[docs update]完善Java集合常见面试题总结(上)
This commit is contained in:
parent
c71c2417aa
commit
f601220639
|
|
@ -168,7 +168,7 @@ MySQL 8.x 中实现的索引新特性:
|
|||
|
||||
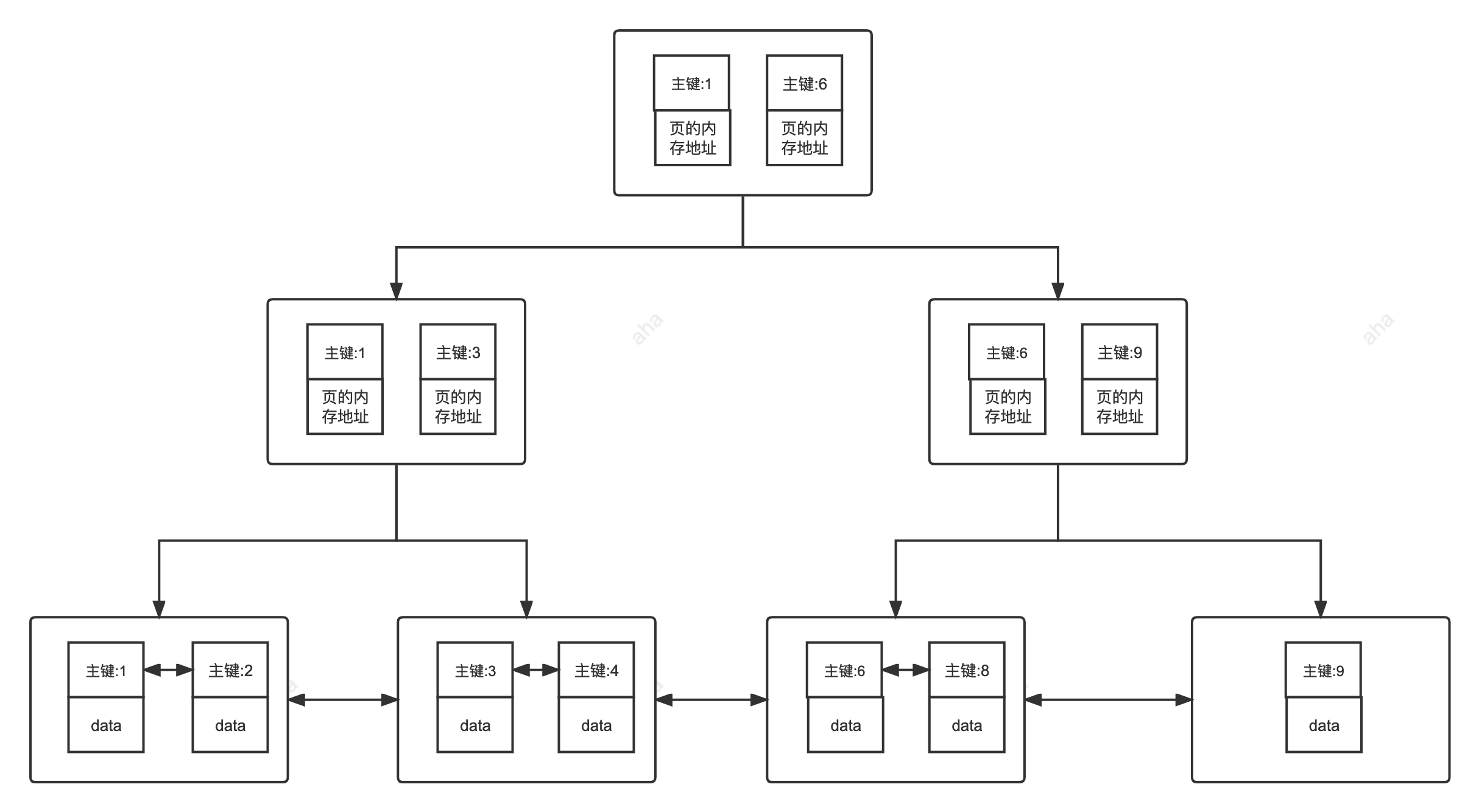
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在 null 值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
|
||||
|
||||
|
||||

|
||||
|
||||
## 二级索引
|
||||
|
||||
|
|
@ -186,7 +186,7 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
|||
|
||||
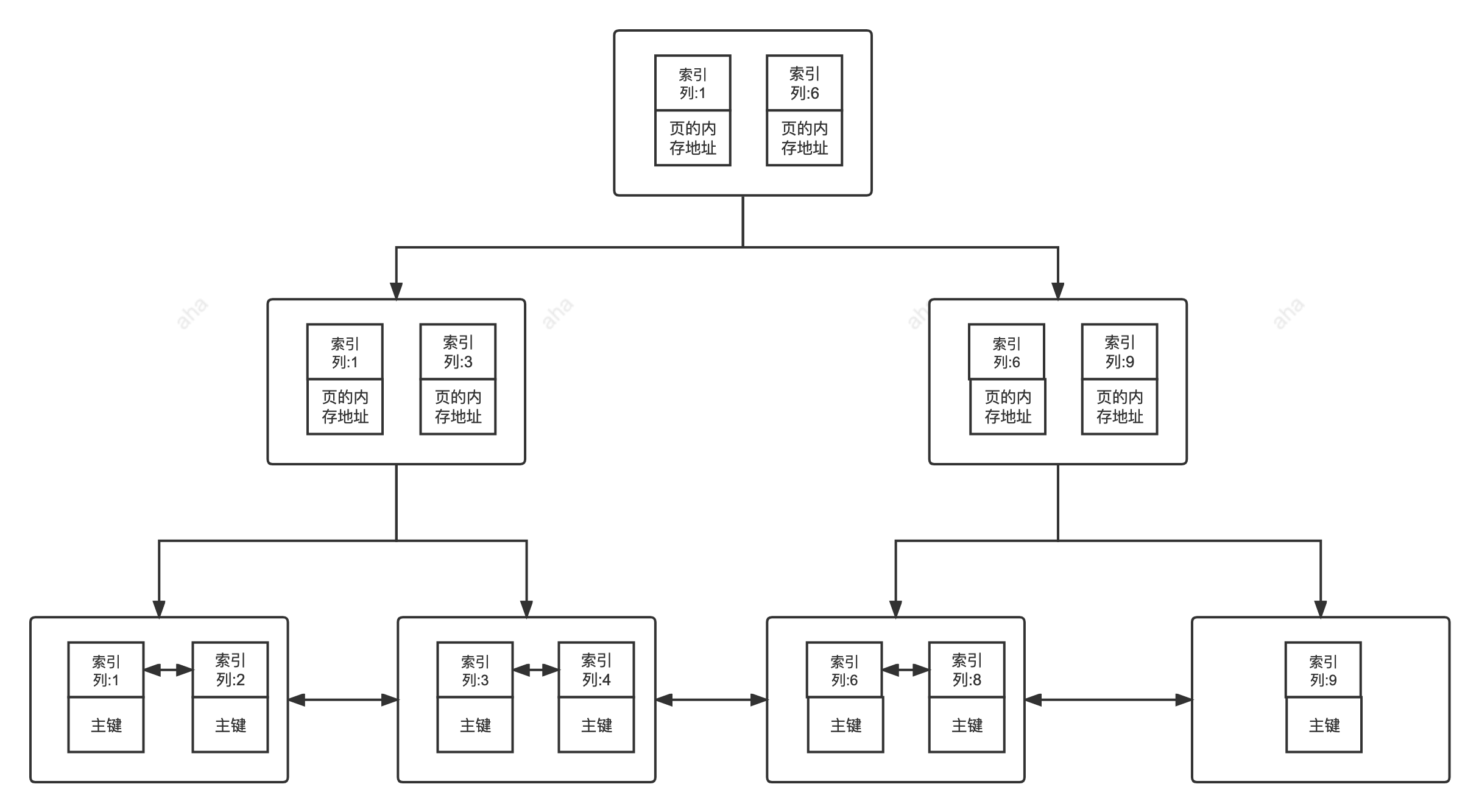
二级索引:
|
||||
|
||||
|
||||

|
||||
|
||||
## 聚簇索引与非聚簇索引
|
||||
|
||||
|
|
@ -231,11 +231,11 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
|||
|
||||
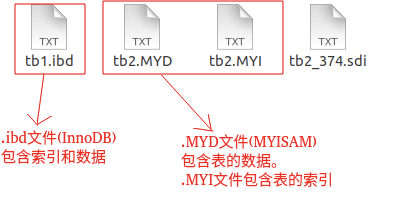
这是 MySQL 的表的文件截图:
|
||||
|
||||
|
||||

|
||||
|
||||
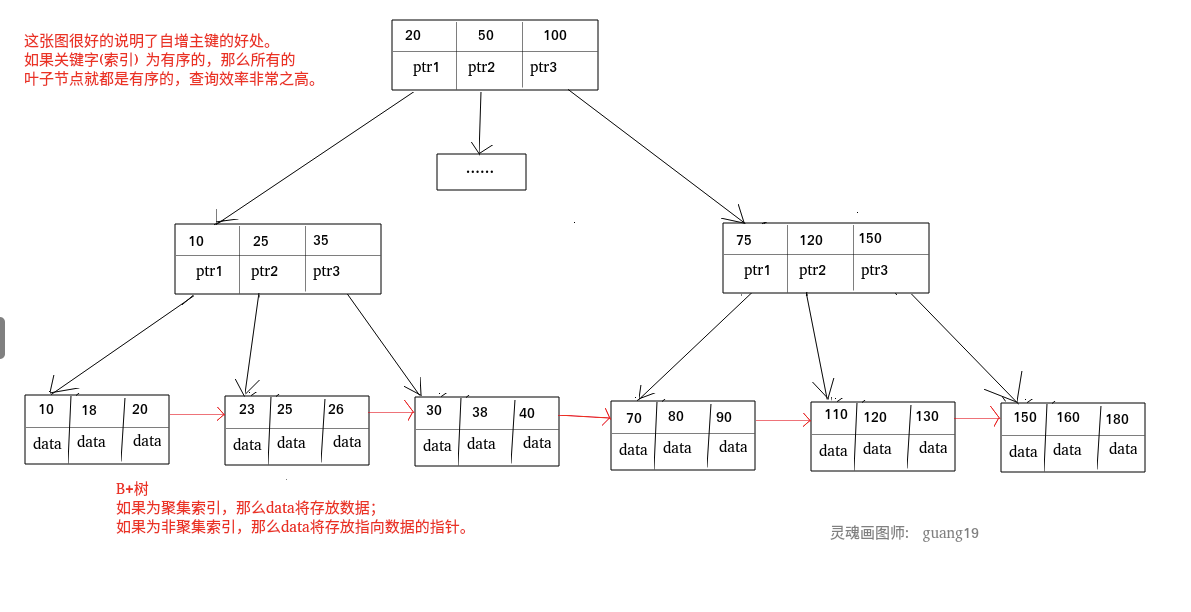
聚簇索引和非聚簇索引:
|
||||
|
||||
|
||||

|
||||
|
||||
#### 非聚簇索引一定回表查询吗(覆盖索引)?
|
||||
|
||||
|
|
@ -393,7 +393,7 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
|
|||
|
||||
索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
|
||||
|
||||
- 使用 `SELECT *` 进行查询;
|
||||
- ~~使用 `SELECT *` 进行查询;~~ `SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖;
|
||||
- 创建了组合索引,但查询条件未遵守最左匹配原则;
|
||||
- 在索引列上进行计算、函数、类型转换等操作;
|
||||
- 以 `%` 开头的 LIKE 查询比如 `like '%abc'`;
|
||||
|
|
|
|||
|
|
@ -20,4 +20,11 @@ icon: experience
|
|||
|
||||

|
||||
|
||||
相比于牛客网或者其他网站的面经,《Java面试指北》中整理的面经质量更高,并且,我会提供优质的参考资料。
|
||||
|
||||
有很多同学要说了:“为什么不直接给出具体答案呢?”。主要原因有如下两点:
|
||||
|
||||
1. 参考资料解释的要更详细一些,还可以顺便让你把相关的知识点复习一下。
|
||||
2. 给出的参考资料基本都是我的原创,假如后续我想对面试问题的答案进行完善,就不需要挨个把之前的面经写的答案给修改了(面试中的很多问题都是比较类似的)。当然了,我的原创文章也不太可能覆盖到面试的每个点,部面试问题的答案,我是精选的其他技术博主写的优质文章,文章质量都很高。
|
||||
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ Java 集合, 也叫作容器,主要是由两大接口派生而来:一个
|
|||
|
||||
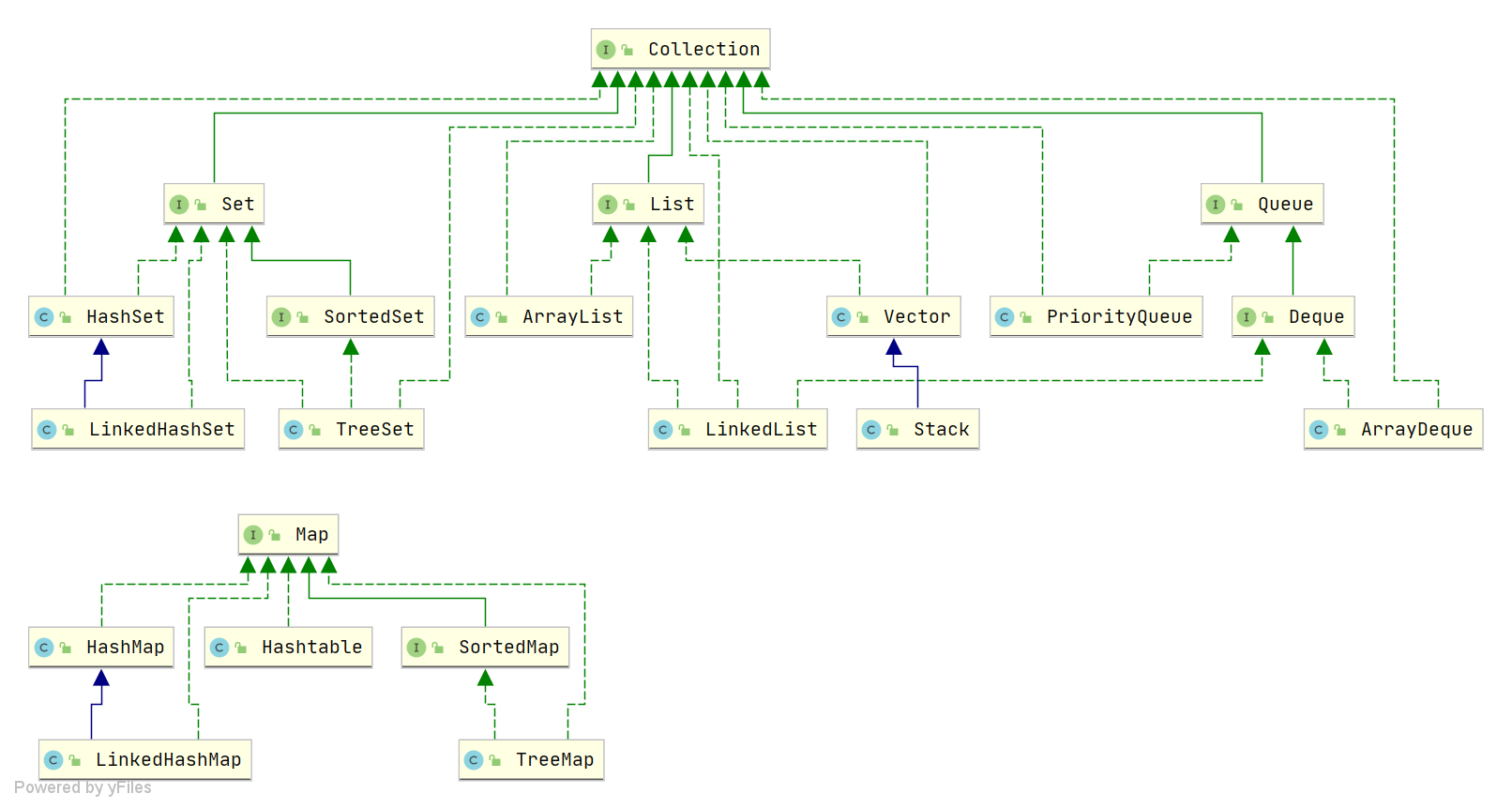
Java 集合框架如下图所示:
|
||||
|
||||
|
||||

|
||||
|
||||
注:图中只列举了主要的继承派生关系,并没有列举所有关系。比方省略了`AbstractList`, `NavigableSet`等抽象类以及其他的一些辅助类,如想深入了解,可自行查看源码。
|
||||
|
||||
|
|
@ -63,50 +63,180 @@ Java 集合框架如下图所示:
|
|||
|
||||
### 如何选用集合?
|
||||
|
||||
主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用 `Map` 接口下的集合,需要排序时选择 `TreeMap`,不需要排序时就选择 `HashMap`,需要保证线程安全就选用 `ConcurrentHashMap`。
|
||||
我们主要根据集合的特点来选择合适的集合。比如:
|
||||
|
||||
当我们只需要存放元素值时,就选择实现`Collection` 接口的集合,需要保证元素唯一时选择实现 `Set` 接口的集合比如 `TreeSet` 或 `HashSet`,不需要就选择实现 `List` 接口的比如 `ArrayList` 或 `LinkedList`,然后再根据实现这些接口的集合的特点来选用。
|
||||
- 我们需要根据键值获取到元素值时就选用 `Map` 接口下的集合,需要排序时选择 `TreeMap`,不需要排序时就选择 `HashMap`,需要保证线程安全就选用 `ConcurrentHashMap`。
|
||||
- 我们只需要存放元素值时,就选择实现`Collection` 接口的集合,需要保证元素唯一时选择实现 `Set` 接口的集合比如 `TreeSet` 或 `HashSet`,不需要就选择实现 `List` 接口的比如 `ArrayList` 或 `LinkedList`,然后再根据实现这些接口的集合的特点来选用。
|
||||
|
||||
### 为什么要使用集合?
|
||||
|
||||
当我们需要保存一组类型相同的数据的时候,我们应该是用一个容器来保存,这个容器就是数组,但是,使用数组存储对象具有一定的弊端,
|
||||
因为我们在实际开发中,存储的数据的类型是多种多样的,于是,就出现了“集合”,集合同样也是用来存储多个数据的。
|
||||
当我们需要存储一组类型相同的数据时,数组是最常用且最基本的容器之一。但是,使用数组存储对象存在一些不足之处,因为在实际开发中,存储的数据类型多种多样且数量不确定。这时,Java 集合就派上用场了。与数组相比,Java 集合提供了更灵活、更有效的方法来存储多个数据对象。Java 集合框架中的各种集合类和接口可以存储不同类型和数量的对象,同时还具有多样化的操作方式。相较于数组,Java 集合的优势在于它们的大小可变、支持泛型、具有内建算法等。总的来说,Java 集合提高了数据的存储和处理灵活性,可以更好地适应现代软件开发中多样化的数据需求,并支持高质量的代码编写。
|
||||
|
||||
数组的缺点是一旦声明之后,长度就不可变了;同时,声明数组时的数据类型也决定了该数组存储的数据的类型;而且,数组存储的数据是有序的、可重复的,特点单一。
|
||||
但是集合提高了数据存储的灵活性,Java 集合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据。
|
||||
## List
|
||||
|
||||
## Collection 子接口之 List
|
||||
### ArrayList 和 Array(数组)的区别?
|
||||
|
||||
### ArrayList 和 Vector 的区别?
|
||||
`ArrayList` 内部基于动态数组实现,比 `Array`(静态数组) 使用起来更加灵活:
|
||||
|
||||
- `ArrayList` 是 `List` 的主要实现类,底层使用 `Object[]`存储,适用于频繁的查找工作,线程不安全 ;
|
||||
- `Vector` 是 `List` 的古老实现类,底层使用`Object[]` 存储,线程安全的。
|
||||
- `ArrayList`会根据实际存储的元素动态地扩容或缩容,而 `Array` 被创建之后就不能改变它的长度了。
|
||||
- `ArrayList` 允许你使用泛型来确保类型安全,`Array` 则不可以。
|
||||
- `ArrayList` 中只能存储对象。对于基本类型数据,需要使用其对应的包装类(如 Integer、Double 等)。`Array` 可以直接存储基本类型数据,也可以存储对象。
|
||||
- `ArrayList` 支持插入、删除、遍历等常见操作,并且提供了丰富的 API 操作方法,比如 `add()`、`remove()`等。`Array` 只是一个固定长度的数组,只能按照下标访问其中的元素,不具备动态添加、删除元素的能力。
|
||||
- `ArrayList`创建时不需要指定大小,而`Array`创建时必须指定大小。
|
||||
|
||||
下面是二者使用的简单对比:
|
||||
|
||||
`Array`:
|
||||
|
||||
```java
|
||||
// 初始化一个 String 类型的数组
|
||||
String[] stringArr = new String[]{"hello", "world", "!"};
|
||||
// 修改数组元素的值
|
||||
stringArr[0] = "goodbye";
|
||||
System.out.println(Arrays.toString(stringArr));// [goodbye, world, !]
|
||||
// 删除数组中的元素,需要手动移动后面的元素
|
||||
for (int i = 0; i < stringArr.length - 1; i++) {
|
||||
stringArr[i] = stringArr[i + 1];
|
||||
}
|
||||
stringArr[stringArr.length - 1] = null;
|
||||
System.out.println(Arrays.toString(stringArr));// [world, !, null]
|
||||
```
|
||||
|
||||
`ArrayList` :
|
||||
|
||||
```java
|
||||
// 初始化一个 String 类型的 ArrayList
|
||||
ArrayList<String> stringList = new ArrayList<>(Arrays.asList("hello", "world", "!"));
|
||||
// 添加元素到 ArrayList 中
|
||||
stringList.add("goodbye");
|
||||
System.out.println(stringList);// [hello, world, !, goodbye]
|
||||
// 修改 ArrayList 中的元素
|
||||
stringList.set(0, "hi");
|
||||
System.out.println(stringList);// [hi, world, !, goodbye]
|
||||
// 删除 ArrayList 中的元素
|
||||
stringList.remove(0);
|
||||
System.out.println(stringList); // [world, !, goodbye]
|
||||
```
|
||||
|
||||
### ArrayList 和 Vector 的区别?(了解即可)
|
||||
|
||||
- `ArrayList` 是 `List` 的主要实现类,底层使用 `Object[]`存储,适用于频繁的查找工作,线程不安全 。
|
||||
- `Vector` 是 `List` 的古老实现类,底层使用`Object[]` 存储,线程安全。
|
||||
|
||||
### Vector 和 Stack 的区别?(了解即可)
|
||||
|
||||
- `Vector` 和 `Stack` 两者都是线程安全的,都是使用 `synchronized` 关键字进行同步处理。
|
||||
- `Stack` 继承自 `Vector`,是一个后进先出的栈,而 `Vector` 是一个列表。
|
||||
|
||||
随着 Java 并发编程的发展,`Vector` 和 `Stack` 已经被淘汰,推荐使用并发集合类(例如 `ConcurrentHashMap`、`CopyOnWriteArrayList` 等)或者手动实现线程安全的方法来提供安全的多线程操作支持。
|
||||
|
||||
### ArrayList 可以添加 null 值吗?
|
||||
|
||||
`ArrayList` 中可以存储任何类型的对象,包括 `null` 值。不过,不建议向`ArrayList` 中添加 `null` 值, `null` 值无意义,会让代码难以维护比如忘记做判空处理就会导致空指针异常。
|
||||
|
||||
示例代码:
|
||||
|
||||
```java
|
||||
ArrayList<String> listOfStrings = new ArrayList<>();
|
||||
listOfStrings.add(null);
|
||||
listOfStrings.add("java");
|
||||
System.out.println(listOfStrings);
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
[null, java]
|
||||
```
|
||||
|
||||
### ArrayList 插入和删除元素的时间复杂度?
|
||||
|
||||
对于插入:
|
||||
|
||||
- 头部插入:由于需要将所有元素都依次向后移动一个位置,因此时间复杂度是 O(n)。
|
||||
- 尾部插入:当 `ArrayList` 的容量未达到极限时,往列表末尾插入元素的时间复杂度是 O(1),因为它只需要在数组末尾添加一个元素即可;当容量已达到极限并且需要扩容时,则需要执行一次 O(n) 的操作将原数组复制到新的更大的数组中,然后再执行 O(1) 的操作添加元素。
|
||||
- 指定位置插入:需要将目标位置之后的所有元素都向后移动一个位置,然后再把新元素放入指定位置。这个过程需要移动平均 n/2 个元素,因此时间复杂度为 O(n)。
|
||||
|
||||
对于删除:
|
||||
|
||||
- 头部删除:由于需要将所有元素依次向前移动一个位置,因此时间复杂度是 O(n)。
|
||||
- 尾部删除:当删除的元素位于列表末尾时,时间复杂度为 O(1)。
|
||||
- 指定位置删除:需要将目标元素之后的所有元素向前移动一个位置以填补被删除的空白位置,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)。
|
||||
|
||||
这里简单列举一个例子:
|
||||
|
||||
```java
|
||||
// ArrayList的底层数组大小为10,此时存储了7个元素
|
||||
+---+---+---+---+---+---+---+---+---+---+
|
||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | | | |
|
||||
+---+---+---+---+---+---+---+---+---+---+
|
||||
0 1 2 3 4 5 6 7 8 9
|
||||
// 在索引为1的位置插入一个元素8,该元素后面的所有元素都要向右移动一位
|
||||
+---+---+---+---+---+---+---+---+---+---+
|
||||
| 1 | 8 | 2 | 3 | 4 | 5 | 6 | 7 | | |
|
||||
+---+---+---+---+---+---+---+---+---+---+
|
||||
0 1 2 3 4 5 6 7 8 9
|
||||
// 删除索引为1的位置的元素,该元素后面的所有元素都要向左移动一位
|
||||
+---+---+---+---+---+---+---+---+---+---+
|
||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | | | |
|
||||
+---+---+---+---+---+---+---+---+---+---+
|
||||
0 1 2 3 4 5 6 7 8 9
|
||||
```
|
||||
|
||||
### LinkedList 插入和删除元素的时间复杂度?
|
||||
|
||||
- 头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
|
||||
- 尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
|
||||
- 指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)。
|
||||
|
||||
这里简单列举一个例子:
|
||||
|
||||
```java
|
||||
// LinkedList中有5个元素
|
||||
+---+ +---+ +---+ +---+ +---+
|
||||
| 1 |--->| 2 |--->| 3 |--->| 4 |--->| 5 |
|
||||
+---+ +---+ +---+ +---+ +---+
|
||||
// 在节点2和3之间插入一个新节点6
|
||||
// 我们需要先移动到节点2这里,再修改节点2和节点6的指针(节点2指向节点6,节点6指向节点3)
|
||||
+---+ +---+ +---+ +---+ +---+ +---+
|
||||
| 1 |--->| 2 |--->| 6 |--->| 3 |--->| 4 |--->| 5 |
|
||||
+---+ +---+ +---+ +---+ +---+ +---+
|
||||
// 删除节点6
|
||||
// 我们需要先移动到节点3这里,找到它的前一个节点和后一个节点,然后再修改节点2的指针(指向节点3)
|
||||
+---+ +---+ +---+ +---+ +---+
|
||||
| 1 |--->| 2 |--->| 3 |--->| 4 |--->| 5 |
|
||||
+---+ +---+ +---+ +---+ +---+
|
||||
```
|
||||
|
||||
### LinkedList 为什么不能实现 RandomAccess 接口?
|
||||
|
||||
`RandomAccess` 是一个标记接口,用来表明实现该接口的类支持随机访问(即可以通过索引快速访问元素)。由于 `LinkedList` 底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,所以不能实现 `RandomAccess` 接口。
|
||||
|
||||
### ArrayList 与 LinkedList 区别?
|
||||
|
||||
- **是否保证线程安全:** `ArrayList` 和 `LinkedList` 都是不同步的,也就是不保证线程安全;
|
||||
- **底层数据结构:** `ArrayList` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
|
||||
- **插入和删除是否受元素位置的影响:**
|
||||
- `ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行`add(E e)`方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。
|
||||
- `LinkedList` 采用链表存储,所以,如果是在头尾插入或者删除元素不受元素位置的影响(`add(E e)`、`addFirst(E e)`、`addLast(E e)`、`removeFirst()`、 `removeLast()`),时间复杂度为 O(1),如果是要在指定位置 `i` 插入和删除元素的话(`add(int index, E element)`,`remove(Object o)`), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入。
|
||||
- **是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList`(实现了 RandomAccess 接口) 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
|
||||
- **内存空间占用:** `ArrayList` 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
|
||||
- `ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行`add(E e)`方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`),时间复杂度就为 O(n)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。
|
||||
- `LinkedList` 采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响(`add(E e)`、`addFirst(E e)`、`addLast(E e)`、`removeFirst()`、 `removeLast()`),时间复杂度为 O(1),如果是要在指定位置 `i` 插入和删除元素的话(`add(int index, E element)`,`remove(Object o)`,`remove(int index)`), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入和删除。
|
||||
- **是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList`(实现了 `RandomAccess` 接口) 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
|
||||
- **内存空间占用:** `ArrayList` 的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
|
||||
|
||||
我们在项目中一般是不会使用到 `LinkedList` 的,需要用到 `LinkedList` 的场景几乎都可以使用 `ArrayList` 来代替,并且,性能通常会更好!就连 `LinkedList` 的作者约书亚 · 布洛克(Josh Bloch)自己都说从来不会使用 `LinkedList` 。
|
||||
|
||||
|
||||
|
||||
另外,不要下意识地认为 `LinkedList` 作为链表就最适合元素增删的场景。我在上面也说了,`LinkedList` 仅仅在头尾插入或者删除元素的时候时间复杂度近似 O(1),其他情况增删元素的时间复杂度都是 O(n) 。
|
||||
另外,不要下意识地认为 `LinkedList` 作为链表就最适合元素增删的场景。我在上面也说了,`LinkedList` 仅仅在头尾插入或者删除元素的时候时间复杂度近似 O(1),其他情况增删元素的平均时间复杂度都是 O(n) 。
|
||||
|
||||
#### 补充内容:双向链表和双向循环链表
|
||||
#### 补充内容: 双向链表和双向循环链表
|
||||
|
||||
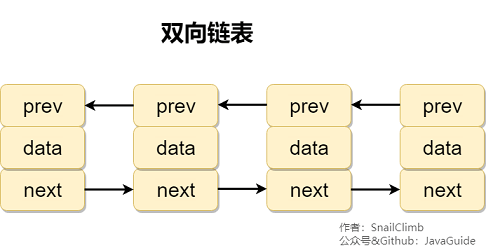
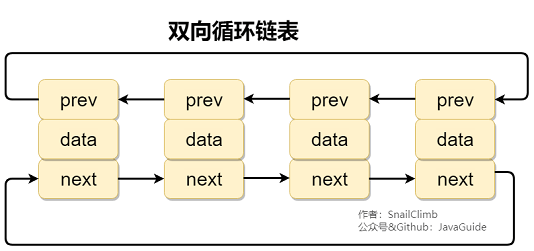
**双向链表:** 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
|
||||
|
||||
|
||||
|
||||
|
||||
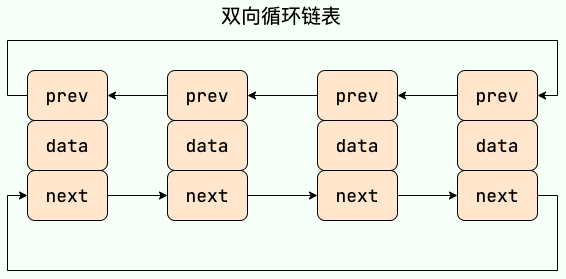
**双向循环链表:** 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
|
||||
|
||||
|
||||
|
||||
|
||||
#### 补充内容:RandomAccess 接口
|
||||
|
||||
|
|
@ -133,50 +263,51 @@ public interface RandomAccess {
|
|||
|
||||
### 说一说 ArrayList 的扩容机制吧
|
||||
|
||||
详见笔主的这篇文章: [ArrayList 扩容机制分析](https://javaguide.cn/java/collection/arraylist-source-code.html#_3-1-%E5%85%88%E4%BB%8E-arraylist-%E7%9A%84%E6%9E%84%E9%80%A0%E5%87%BD%E6%95%B0%E8%AF%B4%E8%B5%B7)
|
||||
详见笔主的这篇文章: [ArrayList 扩容机制分析](https://javaguide.cn/java/collection/arraylist-source-code.html#_3-1-%E5%85%88%E4%BB%8E-arraylist-%E7%9A%84%E6%9E%84%E9%80%A0%E5%87%BD%E6%95%B0%E8%AF%B4%E8%B5%B7)。
|
||||
|
||||
## Collection 子接口之 Set
|
||||
## Set
|
||||
|
||||
### comparable 和 Comparator 的区别
|
||||
### Comparable 和 Comparator 的区别
|
||||
|
||||
- `comparable` 接口实际上是出自`java.lang`包 它有一个 `compareTo(Object obj)`方法用来排序
|
||||
- `comparator`接口实际上是出自 java.util 包它有一个`compare(Object obj1, Object obj2)`方法用来排序
|
||||
`Comparable` 接口和 `Comparator` 接口都是 Java 中用于排序的接口,它们在实现类对象之间比较大小、排序等方面发挥了重要作用:
|
||||
|
||||
一般我们需要对一个集合使用自定义排序时,我们就要重写`compareTo()`方法或`compare()`方法,当我们需要对某一个集合实现两种排序方式,比如一个 song 对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写`compareTo()`方法和使用自制的`Comparator`方法或者以两个 Comparator 来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 `Collections.sort()`.
|
||||
- `Comparable` 接口实际上是出自`java.lang`包 它有一个 `compareTo(Object obj)`方法用来排序
|
||||
- `Comparator`接口实际上是出自 `java.util` 包它有一个`compare(Object obj1, Object obj2)`方法用来排序
|
||||
|
||||
一般我们需要对一个集合使用自定义排序时,我们就要重写`compareTo()`方法或`compare()`方法,当我们需要对某一个集合实现两种排序方式,比如一个 `song` 对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写`compareTo()`方法和使用自制的`Comparator`方法或者以两个 `Comparator` 来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 `Collections.sort()`.
|
||||
|
||||
#### Comparator 定制排序
|
||||
|
||||
```java
|
||||
ArrayList<Integer> arrayList = new ArrayList<Integer>();
|
||||
arrayList.add(-1);
|
||||
arrayList.add(3);
|
||||
arrayList.add(3);
|
||||
arrayList.add(-5);
|
||||
arrayList.add(7);
|
||||
arrayList.add(4);
|
||||
arrayList.add(-9);
|
||||
arrayList.add(-7);
|
||||
System.out.println("原始数组:");
|
||||
System.out.println(arrayList);
|
||||
// void reverse(List list):反转
|
||||
Collections.reverse(arrayList);
|
||||
System.out.println("Collections.reverse(arrayList):");
|
||||
System.out.println(arrayList);
|
||||
ArrayList<Integer> arrayList = new ArrayList<Integer>();
|
||||
arrayList.add(-1);
|
||||
arrayList.add(3);
|
||||
arrayList.add(3);
|
||||
arrayList.add(-5);
|
||||
arrayList.add(7);
|
||||
arrayList.add(4);
|
||||
arrayList.add(-9);
|
||||
arrayList.add(-7);
|
||||
System.out.println("原始数组:");
|
||||
System.out.println(arrayList);
|
||||
// void reverse(List list):反转
|
||||
Collections.reverse(arrayList);
|
||||
System.out.println("Collections.reverse(arrayList):");
|
||||
System.out.println(arrayList);
|
||||
|
||||
// void sort(List list),按自然排序的升序排序
|
||||
Collections.sort(arrayList);
|
||||
System.out.println("Collections.sort(arrayList):");
|
||||
System.out.println(arrayList);
|
||||
// 定制排序的用法
|
||||
Collections.sort(arrayList, new Comparator<Integer>() {
|
||||
|
||||
@Override
|
||||
public int compare(Integer o1, Integer o2) {
|
||||
return o2.compareTo(o1);
|
||||
}
|
||||
});
|
||||
System.out.println("定制排序后:");
|
||||
System.out.println(arrayList);
|
||||
// void sort(List list),按自然排序的升序排序
|
||||
Collections.sort(arrayList);
|
||||
System.out.println("Collections.sort(arrayList):");
|
||||
System.out.println(arrayList);
|
||||
// 定制排序的用法
|
||||
Collections.sort(arrayList, new Comparator<Integer>() {
|
||||
@Override
|
||||
public int compare(Integer o1, Integer o2) {
|
||||
return o2.compareTo(o1);
|
||||
}
|
||||
});
|
||||
System.out.println("定制排序后:");
|
||||
System.out.println(arrayList);
|
||||
```
|
||||
|
||||
Output:
|
||||
|
|
@ -277,7 +408,7 @@ Output:
|
|||
- `HashSet`、`LinkedHashSet` 和 `TreeSet` 的主要区别在于底层数据结构不同。`HashSet` 的底层数据结构是哈希表(基于 `HashMap` 实现)。`LinkedHashSet` 的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。`TreeSet` 底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。
|
||||
- 底层数据结构不同又导致这三者的应用场景不同。`HashSet` 用于不需要保证元素插入和取出顺序的场景,`LinkedHashSet` 用于保证元素的插入和取出顺序满足 FIFO 的场景,`TreeSet` 用于支持对元素自定义排序规则的场景。
|
||||
|
||||
## Collection 子接口之 Queue
|
||||
## Queue
|
||||
|
||||
### Queue 与 Deque 的区别
|
||||
|
||||
|
|
@ -332,3 +463,32 @@ Output:
|
|||
- `PriorityQueue` 默认是小顶堆,但可以接收一个 `Comparator` 作为构造参数,从而来自定义元素优先级的先后。
|
||||
|
||||
`PriorityQueue` 在面试中可能更多的会出现在手撕算法的时候,典型例题包括堆排序、求第 K 大的数、带权图的遍历等,所以需要会熟练使用才行。
|
||||
|
||||
### 什么是 BlockingQueue?
|
||||
|
||||
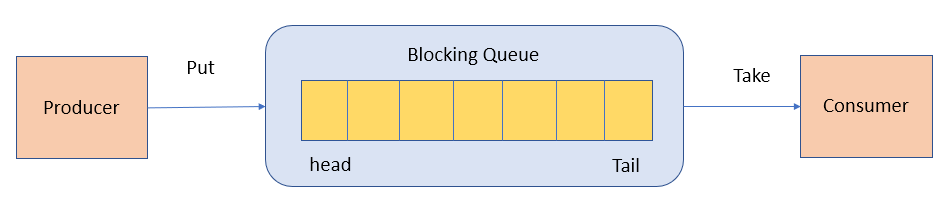
`BlockingQueue` (阻塞队列)是一个接口,继承自 `Queue`。`BlockingQueue`阻塞的原因是其支持当队列没有元素时一直阻塞,直到有有元素;还支持如果队列已满,一直等到队列可以放入新元素时再放入。
|
||||
|
||||
```java
|
||||
public interface BlockingQueue<E> extends Queue<E> {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
`BlockingQueue` 常用于生产者-消费者模型中,生产者线程会向队列中添加数据,而消费者线程会从队列中取出数据进行处理。
|
||||
|
||||
|
||||
|
||||
### BlockingQueue 的实现类有哪些?
|
||||
|
||||
|
||||
|
||||
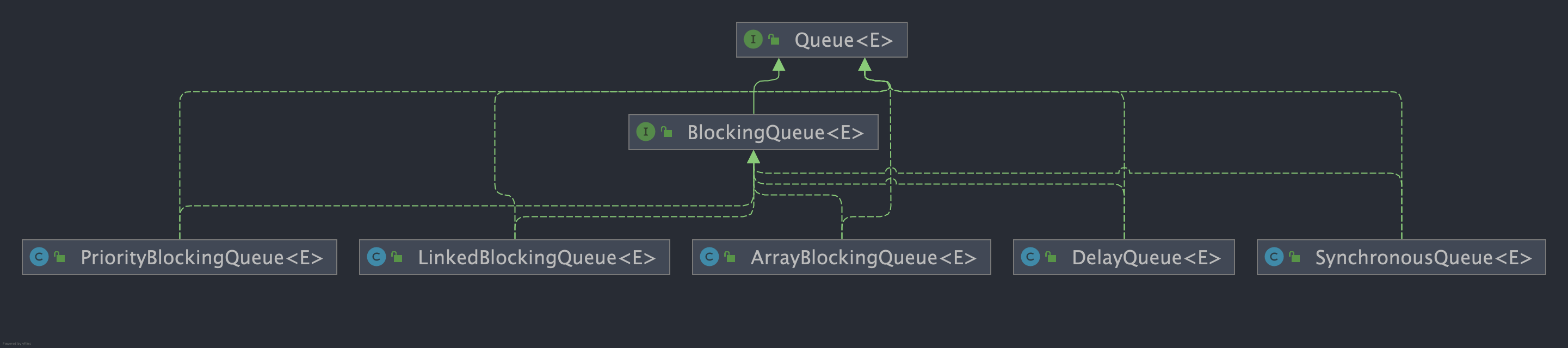
Java 中常用的阻塞队列实现类有以下几种:
|
||||
|
||||
1. `ArrayBlockingQueue`:使用数组实现的有界阻塞队列。在创建时需要指定容量大小,并支持公平和非公平两种方式的锁访问机制。
|
||||
2. `LinkedBlockingQueue`:使用单向链表实现的可选有界阻塞队列。在创建时可以指定容量大小,如果不指定则默认为`Integer.MAX_VALUE`。和`ArrayBlockingQueue`类似, 它也支持公平和非公平的锁访问机制。
|
||||
3. `PriorityBlockingQueue`:支持优先级排序的无界阻塞队列。元素必须实现`Comparable`接口或者在构造函数中传入`Comparator`对象,并且不能插入 null 元素。
|
||||
4. `SynchronousQueue`:同步队列,是一种不存储元素的阻塞队列。每个插入操作都必须等待对应的删除操作,反之删除操作也必须等待插入操作。因此,`SynchronousQueue`通常用于线程之间的直接传递数据。
|
||||
5. `DelayQueue`:延迟队列,其中的元素只有到了其指定的延迟时间,才能够从队列中出队。
|
||||
6. ......
|
||||
|
||||
日常开发中,这些队列使用的其实都不多,了解即可。
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ head:
|
|||
content: Java集合常见知识点和面试题总结,希望对你有帮助!
|
||||
---
|
||||
|
||||
## Map 接口
|
||||
## Map
|
||||
|
||||
### HashMap 和 Hashtable 的区别
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue