[docs update]进一步完善CompletableFuture 详解
This commit is contained in:
parent
5782cb1851
commit
0039e726ed
|
|
@ -5,9 +5,11 @@ tag:
|
|||
- 数据结构
|
||||
---
|
||||
|
||||
海量数据处理以及缓存穿透这两个场景让我认识了 布隆过滤器 ,我查阅了一些资料来了解它,但是很多现成资料并不满足我的需求,所以就决定自己总结一篇关于布隆过滤器的文章。希望通过这篇文章让更多人了解布隆过滤器,并且会实际去使用它!
|
||||
布隆过滤器相信大家没用过的话,也已经听过了。
|
||||
|
||||
下面我们将分为几个方面来介绍布隆过滤器:
|
||||
布隆过滤器主要是为了解决海量数据的存在性问题。对于海量数据中判定某个数据是否存在且容忍轻微误差这一场景(比如缓存穿透、海量数据去重)来说,非常适合。
|
||||
|
||||
文章内容概览:
|
||||
|
||||
1. 什么是布隆过滤器?
|
||||
2. 布隆过滤器的原理介绍。
|
||||
|
|
@ -20,7 +22,7 @@ tag:
|
|||
|
||||
首先,我们需要了解布隆过滤器的概念。
|
||||
|
||||
布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于 1970 年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
|
||||
布隆过滤器(Bloom Filter,BF)是一个叫做 Bloom 的老哥于 1970 年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
|
||||
|
||||
Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 Bloom Filter 节省内存的核心所在。这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。
|
||||
|
||||
|
|
|
|||
|
|
@ -180,11 +180,11 @@ MySQL 8.x 中实现的索引新特性:
|
|||
|
||||
PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
|
||||
|
||||
1. **唯一索引(Unique Key)**:唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。** 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
|
||||
2. **普通索引(Index)**:**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。**
|
||||
3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
|
||||
1. **唯一索引(Unique Key)**:唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
|
||||
2. **普通索引(Index)**:普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
|
||||
3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
|
||||
因为只取前几个字符。
|
||||
4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
|
||||
4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
|
||||
|
||||
二级索引:
|
||||
|
||||
|
|
@ -228,8 +228,8 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
|||
|
||||
**缺点**:
|
||||
|
||||
- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据
|
||||
- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
|
||||
- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据
|
||||
- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
|
||||
|
||||
这是 MySQL 的表的文件截图:
|
||||
|
||||
|
|
@ -349,7 +349,7 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
|
|||
|
||||
### 最左前缀匹配原则
|
||||
|
||||
最左前缀匹配原则指的是,在使用联合索引时,**MySQL** 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配,如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询(如 **`>`**、**`<`**)才会停止匹配。对于 **`>=`**、**`<=`**、**`BETWEEN`**、**`like`** 前缀匹配的范围查询,并不会停止匹配。所以,我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
|
||||
最左前缀匹配原则指的是,在使用联合索引时,**MySQL** 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配,如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询(如 **`>`**、**`<`** )才会停止匹配。对于 **`>=`**、**`<=`**、**`BETWEEN`**、**`like`** 前缀匹配的范围查询,并不会停止匹配。所以,我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
|
||||
|
||||
相关阅读:[联合索引的最左匹配原则全网都在说的一个错误结论](https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ)。
|
||||
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ PS:也可能直接问什么是消息队列?消息队列就是一个使用队
|
|||
## RabbitMQ 特点?
|
||||
|
||||
- **可靠性**: RabbitMQ 使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等。
|
||||
- **灵活的路由** : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个 交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
|
||||
- **灵活的路由** : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
|
||||
- **扩展性**: 多个 RabbitMQ 节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
|
||||
- **高可用性** : 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。
|
||||
- **多种协议**: RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP, MQTT 等多种消息 中间件协议。
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ icon: jianli
|
|||
- 一般情况下你的简历上注明你会的东西才会被问到(Java 基础、集合、并发、MySQL、Redis 、Spring、Spring Boot 这些算是每个人必问的),比如写了你熟练使用 Redis,那面试官就很大概率会问你 Redis 的一些问题,再比如你写了你在项目中使用了消息队列,那面试官大概率问很多消息队列相关的问题。
|
||||
- 技能熟练度在很大程度上也决定了面试官提问的深度。
|
||||
|
||||
在不夸大自己能力的情况下,写出一份好的简历也是一项很棒的能力。
|
||||
在不夸大自己能力的情况下,写出一份好的简历也是一项很棒的能力。一般情况下,技术能力和学习能力比较厉害的,写出来的简历也比较棒!
|
||||
|
||||
## 简历模板
|
||||
|
||||
|
|
@ -36,13 +36,13 @@ icon: jianli
|
|||
|
||||
下面是我收集的一些还不错的简历模板:
|
||||
|
||||
- 适合中文的简历模板收集(推荐,免费):<https://github.com/dyweb/awesome-resume-for-chinese>
|
||||
- 木及简历(部分收费) : <https://www.mujicv.com/>
|
||||
- 简单简历(付费):<https://easycv.cn/>
|
||||
- 站长简历:<https://jianli.chinaz.com/>
|
||||
- 适合中文的简历模板收集(推荐,开源免费):<https://github.com/dyweb/awesome-resume-for-chinese>
|
||||
- 木及简历(推荐,部分免费) : <https://www.mujicv.com/>
|
||||
- 简单简历(推荐,部分免费):<https://easycv.cn/>
|
||||
- 极简简历(免费): <https://www.polebrief.com/index>
|
||||
- Markdown 简历排版工具(开源免费):<https://resume.mdnice.com/>
|
||||
- 站长简历(收费,支持AI生成):<https://jianli.chinaz.com/>
|
||||
- typora+markdown+css 自定义简历模板 :<https://github.com/Snailclimb/typora-markdown-resume>
|
||||
- 极简简历 : <https://www.polebrief.com/index>
|
||||
- Markdown 简历排版工具:<https://resume.mdnice.com/>
|
||||
- 超级简历(部分收费) : <https://www.wondercv.com/>
|
||||
|
||||
上面这些简历模板大多是只有 1 页内容,很难展现足够的信息量。如果你不是顶级大牛(比如 ACM 大赛获奖)的话,我建议还是尽可能多写一点可以突出你自己能力的内容(校招生 2 页之内,社招生 3 页之内,记得精炼语言,不要过多废话)。
|
||||
|
|
@ -53,6 +53,10 @@ icon: jianli
|
|||
- 技术名词最好规范大小写比较好,比如 java->Java ,spring boot -> Spring Boot 。这个虽然有些面试官不会介意,但是很多面试官都会在意这个细节的。
|
||||
- 中文和数字英文之间加上空格的话看起来会舒服一点。
|
||||
|
||||
另外,知识星球里还有真实的简历模板可供参考,地址:<https://t.zsxq.com/12ypxGNzU> (需加入[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)获取)。
|
||||
|
||||
|
||||
|
||||
## 简历内容
|
||||
|
||||
### 个人信息
|
||||
|
|
@ -138,6 +142,8 @@ icon: jianli
|
|||
|
||||
项目介绍尽量压缩在两行之内,不需要介绍太多,但也不要随便几个字就介绍完了。
|
||||
|
||||
|
||||
|
||||
**2、技术架构直接写技术名词就行,不要再介绍技术是干嘛的了,没意义,属于无效介绍。**
|
||||
|
||||

|
||||
|
|
@ -156,11 +162,17 @@ icon: jianli
|
|||
- 使用 xxx 技术优化了 xxx 模块,响应时间从 2s 降低到 0.2s。
|
||||
- ......
|
||||
|
||||
示例:
|
||||
个人职责介绍示例 :
|
||||
|
||||
- 使用 Sharding-JDBC 对 MySQL 数据库进行分库分表,优化千万级大表,单表数据量保持在 500w 以下。
|
||||
- 基于 Spring Cloud Gateway + Spring Security OAuth2 + JWT 实现微服务统一认证授权和鉴权,使用 RBAC 权限模型实现动态权限控制。
|
||||
- 参与项目订单模块的开发,负责订单创建、删除、查询等功能。
|
||||
- 整合 Canal + RocketMQ 将 MySQL 增量数据(如商品、订单数据)同步到 ES。
|
||||
- 排查并解决扣费模块由于扣费父任务和反作弊子任务使用同一个线程池导致的死锁问题。
|
||||
- 负责用户统计模块的开发,使用 CompletableFuture 并行加载后台用户统计模块的数据信息,平均相应时间从 3.5s 降低到 1s。
|
||||
- 使用 Sharding-JDBC 以用户 ID 后 4 位作为 Shard Key 对订单表进行分库分表,共 3 个库,每个库 2 个订单表,单表数据量保持在 500w 以下。自定义雪花算法生成订单 ID 的规则,把分片键同时作为的订单 ID 一部分,避免了额外存储订单 ID 与路由键的关系。
|
||||
- 热门数据(如首页、热门博客)使用 Redis+Caffeine 两级缓存,解决了缓存击穿和穿透问题,查询速度毫秒级,QPS 30w+。
|
||||
- 使用 CompletableFuture 优化购物车查询模块,对获取用户信息、商品详情、优惠券信息等异步 RPC 调用进行编排,响应时间从 2s 降低 0.2s。
|
||||
- 使用 CompletableFuture 优化购物车查询模块,对获取用户信息、商品详情、优惠券信息等异步 RPC 调用进行编排,响应时间从 2s 降低为 0.2s。
|
||||
- 搭建 EasyMock 服务,用于模拟第三方平台接口,方便了在网络隔离情况下的接口对接工作。
|
||||
|
||||
**4、如果你觉得你的项目技术比较落后的话,可以自己私下进行改进。重要的是让项目比较有亮点,通过什么方式就无所谓了。**
|
||||
|
||||
|
|
|
|||
|
|
@ -35,6 +35,15 @@ head:
|
|||
|
||||
“Write Once, Run Anywhere(一次编写,随处运行)”这句宣传口号,真心经典,流传了好多年!以至于,直到今天,依然有很多人觉得跨平台是 Java 语言最大的优势。实际上,跨平台已经不是 Java 最大的卖点了,各种 JDK 新特性也不是。目前市面上虚拟化技术已经非常成熟,比如你通过 Docker 就很容易实现跨平台了。在我看来,Java 强大的生态才是!
|
||||
|
||||
### Java SE vs Java EE
|
||||
|
||||
- Java SE(Java Platform,Standard Edition): Java 平台标准版,Java 编程语言的基础,它包含了支持 Java 应用程序开发和运行的核心类库以及虚拟机等核心组件。Java SE 可以用于构建桌面应用程序或简单的服务器应用程序。
|
||||
- Java EE(Java Platform, Enterprise Edition ):Java 平台企业版,建立在 Java SE 的基础上,包含了支持企业级应用程序开发和部署的标准和规范(比如 Servlet、JSP、EJB、JDBC、JPA、JTA、JavaMail、JMS)。 Java EE 可以用于构建分布式、可移植、健壮、可伸缩和安全的服务端 Java 应用程序,例如 Web 应用程序。
|
||||
|
||||
简单来说,Java SE 是 Java 的基础版本,Java EE 是 Java 的高级版本。Java SE 更适合开发桌面应用程序或简单的服务器应用程序,Java EE 更适合开发复杂的企业级应用程序或 Web 应用程序。
|
||||
|
||||
除了 Java SE 和 Java EE,还有一个 Java ME(Java Platform,Micro Edition)。Java ME 是 Java 的微型版本,主要用于开发嵌入式消费电子设备的应用程序,例如手机、PDA、机顶盒、冰箱、空调等。Java ME 无需重点关注,知道有这个东西就好了,现在已经用不上了。
|
||||
|
||||
### JVM vs JDK vs JRE
|
||||
|
||||
#### JVM
|
||||
|
|
@ -61,17 +70,17 @@ JRE(Java Runtime Environment) 是 Java 运行时环境。它是运行已编
|
|||
|
||||
### 什么是字节码?采用字节码的好处是什么?
|
||||
|
||||
在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以, Java 程序运行时相对来说还是高效的(不过,和 C++,Rust,Go 等语言还是有一定差距的),而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
|
||||
在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以, Java 程序运行时相对来说还是高效的(不过,和C、 C++,Rust,Go 等语言还是有一定差距的),而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
|
||||
|
||||
**Java 程序从源代码到运行的过程如下图所示**:
|
||||
|
||||
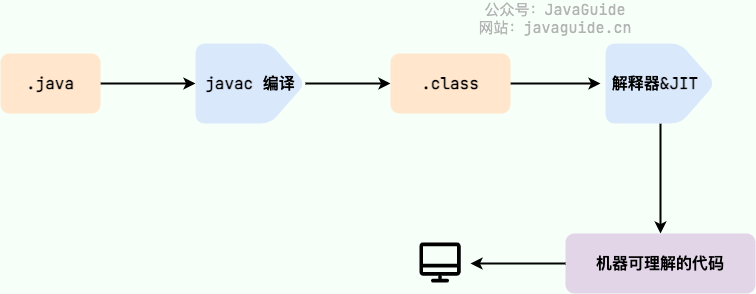
|
||||
|
||||
我们需要格外注意的是 `.class->机器码` 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT(just-in-time compilation) 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 **Java 是编译与解释共存的语言** 。
|
||||
我们需要格外注意的是 `.class->机器码` 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 **JIT(Just in Time Compilation)** 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 **Java 是编译与解释共存的语言** 。
|
||||
|
||||
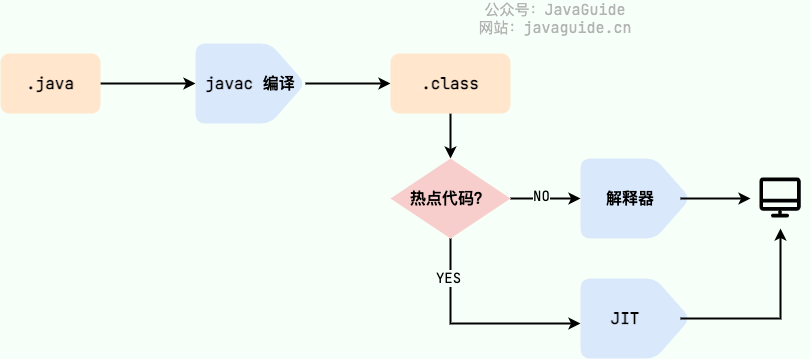
|
||||
|
||||
> HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。
|
||||
> HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。
|
||||
|
||||
JDK、JRE、JVM、JIT 这四者的关系如下图所示。
|
||||
|
||||
|
|
@ -81,12 +90,6 @@ JDK、JRE、JVM、JIT 这四者的关系如下图所示。
|
|||
|
||||
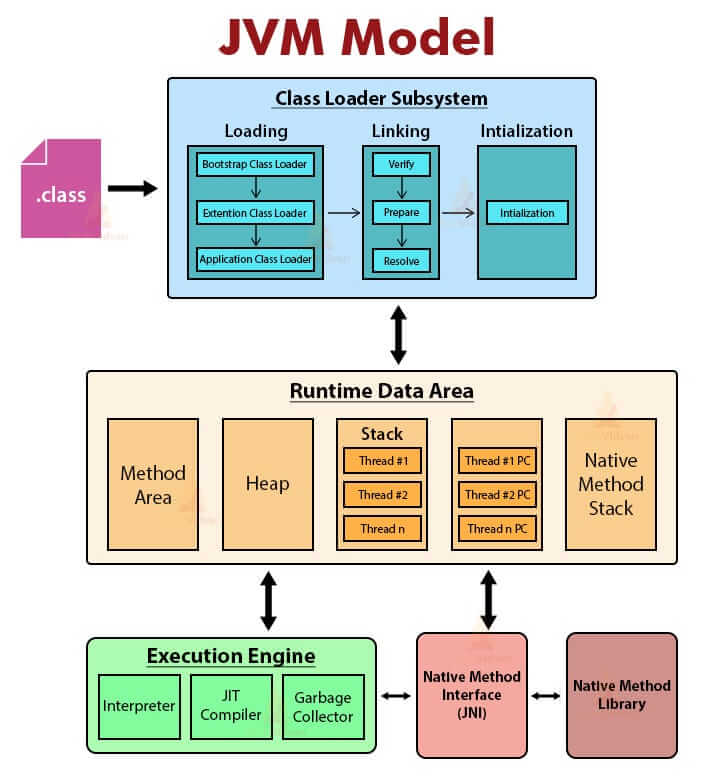
|
||||
|
||||
### 为什么不全部使用 AOT 呢?
|
||||
|
||||
AOT 可以提前编译节省启动时间,那为什么不全部使用这种编译方式呢?
|
||||
|
||||
长话短说,这和 Java 语言的动态特性有千丝万缕的联系了。举个例子,CGLIB 动态代理使用的是 ASM 技术,而这种技术大致原理是运行时直接在内存中生成并加载修改后的字节码文件也就是 `.class` 文件,如果全部使用 AOT 提前编译,也就不能使用 ASM 技术了。为了支持类似的动态特性,所以选择使用 JIT 即时编译器。
|
||||
|
||||
### 为什么说 Java 语言“编译与解释并存”?
|
||||
|
||||
其实这个问题我们讲字节码的时候已经提到过,因为比较重要,所以我们这里再提一下。
|
||||
|
|
@ -108,6 +111,25 @@ AOT 可以提前编译节省启动时间,那为什么不全部使用这种编
|
|||
|
||||
这是因为 Java 语言既具有编译型语言的特征,也具有解释型语言的特征。因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(`.class` 文件),这种字节码必须由 Java 解释器来解释执行。
|
||||
|
||||
### AOT 有什么优点?为什么不全部使用 AOT 呢?
|
||||
|
||||
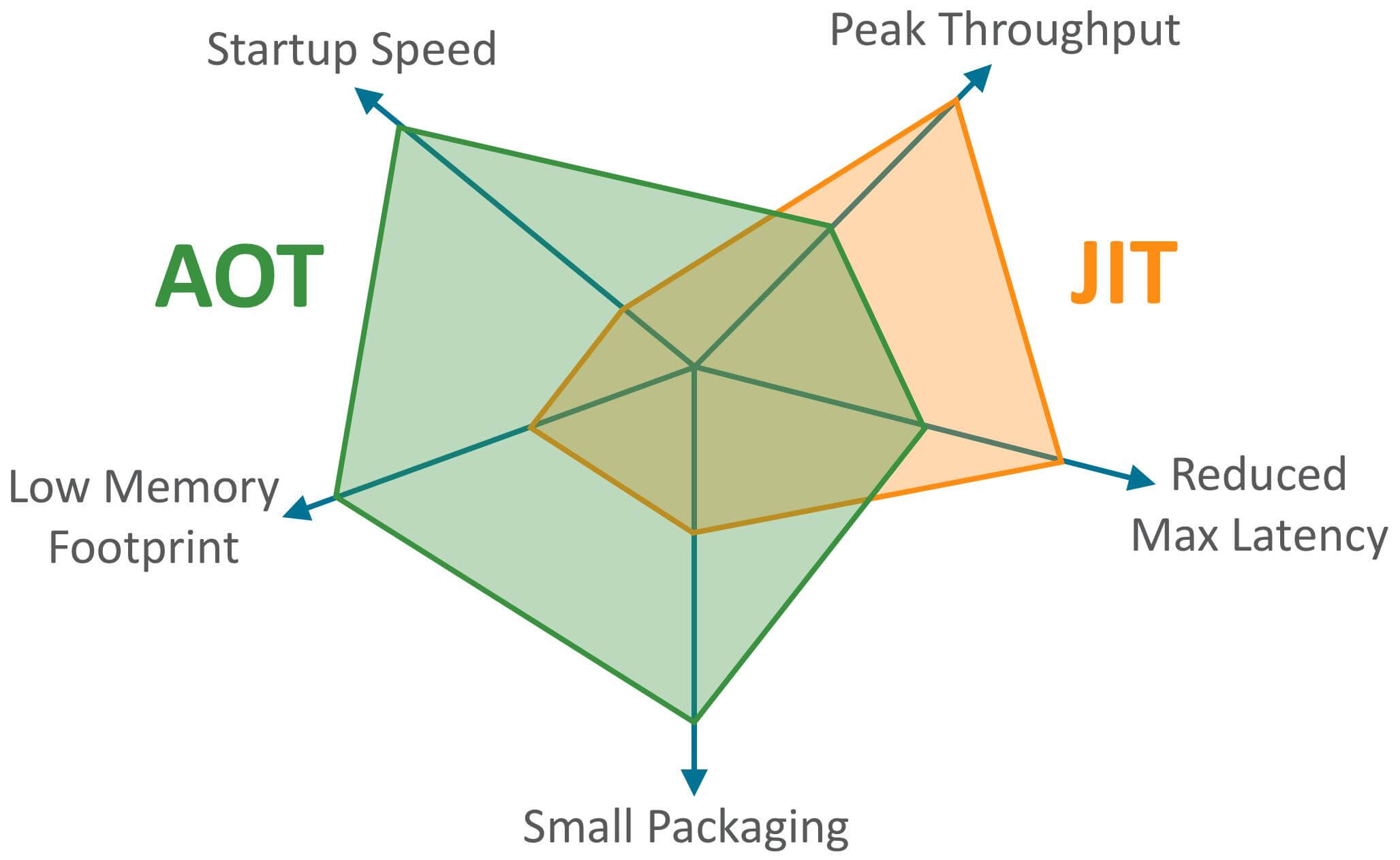
JDK 9 引入了一种新的编译模式 **AOT(Ahead of Time Compilation)** 。和 JIT 不同的是,这种编译模式会在程序被执行前就将其编译成机器码,属于静态编译(C、 C++,Rust,Go 等语言就是静态编译)。AOT 避免了 JIT 预热等各方面的开销,可以提高 Java 程序的启动速度,避免预热时间长。并且,AOT 还能减少内存占用和增强 Java 程序的安全性(AOT 编译后的代码不容易被反编译和修改),特别适合云原生场景。
|
||||
|
||||
**JIT 与 AOT 两者的关键指标对比**:
|
||||
|
||||
|
||||
|
||||
可以看出,AOT 的主要优势在于启动时间、内存占用和打包体积。JIT 的主要优势在于具备更高的极限处理能力,可以降低请求的最大延迟。
|
||||
|
||||
提到 AOT 就不得不提 [GraalVM](https://www.graalvm.org/) 了!GraalVM 是一种高性能的 JDK(完整的 JDK 发行版本),它可以运行 Java 和其他 JVM 语言,以及 JavaScript、Python 等非 JVM 语言。 GraalVM 不仅能提供 AOT 编译,还能提供 JIT 编译。感兴趣的同学,可以去看看 GraalVM 的官方文档:<https://www.graalvm.org/latest/docs/>。如果觉得官方文档看着比较难理解的话,也可以找一些文章来看看,比如:
|
||||
|
||||
- [基于静态编译构建微服务应用](https://mp.weixin.qq.com/s/4haTyXUmh8m-dBQaEzwDJw)
|
||||
- [走向 Native 化:Spring&Dubbo AOT 技术示例与原理讲解](https://cn.dubbo.apache.org/zh-cn/blog/2023/06/28/%e8%b5%b0%e5%90%91-native-%e5%8c%96springdubbo-aot-%e6%8a%80%e6%9c%af%e7%a4%ba%e4%be%8b%e4%b8%8e%e5%8e%9f%e7%90%86%e8%ae%b2%e8%a7%a3/)
|
||||
|
||||
**既然 AOT 这么多优点,那为什么不全部使用这种编译方式呢?**
|
||||
|
||||
我们前面也对比过 JIT 与 AOT,两者各有优点,只能说 AOT 更适合当下的云原生场景,对微服务架构的支持也比较友好。除此之外,AOT 编译无法支持 Java 的一些动态特性,如反射、动态代理、动态加载、JNI(Java Native Interface)等。然而,很多框架和库(如 Spring、CGLIB)都用到了这些特性。如果只使用 AOT 编译,那就没办法使用这些框架和库了,或者说需要针对性地去做适配和优化。举个例子,CGLIB 动态代理使用的是 ASM 技术,而这种技术大致原理是运行时直接在内存中生成并加载修改后的字节码文件也就是 `.class` 文件,如果全部使用 AOT 提前编译,也就不能使用 ASM 技术了。为了支持类似的动态特性,所以选择使用 JIT 即时编译器。
|
||||
|
||||
### Oracle JDK vs OpenJDK
|
||||
|
||||
可能在看这个问题之前很多人和我一样并没有接触和使用过 OpenJDK 。那么 Oracle JDK 和 OpenJDK 之间是否存在重大差异?下面我通过收集到的一些资料,为你解答这个被很多人忽视的问题。
|
||||
|
|
|
|||
|
|
@ -5,21 +5,77 @@ tag:
|
|||
- Java并发
|
||||
---
|
||||
|
||||
自己在项目中使用 `CompletableFuture` 比较多,看到很多开源框架中也大量使用到了 `CompletableFuture` 。
|
||||
一个接口可能需要调用 N 个其他服务的接口,这在项目开发中还是挺常见的。举个例子:用户请求获取订单信息,可能需要调用用户信息、商品详情、物流信息、商品推荐等接口,最后再汇总数据统一返回。
|
||||
|
||||
因此,专门写一篇文章来介绍这个 Java 8 才被引入的一个非常有用的用于异步编程的类。
|
||||
如果是串行(按顺序依次执行每个任务)执行的话,接口的响应速度会非常慢。考虑到这些接口之间有大部分都是 **无前后顺序关联** 的,可以 **并行执行** ,就比如说调用获取商品详情的时候,可以同时调用获取物流信息。通过并行执行多个任务的方式,接口的响应速度会得到大幅优化。
|
||||
|
||||
## 简单介绍
|
||||

|
||||
|
||||
`CompletableFuture` 同时实现了 `Future` 和 `CompletionStage` 接口。
|
||||
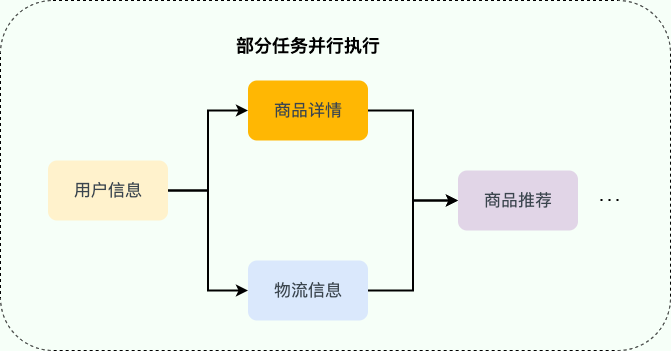
对于存在前后顺序关系的接口调用,可以进行编排,如下图所示。
|
||||
|
||||
|
||||
|
||||
1. 获取用户信息之后,才能调用商品详情和物流信息接口。
|
||||
2. 成功获取商品详情和物流信息之后,才能调用商品推荐接口。
|
||||
|
||||
对于 Java 程序来说,Java 8 才被引入的 `CompletableFuture` 可以帮助我们来做多个任务的编排,功能非常强大。
|
||||
|
||||
这篇文章是 `CompletableFuture` 的简单入门,带大家看看 `CompletableFuture` 常用的 API。
|
||||
|
||||
## Future 介绍
|
||||
|
||||
`Future` 类是异步思想的典型运用,主要用在一些需要执行耗时任务的场景,避免程序一直原地等待耗时任务执行完成,执行效率太低。具体来说是这样的:当我们执行某一耗时的任务时,可以将这个耗时任务交给一个子线程去异步执行,同时我们可以干点其他事情,不用傻傻等待耗时任务执行完成。等我们的事情干完后,我们再通过 `Future` 类获取到耗时任务的执行结果。这样一来,程序的执行效率就明显提高了。
|
||||
|
||||
这其实就是多线程中经典的 **Future 模式**,你可以将其看作是一种设计模式,核心思想是异步调用,主要用在多线程领域,并非 Java 语言独有。
|
||||
|
||||
在 Java 中,`Future` 类只是一个泛型接口,位于 `java.util.concurrent` 包下,其中定义了 5 个方法,主要包括下面这 4 个功能:
|
||||
|
||||
- 取消任务;
|
||||
- 判断任务是否被取消;
|
||||
- 判断任务是否已经执行完成;
|
||||
- 获取任务执行结果。
|
||||
|
||||
```java
|
||||
// V 代表了Future执行的任务返回值的类型
|
||||
public interface Future<V> {
|
||||
// 取消任务执行
|
||||
// 成功取消返回 true,否则返回 false
|
||||
boolean cancel(boolean mayInterruptIfRunning);
|
||||
// 判断任务是否被取消
|
||||
boolean isCancelled();
|
||||
// 判断任务是否已经执行完成
|
||||
boolean isDone();
|
||||
// 获取任务执行结果
|
||||
V get() throws InterruptedException, ExecutionException;
|
||||
// 指定时间内没有返回计算结果就抛出 TimeOutException 异常
|
||||
V get(long timeout, TimeUnit unit)
|
||||
|
||||
throws InterruptedException, ExecutionException, TimeoutExceptio
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
简单理解就是:我有一个任务,提交给了 `Future` 来处理。任务执行期间我自己可以去做任何想做的事情。并且,在这期间我还可以取消任务以及获取任务的执行状态。一段时间之后,我就可以 `Future` 那里直接取出任务执行结果。
|
||||
|
||||
## CompletableFuture 介绍
|
||||
|
||||
`Future` 在实际使用过程中存在一些局限性比如不支持异步任务的编排组合、获取计算结果的 `get()` 方法为阻塞调用。
|
||||
|
||||
Java 8 才被引入`CompletableFuture` 类可以解决`Future` 的这些缺陷。`CompletableFuture` 除了提供了更为好用和强大的 `Future` 特性之外,还提供了函数式编程、异步任务编排组合(可以将多个异步任务串联起来,组成一个完整的链式调用)等能力。
|
||||
|
||||
下面我们来简单看看 `CompletableFuture` 类的定义。
|
||||
|
||||
```java
|
||||
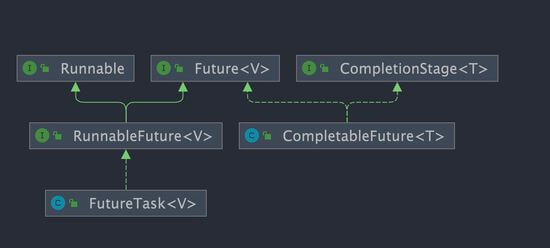
public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,`CompletableFuture` 同时实现了 `Future` 和 `CompletionStage` 接口。
|
||||
|
||||
|
||||
|
||||
`CompletionStage` 接口描述了一个异步计算的阶段。很多计算可以分成多个阶段或步骤,此时可以通过它将所有步骤组合起来,形成异步计算的流水线。
|
||||
|
||||
`CompletableFuture` 除了提供了更为好用和强大的 `Future` 特性之外,还提供了函数式编程的能力。
|
||||
|
||||

|
||||
|
|
@ -40,7 +96,7 @@ public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {
|
|||
|
||||
由于方法众多,所以这里不能一一讲解,下文中我会介绍大部分常见方法的使用。
|
||||
|
||||
## 常见操作
|
||||
## CompletableFuture 常见操作
|
||||
|
||||
### 创建 CompletableFuture
|
||||
|
||||
|
|
@ -374,7 +430,7 @@ completableFuture.get(); // ExecutionException
|
|||
|
||||
### 组合 CompletableFuture
|
||||
|
||||
你可以使用 `thenCompose()` 按顺序链接两个 `CompletableFuture` 对象。
|
||||
你可以使用 `thenCompose()` 按顺序链接两个 `CompletableFuture` 对象,实现异步的任务链。它的作用是将前一个任务的返回结果作为下一个任务的输入参数,从而形成一个依赖关系。
|
||||
|
||||
```java
|
||||
public <U> CompletableFuture<U> thenCompose(
|
||||
|
|
@ -403,9 +459,9 @@ CompletableFuture<String> future
|
|||
assertEquals("hello!world!", future.get());
|
||||
```
|
||||
|
||||
在实际开发中,这个方法还是非常有用的。比如说,我们先要获取用户信息然后再用用户信息去做其他事情。
|
||||
在实际开发中,这个方法还是非常有用的。比如说,task1 和 task2 都是异步执行的,但 task1 必须执行完成后才能开始执行 task2(task2 依赖 task1 的执行结果)。
|
||||
|
||||
和 `thenCompose()` 方法类似的还有 `thenCombine()` 方法, `thenCombine()` 同样可以组合两个 `CompletableFuture` 对象。
|
||||
和 `thenCompose()` 方法类似的还有 `thenCombine()` 方法, 它同样可以组合两个 `CompletableFuture` 对象。
|
||||
|
||||
```java
|
||||
CompletableFuture<String> completableFuture
|
||||
|
|
@ -421,6 +477,73 @@ assertEquals("hello!world!nice!", completableFuture.get());
|
|||
- `thenCompose()` 可以链接两个 `CompletableFuture` 对象,并将前一个任务的返回结果作为下一个任务的参数,它们之间存在着先后顺序。
|
||||
- `thenCombine()` 会在两个任务都执行完成后,把两个任务的结果合并。两个任务是并行执行的,它们之间并没有先后依赖顺序。
|
||||
|
||||
除了 `thenCompose()` 和 `thenCombine()` 之外, 还有一些其他的组合 `CompletableFuture` 的方法用于实现不同的效果,满足不同的业务需求。
|
||||
|
||||
例如,如果我们想要实现 task1 和 task2 中的任意一个任务执行完后就执行 task3 的话,可以使用 `acceptEither()`。
|
||||
|
||||
```java
|
||||
public CompletableFuture<Void> acceptEither(
|
||||
CompletionStage<? extends T> other, Consumer<? super T> action) {
|
||||
return orAcceptStage(null, other, action);
|
||||
}
|
||||
|
||||
public CompletableFuture<Void> acceptEitherAsync(
|
||||
CompletionStage<? extends T> other, Consumer<? super T> action) {
|
||||
return orAcceptStage(asyncPool, other, action);
|
||||
}
|
||||
```
|
||||
|
||||
简单举一个例子:
|
||||
|
||||
```java
|
||||
CompletableFuture<String> task = CompletableFuture.supplyAsync(() -> {
|
||||
System.out.println("任务1开始执行,当前时间:" + System.currentTimeMillis());
|
||||
try {
|
||||
Thread.sleep(500);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("任务1执行完毕,当前时间:" + System.currentTimeMillis());
|
||||
return "task1";
|
||||
});
|
||||
|
||||
CompletableFuture<String> task2 = CompletableFuture.supplyAsync(() -> {
|
||||
System.out.println("任务2开始执行,当前时间:" + System.currentTimeMillis());
|
||||
try {
|
||||
Thread.sleep(1000);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("任务2执行完毕,当前时间:" + System.currentTimeMillis());
|
||||
return "task2";
|
||||
});
|
||||
|
||||
task.acceptEitherAsync(task2, (res) -> {
|
||||
System.out.println("任务3开始执行,当前时间:" + System.currentTimeMillis());
|
||||
System.out.println("上一个任务的结果为:" + res);
|
||||
});
|
||||
|
||||
// 增加一些延迟时间,确保异步任务有足够的时间完成
|
||||
try {
|
||||
Thread.sleep(2000);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
任务1开始执行,当前时间:1695088058520
|
||||
任务2开始执行,当前时间:1695088058521
|
||||
任务1执行完毕,当前时间:1695088059023
|
||||
任务3开始执行,当前时间:1695088059023
|
||||
上一个任务的结果为:task1
|
||||
任务2执行完毕,当前时间:1695088059523
|
||||
```
|
||||
|
||||
任务组合操作`acceptEitherAsync()`会在异步任务 1 和异步任务 2 中的任意一个完成时触发执行任务 3,但是需要注意,这个触发时机是不确定的。如果任务 1 和任务 2 都还未完成,那么任务 3 就不能被执行。
|
||||
|
||||
### 并行运行多个 CompletableFuture
|
||||
|
||||
你可以通过 `CompletableFuture` 的 `allOf()`这个静态方法来并行运行多个 `CompletableFuture` 。
|
||||
|
|
@ -518,12 +641,80 @@ future1 done...
|
|||
abc
|
||||
```
|
||||
|
||||
## CompletableFuture 使用建议
|
||||
|
||||
### 使用自定义线程池
|
||||
|
||||
我们上面的代码示例中,为了方便,都没有选择自定义线程池。实际项目中,这是不可取的。
|
||||
|
||||
`CompletableFuture` 默认使用`ForkJoinPool.commonPool()` 作为执行器,这个线程池是全局共享的,可能会被其他任务占用,导致性能下降或者饥饿。因此,建议使用自定义的线程池来执行 `CompletableFuture` 的异步任务,可以提高并发度和灵活性。
|
||||
|
||||
```java
|
||||
private ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 10,
|
||||
0L, TimeUnit.MILLISECONDS,
|
||||
new LinkedBlockingQueue<Runnable>());
|
||||
|
||||
CompletableFuture.runAsync(() -> {
|
||||
//...
|
||||
}, executor);
|
||||
```
|
||||
|
||||
### 尽量避免使用 get()
|
||||
|
||||
`CompletableFuture`的`get()`方法是阻塞的,尽量避免使用。如果必须要使用的话,需要添加超时时间,否则可能会导致主线程一直等待,无法执行其他任务。
|
||||
|
||||
```java
|
||||
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
|
||||
try {
|
||||
Thread.sleep(10_000);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return "Hello, world!";
|
||||
});
|
||||
|
||||
// 获取异步任务的返回值,设置超时时间为 5 秒
|
||||
try {
|
||||
String result = future.get(5, TimeUnit.SECONDS);
|
||||
System.out.println(result);
|
||||
} catch (InterruptedException | ExecutionException | TimeoutException e) {
|
||||
// 处理异常
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
上面这段代码在调用 `get()` 时抛出了 `TimeoutException` 异常。这样我们就可以在异常处理中进行相应的操作,比如取消任务、重试任务、记录日志等。
|
||||
|
||||
### 正确进行异常处理
|
||||
|
||||
使用 `CompletableFuture`的时候一定要以正确的方式进行异常处理,避免异常丢失或者出现不可控问题。
|
||||
|
||||
下面是一些建议:
|
||||
|
||||
- 使用 `whenComplete` 方法可以在任务完成时触发回调函数,并正确地处理异常,而不是让异常被吞噬或丢失。
|
||||
- 使用 `exceptionally` 方法可以处理异常并重新抛出,以便异常能够传播到后续阶段,而不是让异常被忽略或终止。
|
||||
- 使用 `handle` 方法可以处理正常的返回结果和异常,并返回一个新的结果,而不是让异常影响正常的业务逻辑。
|
||||
- 使用 `CompletableFuture.allOf` 方法可以组合多个 `CompletableFuture`,并统一处理所有任务的异常,而不是让异常处理过于冗长或重复。
|
||||
- ......
|
||||
|
||||
### 合理组合多个异步任务
|
||||
|
||||
正确使用 `thenCompose()` 、 `thenCombine()` 、``acceptEither()`、`allOf()`、`anyOf() `等方法来组合多个异步任务,以满足实际业务的需求,提高程序执行效率。
|
||||
|
||||
实际使用中,我们还可以利用或者参考现成的异步任务编排框架,比如京东的 [asyncTool](https://gitee.com/jd-platform-opensource/asyncTool) 。
|
||||
|
||||
|
||||
|
||||
## 后记
|
||||
|
||||
这篇文章只是简单介绍了 `CompletableFuture` 比较常用的一些 API 。
|
||||
这篇文章只是简单介绍了 `CompletableFuture` 比较常用的一些 API 。如果想要深入学习的话,还可以多找一些书籍和博客看,比如下面几篇文章就挺不错:
|
||||
|
||||
如果想要深入学习的话,可以多找一些书籍和博客看。
|
||||
- [CompletableFuture 原理与实践-外卖商家端 API 的异步化 - 美团技术团队](https://tech.meituan.com/2022/05/12/principles-and-practices-of-completablefuture.html):这篇文章详细介绍了 `CompletableFuture` 在实际项目中的运用。参考这篇文章,可以对项目中类似的场景进行优化,也算是一个小亮点了。这种性能优化方式比较简单且效果还不错!
|
||||
- [读 RocketMQ 源码,学习并发编程三大神器 - 勇哥 java 实战分享](https://mp.weixin.qq.com/s/32Ak-WFLynQfpn0Cg0N-0A):这篇文章介绍了 RocketMQ 对`CompletableFuture`的应用。具体来说,从 RocketMQ 4.7 开始,RocketMQ 引入了 `CompletableFuture`来实现异步消息处理 。
|
||||
|
||||
另外,建议 G 友们可以看看京东的 [asyncTool](https://gitee.com/jd-platform-opensource/asyncTool) 这个并发框架,里面大量使用到了 `CompletableFuture` 。
|
||||
|
||||
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
Loading…
Reference in New Issue