| api | ||
| codegeex | ||
| configs | ||
| deployment | ||
| generations | ||
| resources | ||
| scripts | ||
| tests | ||
| vscode-extension | ||
| .gitmodules | ||
| LICENSE | ||
| MODEL_LICENSE | ||
| README_zh.md | ||
| README.md | ||
| requirements.txt | ||
| setup.py | ||
🏠 Homepage | 📖 Blog | 🪧 DEMO | 🤖 Download Model | 📄 Paper | 🌐 中文
🛠 VS Code, Jetbrains, Cloud Studio supported | 👋 Join our Discord, Slack, Telegram, WeChat
🌟 The newest CodeGeeX4 has been released. | 最新一代 CodeGeeX4 模型已经正式开源。
- CodeGeeX: A Multilingual Code Generation Model
CodeGeeX: A Multilingual Code Generation Model
We introduce CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters, pre-trained on a large code corpus of more than 20 programming languages. As of June 22, 2022, CodeGeeX has been trained on more than 850 billion tokens on a cluster of 1,536 Ascend 910 AI Processors. CodeGeeX has several unique features:
- Multilingual Code Generation: CodeGeeX has good performance for generating executable programs in several mainstream programming languages, including Python, C++, Java, JavaScript, Go, etc. DEMO
- Crosslingual Code Translation: CodeGeeX supports the translation of code snippets between different languages. Simply by one click, CodeGeeX can transform a program into any expected language with a high accuracy. DEMO
- Customizable Programming Assistant: CodeGeeX is available in the VS Code extension marketplace for free. It supports code completion, explanation, summarization and more, which empower users with a better coding experience. VS Code Extension
- Open-Source and Cross-Platform: All codes and model weights are publicly available for research purposes. CodeGeeX supports both Ascend and NVIDIA platforms. It supports inference in a single Ascend 910, NVIDIA V100 or A100. Apply Model Weights
HumanEval-X for Realistic Multilingual Benchmarking. To help standardize the evaluation of multilingual code generation and translation, we develop and release the HumanEval-X Benchmark. HumanEval-X is a new multilingual benchmark that contains 820 human-crafted coding problems in 5 programming languages (Python, C++, Java, JavaScript, and Go), each of these problems is associated with tests and solutions. Usage 🤗 Available in HuggingFace
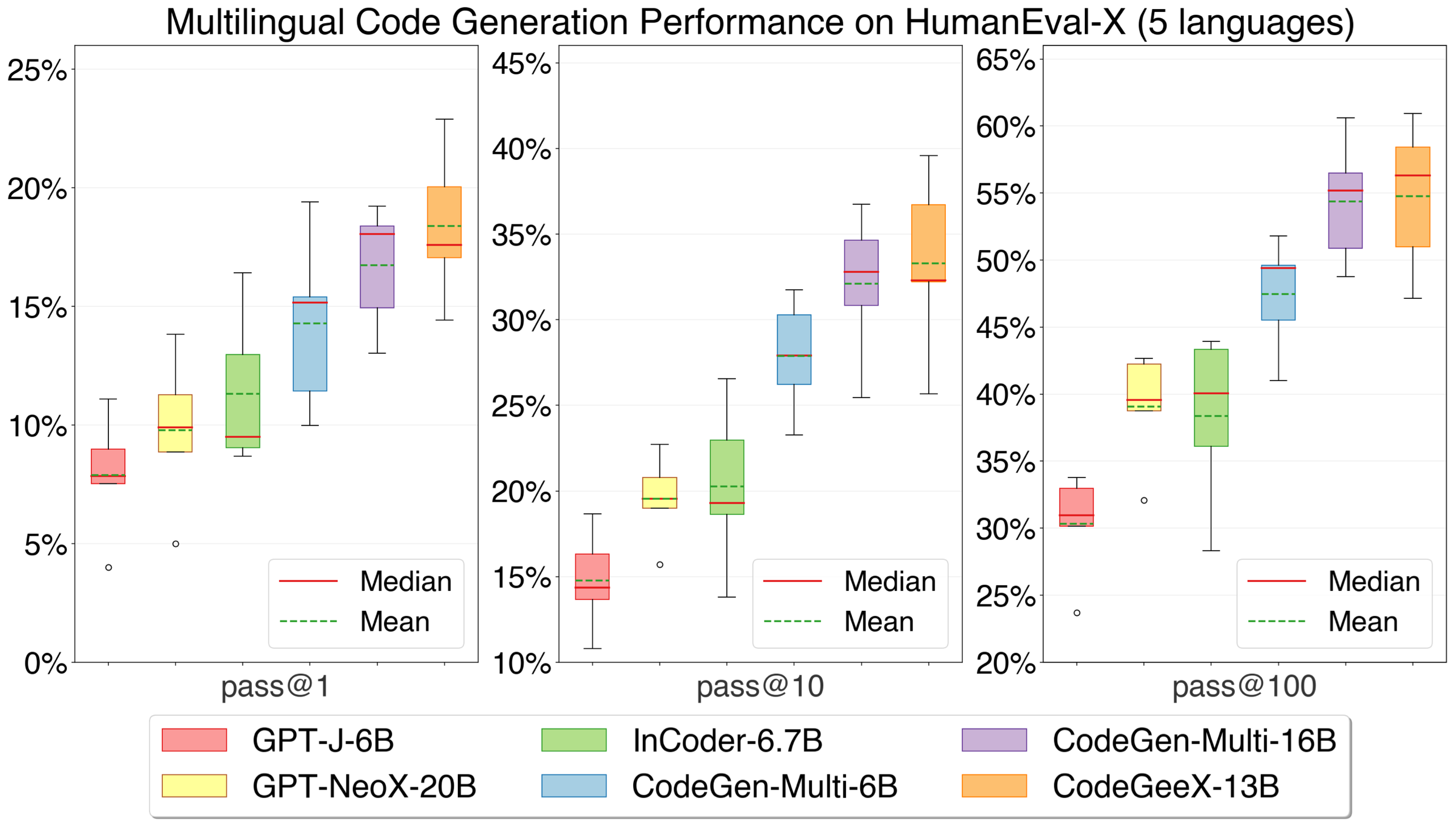
CodeGeeX achieves the highest average performance compared with other open-sourced multilingual baselines.
News
-
🌟 2023-07-24: CodeGeeX2 has been released, more powerful, faster, and lightweight. Support 100+ languages and many new features.
-
2023-5-16: CodeGeeX paper has been accepted by KDD 2023, Long Beach and will be represented during the conference.
-
2023-03-30: CodeGeeX paper is now available at arxiv.
-
2023-02-14: CodeGeeX now supports Cloud Studio, a fantastic web IDE from Tencent. Click on the badge on top of this page to quickly launch an environment to test CodeGeeX.
-
2023-02-13: Thanks a lot to OneFlow team for adding oneflow backend for CodeGeeX's inference (Even faster than FasterTransformer under FP16!). Check more details here.
-
2023-02: We are hosting CodeGeeX "Coding With AI" Hackathon, design cool applications based on CodeGeeX and win prizes (RTX 4090, DJI drone, etc)!
-
2022-12-31: We release the FasterTransformer version of CodeGeeX in codegeex-fastertransformer. The INT8 accelerated version reaches an a verage speed of <15ms/token. Happy new year to everyone!
-
2022-12-13: We release the source code of CodeGeeX VS Code extension in codegeex-vscode-extension. Follow QuickStart to start development.
-
2022-12-11: CodeGeeX is now available for Jetbrains IDEs (IntelliJ IDEA, PyCharm, GoLand, CLion, etc), download it here.
-
2022-12-04: We release source code of quantization (requires less GPU RAM: 27GB -> 15GB) and model parallelism (possible to run on multiple GPUs with <8G RAM).
-
2022-09-30: We release the cross-platform source code and models weights for both Ascend and NVIDIA platforms.
Getting Started
CodeGeeX is initially implemented in Mindspore and trained Ascend 910 AI Processors. We provide a torch-compatible version based on Megatron-LM to facilitate usage on GPU platforms.
Installation
Python 3.7+ / CUDA 11+ / PyTorch 1.10+ / DeepSpeed 0.6+ are required. Install codegeex package via:
git clone git@github.com:THUDM/CodeGeeX.git
cd CodeGeeX
pip install -e .
Or use CodeGeeX docker to quickly set up the environment (with nvidia-docker installed):
docker pull codegeex/codegeex:latest
# To enable GPU support, clarify device ids with --device
docker run --gpus '"device=0,1"' -it --ipc=host --name=codegeex codegeex/codegeex
Model Weights
Apply and download model weights through this link. You'll receive by mail urls.txt that contains temporary download links. We recommend you to use aria2 to download it via the following command (Please make sure you have enough disk space to download the checkpoint (~26GB)):
aria2c -x 16 -s 16 -j 4 --continue=true -i urls.txt
Run the following command to get the full model weights:
cat codegeex_13b.tar.gz.* > codegeex_13b.tar.gz
tar xvf codegeex_13b.tar.gz
Inference on GPUs
Have a try on generating the first program with CodeGeeX. First, specify the path of the model weights in configs/codegeex_13b.sh. Second, write the prompt (natural language description or code snippet) into a file, e.g., tests/test_prompt.txt, then run the following script:
# On a single GPU (with more than 27GB RAM)
bash ./scripts/test_inference.sh <GPU_ID> ./tests/test_prompt.txt
# With quantization (with more than 15GB RAM)
bash ./scripts/test_inference_quantized.sh <GPU_ID> ./tests/test_prompt.txt
# On multiple GPUs (with more than 6GB RAM, need to first convert ckpt to MP_SIZE partitions)
bash ./scripts/convert_ckpt_parallel.sh <LOAD_CKPT_PATH> <SAVE_CKPT_PATH> <MP_SIZE>
bash ./scripts/test_inference_parallel.sh <MP_SIZE> ./tests/test_prompt.txt
VS Code and Jetbrains Extension Guidance
Based on CodeGeeX, we also develop free extentions for VS Code and Jetbrains IDEs, and more in the future.
For VS Code, search "codegeex" in Marketplace or install it here. Detailed instructions can be found in VS Code Extension Guidance. For developers, we have also released the source code in codegeex-vscode-extension, please follow QuickStart to start development.
For Jetbrains IDEs, search "codegeex" in Plugins or install it here. Make sure your IDE version is 2021.1 or later. CodeGeeX now supports IntelliJ IDEA, PyCharm, GoLand, CLion, Android Studio, AppCode, Aqua, DataSpell, DataGrip, Rider, RubyMine, and WebStorm.
CodeGeeX: Architecture, Code Corpus, and Implementation
Architecture: CodeGeeX is a large-scale pre-trained programming language model based on transformers. It is a left-to-right autoregressive decoder, which takes code and natural language as input and predicts the probability of the next token. CodeGeeX contains 40 transformer layers with a hidden size of 5,120 for self-attention blocks and 20,480 for feed-forward layers, making its size reach 13 billion parameters. It supports a maximum sequence length of 2,048.
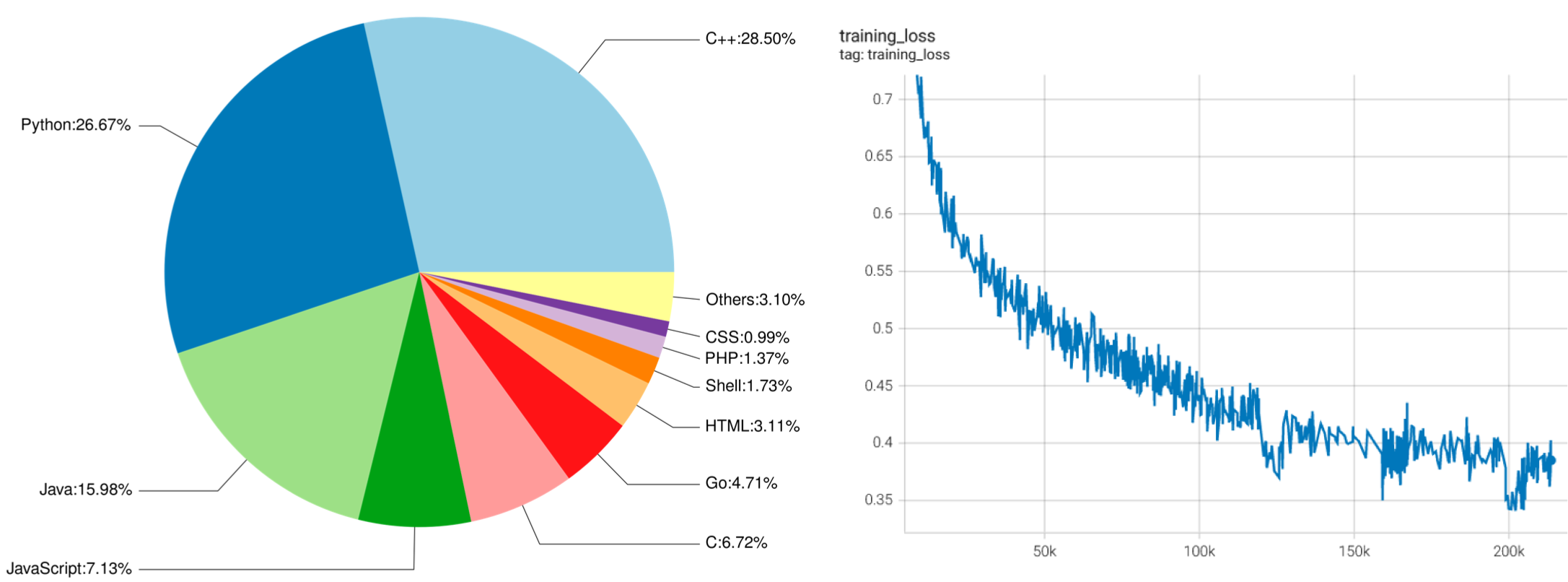
Left: the proportion of programming languages in CodeGeeX's training data. Right: the plot of training loss against the training steps of CodeGeeX.
Code Corpus: Our training data contains two parts. The first part is from open-sourced code datasets, The Pile and CodeParrot. The Pile contains a subset of code corpus that collects public repositories with more than 100 stars from GitHub, from which we select codes in 23 popular programming languages. The second part is supplementary data directly scrapped from the public GitHub repositories that do not appear in previous datasets, including Python, Java and C++. To obtain data of potentially higher quality, repositories with at least one star and its size smaller than 10MB are chosen. A file is filtered out if it 1) has more than 100 characters per line on average, 2) is automatically generated, 3) has a ratio of alphabet less than 40%, or 4) is bigger than 100KB or smaller than 1KB. To help the model distinguish different languages, we add a language-specific prefix at the beginning of each segment in the form of [Comment sign] language: [LANG], e.g., # language: Python. For tokenization, we use the same tokenizer as GPT-2 and process whitespaces as extra tokens, resulting in a vocabulary of 50,400 tokens. In total, the code corpus has 23 programming languages with 158.7B tokens.
Training: We implement CodeGeeX in Mindspore 1.7 and train it on 1,536 Ascend 910 AI Processor (32GB). The model weights are under FP16 format, except that we use FP32 for layer-norm and softmax for higher precision and stability. The entire model consumes about 27GB of memory. To increase the training efficiency, we adopt an 8-way model parallel training together with 192-way data parallel training, with ZeRO-2 optimizer enabled. The micro-batch size is 16 and the global batch size reaches 3,072. Moreover, we adopt techniques to further boost the training efficiency including the element-wise operator fusion, fast gelu activation, matrix multiplication dimension optimization, etc. The entire training process takes nearly two months, spanning from April 18 to June 22, 2022, during which 850B tokens were passed for training, i.e., 5+ epochs.
HumanEval-X: A new benchmark for Multilingual Program Synthesis
To better evaluate the multilingual ability of code generation models, we propose a new benchmark HumanEval-X. While previous works evaluate multilingual program synthesis under semantic similarity (e.g., CodeBLEU) which is often misleading, HumanEval-X evaluates the functional correctness of the generated programs. HumanEval-X consists of 820 high-quality human-crafted data samples (each with test cases) in Python, C++, Java, JavaScript, and Go, and can be used for various tasks.

An illustration of tasks supported by HumanEval-X. Declarations, docstrings, and solutions are marked with red, green, and blue respectively. Code generation uses declaration and docstring as input, to generate solution. Code translation uses declaration in both languages and translate the solution in source language to the one in target language.
In HumanEval-X, every sample in each language contains declaration, docstring, and solution, which can be combined in various ways to support different downstream tasks including generation, translation, summarization, etc. We currently focus on two tasks: code generation and code translation. For code generation, the model uses declaration and docstring as input to generate the solution. For code translation, the model uses declarations in both languages and the solution in the source language as input, to generate solutions in the target language. We remove the description during code translation to prevent the model from directly solving the problem. For both tasks, we use the unbiased pass@k metric proposed in Codex: \text{pass}@k:= \mathbb{E}[1-\frac{\tbinom{n-c}{k}}{\tbinom{n}{k}}], with n=200 and k\in(1,10,100).
Multilingual Code Generation
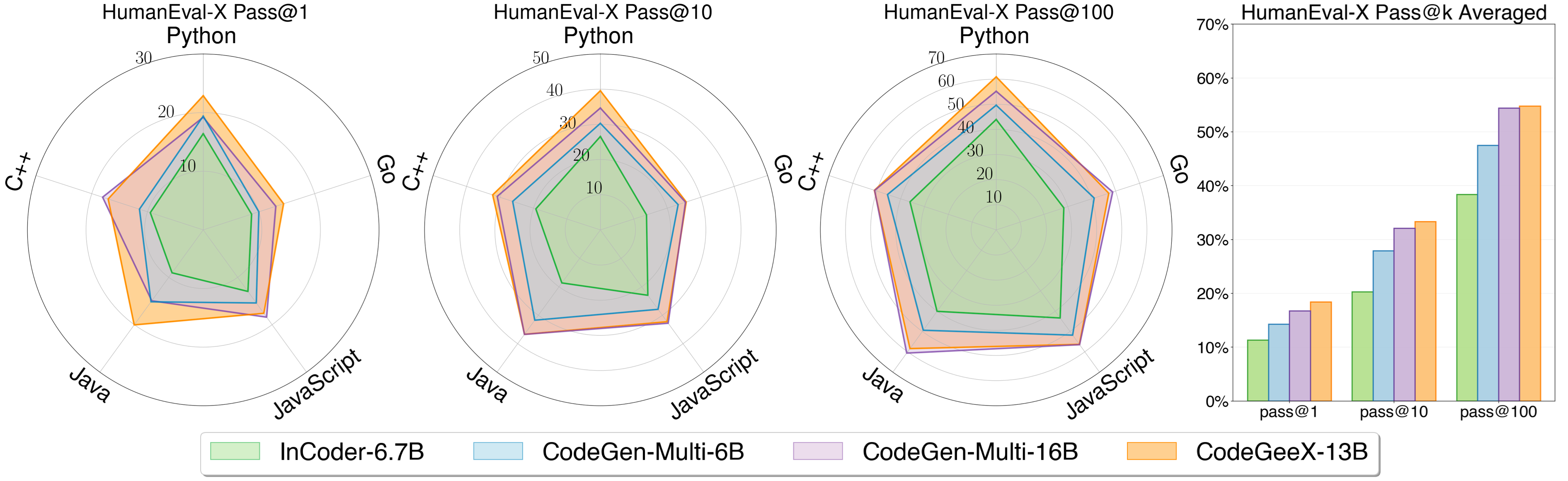
Left: the detailed pass@k (k=1,10,100) performance on code generation task for five languages in HumanEval-X. Right: the average performance of all languages of each model. CodeGeeX achieves the highest average performance compared with InCoder-6.7B, CodeGen-Multi-6B and CodeGen-Multi-16B.
We compare CodeGeeX with two other open-sourced code generation models, InCoder (from Meta) and CodeGen (from Salesforce). Specifically, InCoder-6.7B, CodeGen-Multi-6B and CodeGen-Multi-16B are considered. CodeGeeX significantly outperforms models with smaller scales (by 7.5%~16.3%) and is competitive with CodeGen-Multi-16B with a larger scale (average performance 54.76% vs. 54.39%). CodeGeeX achieves the best average performance across languages.
Crosslingual Code Translation
Results on HumanEval-X code translation task. Best language-wise performance are bolded.
We also evaluate the performance of translation across different programming languages. We test the zero-shot performance of CodeGeeX, as well as the fine-tuned CodeGeeX-13B-FT (fine-tuned using the training set of code translation tasks in XLCoST; Go is absent in the original set, we thus add a small set to it). The results indicate that models have a preference for languages, e.g., CodeGeeX is good at translating other languages to Python and C++, while CodeGen-Multi-16B is better at translating to JavaScript and Go; these could probably be due to the difference in language distribution in the training corpus. Among 20 translation pairs, we also observe that the performance of A-to-B and B-to-A are always negatively correlated, which might indicate that the current models are still not capable of learning all languages well.
How to use HumanEval-X and contribute to it?
For more details on how to use HumanEval-X, please see usage. We highly welcome the community to contribute to HumanEval-X by adding more problems or extending it to other languages, please check out the standard format of HumanEval-X and add a pull request.
Please kindly let us know if you have any comment or suggestion, via codegeex@aminer.cn.
Examples of Generation
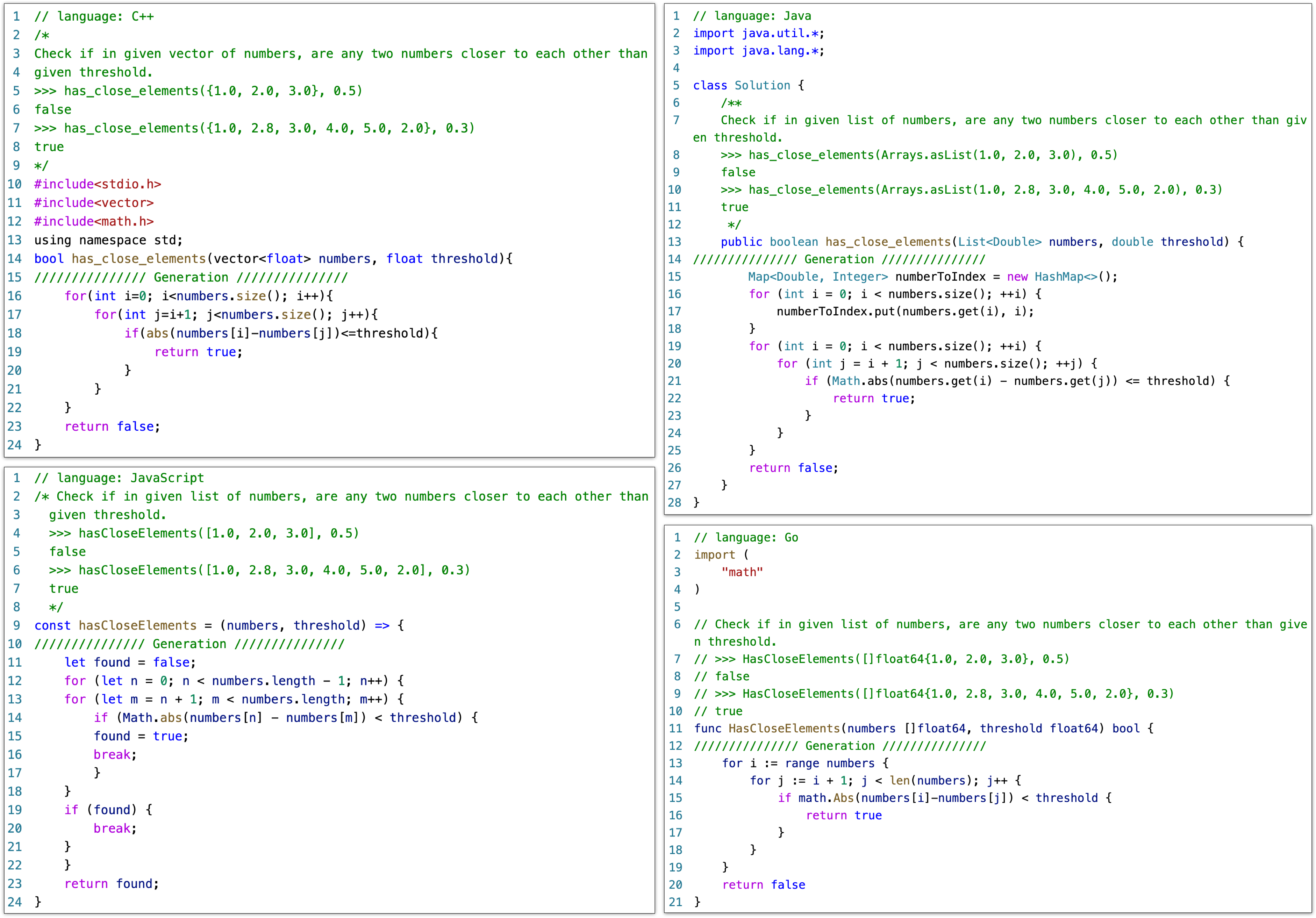
Acknowledgement
This project is supported by the National Science Foundation for Distinguished Young Scholars (No. 61825602).
Lead Contributors
Qinkai Zheng (Tsinghua KEG), Xiao Xia (Tsinghua KEG), Xu Zou (Tsinghua KEG)
Contributors
Tsinghua KEG---The Knowledge Engineering Group at Tsinghua: Aohan Zeng, Wendi Zheng, Lilong Xue
Zhilin Yang's Group at Tsinghua IIIS: Yifeng Liu, Yanru Chen, Yichen Xu (BUPT, work was done when visiting Tsinghua)
Peng Cheng Laboratory: Qingyu Chen, Zhongqi Li, Gaojun Fan
Zhipu.AI: Yufei Xue, Shan Wang, Jiecai Shan, Haohan Jiang, Lu Liu, Xuan Xue, Peng Zhang
Ascend and Mindspore Team: Yifan Yao, Teng Su, Qihui Deng, Bin Zhou
Data Annotations
Ruijie Cheng (Tsinghua), Peinan Yu (Tsinghua), Jingyao Zhang (Zhipu.AI), Bowen Huang (Zhipu.AI), Shaoyu Wang (Zhipu.AI)
Advisors
Zhilin Yang (Tsinghua IIIS), Yuxiao Dong (Tsinghua KEG), Wenguang Chen (Tsinghua PACMAN), Jie Tang (Tsinghua KEG)
Computation Sponsors
Zhipu.AI---an AI startup that aims to teach machines to think like humans
Project Leader
Jie Tang (Tsinghua KEG & BAAI)
License
Our code is licensed under the Apache-2.0 license. Our model is licensed under the license.
Citation
If you find our work useful, please cite:
@inproceedings{zheng2023codegeex,
title={CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Benchmarking on HumanEval-X},
author={Qinkai Zheng and Xiao Xia and Xu Zou and Yuxiao Dong and Shan Wang and Yufei Xue and Zihan Wang and Lei Shen and Andi Wang and Yang Li and Teng Su and Zhilin Yang and Jie Tang},
booktitle={Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages={5673--5684},
year={2023}
}