[docs update]完善 MySQL索引下推 & Memcached vs Redis
This commit is contained in:
parent
758e3cb8db
commit
8d80bad083
|
|
@ -223,7 +223,7 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
|||
|
||||
**优点**:
|
||||
|
||||
更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的
|
||||
更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的。
|
||||
|
||||
**缺点**:
|
||||
|
||||
|
|
@ -391,19 +391,29 @@ MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS)
|
|||
|
||||
**索引下推(Index Condition Pushdown,简称 ICP)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,它允许存储引擎在索引遍历过程中,执行部分 `WHERE`字句的判断条件,直接过滤掉不满足条件的记录,从而减少回表次数,提高查询效率。
|
||||
|
||||
假设我们有一个名为 `usr` 的表,其中包含 `id`, `name`, 和 `age` 3 个字段,`name` 字段上创建了索引。
|
||||
假设我们有一个名为 `user` 的表,其中包含 `id`, `username`, `zipcode`和 `birthdate` 4 个字段,创建了联合索引`(zipcode, birthdate)`。
|
||||
|
||||
```sql
|
||||
#查询名字以"Aoki"开头且年龄为30岁的用户
|
||||
EXPLAIN SELECT * FROM usr
|
||||
WHERE name LIKE 'Aoki%' AND age = 30;
|
||||
CREATE TABLE `user` (
|
||||
`id` int NOT NULL AUTO_INCREMENT,
|
||||
`username` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
|
||||
`zipcode` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
|
||||
`birthdate` date NOT NULL,
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_username_birthdate` (`zipcode`,`birthdate`) ) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8mb4;
|
||||
|
||||
# 查询 zipcode 为 431200 且生日在 3 月的用户
|
||||
# birthdate 字段使用函数索引失效
|
||||
SELECT * FROM user WHERE zipcode = '431200' AND MONTH(birthdate) = 3;
|
||||
```
|
||||
|
||||
- 没有索引下推之前,即使 `name` 字段建立的索引可以帮助我们快速定位到了以“张”开头的用户,但我们仍然需要对每一个找到的以“张”开头的用户进行回表操作,获取完整的用户数据,再判断 `age` 字段是否等于 30。
|
||||
- 有了索引下推之后,存储引擎会在使用 `name` 索引查找以"张"开头的记录时,同时检查 `age` 字段是否等于 30。这样,只有同时满足 `name` 和 `age` 条件的记录才会被返回,减少了回表次数。
|
||||
- 没有索引下推之前,即使 `zipcode` 字段利用索引可以帮助我们快速定位到 `zipcode = '431200'` 的用户,但我们仍然需要对每一个找到的用户进行回表操作,获取完整的用户数据,再去判断 `MONTH(birthdate) = 12`。
|
||||
- 有了索引下推之后,存储引擎会在使用`zipcode` 字段索引查找`zipcode = '431200'` 的用户时,同时判断`MONTH(birthdate) = 12`。这样,只有同时满足条件的记录才会被返回,减少了回表次数。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
再来讲讲索引下推的具体原理,先看下面这张 MySQL 简要架构图。
|
||||
|
||||

|
||||
|
|
@ -416,13 +426,13 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
|
|||
|
||||
没有索引下推之前:
|
||||
|
||||
- 存储引擎层先根据 `name` 索引字段找到所有以“张”开头用户的主键 ID,然后二次回表查询,获取完整的用户数据。
|
||||
- 存储引擎层把所有以“张”开头的用户数据全部交给 Server 层,Server 层根据`age` 字段是否等于 30 这一条件再进一步做筛选。
|
||||
- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户的主键 ID,然后二次回表查询,获取完整的用户数据;
|
||||
- 存储引擎层把所有 `zipcode = '431200'` 的用户数据全部交给 Server 层,Server 层根据`MONTH(birthdate) = 12`这一条件再进一步做筛选。
|
||||
|
||||
有了索引下推之后:
|
||||
|
||||
- 存储引擎层先根据 `name` 索引字段找到所有以“张”开头的用户,然后直接判断`age` 字段是否等于 30,筛选出符合条件的 主键 ID。
|
||||
- 二次回表查询,根据符合条件的主键 ID 去获取完整的用户数据,
|
||||
- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户,然后直接判断 `MONTH(birthdate) = 12`,筛选出符合条件的主键 ID;
|
||||
- 二次回表查询,根据符合条件的主键 ID 去获取完整的用户数据;
|
||||
- 存储引擎层把符合条件的用户数据全部交给 Server 层。
|
||||
|
||||
可以看出,**除了可以减少回表次数之外,索引下推还可以减少存储引擎层和 Server 层的数据传输量。**
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ head:
|
|||
|
||||
[Redis](https://redis.io/) (**RE**mote **DI**ctionary **S**erver)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
|
||||
|
||||
为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
|
||||
为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、发布订阅模型、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
|
||||
|
||||
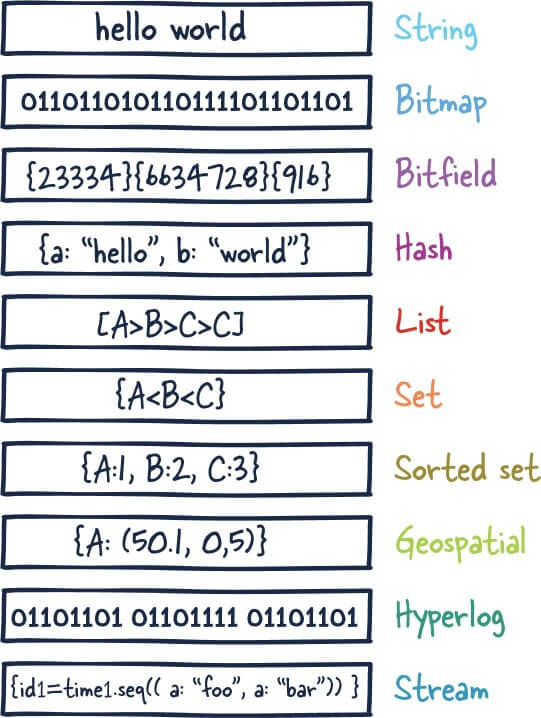
|
||||
|
||||
|
|
@ -36,14 +36,17 @@ Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两
|
|||
|
||||
Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
|
||||
|
||||
1. Redis 基于内存,内存的访问速度是磁盘的上千倍;
|
||||
1. Redis 基于内存,内存的访问速度比磁盘快很多;
|
||||
2. Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
|
||||
3. Redis 内置了多种优化过后的数据类型/结构实现,性能非常高。
|
||||
4. Redis 通信协议实现简单且解析高效。
|
||||
|
||||
> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770) 。
|
||||
|
||||

|
||||
|
||||
那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高且 Redis 提供的数据持久化仍然有数据丢失的风险。
|
||||
|
||||
### 分布式缓存常见的技术选型方案有哪些?
|
||||
|
||||
分布式缓存的话,比较老牌同时也是使用的比较多的还是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
|
||||
|
|
@ -73,14 +76,12 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
|||
|
||||
**区别**:
|
||||
|
||||
1. **Redis 支持更丰富的数据类型(支持更复杂的应用场景)**。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
|
||||
2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。**
|
||||
3. **Redis 有灾难恢复机制。** 因为可以把缓存中的数据持久化到磁盘上。
|
||||
4. **Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。**
|
||||
5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的。**
|
||||
6. **Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。** (Redis 6.0 针对网络数据的读写引入了多线程)
|
||||
7. **Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。**
|
||||
8. **Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。**
|
||||
1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
|
||||
2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制而 Memcached 没有。
|
||||
3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 自 3.0 版本起是原生支持集群模式的。
|
||||
4. **线程模型**:Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。 (Redis 6.0 针对网络数据的读写引入了多线程)
|
||||
5. **特性支持**:Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
|
||||
6. **过期数据删除**:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
|
||||
|
||||
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
|
||||
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 155 KiB |
|
|
@ -171,7 +171,7 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
|
|||
|
||||

|
||||
|
||||
1、整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是本地内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
|
||||
1、整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整(也就是受到 JVM 内存的限制),而元空间使用的是本地内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
|
||||
|
||||
> 当元空间溢出时会得到如下错误:`java.lang.OutOfMemoryError: MetaSpace`
|
||||
|
||||
|
|
@ -181,6 +181,8 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
|
|||
|
||||
3、在 JDK8,合并 HotSpot 和 JRockit 的代码时, JRockit 从来没有一个叫永久代的东西, 合并之后就没有必要额外的设置这么一个永久代的地方了。
|
||||
|
||||
4、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
|
||||
|
||||
**方法区常用参数有哪些?**
|
||||
|
||||
JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参数来调节方法区大小。
|
||||
|
|
|
|||
|
|
@ -83,7 +83,9 @@ public class XSSFilter implements Filter {
|
|||
使用 Session 进行身份认证的话,需要保存一份信息在服务器端,而且这种方式会依赖到 Cookie(需要 Cookie 保存 `SessionId`),所以不适合移动端。
|
||||
|
||||
但是,使用 JWT 进行身份认证就不会存在这种问题,因为只要 JWT 可以被客户端存储就能够使用,而且 JWT 还可以跨语言使用。
|
||||
|
||||
> 为什么使用 Session 进行身份认证的话不适合移动端 ?
|
||||
>
|
||||
> 1. 状态管理: Session 基于服务器端的状态管理,而移动端应用通常是无状态的。移动设备的连接可能不稳定或中断,因此难以维护长期的会话状态。如果使用 Session 进行身份认证,移动应用需要频繁地与服务器进行会话维护,增加了网络开销和复杂性;
|
||||
> 2. 兼容性: 移动端应用通常会面向多个平台,如 iOS、Android 和 Web。每个平台对于 Session 的管理和存储方式可能不同,可能导致跨平台兼容性的问题;
|
||||
> 3. 安全性: 移动设备通常处于不受信任的网络环境,存在数据泄露和攻击的风险。将敏感的会话信息存储在移动设备上增加了被攻击的潜在风险。
|
||||
|
|
@ -110,9 +112,9 @@ public class XSSFilter implements Filter {
|
|||
|
||||
那我们如何解决这个问题呢?查阅了很多资料,我简单总结了下面 4 种方案:
|
||||
|
||||
**1、将 JWT 存入内存数据库**
|
||||
**1、将 JWT 存入数据库**
|
||||
|
||||
将 JWT 存入 DB 中,Redis 内存数据库在这里是不错的选择。如果需要让某个 JWT 失效就直接从 Redis 中删除这个 JWT 即可。但是,这样会导致每次使用 JWT 发送请求都要先从 DB 中查询 JWT 是否存在的步骤,而且违背了 JWT 的无状态原则。
|
||||
将有效的 JWT 存入数据库中,更建议使用内存数据库比如 Redis。如果需要让某个 JWT 失效就直接从 Redis 中删除这个 JWT 即可。但是,这样会导致每次使用 JWT 都要先从 Redis 中查询 JWT 是否存在的步骤,而且违背了 JWT 的无状态原则。
|
||||
|
||||
**2、黑名单机制**
|
||||
|
||||
|
|
@ -143,28 +145,30 @@ JWT 有效期一般都建议设置的不太长,那么 JWT 过期后如何认
|
|||
|
||||
JWT 认证的话,我们应该如何解决续签问题呢?查阅了很多资料,我简单总结了下面 4 种方案:
|
||||
|
||||
**1、类似于 Session 认证中的做法**
|
||||
**1、类似于 Session 认证中的做法(不推荐)**
|
||||
|
||||
这种方案满足于大部分场景。假设服务端给的 JWT 有效期设置为 30 分钟,服务端每次进行校验时,如果发现 JWT 的有效期马上快过期了,服务端就重新生成 JWT 给客户端。客户端每次请求都检查新旧 JWT,如果不一致,则更新本地的 JWT。这种做法的问题是仅仅在快过期的时候请求才会更新 JWT ,对客户端不是很友好。
|
||||
这种方案满足于大部分场景。假设服务端给的 JWT 有效期设置为 30 分钟,服务端每次进行校验时,如果发现 JWT 的有效期马上快过期了,服务端就重新生成 JWT 给客户端。客户端每次请求都检查新旧 JWT,如果不一致,则更新本地的 JWT。这种做法的问题是仅仅在快过期的时候请求才会更新 JWT ,对客户端不是很友好。
|
||||
|
||||
**2、每次请求都返回新 JWT**
|
||||
**2、每次请求都返回新 JWT(不推荐)**
|
||||
|
||||
这种方案的的思路很简单,但是,开销会比较大,尤其是在服务端要存储维护 JWT 的情况下。
|
||||
|
||||
**3、JWT 有效期设置到半夜**
|
||||
**3、JWT 有效期设置到半夜(不推荐)**
|
||||
|
||||
这种方案是一种折衷的方案,保证了大部分用户白天可以正常登录,适用于对安全性要求不高的系统。
|
||||
|
||||
**4、用户登录返回两个 JWT**
|
||||
**4、用户登录返回两个 JWT(推荐)**
|
||||
|
||||
第一个是 accessJWT ,它的过期时间 JWT 本身的过期时间比如半个小时,另外一个是 refreshJWT 它的过期时间更长一点比如为 1 天。客户端登录后,将 accessJWT 和 refreshJWT 保存在本地,每次访问将 accessJWT 传给服务端。服务端校验 accessJWT 的有效性,如果过期的话,就将 refreshJWT 传给服务端。如果有效,服务端就生成新的 accessJWT 给客户端。否则,客户端就重新登录即可。
|
||||
第一个是 accessJWT ,它的过期时间 JWT 本身的过期时间比如半个小时,另外一个是 refreshJWT 它的过期时间更长一点比如为 1 天。refreshJWT 只用来获取 accessJWT,不容易被泄露。
|
||||
|
||||
客户端登录后,将 accessJWT 和 refreshJWT 保存在本地,每次访问将 accessJWT 传给服务端。服务端校验 accessJWT 的有效性,如果过期的话,就将 refreshJWT 传给服务端。如果有效,服务端就生成新的 accessJWT 给客户端。否则,客户端就重新登录即可。
|
||||
|
||||
这种方案的不足是:
|
||||
|
||||
- 需要客户端来配合;
|
||||
- 用户注销的时候需要同时保证两个 JWT 都无效;
|
||||
- 重新请求获取 JWT 的过程中会有短暂 JWT 不可用的情况(可以通过在客户端设置定时器,当 accessJWT 快过期的时候,提前去通过 refreshJWT 获取新的 accessJWT);
|
||||
- 存在安全问题,只要拿到了未过期的 refreshJWT 就一直可以获取到 accessJWT。
|
||||
- 存在安全问题,只要拿到了未过期的 refreshJWT 就一直可以获取到 accessJWT。不过,由于 refreshJWT 只用来获取 accessJWT,不容易被泄露。
|
||||
|
||||
## 总结
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue