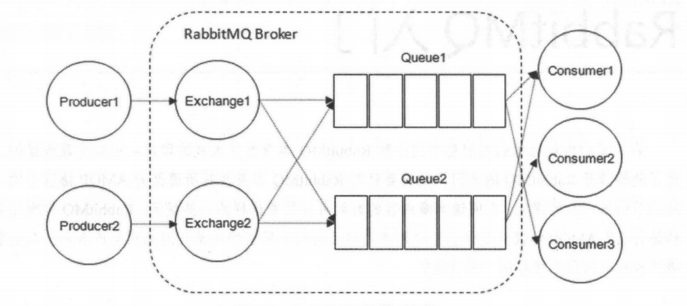
|
|
|
|
|
|
|
|
|
|
|
|
下面我会一一介绍上图中的一些概念。
|
|
|
|
|
|
|
|
|
|
|
|
### Producer(生产者) 和 Consumer(消费者)
|
|
|
|
|
|
|
|
|
|
|
|
- **Producer(生产者)** :生产消息的一方(邮件投递者)
|
|
|
|
|
|
- **Consumer(消费者)** :消费消息的一方(邮件收件人)
|
|
|
|
|
|
|
|
|
|
|
|
消息一般由 2 部分组成:**消息头**(或者说是标签 Label)和 **消息体**。消息体也可以称为 payLoad ,消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括 routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。生产者把消息交由 RabbitMQ 后,RabbitMQ 会根据消息头把消息发送给感兴趣的 Consumer(消费者)。
|
|
|
|
|
|
|
|
|
|
|
|
### Exchange(交换器)
|
|
|
|
|
|
|
|
|
|
|
|
在 RabbitMQ 中,消息并不是直接被投递到 **Queue(消息队列)** 中的,中间还必须经过 **Exchange(交换器)** 这一层,**Exchange(交换器)** 会把我们的消息分配到对应的 **Queue(消息队列)** 中。
|
|
|
|
|
|
|
|
|
|
|
|
**Exchange(交换器)** 用来接收生产者发送的消息并将这些消息路由给服务器中的队列中,如果路由不到,或许会返回给 **Producer(生产者)** ,或许会被直接丢弃掉 。这里可以将 RabbitMQ 中的交换器看作一个简单的实体。
|
|
|
|
|
|
|
|
|
|
|
|
**RabbitMQ 的 Exchange(交换器) 有 4 种类型,不同的类型对应着不同的路由策略**:**direct(默认)**,**fanout**, **topic**, 和 **headers**,不同类型的 Exchange 转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。
|
|
|
|
|
|
|
|
|
|
|
|
Exchange(交换器) 示意图如下:
|
|
|
|
|
|
|
|
|
|
|
|
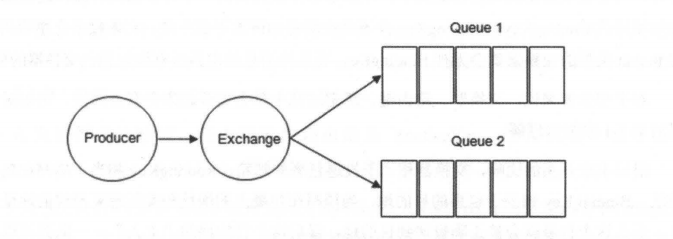
|
|
|
|
|
|
|
|
|
|
|
|
生产者将消息发给交换器的时候,一般会指定一个 **RoutingKey(路由键)**,用来指定这个消息的路由规则,而这个 **RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效**。
|
|
|
|
|
|
|
|
|
|
|
|
RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(消息队列)** 关联起来,在绑定的时候一般会指定一个 **BindingKey(绑定建)** ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。
|
|
|
|
|
|
|
|
|
|
|
|
Binding(绑定) 示意图:
|
|
|
|
|
|
|
|
|
|
|
|
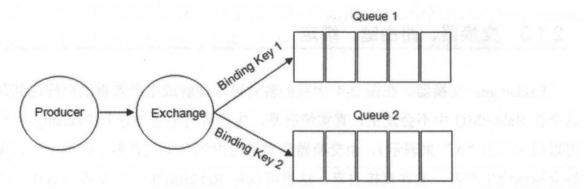
|
|
|
|
|
|
|
|
|
|
|
|
生产者将消息发送给交换器时,需要一个 RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如 fanout 类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
|
|
|
|
|
|
|
|
|
|
|
|
### Queue(消息队列)
|
|
|
|
|
|
|
|
|
|
|
|
**Queue(消息队列)** 用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
|
|
|
|
|
|
|
|
|
|
|
|
**RabbitMQ** 中消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是 topic 实际存储文件中的位移标识。 RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
|
|
|
|
|
|
|
|
|
|
|
|
**多个消费者可以订阅同一个队列**,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
|
|
|
|
|
|
|
|
|
|
|
|
**RabbitMQ** 不支持队列层面的广播消费,如果有广播消费的需求,需要在其上进行二次开发,这样会很麻烦,不建议这样做。
|
|
|
|
|
|
|
|
|
|
|
|
### Broker(消息中间件的服务节点)
|
|
|
|
|
|
|
|
|
|
|
|
对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者 RabbitMQ 服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台 RabbitMQ 服务器。
|
|
|
|
|
|
|
|
|
|
|
|
下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从 Broker 中消费数据的整个流程。
|
|
|
|
|
|
|
|
|
|
|
|
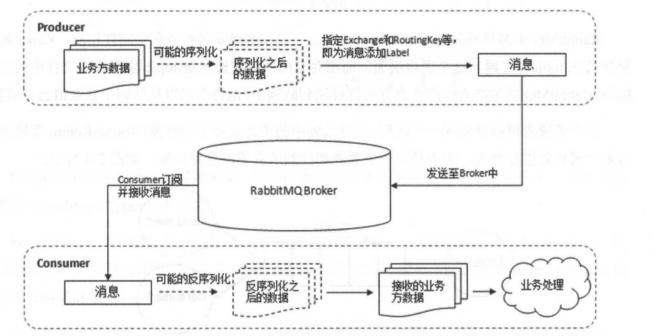
|
|
|
|
|
|
|
|
|
|
|
|
这样图 1 中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。
|
|
|
|
|
|
|
|
|
|
|
|
### Exchange Types(交换器类型)
|
|
|
|
|
|
|
|
|
|
|
|
RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP 规范里还提到两种 Exchange Type,分别为 system 与 自定义,这里不予以描述)。
|
|
|
|
|
|
|
|
|
|
|
|
**1、fanout**
|
|
|
|
|
|
|
|
|
|
|
|
fanout 类型的 Exchange 路由规则非常简单,它会把所有发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
|
|
|
|
|
|
|
|
|
|
|
|
**2、direct**
|
|
|
|
|
|
|
|
|
|
|
|
direct 类型的 Exchange 路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
|
|
|
|
|
|
|
|
|
|
|
|
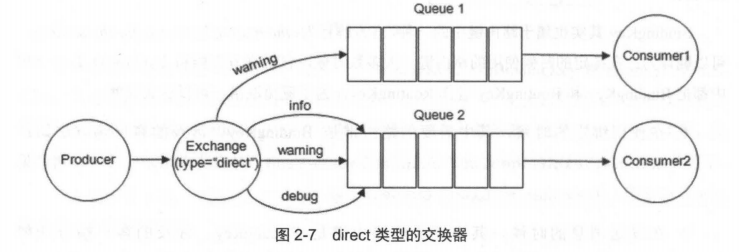
|
|
|
|
|
|
|
|
|
|
|
|
以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到 Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
|
|
|
|
|
|
|
|
|
|
|
|
direct 类型常用在处理有优先级的任务,根据任务的优先级把消息发送到对应的队列,这样可以指派更多的资源去处理高优先级的队列。
|
|
|
|
|
|
|
|
|
|
|
|
**3、topic**
|
|
|
|
|
|
|
|
|
|
|
|
前面讲到 direct 类型的交换器路由规则是完全匹配 BindingKey 和 RoutingKey ,但是这种严格的匹配方式在很多情况下不能满足实际业务的需求。topic 类型的交换器在匹配规则上进行了扩展,它与 direct 类型的交换器相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,但这里的匹配规则有些不同,它约定:
|
|
|
|
|
|
|
|
|
|
|
|
- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
|
|
|
|
|
|
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
|
|
|
|
|
|
- BindingKey 中可以存在两种特殊字符串“\*”和“#”,用于做模糊匹配,其中“\*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
|
|
|
|
|
|
|
|
|
|
|
|
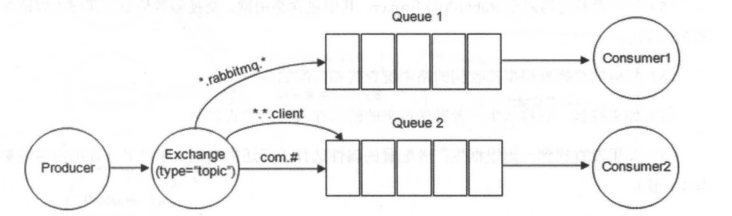
|
|
|
|
|
|
|
|
|
|
|
|
以上图为例:
|
|
|
|
|
|
|
|
|
|
|
|
- 路由键为 “com.rabbitmq.client” 的消息会同时路由到 Queue1 和 Queue2;
|
|
|
|
|
|
- 路由键为 “com.hidden.client” 的消息只会路由到 Queue2 中;
|
|
|
|
|
|
- 路由键为 “com.hidden.demo” 的消息只会路由到 Queue2 中;
|
|
|
|
|
|
- 路由键为 “java.rabbitmq.demo” 的消息只会路由到 Queue1 中;
|
|
|
|
|
|
- 路由键为 “java.util.concurrent” 的消息将会被丢弃或者返回给生产者(需要设置 mandatory 参数),因为它没有匹配任何路由键。
|
|
|
|
|
|
|
|
|
|
|
|
**4、headers(不推荐)**
|
|
|
|
|
|
|
|
|
|
|
|
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。在绑定队列和交换器时指定一组键值对,当发送消息到交换器时,RabbitMQ 会获取到该消息的 headers(也是一个键值对的形式),对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
|
|
|
|
|
|
|
2022-08-02 18:06:55 +08:00
|
|
|
|
## AMQP 是什么?
|
|
|
|
|
|
|
|
|
|
|
|
RabbitMQ 就是 AMQP 协议的 `Erlang` 的实现(当然 RabbitMQ 还支持 `STOMP2`、 `MQTT3` 等协议 ) AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定 。
|
|
|
|
|
|
|
|
|
|
|
|
RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。目前 RabbitMQ 最新版本默认支持的是 AMQP 0-9-1。
|
|
|
|
|
|
|
2023-05-05 12:39:01 +08:00
|
|
|
|
**AMQP 协议的三层**:
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
|
|
|
|
|
- **Module Layer**:协议最高层,主要定义了一些客户端调用的命令,客户端可以用这些命令实现自己的业务逻辑。
|
|
|
|
|
|
- **Session Layer**:中间层,主要负责客户端命令发送给服务器,再将服务端应答返回客户端,提供可靠性同步机制和错误处理。
|
2024-03-15 10:47:37 +08:00
|
|
|
|
- **TransportLayer**:最底层,主要传输二进制数据流,提供帧的处理、信道复用、错误检测和数据表示等。
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
2023-05-05 12:39:01 +08:00
|
|
|
|
**AMQP 模型的三大组件**:
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
2023-05-05 12:39:01 +08:00
|
|
|
|
- **交换器 (Exchange)**:消息代理服务器中用于把消息路由到队列的组件。
|
|
|
|
|
|
- **队列 (Queue)**:用来存储消息的数据结构,位于硬盘或内存中。
|
|
|
|
|
|
- **绑定 (Binding)**:一套规则,告知交换器消息应该将消息投递给哪个队列。
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
|
|
|
|
|
## **说说生产者 Producer 和消费者 Consumer?**
|
|
|
|
|
|
|
|
|
|
|
|
**生产者** :
|
|
|
|
|
|
|
|
|
|
|
|
- 消息生产者,就是投递消息的一方。
|
|
|
|
|
|
- 消息一般包含两个部分:消息体(`payload`)和标签(`Label`)。
|
|
|
|
|
|
|
2023-05-05 12:39:01 +08:00
|
|
|
|
**消费者**:
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
|
|
|
|
|
- 消费消息,也就是接收消息的一方。
|
|
|
|
|
|
- 消费者连接到 RabbitMQ 服务器,并订阅到队列上。消费消息时只消费消息体,丢弃标签。
|
|
|
|
|
|
|
|
|
|
|
|
## 说说 Broker 服务节点、Queue 队列、Exchange 交换器?
|
|
|
|
|
|
|
2023-09-11 10:18:53 +08:00
|
|
|
|
- **Broker**:可以看做 RabbitMQ 的服务节点。一般情况下一个 Broker 可以看做一个 RabbitMQ 服务器。
|
|
|
|
|
|
- **Queue**:RabbitMQ 的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
|
|
|
|
|
|
- **Exchange**:生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
|
|
|
|
|
## 什么是死信队列?如何导致的?
|
|
|
|
|
|
|
2024-04-10 00:20:28 +08:00
|
|
|
|
DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消息在一个队列中变成死信 (`dead message`) 之后,它能被重新发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
|
|
|
|
|
**导致的死信的几种原因**:
|
|
|
|
|
|
|
|
|
|
|
|
- 消息被拒(`Basic.Reject /Basic.Nack`) 且 `requeue = false`。
|
|
|
|
|
|
- 消息 TTL 过期。
|
|
|
|
|
|
- 队列满了,无法再添加。
|
|
|
|
|
|
|
|
|
|
|
|
## 什么是延迟队列?RabbitMQ 怎么实现延迟队列?
|
|
|
|
|
|
|
|
|
|
|
|
延迟队列指的是存储对应的延迟消息,消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费。
|
|
|
|
|
|
|
2023-04-28 17:31:44 +08:00
|
|
|
|
RabbitMQ 本身是没有延迟队列的,要实现延迟消息,一般有两种方式:
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
2023-04-28 17:31:44 +08:00
|
|
|
|
1. 通过 RabbitMQ 本身队列的特性来实现,需要使用 RabbitMQ 的死信交换机(Exchange)和消息的存活时间 TTL(Time To Live)。
|
|
|
|
|
|
2. 在 RabbitMQ 3.5.7 及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时,插件依赖 Erlang/OPT 18.0 及以上。
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
2023-04-28 17:31:44 +08:00
|
|
|
|
也就是说,AMQP 协议以及 RabbitMQ 本身没有直接支持延迟队列的功能,但是可以通过 TTL 和 DLX 模拟出延迟队列的功能。
|
2022-08-02 18:06:55 +08:00
|
|
|
|
|
|
|
|
|
|
## 什么是优先级队列?
|
|
|
|
|
|
|
|
|
|
|
|
RabbitMQ 自 V3.5.0 有优先级队列实现,优先级高的队列会先被消费。
|
|
|
|
|
|
|
|
|
|
|
|
可以通过`x-max-priority`参数来实现优先级队列。不过,当消费速度大于生产速度且 Broker 没有堆积的情况下,优先级显得没有意义。
|
|
|
|
|
|
|
|
|
|
|
|
## RabbitMQ 有哪些工作模式?
|
|
|
|
|
|
|
|
|
|
|
|
- 简单模式
|
|
|
|
|
|
- work 工作模式
|
|
|
|
|
|
- pub/sub 发布订阅模式
|
|
|
|
|
|
- Routing 路由模式
|
|
|
|
|
|
- Topic 主题模式
|
|
|
|
|
|
|
|
|
|
|
|
## RabbitMQ 消息怎么传输?
|
|
|
|
|
|
|
|
|
|
|
|
由于 TCP 链接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈,所以 RabbitMQ 使用信道的方式来传输数据。信道(Channel)是生产者、消费者与 RabbitMQ 通信的渠道,信道是建立在 TCP 链接上的虚拟链接,且每条 TCP 链接上的信道数量没有限制。就是说 RabbitMQ 在一条 TCP 链接上建立成百上千个信道来达到多个线程处理,这个 TCP 被多个线程共享,每个信道在 RabbitMQ 都有唯一的 ID,保证了信道私有性,每个信道对应一个线程使用。
|
|
|
|
|
|
|
|
|
|
|
|
## **如何保证消息的可靠性?**
|
|
|
|
|
|
|
|
|
|
|
|
消息到 MQ 的过程中搞丢,MQ 自己搞丢,MQ 到消费过程中搞丢。
|
|
|
|
|
|
|
|
|
|
|
|
- 生产者到 RabbitMQ:事务机制和 Confirm 机制,注意:事务机制和 Confirm 机制是互斥的,两者不能共存,会导致 RabbitMQ 报错。
|
|
|
|
|
|
- RabbitMQ 自身:持久化、集群、普通模式、镜像模式。
|
|
|
|
|
|
- RabbitMQ 到消费者:basicAck 机制、死信队列、消息补偿机制。
|
|
|
|
|
|
|
|
|
|
|
|
## 如何保证 RabbitMQ 消息的顺序性?
|
|
|
|
|
|
|
|
|
|
|
|
- 拆分多个 queue(消息队列),每个 queue(消息队列) 一个 consumer(消费者),就是多一些 queue (消息队列)而已,确实是麻烦点;
|
|
|
|
|
|
- 或者就一个 queue (消息队列)但是对应一个 consumer(消费者),然后这个 consumer(消费者)内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
|
|
|
|
|
|
|
|
|
|
|
|
## 如何保证 RabbitMQ 高可用的?
|
|
|
|
|
|
|
|
|
|
|
|
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
|
|
|
|
|
|
|
|
|
|
|
|
**单机模式**
|
|
|
|
|
|
|
|
|
|
|
|
Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用单机模式。
|
|
|
|
|
|
|
|
|
|
|
|
**普通集群模式**
|
|
|
|
|
|
|
|
|
|
|
|
意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。
|
|
|
|
|
|
|
|
|
|
|
|
你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
|
|
|
|
|
|
|
|
|
|
|
|
**镜像集群模式**
|
|
|
|
|
|
|
|
|
|
|
|
这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
|
|
|
|
|
|
|
|
|
|
|
|
这样的好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
|
|
|
|
|
|
|
|
|
|
|
|
## 如何解决消息队列的延时以及过期失效问题?
|
|
|
|
|
|
|
|
|
|
|
|
RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在 mq 里,而是大量的数据会直接搞丢。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上 12 点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
|
2023-08-07 18:56:33 +08:00
|
|
|
|
|
2023-09-11 10:18:53 +08:00
|
|
|
|
<!-- @include: @article-footer.snippet.md -->
|