Merge branch 'main' into tweaks1
This commit is contained in:
commit
3a136fa592
52
README.md
52
README.md
|
|
@ -18,9 +18,9 @@
|
|||
|
||||
</div>
|
||||
|
||||
> 1. **面试专版** :准备面试的小伙伴可以考虑面试专版:[《Java 面试指北 》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) (质量很高,专为面试打造,配合 JavaGuide 食用)。
|
||||
> 1. **知识星球** :专属面试小册/一对一交流/简历修改/专属求职指南,欢迎加入 [JavaGuide 知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看星球的详细介绍,一定一定一定确定自己真的需要再加入,一定一定要看完详细介绍之后再加我)。
|
||||
> 1. **转载须知** :以下所有文章如非文首说明为转载皆为我(Guide)的原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
|
||||
> 1. **面试专版**:准备面试的小伙伴可以考虑面试专版:[《Java 面试指北 》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) (质量很高,专为面试打造,配合 JavaGuide 食用)。
|
||||
> 1. **知识星球**:专属面试小册/一对一交流/简历修改/专属求职指南,欢迎加入 [JavaGuide 知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看星球的详细介绍,一定一定一定确定自己真的需要再加入,一定一定要看完详细介绍之后再加我)。
|
||||
> 1. **转载须知**:以下所有文章如非文首说明为转载皆为我(Guide)的原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
|
||||
|
||||
<div align="center">
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/gongzhonghaoxuanchuan.png" style="margin: 0 auto;" />
|
||||
|
|
@ -44,7 +44,7 @@
|
|||
- [Java 基础常见知识点&面试题总结(中)](./docs/java/basis/java-basic-questions-02.md)
|
||||
- [Java 基础常见知识点&面试题总结(下)](./docs/java/basis/java-basic-questions-03.md)
|
||||
|
||||
**重要知识点详解** :
|
||||
**重要知识点详解**:
|
||||
|
||||
- [为什么 Java 中只有值传递?](./docs/java/basis/why-there-only-value-passing-in-java.md)
|
||||
- [Java 序列化详解](./docs/java/basis/serialization.md)
|
||||
|
|
@ -58,13 +58,13 @@
|
|||
|
||||
### 集合
|
||||
|
||||
**知识点/面试题总结** :
|
||||
**知识点/面试题总结**:
|
||||
|
||||
- [Java 集合常见知识点&面试题总结(上)](./docs/java/collection/java-collection-questions-01.md) (必看 :+1:)
|
||||
- [Java 集合常见知识点&面试题总结(下)](./docs/java/collection/java-collection-questions-02.md) (必看 :+1:)
|
||||
- [Java 容器使用注意事项总结](./docs/java/collection/java-collection-precautions-for-use.md)
|
||||
|
||||
**源码分析** :
|
||||
**源码分析**:
|
||||
|
||||
- [ArrayList 源码+扩容机制分析](./docs/java/collection/arraylist-source-code.md)
|
||||
- [HashMap(JDK1.8)源码+底层数据结构分析](./docs/java/collection/hashmap-source-code.md)
|
||||
|
|
@ -84,10 +84,10 @@
|
|||
- [Java 并发常见知识点&面试题总结(中)](./docs/java/concurrent/java-concurrent-questions-02.md)
|
||||
- [Java 并发常见知识点&面试题总结(下)](./docs/java/concurrent/java-concurrent-questions-03.md)
|
||||
|
||||
**重要知识点详解** :
|
||||
**重要知识点详解**:
|
||||
|
||||
- [JMM(Java 内存模型)详解](./docs/java/concurrent/jmm.md)
|
||||
- **线程池** :[Java 线程池详解](./docs/java/concurrent/java-thread-pool-summary.md)、[Java 线程池最佳实践](./docs/java/concurrent/java-thread-pool-best-practices.md)
|
||||
- **线程池**:[Java 线程池详解](./docs/java/concurrent/java-thread-pool-summary.md)、[Java 线程池最佳实践](./docs/java/concurrent/java-thread-pool-best-practices.md)
|
||||
- [ThreadLocal 详解](./docs/java/concurrent/threadlocal.md)
|
||||
- [Java 并发容器总结](./docs/java/concurrent/java-concurrent-collections.md)
|
||||
- [Atomic 原子类总结](./docs/java/concurrent/atomic-classes.md)
|
||||
|
|
@ -109,7 +109,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
|
||||
### 新特性
|
||||
|
||||
- **Java 8** :[Java 8 新特性总结(翻译)](./docs/java/new-features/java8-tutorial-translate.md)、[Java8 常用新特性总结](./docs/java/new-features/java8-common-new-features.md)
|
||||
- **Java 8**:[Java 8 新特性总结(翻译)](./docs/java/new-features/java8-tutorial-translate.md)、[Java8 常用新特性总结](./docs/java/new-features/java8-common-new-features.md)
|
||||
- [Java 9 新特性概览](./docs/java/new-features/java9.md)
|
||||
- [Java 10 新特性概览](./docs/java/new-features/java10.md)
|
||||
- [Java 11 新特性概览](./docs/java/new-features/java11.md)
|
||||
|
|
@ -125,20 +125,21 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
|
||||
### 操作系统
|
||||
|
||||
- [操作系统常见面试题总结(上)](./docs/cs-basics/operating-system/operating-system-basic-questions-01.md)
|
||||
- [操作系统常见面试题总结(下)](./docs/cs-basics/operating-system/operating-system-basic-questions-02.md)
|
||||
- [后端程序员必备的 Linux 基础知识总结](./docs/cs-basics/operating-system/linux-intro.md)
|
||||
- [Shell 编程基础知识总结](./docs/cs-basics/operating-system/shell-intro.md)
|
||||
- [操作系统常见知识点&面试题总结(上)](./docs/cs-basics/operating-system/operating-system-basic-questions-01.md)
|
||||
- [操作系统常见知识点&面试题总结(下)](./docs/cs-basics/operating-system/operating-system-basic-questions-02.md)
|
||||
- **Linux**:
|
||||
- [后端程序员必备的 Linux 基础知识总结](./docs/cs-basics/operating-system/linux-intro.md)
|
||||
- [Shell 编程基础知识总结](./docs/cs-basics/operating-system/shell-intro.md)
|
||||
|
||||
### 网络
|
||||
|
||||
**知识点/面试题总结** :
|
||||
**知识点/面试题总结**:
|
||||
|
||||
- [计算机网络常见知识点&面试题总结(上)](./docs/cs-basics/network/other-network-questions.md)
|
||||
- [计算机网络常见知识点&面试题总结(下)](./docs/cs-basics/network/other-network-questions2.md)
|
||||
- [谢希仁老师的《计算机网络》内容总结(补充)](./docs/cs-basics/network/computer-network-xiexiren-summary.md)
|
||||
|
||||
**重要知识点详解** :
|
||||
**重要知识点详解**:
|
||||
|
||||
- [OSI 和 TCP/IP 网络分层模型详解(基础)](./docs/cs-basics/network/osi-and-tcp-ip-model.md)
|
||||
- [应用层常见协议总结(应用层)](./docs/cs-basics/network/application-layer-protocol.md)
|
||||
|
|
@ -159,9 +160,9 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
- [线性数据结构 :数组、链表、栈、队列](./docs/cs-basics/data-structure/linear-data-structure.md)
|
||||
- [图](./docs/cs-basics/data-structure/graph.md)
|
||||
- [堆](./docs/cs-basics/data-structure/heap.md)
|
||||
- [树](./docs/cs-basics/data-structure/tree.md) :重点关注[红黑树](./docs/cs-basics/data-structure/red-black-tree.md)、B-,B+,B\*树、LSM 树
|
||||
- [树](./docs/cs-basics/data-structure/tree.md):重点关注[红黑树](./docs/cs-basics/data-structure/red-black-tree.md)、B-,B+,B\*树、LSM 树
|
||||
|
||||
其他常用数据结构 :
|
||||
其他常用数据结构:
|
||||
|
||||
- [布隆过滤器](./docs/cs-basics/data-structure/bloom-filter.md)
|
||||
|
||||
|
|
@ -172,7 +173,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
- [算法学习书籍+资源推荐](https://www.zhihu.com/question/323359308/answer/1545320858) 。
|
||||
- [如何刷 Leetcode?](https://www.zhihu.com/question/31092580/answer/1534887374)
|
||||
|
||||
**常见算法问题总结** :
|
||||
**常见算法问题总结**:
|
||||
|
||||
- [几道常见的字符串算法题总结 ](./docs/cs-basics/algorithms/string-algorithm-problems.md)
|
||||
- [几道常见的链表算法题总结 ](./docs/cs-basics/algorithms/linkedlist-algorithm-problems.md)
|
||||
|
|
@ -258,7 +259,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
### Git
|
||||
|
||||
- [Git 核心概念总结](./docs/tools/git/git-intro.md)
|
||||
- [Github 实用小技巧总结](./docs/tools/git/github-tips.md)
|
||||
- [GitHub 实用小技巧总结](./docs/tools/git/github-tips.md)
|
||||
|
||||
## 系统设计
|
||||
|
||||
|
|
@ -284,7 +285,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
- [Spring/Spring Boot 常用注解总结](./docs/system-design/framework/spring/spring-common-annotations.md)
|
||||
- [SpringBoot 入门指南](https://github.com/Snailclimb/springboot-guide)
|
||||
|
||||
**重要知识点详解** :
|
||||
**重要知识点详解**:
|
||||
|
||||
- [Spring 事务详解](./docs/system-design/framework/spring/spring-transaction.md)
|
||||
- [Spring 中的设计模式详解](./docs/system-design/framework/spring/spring-design-patterns-summary.md)
|
||||
|
|
@ -343,12 +344,13 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
|
||||
### API 网关
|
||||
|
||||
- [API 网关基础知识总结](./docs/distributed-system/api-gateway.md)
|
||||
- [API 网关基础知识总结](https://javaguide.cn/distributed-system/api-gateway.html)
|
||||
- [Spring Cloud Gateway 常见知识点&面试题总结](./docs/distributed-system/spring-cloud-gateway-questions.md)
|
||||
|
||||
### 分布式 ID
|
||||
|
||||
[分布式 ID 常见知识点&面试题总结](https://javaguide.cn/distributed-system/distributed-id.html)
|
||||
- [分布式 ID 常见知识点&面试题总结](https://javaguide.cn/distributed-system/distributed-id.html)
|
||||
- [分布式 ID 设计指南](https://javaguide.cn/distributed-system/distributed-id-design.html)
|
||||
|
||||
### 分布式锁
|
||||
|
||||
|
|
@ -414,10 +416,10 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
|
||||
### 灾备设计和异地多活
|
||||
|
||||
**灾备** = 容灾+备份。
|
||||
**灾备** = 容灾 + 备份。
|
||||
|
||||
- **备份** : 将系统所产生的的所有重要数据多备份几份。
|
||||
- **容灾** : 在异地建立两个完全相同的系统。当某个地方的系统突然挂掉,整个应用系统可以切换到另一个,这样系统就可以正常提供服务了。
|
||||
- **备份**:将系统所产生的的所有重要数据多备份几份。
|
||||
- **容灾**:在异地建立两个完全相同的系统。当某个地方的系统突然挂掉,整个应用系统可以切换到另一个,这样系统就可以正常提供服务了。
|
||||
|
||||
**异地多活** 描述的是将服务部署在异地并且服务同时对外提供服务。和传统的灾备设计的最主要区别在于“多活”,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者人为灾害。
|
||||
|
||||
|
|
|
|||
|
|
@ -6,9 +6,9 @@ import theme from "./theme.js";
|
|||
export default defineUserConfig({
|
||||
dest: "./dist",
|
||||
|
||||
title: "JavaGuide(Java面试+学习指南)",
|
||||
title: "JavaGuide(Java面试 + 学习指南)",
|
||||
description:
|
||||
"「Java学习指北+Java面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,复习 Java 知识点,首选 JavaGuide! ",
|
||||
"「Java学习指北 + Java面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,复习 Java 知识点,首选 JavaGuide! ",
|
||||
|
||||
head: [
|
||||
// meta
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@ export default navbar([
|
|||
text: "更新历史",
|
||||
icon: "history",
|
||||
link: "/timeline/",
|
||||
}
|
||||
},
|
||||
],
|
||||
},
|
||||
]);
|
||||
|
|
|
|||
|
|
@ -467,20 +467,17 @@ export default sidebar({
|
|||
text: "ZooKeeper",
|
||||
icon: "framework",
|
||||
prefix: "distributed-process-coordination/zookeeper/",
|
||||
children: [
|
||||
"zookeeper-intro",
|
||||
"zookeeper-plus",
|
||||
],
|
||||
children: ["zookeeper-intro", "zookeeper-plus"],
|
||||
},
|
||||
{
|
||||
text: "API网关",
|
||||
icon: "gateway",
|
||||
children: ["api-gateway","spring-cloud-gateway-questions"],
|
||||
children: ["api-gateway", "spring-cloud-gateway-questions"],
|
||||
},
|
||||
{
|
||||
text: "分布式ID",
|
||||
icon: "id",
|
||||
children: ["distributed-id"],
|
||||
children: ["distributed-id", "distributed-id-design"],
|
||||
},
|
||||
{
|
||||
text: "分布式锁",
|
||||
|
|
|
|||
|
|
@ -11,14 +11,14 @@ tag:
|
|||
|
||||
不得不说 ThoughtWorks 的培训机制还是很不错的。应届生入职之后一般都会安排培训,与往年不同的是,今年的培训多了中国本地班(TWU-C)。作为本地班的第一期学员,说句心里话还是很不错。8 周的培训,除了工作需要用到的基本技术比如 ES6、SpringBoot 等等之外,还会增加一些新员工基本技能的培训比如如何高效开会、如何给别人正确的提 Feedback、如何对代码进行重构、如何进行 TDD 等等。培训期间不定期的有活动,比如 Weekend Trip、 City Tour、Cake time 等等。最后三周还会有一个实际的模拟项目,这个项目基本和我们正式工作的实际项目差不多,我个人感觉很不错。目前这个项目已经正式完成了一个迭代,我觉得在做项目的过程中,收获最大的不是项目中使用的技术,而是如何进行团队合作、如何正确使用 Git 团队协同开发、一个完成的迭代是什么样子的、做项目的过程中可能遇到那些问题、一个项目运作的完整流程等等。
|
||||
|
||||
ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司的这段时间深有感触。培训期间,我们每个人会有一个 Trainer 负责,Trainer 就是日常带我们上课和做项目的同事,一个 Trainer 大概会负责 5-6 个人。Trainer 不定期都会给我们最近表现的 Feedback( 反馈) ,我个人觉得这个并不是这是走走形式,Trainer 们都很负责,很多时候都是在下班之后找我们聊天。同事们也都很热心,如果你遇到问题,向别人询问,其他人如果知道的话一般都会毫无保留的告诉你,如果遇到大部分都不懂的问题,甚至会组织一次技术 Session 分享。上周五我在我们小组内进行了一次关于 Feign 远程调用的技术分享,因为 team 里面大家对这部分知识都不太熟悉,但是后面的项目进展大概率会用到这部分知识。我刚好研究了这部分内容,所以就分享给了组内的其他同事,以便于项目更好的进行。
|
||||
ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司的这段时间深有感触。培训期间,我们每个人会有一个 Trainer 负责,Trainer 就是日常带我们上课和做项目的同事,一个 Trainer 大概会负责 5 - 6 个人。Trainer 不定期都会给我们最近表现的 Feedback (反馈) ,我个人觉得这个并不是这是走走形式,Trainer 们都很负责,很多时候都是在下班之后找我们聊天。同事们也都很热心,如果你遇到问题,向别人询问,其他人如果知道的话一般都会毫无保留的告诉你,如果遇到大部分都不懂的问题,甚至会组织一次技术 Session 分享。上周五我在我们小组内进行了一次关于 Feign 远程调用的技术分享,因为 team 里面大家对这部分知识都不太熟悉,但是后面的项目进展大概率会用到这部分知识。我刚好研究了这部分内容,所以就分享给了组内的其他同事,以便于项目更好的进行。
|
||||
|
||||
另外,ThoughtWorks 也是一家非常提倡 Feedback( 反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
|
||||
另外,ThoughtWorks 也是一家非常提倡 Feedback (反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
|
||||
|
||||

|
||||
|
||||
工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 pr 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
|
||||
工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 PR 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
|
||||
|
||||
工作之后身边也会有很多厉害的人,多从他人身上学习我觉得是每个职场人都应该做的。这一届和我们一起培训的同事中,有一些技术很厉害的,也有一些技术虽然不是那么厉害,但是组织能力以及团队协作能力特别厉害的。有一个特别厉害的同事,在我们还在学 SpringBoot 各种语法的时候,他自己利用业余时间写了一个简化版的 SpringBoot ,涵盖了 Spring 的一些常用注解比如 `@RestController`、`@Autowried`、`@Pathvairable`、`@RestquestParam`等等(已经联系这位同事,想让他开源一下,后面会第一时间同步到公众号,期待一下吧!)。我觉得这位同事对于编程是真的有兴趣,他好像从初中就开始接触编程了,对于各种底层知识也非常感兴趣,自己写过实现过很多比较底层的东西。他的梦想是在 Github 上造一个 20k Star 以上的轮子。我相信以这位同事的能力一定会达成目标的,在这里祝福这位同事,希望他可以尽快实现这个目标。
|
||||
工作之后身边也会有很多厉害的人,多从他人身上学习我觉得是每个职场人都应该做的。这一届和我们一起培训的同事中,有一些技术很厉害的,也有一些技术虽然不是那么厉害,但是组织能力以及团队协作能力特别厉害的。有一个特别厉害的同事,在我们还在学 SpringBoot 各种语法的时候,他自己利用业余时间写了一个简化版的 SpringBoot ,涵盖了 Spring 的一些常用注解比如 `@RestController`、`@Autowried`、`@Pathvairable`、`@RestquestParam`等等(已经联系这位同事,想让他开源一下,后面会第一时间同步到公众号,期待一下吧!)。我觉得这位同事对于编程是真的有兴趣,他好像从初中就开始接触编程了,对于各种底层知识也非常感兴趣,自己写过实现过很多比较底层的东西。他的梦想是在 Github 上造一个 20k Star 以上的轮子。我相信以这位同事的能力一定会达成目标的,在这里祝福这位同事,希望他可以尽快实现这个目标。
|
||||
|
||||
这是我入职一个多月之后的个人感受,很多地方都是一带而过,后面我会抽时间分享自己在公司或者业余学到的比较有用的知识给各位,希望看过的人都能有所收获。
|
||||
|
|
|
|||
|
|
@ -5,25 +5,25 @@ tag:
|
|||
- 个人经历
|
||||
---
|
||||
|
||||
如果大家看过我之前的介绍的话,就会知道我是 19 年毕业的几百万应届毕业生中的一员。这篇文章主要讲了一下我入职大半年的感受,文中有很多自己的主观感受,如果你们有任何不认同的地方都可以直接在评论区说出来, 会很尊重其他人的想法。
|
||||
如果大家看过我之前的介绍的话,就会知道我是 19 年毕业的几百万应届毕业生中的一员。这篇文章主要讲了一下我入职大半年的感受,文中有很多自己的主观感受,如果你们有任何不认同的地方都可以直接在评论区说出来,会很尊重其他人的想法。
|
||||
|
||||
简单说一下自己的情况吧!我目前是在一家外企,每天的工作和大部分人一样就是做开发。毕业到现在,差不多也算是工作半年多了,也已经过了公司 6 个月的试用期。目前在公司做过两个偏向于业务方向的项目,其中一个正在做。你很难想象我在公司做的两个业务项目的后端都没有涉及到分布式/微服务,没有接触到 Redis、Kafka 等等比较“高大上”的技术在项目中的实际运用。
|
||||
|
||||
第一个项目做的是公司的内部项目——员工成长系统。抛去员工成长系统这个名字,实际上这个系统做的就是绩效考核比如你在某个项目组的表现。这个项目的技术是 Spring Boot+ JPA+Spring Security + K8S+Docker+React。第二个目前正在做的是一个集成游戏(cocos)、Web 管理端(Spring Boot+Vue)和小程序(Taro)项目。
|
||||
第一个项目做的是公司的内部项目——员工成长系统。抛去员工成长系统这个名字,实际上这个系统做的就是绩效考核比如你在某个项目组的表现。这个项目的技术是 Spring Boot+ JPA + Spring Security + K8S + Docker + React。第二个目前正在做的是一个集成游戏 (cocos)、Web 管理端 (Spring Boot + Vue) 和小程序 (Taro) 项目。
|
||||
|
||||
是的,我在工作中的大部分时间都和 CRUD 有关,每天也会写前端页面。之前我认识的一个朋友 ,他听说我做的项目中大部分内容都是写业务代码之后就非常纳闷,他觉得单纯写业务代码得不到提升?what?你一个应届生,连业务代码都写不好你给我说这个!所以,**我就很纳闷不知道为什么现在很多连业务代码都写不好的人为什么人听到 CRUD 就会反感?至少我觉得在我工作这段时间我的代码质量得到了提升、定位问题的能力有了很大的改进、对于业务有了更深的认识,自己也可以独立完成一些前端的开发了。**
|
||||
|
||||
其实,我个人觉得能把业务代码写好也没那么容易,抱怨自己天天做 CRUD 工作之前,看看自己 CRUD 的代码写好没。再换句话说,单纯写 CRUD 的过程中你搞懂了哪些你常用的注解或者类吗?这就像一个只会 `@Service`、`@Autowired`、`@RestController`等等最简单的注解的人说我已经掌握了 Spring Boot 一样。
|
||||
|
||||
不知道什么时候开始大家都会觉得有实际使用 Redis、MQ 的经验就很牛逼了, 这可能和当前的面试环境有关系。你需要和别人有差异,你想进大厂的话,好像就必须要这些技术比较在行,好吧,没有好像,自信点来说对于大部分求职者这些技术都是默认你必备的了。
|
||||
不知道什么时候开始大家都会觉得有实际使用 Redis、MQ 的经验就很牛逼了,这可能和当前的面试环境有关系。你需要和别人有差异,你想进大厂的话,好像就必须要这些技术比较在行,好吧,没有好像,自信点来说对于大部分求职者这些技术都是默认你必备的了。
|
||||
|
||||
**实话实说,我在大学的时候就陷入过这个“伪命题”中**。在大学的时候,我大二因为加入了一个学校的偏技术方向的校媒才接触到 Java ,当时我们学习 Java 的目的就是开发一个校园通。 大二的时候,编程相当于才入门水平的我才接触 Java,花了一段时间才掌握 Java 基础。然后,就开始学习安卓开发。
|
||||
|
||||
到了大三上学期,我才真正确定要走 Java 后台的方向,找 Java 后台的开发工作。学习了 3 个月左右的 WEB 开发基础之后,我就开始学习分布式方面内容比如 Redis、Dubbo 这些。我当时是通过看书+视频+博客的方式学习的,自学过程中通过看视频自己做过两个完整的项目,一个普通的业务系统,一个是分布式的系统。**我当时以为自己做完之后就很牛逼了,我觉得普通的 CRUD 工作已经不符合我当前的水平了。哈哈!现在看来,当时的我过于哈皮!**
|
||||
到了大三上学期,我才真正确定要走 Java 后台的方向,找 Java 后台的开发工作。学习了 3 个月左右的 WEB 开发基础之后,我就开始学习分布式方面内容比如 Redis、Dubbo 这些。我当时是通过看书 + 视频 + 博客的方式学习的,自学过程中通过看视频自己做过两个完整的项目,一个普通的业务系统,一个是分布式的系统。**我当时以为自己做完之后就很牛逼了,我觉得普通的 CRUD 工作已经不符合我当前的水平了。哈哈!现在看来,当时的我过于哈皮!**
|
||||
|
||||
这不!到了大三暑假跟着老师一起做项目的时候就出问题了。大三的时候,我们跟着老师做的是一个绩效考核系统,业务复杂程度中等。这个项目的技术用的是:SSM+Shiro+JSP。当时,做这个项目的时候我遇到各种问题,各种我以为我会写的代码都不会写了,甚至我写一个简单的 CRUD 都要花费好几天的时间。所以,那时候我都是边复习边学习边写代码。虽然很累,但是,那时候学到了很多,也让我在技术面前变得更加踏实。我觉得这“**这个项目已经没有维护的可能性**”这句话是我对我过的这个项目最大的否定了。
|
||||
这不!到了大三暑假跟着老师一起做项目的时候就出问题了。大三的时候,我们跟着老师做的是一个绩效考核系统,业务复杂程度中等。这个项目的技术用的是:SSM + Shiro + JSP。当时,做这个项目的时候我遇到各种问题,各种我以为我会写的代码都不会写了,甚至我写一个简单的 CRUD 都要花费好几天的时间。所以,那时候我都是边复习边学习边写代码。虽然很累,但是,那时候学到了很多,也让我在技术面前变得更加踏实。我觉得这“**这个项目已经没有维护的可能性**”这句话是我对我过的这个项目最大的否定了。
|
||||
|
||||
技术千变万化,掌握最核心的才是王道。我们前几年可能还在用 Spring 基于传统的 XML 开发,现在几乎大家都会用 Spring Boot 这个开发利器来提升开发速度,再比如几年前我们使用消息队列可能还在用 ActiveMQ,到今天几乎都没有人用它了,现在比较常用的就是 Rocket MQ、Kafka 。技术更新换代这么快的今天,你是无法把每一个框架/工具都学习一遍的, 。
|
||||
技术千变万化,掌握最核心的才是王道。我们前几年可能还在用 Spring 基于传统的 XML 开发,现在几乎大家都会用 Spring Boot 这个开发利器来提升开发速度,再比如几年前我们使用消息队列可能还在用 ActiveMQ,到今天几乎都没有人用它了,现在比较常用的就是 Rocket MQ、Kafka 。技术更新换代这么快的今天,你是无法把每一个框架/工具都学习一遍的。
|
||||
|
||||
**很多初学者上来就想通过做项目学习,特别是在公司,我觉得这个是不太可取的。** 如果的 Java 基础或者 Spring Boot 基础不好的话,建议自己先提前学习一下之后再开始看视频或者通过其他方式做项目。 **还有一点就是,我不知道为什么大家都会说边跟着项目边学习做的话效果最好,我觉得这个要加一个前提是你对这门技术有基本的了解或者说你对编程有了一定的了解。**
|
||||
|
||||
|
|
@ -31,9 +31,9 @@ tag:
|
|||
|
||||
不知道其他公司的程序员是怎么样的?我感觉技术积累很大程度在乎平时,单纯依靠工作绝大部分情况只会加快自己做需求的熟练度,当然,写多了之后或多或少也会提升你对代码质量的认识(前提是你有这个意识)。
|
||||
|
||||
工作之余,我会利用业余时间来学习自己想学的东西。工作中的例子就是我刚进公司的第一个项目用到了 Spring Security+JWT ,因为当时自己对于这个技术不太了解,然后就在工作之外大概花了一周的时间学习写了一个 Demo 分享了出来,Github 地址:<https://github.com/Snailclimb/spring-security-jwt-guide> 。以次为契机,我还分享了
|
||||
工作之余,我会利用业余时间来学习自己想学的东西。工作中的例子就是我刚进公司的第一个项目用到了 Spring Security + JWT ,因为当时自己对于这个技术不太了解,然后就在工作之外大概花了一周的时间学习写了一个 Demo 分享了出来,GitHub 地址:<https://github.com/Snailclimb/spring-security-jwt-guide> 。以次为契机,我还分享了
|
||||
|
||||
- [《一问带你区分清楚 Authentication,Authorization 以及 Cookie、Session、Token》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485626&idx=1&sn=3247aa9000693dd692de8a04ccffeec1&chksm=cea24771f9d5ce675ea0203633a95b68bfe412dc6a9d05f22d221161147b76161d1b470d54b3&token=684071313&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [《一问带你区分清楚 Authentication、Authorization 以及 Cookie、Session、Token》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485626&idx=1&sn=3247aa9000693dd692de8a04ccffeec1&chksm=cea24771f9d5ce675ea0203633a95b68bfe412dc6a9d05f22d221161147b76161d1b470d54b3&token=684071313&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [JWT 身份认证优缺点分析以及常见问题解决方案](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485655&idx=1&sn=583eeeb081ea21a8ec6347c72aa223d6&chksm=cea2471cf9d5ce0aa135f2fb9aa32d98ebb3338292beaccc1aae43d1178b16c0125eb4139ca4&token=1737409938&lang=zh_CN#rd)
|
||||
|
||||
另外一个最近的例子是因为肺炎疫情在家的这段时间,自学了 Kafka,并且正在准备写一系列的入门文章,目前已经完成了:
|
||||
|
|
|
|||
|
|
@ -125,7 +125,7 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟
|
|||
|
||||
大学生活过的还是挺丰富的,我会偶尔通宵敲代码,也会偶尔半夜发疯跑出去和同学一起走走古城墙、去网吧锤一夜的 LOL。
|
||||
|
||||
大学生活专门写过一篇文章介绍: [害,毕业三年了!](https://javaguide.cn/about-the-author/my-college-life.html) 。
|
||||
大学生活专门写过一篇文章介绍:[害,毕业三年了!](./my-college-life.md) 。
|
||||
|
||||
## 总结
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ tag:
|
|||
- 个人经历
|
||||
---
|
||||
|
||||
2021-03-21,晚上 12 点,肝完了我正在做的一个项目的前端的某块功能,我随手打开了[我的 Github 主页](https://github.com/Snailclimb)。
|
||||
2021-03-21,晚上 12 点,肝完了我正在做的一个项目的前端的某块功能,我随手打开了[我的 GitHub 主页](https://github.com/Snailclimb)。
|
||||
|
||||
好家伙!几天没注意,[JavaGuide](https://github.com/Snailclimb/JavaGuide) 这个项目直接上了 100K star。
|
||||
|
||||
|
|
@ -29,11 +29,11 @@ tag:
|
|||
|
||||
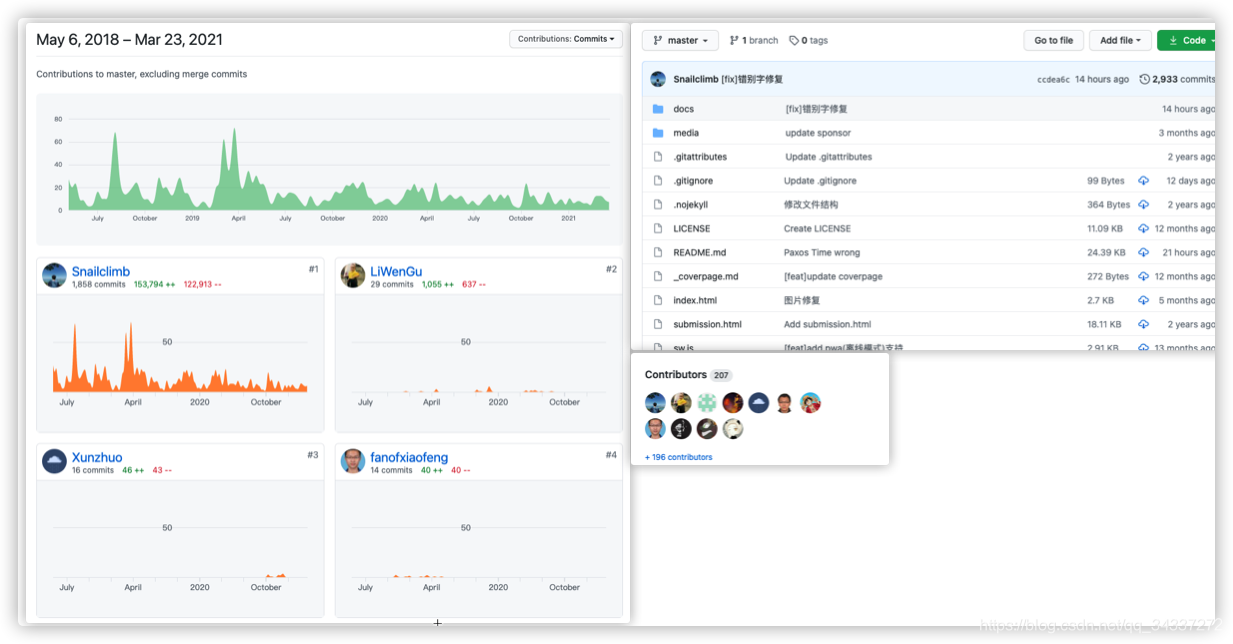
|
||||
|
||||
累计有 **511** 个 **issue** 和 **575** 个 **pr**。所有的 pr 都已经被处理,仅有 15 个左右的 issue 我还未抽出时间处理。
|
||||
累计有 **511** 个 **issue** 和 **575** 个 **PR**。所有的 PR 都已经被处理,仅有 15 个左右的 issue 我还未抽出时间处理。
|
||||
|
||||

|
||||
|
||||
其实,相比于 star 数量,你看看仓库的 issue 和 pr 更能说明你的项目是否有价值。
|
||||
其实,相比于 star 数量,你看看仓库的 issue 和 PR 更能说明你的项目是否有价值。
|
||||
|
||||
那些到处骗 star 甚至是 刷 star 的行为,我就不多说了,有点丢人。人家觉得你的项目还不错,能提供价值,自然就给你点 star 了。
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ tag:
|
|||
- 个人经历
|
||||
---
|
||||
|
||||
> 关于初高中的生活,可以看 2020 年我写的[我曾经也是网瘾少年](https://javaguide.cn/about-the-author/internet-addiction-teenager.html)这篇文章。
|
||||
> 关于初高中的生活,可以看 2020 年我写的 [我曾经也是网瘾少年](./internet-addiction-teenager.md) 这篇文章。
|
||||
|
||||
2019 年 6 月份毕业,距今已经过去了 3 年。趁着高考以及应届生毕业之际,简单聊聊自己的大学生活。
|
||||
|
||||
|
|
@ -38,7 +38,7 @@ tag:
|
|||
|
||||
我不爱出风头,性格有点内向。刚上大学那会,内心还是有一点不自信,干什么事情都畏畏缩缩,还是迫切希望改变自己的!
|
||||
|
||||
于是,凭借着一腔热血,我尝试了很多我之前从未尝试过的事情:**露营**、**户外烧烤**、**公交车演讲**、**环跑古城墙**、**徒步旅行**、**异地求生**、**圣诞节卖苹果** 、**元旦晚会演出**...。
|
||||
于是,凭借着一腔热血,我尝试了很多我之前从未尝试过的事情:**露营**、**户外烧烤**、**公交车演讲**、**环跑古城墙**、**徒步旅行**、**异地求生**、**圣诞节卖苹果**、**元旦晚会演出**...。
|
||||
|
||||
下面这些都是我和社团的小伙伴利用课外时间自己做的,在圣诞节那周基本都卖完了。我记得,为了能够多卖一些,我们还挨个去每一个寝室推销了一遍。
|
||||
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ category: 走近作者
|
|||
|
||||
## 我坚持写了多久博客?
|
||||
|
||||
时间真快啊!我自己是从大二开始写博客的。那时候就是随意地在博客平台上发发自己的学习笔记和自己写的程序。就比如 [谢希仁老师的《计算机网络》内容总结](https://javaguide.cn/cs-basics/network/%E8%B0%A2%E5%B8%8C%E4%BB%81%E8%80%81%E5%B8%88%E7%9A%84%E3%80%8A%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%E3%80%8B%E5%86%85%E5%AE%B9%E6%80%BB%E7%BB%93/) 这篇文章就是我在大二学习计算机网络这门课的时候对照着教材总结的。
|
||||
时间真快啊!我自己是从大二开始写博客的。那时候就是随意地在博客平台上发发自己的学习笔记和自己写的程序。就比如 [谢希仁老师的《计算机网络》内容总结](../cs-basics/network/computer-network-xiexiren-summary.md) 这篇文章就是我在大二学习计算机网络这门课的时候对照着教材总结的。
|
||||
|
||||
身边也有很多小伙伴经常问我:“我现在写博客还晚么?”
|
||||
|
||||
|
|
@ -49,7 +49,7 @@ category: 走近作者
|
|||
|
||||
## 为什么自称 Guide?
|
||||
|
||||
可能是因为我的项目名字叫做 JavaGuide , 所以导致有很多人称呼我为 **Guide哥**。
|
||||
可能是因为我的项目名字叫做 JavaGuide , 所以导致有很多人称呼我为 **Guide 哥**。
|
||||
|
||||
后面,为了读者更方便称呼,我就将自己的笔名改成了 **Guide**。
|
||||
|
||||
|
|
|
|||
|
|
@ -69,7 +69,7 @@ tag:
|
|||
|
||||

|
||||
|
||||
老粉应该大部分都是通过 JavaGuide 这个项目认识我的,这是我在大三开始准备秋招面试时创建的一个项目。没想到这个项目竟然火了一把,一度霸占了 Github 榜单。可能当时国内这类开源文档教程类项目太少了,所以这个项目受欢迎程度非常高。
|
||||
老粉应该大部分都是通过 JavaGuide 这个项目认识我的,这是我在大三开始准备秋招面试时创建的一个项目。没想到这个项目竟然火了一把,一度霸占了 GitHub 榜单。可能当时国内这类开源文档教程类项目太少了,所以这个项目受欢迎程度非常高。
|
||||
|
||||
|
||||
|
||||
|
|
@ -116,13 +116,13 @@ tag:
|
|||
|
||||
通常来说,写下面这些方向的博客会比较好:
|
||||
|
||||
1. **详细讲解某个知识点** :一定要有自己的思考而不是东拼西凑。不仅要介绍知识点的基本概念和原理,还需要适当结合实际案例和应用场景进行举例说明。
|
||||
2. **问题排查/性能优化经历** :需要详细描述清楚具体的场景以及解决办法。一定要有足够的细节描述,包括出现问题的具体场景、问题的根本原因、解决问题的思路和具体步骤等等。同时,要注重实践性和可操作性,帮助读者更好地学习理解。
|
||||
3. **源码阅读记录** :从一个功能点出发描述其底层源码实现,谈谈你从源码中学到了什么。
|
||||
1. **详细讲解某个知识点**:一定要有自己的思考而不是东拼西凑。不仅要介绍知识点的基本概念和原理,还需要适当结合实际案例和应用场景进行举例说明。
|
||||
2. **问题排查/性能优化经历**:需要详细描述清楚具体的场景以及解决办法。一定要有足够的细节描述,包括出现问题的具体场景、问题的根本原因、解决问题的思路和具体步骤等等。同时,要注重实践性和可操作性,帮助读者更好地学习理解。
|
||||
3. **源码阅读记录**:从一个功能点出发描述其底层源码实现,谈谈你从源码中学到了什么。
|
||||
|
||||
最重要的是一定要重视 Markdown 规范,不然内容再好也会显得不专业。
|
||||
|
||||
Markdown 规范请参考:**<https://javaguide.cn/javaguide/contribution-guideline.html>** (很重要,尽量按照规范来,对你工作中写文档会非常有帮助)
|
||||
详见 [Markdown 规范](../javaguide/contribution-guideline.md) (很重要,尽量按照规范来,对你工作中写文档会非常有帮助)
|
||||
|
||||
## 有没有什么写作技巧分享?
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ star: 2
|
|||
|
||||
|
||||
|
||||
截止到今天,星球已经有 1.3w+的同学加入。虽然比不上很多大佬,但这于我来说也算是小有成就了,真的很满足了!我确信自己是一个普通人,能做成这些,也不过是在兴趣和运气的加持下赶上了时代而已。
|
||||
截止到今天,星球已经有 1.3w+ 的同学加入。虽然比不上很多大佬,但这于我来说也算是小有成就了,真的很满足了!我确信自己是一个普通人,能做成这些,也不过是在兴趣和运气的加持下赶上了时代而已。
|
||||
|
||||
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到他人!**
|
||||
|
||||
|
|
@ -40,7 +40,7 @@ star: 2
|
|||
|
||||
### 专属专栏
|
||||
|
||||
星球更新了 **《Java 面试指北》**、**《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x 、Netty 4.x、SpringBoot2.1 的源码)、 **《从零开始写一个 RPC 框架》**(已更新完) 、**《Kafka 常见面试题/知识点总结》** 等多个优质专栏。
|
||||
星球更新了 **《Java 面试指北》**、**《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、 **《从零开始写一个 RPC 框架》**(已更新完)、**《Kafka 常见面试题/知识点总结》** 等多个优质专栏。
|
||||
|
||||

|
||||
|
||||
|
|
@ -123,11 +123,11 @@ star: 2
|
|||
|
||||
## 如何加入?
|
||||
|
||||
**方式一** :扫描下面的二维码原价加入(续费半价)。
|
||||
**方式一**:扫描下面的二维码原价加入(续费半价)。
|
||||
|
||||
|
||||
|
||||
**方式二(推荐)** :添加我的个人微信(**javaguide1024**)领取一个 **30** 元的星球专属优惠券(一定要备注“优惠卷”)。
|
||||
**方式二(推荐)**:添加我的个人微信(**javaguide1024**)领取一个 **30** 元的星球专属优惠券(一定要备注“优惠卷”)。
|
||||
|
||||
**一定要备注“优惠卷”**,不然通过不了。
|
||||
|
||||
|
|
|
|||
|
|
@ -36,12 +36,12 @@ head:
|
|||
|
||||
其他相关书籍推荐:
|
||||
|
||||
- **[《自己动手写操作系统》](https://book.douban.com/subject/1422377/)** : 不光会带着你详细分析操作系统原理的基础,还会用丰富的实例代码,一步一步地指导你用 C 语言和汇编语言编写出一个具备操作系统基本功能的操作系统框架。
|
||||
- **[《现代操作系统》](https://book.douban.com/subject/3852290/)** : 内容很不错,不过,翻译的一般。如果你是精读本书的话,建议把课后习题都做了。
|
||||
- **[《操作系统真象还原》](https://book.douban.com/subject/26745156/)** : 这本书的作者毕业于北京大学,前百度运维高级工程师。因为在大学期间曾重修操作系统这一科,后对操作系统进行深入研究,著下此书。
|
||||
- **[《深度探索 Linux 操作系统》](https://book.douban.com/subject/25743846/)** :跟着这本书的内容走,可以让你对如何制作一套完善的 GNU/Linux 系统有了清晰的认识。
|
||||
- **[《操作系统设计与实现》](https://book.douban.com/subject/2044818/)** :操作系统的权威教学教材。
|
||||
- **[《Orange'S:一个操作系统的实现》](https://book.douban.com/subject/3735649/)** : 从只有二十行的引导扇区代码出发,一步一步地向读者呈现一个操作系统框架的完成过程。配合《操作系统设计与实现》一起食用更佳!
|
||||
- **[《自己动手写操作系统》](https://book.douban.com/subject/1422377/)**:不光会带着你详细分析操作系统原理的基础,还会用丰富的实例代码,一步一步地指导你用 C 语言和汇编语言编写出一个具备操作系统基本功能的操作系统框架。
|
||||
- **[《现代操作系统》](https://book.douban.com/subject/3852290/)**:内容很不错,不过,翻译的一般。如果你是精读本书的话,建议把课后习题都做了。
|
||||
- **[《操作系统真象还原》](https://book.douban.com/subject/26745156/)**:这本书的作者毕业于北京大学,前百度运维高级工程师。因为在大学期间曾重修操作系统这一科,后对操作系统进行深入研究,著下此书。
|
||||
- **[《深度探索 Linux 操作系统》](https://book.douban.com/subject/25743846/)**:跟着这本书的内容走,可以让你对如何制作一套完善的 GNU/Linux 系统有了清晰的认识。
|
||||
- **[《操作系统设计与实现》](https://book.douban.com/subject/2044818/)**:操作系统的权威教学教材。
|
||||
- **[《Orange'S:一个操作系统的实现》](https://book.douban.com/subject/3735649/)**:从只有二十行的引导扇区代码出发,一步一步地向读者呈现一个操作系统框架的完成过程。配合《操作系统设计与实现》一起食用更佳!
|
||||
|
||||
如果你比较喜欢看视频的话,推荐哈工大李治军老师主讲的慕课 [《操作系统》](https://www.icourse163.org/course/HIT-1002531008),内容质量吊打一众国家精品课程。
|
||||
|
||||
|
|
@ -49,7 +49,7 @@ head:
|
|||
|
||||

|
||||
|
||||
主要讲了一个基本操作系统中的六个基本模块: CPU 管理、内存管理、外设管理、磁盘管理与文件系统、用户接口和启动模块 。
|
||||
主要讲了一个基本操作系统中的六个基本模块:CPU 管理、内存管理、外设管理、磁盘管理与文件系统、用户接口和启动模块 。
|
||||
|
||||
课程难度还是比较大的,尤其是课后的 lab。如果大家想要真正搞懂操作系统底层原理的话,对应的 lab 能做尽量做一下。正如李治军老师说的那样:“纸上得来终觉浅,绝知此事要躬行”。
|
||||
|
||||
|
|
@ -79,14 +79,14 @@ head:
|
|||
|
||||
如果你觉得上面这本书看着比较枯燥的话,我强烈推荐+安利你看看下面这两本非常有趣的网络相关的书籍:
|
||||
|
||||
- [《图解 HTTP》](https://book.douban.com/subject/25863515/ "《图解 HTTP》") : 讲漫画一样的讲 HTTP,很有意思,不会觉得枯燥,大概也涵盖也 HTTP 常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究 HTTP 相关知识的话,读这本书的话应该来说就差不多了。
|
||||
- [《网络是怎样连接的》](https://book.douban.com/subject/26941639/ "《网络是怎样连接的》") :从在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,以图配文,讲解了网络的全貌,并重点介绍了实际的网络设备和软件是如何工作的。
|
||||
- [《图解 HTTP》](https://book.douban.com/subject/25863515/ "《图解 HTTP》"):讲漫画一样的讲 HTTP,很有意思,不会觉得枯燥,大概也涵盖也 HTTP 常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究 HTTP 相关知识的话,读这本书的话应该来说就差不多了。
|
||||
- [《网络是怎样连接的》](https://book.douban.com/subject/26941639/ "《网络是怎样连接的》"):从在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,以图配文,讲解了网络的全貌,并重点介绍了实际的网络设备和软件是如何工作的。
|
||||
|
||||
|
||||
|
||||
除了理论知识之外,学习计算机网络非常重要的一点就是:“**动手实践**”。这点和我们编程差不多。
|
||||
|
||||
Github 上就有一些名校的计算机网络试验/Project:
|
||||
GitHub 上就有一些名校的计算机网络试验/Project:
|
||||
|
||||
- [哈工大计算机网络实验](https://github.com/rccoder/HIT-Computer-Network)
|
||||
- [《计算机网络-自顶向下方法(原书第 6 版)》编程作业,Wireshark 实验文档的翻译和解答。](https://github.com/moranzcw/Computer-Networking-A-Top-Down-Approach-NOTES)
|
||||
|
|
@ -95,11 +95,11 @@ Github 上就有一些名校的计算机网络试验/Project:
|
|||
|
||||
我知道,还有很多小伙伴可能比较喜欢边看视频边学习。所以,我这里再推荐几个顶好的计算机网络视频讲解。
|
||||
|
||||
**1、[哈工大的计算机网络课程](http://www.icourse163.org/course/HIT-154005)** :国家精品课程,截止目前已经开了 10 次课了。大家对这门课的评价都非常高!所以,非常推荐大家看一下!
|
||||
**1、[哈工大的计算机网络课程](http://www.icourse163.org/course/HIT-154005)**:国家精品课程,截止目前已经开了 10 次课了。大家对这门课的评价都非常高!所以,非常推荐大家看一下!
|
||||
|
||||
|
||||
|
||||
**2、[王道考研的计算机网络](https://www.bilibili.com/video/BV19E411D78Q?from=search&seid=17198507506906312317)** :非常适合 CS 专业考研的小朋友!这个视频目前在哔哩哔哩上已经有 1.6w+的点赞。
|
||||
**2、[王道考研的计算机网络](https://www.bilibili.com/video/BV19E411D78Q?from=search&seid=17198507506906312317)**:非常适合 CS 专业考研的小朋友!这个视频目前在哔哩哔哩上已经有 1.6w+ 的点赞。
|
||||
|
||||

|
||||
|
||||
|
|
@ -141,7 +141,7 @@ Github 上就有一些名校的计算机网络试验/Project:
|
|||
|
||||

|
||||
|
||||
这是一本被 Github 上的爆火的计算机自学项目 [Teach Yourself Computer Science](https://link.zhihu.com/?target=https%3A//teachyourselfcs.com/) 强烈推荐的一本算法书籍。
|
||||
这是一本被 GitHub 上的爆火的计算机自学项目 [Teach Yourself Computer Science](https://link.zhihu.com/?target=https%3A//teachyourselfcs.com/) 强烈推荐的一本算法书籍。
|
||||
|
||||
类似的神书还有 [《算法导论》](https://book.douban.com/subject/20432061/)、[《计算机程序设计艺术(第 1 卷)》](https://book.douban.com/subject/1130500/) 。
|
||||
|
||||
|
|
@ -185,7 +185,7 @@ Github 上就有一些名校的计算机网络试验/Project:
|
|||
|
||||
质量很高,介绍了常用的数据结构和算法。
|
||||
|
||||
类似的还有 **[《数据结构与算法分析 :C 语言描述》](https://book.douban.com/subject/1139426/)** 、**[《数据结构与算法分析:C++ 描述》](https://book.douban.com/subject/1971825/)**
|
||||
类似的还有 **[《数据结构与算法分析:C 语言描述》](https://book.douban.com/subject/1139426/)**、**[《数据结构与算法分析:C++ 描述》](https://book.douban.com/subject/1971825/)**
|
||||
|
||||
|
||||
|
||||
|
|
@ -266,8 +266,8 @@ Github 上就有一些名校的计算机网络试验/Project:
|
|||
|
||||
其他书籍推荐:
|
||||
|
||||
- **[《现代编译原理》](https://book.douban.com/subject/30191414/)** :编译原理的入门书。
|
||||
- **[《编译器设计》](https://book.douban.com/subject/20436488/)** : 覆盖了编译器从前端到后端的全部主题。
|
||||
- **[《现代编译原理》](https://book.douban.com/subject/30191414/)**:编译原理的入门书。
|
||||
- **[《编译器设计》](https://book.douban.com/subject/20436488/)**:覆盖了编译器从前端到后端的全部主题。
|
||||
|
||||
我上面推荐的书籍的难度还是比较高的,真心很难坚持看完。这里强烈推荐[哈工大的编译原理视频课程](https://www.icourse163.org/course/HIT-1002123007),真心不错,还是国家精品课程,关键还是又漂亮有温柔的美女老师讲的!
|
||||
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ head:
|
|||
|
||||

|
||||
|
||||
Github 上也已经有大佬用 Java 实现过一个简易的数据库,介绍的挺详细的,感兴趣的朋友可以去看看。地址:[https://github.com/alchemystar/Freedom](https://github.com/alchemystar/Freedom) 。
|
||||
GitHub 上也已经有大佬用 Java 实现过一个简易的数据库,介绍的挺详细的,感兴趣的朋友可以去看看。地址:[https://github.com/alchemystar/Freedom](https://github.com/alchemystar/Freedom) 。
|
||||
|
||||
除了这个用 Java 写的之外,**[db_tutorial](https://github.com/cstack/db_tutorial)** 这个项目是国外的一个大佬用 C 语言写的,朋友们也可以去瞅瞅。
|
||||
|
||||
|
|
@ -54,9 +54,9 @@ Github 上也已经有大佬用 Java 实现过一个简易的数据库,介绍
|
|||
|
||||
一般企业项目开发中,使用 MySQL 比较多。如果你要学习 MySQL 的话,可以看下面这 3 本书籍:
|
||||
|
||||
- **[《MySQL 必知必会》](https://book.douban.com/subject/3354490/)** :非常薄!非常适合 MySQL 新手阅读,很棒的入门教材。
|
||||
- **[《高性能 MySQL》](https://book.douban.com/subject/23008813/)** : MySQL 领域的经典之作!学习 MySQL 必看!属于进阶内容,主要教你如何更好地使用 MySQL 。既有有理论,又有实践!如果你没时间都看一遍的话,我建议第 5 章(创建高性能的索引) 、第 6 章(查询性能优化) 你一定要认真看一下。
|
||||
- **[《MySQL 技术内幕》](https://book.douban.com/subject/24708143/)** :你想深入了解 MySQL 存储引擎的话,看这本书准没错!
|
||||
- **[《MySQL 必知必会》](https://book.douban.com/subject/3354490/)**:非常薄!非常适合 MySQL 新手阅读,很棒的入门教材。
|
||||
- **[《高性能 MySQL》](https://book.douban.com/subject/23008813/)**:MySQL 领域的经典之作!学习 MySQL 必看!属于进阶内容,主要教你如何更好地使用 MySQL 。既有有理论,又有实践!如果你没时间都看一遍的话,我建议第 5 章(创建高性能的索引)、第 6 章(查询性能优化) 你一定要认真看一下。
|
||||
- **[《MySQL 技术内幕》](https://book.douban.com/subject/24708143/)**:你想深入了解 MySQL 存储引擎的话,看这本书准没错!
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -87,5 +87,5 @@ icon: "distributed-network"
|
|||
|
||||
## 其他
|
||||
|
||||
- [《分布式系统 : 概念与设计》](https://book.douban.com/subject/21624776/) :偏教材类型,内容全而无趣,可作为参考书籍;
|
||||
- [《分布式架构原理与实践》](https://book.douban.com/subject/35689350/) :2021 年出版的,没什么热度,我也还没看过。
|
||||
- [《分布式系统 : 概念与设计》](https://book.douban.com/subject/21624776/):偏教材类型,内容全而无趣,可作为参考书籍;
|
||||
- [《分布式架构原理与实践》](https://book.douban.com/subject/35689350/):2021 年出版的,没什么热度,我也还没看过。
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@ icon: "java"
|
|||
|
||||
我个人觉得这本书还是挺适合编程新手阅读的,毕竟是 “Head First” 系列。
|
||||
|
||||
**[《Java 核心技术卷 1+卷 2》](https://book.douban.com/subject/34898994/)**
|
||||
**[《Java 核心技术卷 1 + 卷 2》](https://book.douban.com/subject/34898994/)**
|
||||
|
||||

|
||||
|
||||
|
|
@ -122,12 +122,12 @@ _这本书还是非常适合我们用来学习 Java 多线程的。这本书的
|
|||
|
||||
非常重要!非常重要!特别是 Git 和 Docker。
|
||||
|
||||
- **IDEA** :熟悉基本操作以及常用快捷。你可以通过 Github 上的开源教程 [《IntelliJ IDEA 简体中文专题教程》](https://github.com/judasn/IntelliJ-IDEA-Tutorial) 来学习 IDEA 的使用。
|
||||
- **Maven** :强烈建议学习常用框架之前可以提前花几天时间学习一下**Maven**的使用。(到处找 Jar 包,下载 Jar 包是真的麻烦费事,使用 Maven 可以为你省很多事情)。
|
||||
- **Git** :基本的 Git 技能也是必备的,试着在学习的过程中将自己的代码托管在 Github 上。你可以看看这篇 Github 上开源的 [《Git 极简入门》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Git) 。
|
||||
- **Docker** :学着用 Docker 安装学习中需要用到的软件比如 MySQL ,这样方便很多,可以为你节省不少时间。你可以看看这篇 Github 上开源的 [《Docker 基本概念解读》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Docker) 、[《一文搞懂 Docker 镜像的常用操作!》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Docker-Image)
|
||||
- **IDEA**:熟悉基本操作以及常用快捷。你可以通过 GitHub 上的开源教程 [《IntelliJ IDEA 简体中文专题教程》](https://github.com/judasn/IntelliJ-IDEA-Tutorial) 来学习 IDEA 的使用。
|
||||
- **Maven**:强烈建议学习常用框架之前可以提前花几天时间学习一下**Maven**的使用。(到处找 Jar 包,下载 Jar 包是真的麻烦费事,使用 Maven 可以为你省很多事情)。
|
||||
- **Git**:基本的 Git 技能也是必备的,试着在学习的过程中将自己的代码托管在 Github 上。你可以看看这篇 Github 上开源的 [《Git 极简入门》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Git) 。
|
||||
- **Docker**:学着用 Docker 安装学习中需要用到的软件比如 MySQL ,这样方便很多,可以为你节省不少时间。你可以看看这篇 Github 上开源的 [《Docker 基本概念解读》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Docker) 、[《一文搞懂 Docker 镜像的常用操作!》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Docker-Image)
|
||||
|
||||
除了这些工具之外,我强烈建议你一定要搞懂 Github 的使用。一些使用 Github 的小技巧,你可以看[《Github 小技巧》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Github%E6%8A%80%E5%B7%A7)这篇文章。
|
||||
除了这些工具之外,我强烈建议你一定要搞懂 GitHub 的使用。一些使用 GitHub 的小技巧,你可以看[《GitHub 小技巧》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Github%E6%8A%80%E5%B7%A7)这篇文章。
|
||||
|
||||
## 常用框架
|
||||
|
||||
|
|
@ -177,7 +177,7 @@ SpringBoot 解析,不适合初学者。我是去年入手的,现在就看了
|
|||
|
||||

|
||||
|
||||
这本书可以用来入门 Netty ,内容从 BIO 聊到了 NIO、之后才详细介绍为什么有 Netty 、Netty 为什么好用以及 Netty 重要的知识点讲解。
|
||||
这本书可以用来入门 Netty ,内容从 BIO 聊到了 NIO、之后才详细介绍为什么有 Netty、Netty 为什么好用以及 Netty 重要的知识点讲解。
|
||||
|
||||
这本书基本把 Netty 一些重要的知识点都介绍到了,而且基本都是通过实战的形式讲解。
|
||||
|
||||
|
|
@ -229,6 +229,6 @@ O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是
|
|||
|
||||
[JavaGuide](https://javaguide.cn/) 的面试版本,涵盖了 Java 后端方面的大部分知识点比如 集合、JVM、多线程还有数据库 MySQL 等内容。
|
||||
|
||||
公众号后台回复 :“**面试突击**” 即可免费获取,无任何套路。
|
||||
公众号后台回复:“**面试突击**” 即可免费获取,无任何套路。
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -9,11 +9,11 @@ category: 计算机书籍
|
|||
|
||||
开源的目的是为了大家能一起完善,如果你觉得内容有任何需要完善/补充的地方,欢迎大家在项目 [issues 区](https://github.com/CodingDocs/awesome-cs/issues) 推荐自己认可的技术书籍,让我们共同维护一个优质的技术书籍精选集!
|
||||
|
||||
- Github 地址:[https://github.com/CodingDocs/awesome-cs](https://github.com/CodingDocs/awesome-cs)
|
||||
- GitHub 地址:[https://github.com/CodingDocs/awesome-cs](https://github.com/CodingDocs/awesome-cs)
|
||||
- Gitee 地址:[https://gitee.com/SnailClimb/awesome-cs](https://gitee.com/SnailClimb/awesome-cs)
|
||||
|
||||
如果内容对你有帮助的话,欢迎给本项目点个 Star。我会用我的业余时间持续完善这份书单,感谢!
|
||||
|
||||
本项目推荐的大部分书籍的 PDF 版本我已经整理到了云盘里,你可以在公众号“**Github 掘金计划**” 后台回复“**书籍**”获取到。
|
||||
本项目推荐的大部分书籍的 PDF 版本我已经整理到了云盘里,你可以在公众号“**GitHub 掘金计划**” 后台回复“**书籍**”获取到。
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -120,12 +120,12 @@ Bob 大叔将自己对整洁代码的理解浓缩在了这本书中,真可谓
|
|||
|
||||
## 其他
|
||||
|
||||
- [《代码的未来》](https://book.douban.com/subject/24536403/) :这本书的作者是 Ruby 之父松本行弘,算是一本年代比较久远的书籍(13 年出版),不过,还是非常值得一读。这本书的内容主要介绍是编程/编程语言的本质。我个人还是比较喜欢松本行弘的文字风格,并且,你看他的文章也确实能够有所收获。
|
||||
- [《深入浅出设计模式》](https://book.douban.com/subject/1488876/) : 比较有趣的风格,适合设计模式入门。
|
||||
- [《软件架构设计:大型网站技术架构与业务架构融合之道》](https://book.douban.com/subject/30443578/) : 内容非常全面。适合面试前突击一些比较重要的理论知识,也适合拿来扩充/完善自己的技术广度。
|
||||
- [《微服务架构设计模式》](https://book.douban.com/subject/33425123/) :这本书是世界十大软件架构师之一、微服务架构先驱 Chris Richardson 亲笔撰写,豆瓣评分 9.6。示例代码使用 Java 语言和 Spring 框架。帮助你设计、实现、测试和部署基于微服务的应用程序。
|
||||
- [《代码的未来》](https://book.douban.com/subject/24536403/):这本书的作者是 Ruby 之父松本行弘,算是一本年代比较久远的书籍(13 年出版),不过,还是非常值得一读。这本书的内容主要介绍是编程/编程语言的本质。我个人还是比较喜欢松本行弘的文字风格,并且,你看他的文章也确实能够有所收获。
|
||||
- [《深入浅出设计模式》](https://book.douban.com/subject/1488876/):比较有趣的风格,适合设计模式入门。
|
||||
- [《软件架构设计:大型网站技术架构与业务架构融合之道》](https://book.douban.com/subject/30443578/):内容非常全面。适合面试前突击一些比较重要的理论知识,也适合拿来扩充/完善自己的技术广度。
|
||||
- [《微服务架构设计模式》](https://book.douban.com/subject/33425123/):这本书是世界十大软件架构师之一、微服务架构先驱 Chris Richardson 亲笔撰写,豆瓣评分 9.6。示例代码使用 Java 语言和 Spring 框架。帮助你设计、实现、测试和部署基于微服务的应用程序。
|
||||
|
||||
最后再推荐两个相关的文档:
|
||||
|
||||
- **阿里巴巴 Java 开发手册** :<https://github.com/alibaba/p3c>
|
||||
- **Google Java 编程风格指南**: <http://www.hawstein.com/posts/google-java-style.html>
|
||||
- **阿里巴巴 Java 开发手册**:<https://github.com/alibaba/p3c>
|
||||
- **Google Java 编程风格指南**:<http://www.hawstein.com/posts/google-java-style.html>
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ tag:
|
|||
- 算法
|
||||
---
|
||||
|
||||
> 本文转自:http://www.guoyaohua.com/sorting.html,JavaGuide 对其做了补充完善。
|
||||
> 本文转自:<http://www.guoyaohua.com/sorting.html>,JavaGuide 对其做了补充完善。
|
||||
|
||||
## 引言
|
||||
|
||||
|
|
@ -17,8 +17,8 @@ tag:
|
|||
|
||||
排序算法可以分为:
|
||||
|
||||
- **内部排序** :数据记录在内存中进行排序。
|
||||
- **[外部排序](https://zh.wikipedia.org/wiki/外排序)** :因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
|
||||
- **内部排序**:数据记录在内存中进行排序。
|
||||
- **[外部排序](https://zh.wikipedia.org/wiki/外排序)**:因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
|
||||
|
||||
常见的内部排序算法有:**插入排序**、**希尔排序**、**选择排序**、**冒泡排序**、**归并排序**、**快速排序**、**堆排序**、**基数排序**等,本文只讲解内部排序算法。用一张图概括:
|
||||
|
||||
|
|
@ -37,7 +37,7 @@ tag:
|
|||
- **不稳定**:如果 A 原本在 B 的前面,而 A=B,排序之后 A 可能会出现在 B 的后面。
|
||||
- **内排序**:所有排序操作都在内存中完成。
|
||||
- **外排序**:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行。
|
||||
- **时间复杂度**: 定性描述一个算法执行所耗费的时间。
|
||||
- **时间复杂度**:定性描述一个算法执行所耗费的时间。
|
||||
- **空间复杂度**:定性描述一个算法执行所需内存的大小。
|
||||
|
||||
### 算法分类
|
||||
|
|
@ -87,7 +87,7 @@ public static int[] bubbleSort(int[] arr) {
|
|||
int tmp = arr[j];
|
||||
arr[j] = arr[j + 1];
|
||||
arr[j + 1] = tmp;
|
||||
// Change flag
|
||||
// Change flag
|
||||
flag = false;
|
||||
}
|
||||
}
|
||||
|
|
@ -104,9 +104,9 @@ public static int[] bubbleSort(int[] arr) {
|
|||
### 算法分析
|
||||
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度** :最佳:O(n) ,最差:O(n2), 平均:O(n2)
|
||||
- **空间复杂度** :O(1)
|
||||
- **排序方式** :In-place
|
||||
- **时间复杂度**:最佳:O(n) ,最差:O(n2), 平均:O(n2)
|
||||
- **空间复杂度**:O(1)
|
||||
- **排序方式**:In-place
|
||||
|
||||
## 选择排序 (Selection Sort)
|
||||
|
||||
|
|
@ -151,9 +151,9 @@ public static int[] selectionSort(int[] arr) {
|
|||
### 算法分析
|
||||
|
||||
- **稳定性**:不稳定
|
||||
- **时间复杂度** :最佳:O(n2) ,最差:O(n2), 平均:O(n2)
|
||||
- **空间复杂度** :O(1)
|
||||
- **排序方式** :In-place
|
||||
- **时间复杂度**:最佳:O(n2) ,最差:O(n2), 平均:O(n2)
|
||||
- **空间复杂度**:O(1)
|
||||
- **排序方式**:In-place
|
||||
|
||||
## 插入排序 (Insertion Sort)
|
||||
|
||||
|
|
@ -201,9 +201,9 @@ public static int[] insertionSort(int[] arr) {
|
|||
### 算法分析
|
||||
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度** :最佳:O(n) ,最差:O(n2), 平均:O(n2)
|
||||
- **空间复杂度** :O(1)
|
||||
- **排序方式** :In-place
|
||||
- **时间复杂度**:最佳:O(n) ,最差:O(n2), 平均:O(n2)
|
||||
- **空间复杂度**:O(1)
|
||||
- **排序方式**:In-place
|
||||
|
||||
## 希尔排序 (Shell Sort)
|
||||
|
||||
|
|
@ -258,8 +258,8 @@ public static int[] shellSort(int[] arr) {
|
|||
### 算法分析
|
||||
|
||||
- **稳定性**:不稳定
|
||||
- **时间复杂度** :最佳:O(nlogn), 最差:O(n2) 平均:O(nlogn)
|
||||
- **空间复杂度** :`O(1)`
|
||||
- **时间复杂度**:最佳:O(nlogn), 最差:O(n2) 平均:O(nlogn)
|
||||
- **空间复杂度**:`O(1)`
|
||||
|
||||
## 归并排序 (Merge Sort)
|
||||
|
||||
|
|
@ -341,8 +341,8 @@ public static int[] merge(int[] arr_1, int[] arr_2) {
|
|||
### 算法分析
|
||||
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度** :最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
|
||||
- **空间复杂度** :O(n)
|
||||
- **时间复杂度**:最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
|
||||
- **空间复杂度**:O(n)
|
||||
|
||||
## 快速排序 (Quick Sort)
|
||||
|
||||
|
|
@ -395,9 +395,9 @@ public static void quickSort(int[] array, int low, int high) {
|
|||
|
||||
### 算法分析
|
||||
|
||||
- **稳定性** :不稳定
|
||||
- **时间复杂度** :最佳:O(nlogn), 最差:O(nlogn),平均:O(nlogn)
|
||||
- **空间复杂度** :O(nlogn)
|
||||
- **稳定性**:不稳定
|
||||
- **时间复杂度**:最佳:O(nlogn), 最差:O(nlogn),平均:O(nlogn)
|
||||
- **空间复杂度**:O(nlogn)
|
||||
|
||||
## 堆排序 (Heap Sort)
|
||||
|
||||
|
|
@ -484,9 +484,9 @@ public static int[] heapSort(int[] arr) {
|
|||
|
||||
### 算法分析
|
||||
|
||||
- **稳定性** :不稳定
|
||||
- **时间复杂度** :最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
|
||||
- **空间复杂度** :O(1)
|
||||
- **稳定性**:不稳定
|
||||
- **时间复杂度**:最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
|
||||
- **空间复杂度**:O(1)
|
||||
|
||||
## 计数排序 (Counting Sort)
|
||||
|
||||
|
|
@ -564,9 +564,9 @@ public static int[] countingSort(int[] arr) {
|
|||
|
||||
当输入的元素是 `n` 个 `0` 到 `k` 之间的整数时,它的运行时间是 `O(n+k)`。计数排序不是比较排序,排序的速度快于任何比较排序算法。由于用来计数的数组 `C` 的长度取决于待排序数组中数据的范围(等于待排序数组的**最大值与最小值的差加上 1**),这使得计数排序对于数据范围很大的数组,需要大量额外内存空间。
|
||||
|
||||
- **稳定性** :稳定
|
||||
- **时间复杂度** :最佳:`O(n+k)` 最差:`O(n+k)` 平均:`O(n+k)`
|
||||
- **空间复杂度** :`O(k)`
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度**:最佳:`O(n+k)` 最差:`O(n+k)` 平均:`O(n+k)`
|
||||
- **空间复杂度**:`O(k)`
|
||||
|
||||
## 桶排序 (Bucket Sort)
|
||||
|
||||
|
|
@ -647,9 +647,9 @@ public static List<Integer> bucketSort(List<Integer> arr, int bucket_size) {
|
|||
|
||||
### 算法分析
|
||||
|
||||
- **稳定性** :稳定
|
||||
- **时间复杂度** :最佳:`O(n+k)` 最差:`O(n²)` 平均:`O(n+k)`
|
||||
- **空间复杂度** :`O(k)`
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度**:最佳:`O(n+k)` 最差:`O(n²)` 平均:`O(n+k)`
|
||||
- **空间复杂度**:`O(k)`
|
||||
|
||||
## 基数排序 (Radix Sort)
|
||||
|
||||
|
|
@ -715,9 +715,9 @@ public static int[] radixSort(int[] arr) {
|
|||
|
||||
### 算法分析
|
||||
|
||||
- **稳定性** :稳定
|
||||
- **时间复杂度** :最佳:`O(n×k)` 最差:`O(n×k)` 平均:`O(n×k)`
|
||||
- **空间复杂度** :`O(n+k)`
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度**:最佳:`O(n×k)` 最差:`O(n×k)` 平均:`O(n×k)`
|
||||
- **空间复杂度**:`O(n+k)`
|
||||
|
||||
**基数排序 vs 计数排序 vs 桶排序**
|
||||
|
||||
|
|
@ -729,6 +729,6 @@ public static int[] radixSort(int[] arr) {
|
|||
|
||||
## 参考文章
|
||||
|
||||
- https://www.cnblogs.com/guoyaohua/p/8600214.html
|
||||
- https://en.wikipedia.org/wiki/Sorting_algorithm
|
||||
- https://sort.hust.cc/
|
||||
- <https://www.cnblogs.com/guoyaohua/p/8600214.html>
|
||||
- <https://en.wikipedia.org/wiki/Sorting_algorithm>
|
||||
- <https://sort.hust.cc/>
|
||||
|
|
|
|||
|
|
@ -289,12 +289,7 @@ public class Solution {
|
|||
return dummy.next;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**复杂度分析:**
|
||||
|
||||
- **时间复杂度 O(L)** :该算法对列表进行了两次遍历,首先计算了列表的长度 L\*L 其次找到第 (L - n)(L − n) 个结点。 操作执行了 (2L-n)(2L − n) 步,时间复杂度为 O(L)O(L)。
|
||||
- **空间复杂度 O(1)** :我们只用了常量级的额外空间。
|
||||
``
|
||||
|
||||
**进阶——一次遍历法:**
|
||||
|
||||
|
|
|
|||
|
|
@ -227,7 +227,7 @@ public String replaceSpace(StringBuffer str) {
|
|||
**问题解析:**
|
||||
|
||||
这道题算是比较麻烦和难一点的一个了。我这里采用的是**二分幂**思想,当然也可以采用**快速幂**。
|
||||
更具剑指 offer 书中细节,该题的解题思路如下: 1.当底数为 0 且指数<0 时,会出现对 0 求倒数的情况,需进行错误处理,设置一个全局变量; 2.判断底数是否等于 0,由于 base 为 double 型,所以不能直接用==判断 3.优化求幂函数(二分幂)。
|
||||
更具剑指 offer 书中细节,该题的解题思路如下:1.当底数为 0 且指数<0 时,会出现对 0 求倒数的情况,需进行错误处理,设置一个全局变量; 2.判断底数是否等于 0,由于 base 为 double 型,所以不能直接用==判断 3.优化求幂函数(二分幂)。
|
||||
当 n 为偶数,a^n =(a^n/2)_(a^n/2);
|
||||
当 n 为奇数,a^n = a^[(n-1)/2] _ a^[(n-1)/2] \* a。时间复杂度 O(logn)
|
||||
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ tag:
|
|||
|
||||
首先,我们需要了解布隆过滤器的概念。
|
||||
|
||||
布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于 1970 年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
|
||||
布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于 1970 年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
|
||||
|
||||

|
||||
|
||||
|
|
@ -239,13 +239,13 @@ System.out.println(filter.mightContain(2));
|
|||
|
||||
### 介绍
|
||||
|
||||
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :https://redis.io/modules
|
||||
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍:https://redis.io/modules
|
||||
|
||||
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom
|
||||
其他还有:
|
||||
|
||||
- redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
|
||||
- pyreBloom(Python 中的快速 Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
|
||||
- pyreBloom(Python 中的快速 Redis 布隆过滤器):https://github.com/seomoz/pyreBloom
|
||||
- ......
|
||||
|
||||
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
|
||||
|
|
@ -265,12 +265,12 @@ root@21396d02c252:/data# redis-cli
|
|||
|
||||
### 常用命令一览
|
||||
|
||||
> 注意: key : 布隆过滤器的名称,item : 添加的元素。
|
||||
> 注意:key : 布隆过滤器的名称,item : 添加的元素。
|
||||
|
||||
1. **`BF.ADD`**:将元素添加到布隆过滤器中,如果该过滤器尚不存在,则创建该过滤器。格式:`BF.ADD {key} {item}`。
|
||||
2. **`BF.MADD`** : 将一个或多个元素添加到“布隆过滤器”中,并创建一个尚不存在的过滤器。该命令的操作方式`BF.ADD`与之相同,只不过它允许多个输入并返回多个值。格式:`BF.MADD {key} {item} [item ...]` 。
|
||||
3. **`BF.EXISTS`** : 确定元素是否在布隆过滤器中存在。格式:`BF.EXISTS {key} {item}`。
|
||||
4. **`BF.MEXISTS`** : 确定一个或者多个元素是否在布隆过滤器中存在格式:`BF.MEXISTS {key} {item} [item ...]`。
|
||||
4. **`BF.MEXISTS`**:确定一个或者多个元素是否在布隆过滤器中存在格式:`BF.MEXISTS {key} {item} [item ...]`。
|
||||
|
||||
另外, `BF. RESERVE` 命令需要单独介绍一下:
|
||||
|
||||
|
|
|
|||
|
|
@ -41,8 +41,8 @@ tag:
|
|||
|
||||
堆分为 **最大堆** 和 **最小堆**。二者的区别在于节点的排序方式。
|
||||
|
||||
- **最大堆** :堆中的每一个节点的值都大于等于子树中所有节点的值
|
||||
- **最小堆** :堆中的每一个节点的值都小于等于子树中所有节点的值
|
||||
- **最大堆**:堆中的每一个节点的值都大于等于子树中所有节点的值
|
||||
- **最小堆**:堆中的每一个节点的值都小于等于子树中所有节点的值
|
||||
|
||||
如下图所示,图 1 是最大堆,图 2 是最小堆
|
||||
|
||||
|
|
@ -123,8 +123,8 @@ tag:
|
|||
|
||||
### 堆的操作总结
|
||||
|
||||
- **插入元素** :先将元素放至数组末尾,再自底向上堆化,将末尾元素上浮
|
||||
- **删除堆顶元素** :删除堆顶元素,将末尾元素放至堆顶,再自顶向下堆化,将堆顶元素下沉。也可以自底向上堆化,只是会产生“气泡”,浪费存储空间。最好采用自顶向下堆化的方式。
|
||||
- **插入元素**:先将元素放至数组末尾,再自底向上堆化,将末尾元素上浮
|
||||
- **删除堆顶元素**:删除堆顶元素,将末尾元素放至堆顶,再自顶向下堆化,将堆顶元素下沉。也可以自底向上堆化,只是会产生“气泡”,浪费存储空间。最好采用自顶向下堆化的方式。
|
||||
|
||||
## 堆排序
|
||||
|
||||
|
|
|
|||
|
|
@ -118,7 +118,7 @@ tag:
|
|||
> 1. 左括号必须用相同类型的右括号闭合。
|
||||
> 2. 左括号必须以正确的顺序闭合。
|
||||
>
|
||||
> 比如 "()"、"()[]{}"、"{[]}" 都是有效字符串,而 "(]" 、"([)]" 则不是。
|
||||
> 比如 "()"、"()[]{}"、"{[]}" 都是有效字符串,而 "(]"、"([)]" 则不是。
|
||||
|
||||
这个问题实际是 Leetcode 的一道题目,我们可以利用栈 `Stack` 来解决这个问题。
|
||||
|
||||
|
|
@ -258,7 +258,7 @@ myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
|
|||
|
||||
### 4.1. 队列简介
|
||||
|
||||
**队列(Queue)** 是 **先进先出( FIFO,First In, First Out)** 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 **顺序队列** ,用链表实现的队列叫作 **链式队列** 。**队列只允许在后端(rear)进行插入操作也就是 入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue**
|
||||
**队列(Queue)** 是 **先进先出 (FIFO,First In, First Out)** 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 **顺序队列** ,用链表实现的队列叫作 **链式队列** 。**队列只允许在后端(rear)进行插入操作也就是入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue**
|
||||
|
||||
队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。
|
||||
|
||||
|
|
@ -295,14 +295,14 @@ myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
|
|||
顺序队列中,我们说 `front==rear` 的时候队列为空,循环队列中则不一样,也可能为满,如上图所示。解决办法有两种:
|
||||
|
||||
1. 可以设置一个标志变量 `flag`,当 `front==rear` 并且 `flag=0` 的时候队列为空,当`front==rear` 并且 `flag=1` 的时候队列为满。
|
||||
2. 队列为空的时候就是 `front==rear` ,队列满的时候,我们保证数组还有一个空闲的位置,rear 就指向这个空闲位置,如下图所示,那么现在判断队列是否为满的条件就是: `(rear+1) % QueueSize= front` 。
|
||||
2. 队列为空的时候就是 `front==rear` ,队列满的时候,我们保证数组还有一个空闲的位置,rear 就指向这个空闲位置,如下图所示,那么现在判断队列是否为满的条件就是:`(rear+1) % QueueSize= front` 。
|
||||
|
||||
### 4.3. 常见应用场景
|
||||
|
||||
当我们需要按照一定顺序来处理数据的时候可以考虑使用队列这个数据结构。
|
||||
|
||||
- **阻塞队列:** 阻塞队列可以看成在队列基础上加了阻塞操作的队列。当队列为空的时候,出队操作阻塞,当队列满的时候,入队操作阻塞。使用阻塞队列我们可以很容易实现“生产者 - 消费者“模型。
|
||||
- **线程池中的请求/任务队列:** 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如 :`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出`java.util.concurrent.RejectedExecutionException` 异常。
|
||||
- **线程池中的请求/任务队列:** 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如:`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出`java.util.concurrent.RejectedExecutionException` 异常。
|
||||
- Linux 内核进程队列(按优先级排队)
|
||||
- 现实生活中的派对,播放器上的播放列表;
|
||||
- 消息队列
|
||||
|
|
|
|||
|
|
@ -14,8 +14,8 @@ tag:
|
|||
4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
|
||||
5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
|
||||
|
||||
**红黑树的应用** :TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。
|
||||
**红黑树的应用**:TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。
|
||||
|
||||
**为什么要用红黑树?** 简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
|
||||
|
||||
**相关阅读** :[《红黑树深入剖析及 Java 实现》](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
|
||||
**相关阅读**:[《红黑树深入剖析及 Java 实现》](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
|
||||
|
|
|
|||
|
|
@ -19,16 +19,16 @@ tag:
|
|||
|
||||
如上图所示,通过上面这张图说明一下树中的常用概念:
|
||||
|
||||
- **节点** :树中的每个元素都可以统称为节点。
|
||||
- **根节点** :顶层节点或者说没有父节点的节点。上图中 A 节点就是根节点。
|
||||
- **父节点** :若一个节点含有子节点,则这个节点称为其子节点的父节点。上图中的 B 节点是 D 节点、E 节点的父节点。
|
||||
- **子节点** :一个节点含有的子树的根节点称为该节点的子节点。上图中 D 节点、E 节点是 B 节点的子节点。
|
||||
- **兄弟节点** :具有相同父节点的节点互称为兄弟节点。上图中 D 节点、E 节点的共同父节点是 B 节点,故 D 和 E 为兄弟节点。
|
||||
- **叶子节点** :没有子节点的节点。上图中的 D、F、H、I 都是叶子节点。
|
||||
- **节点的高度** :该节点到叶子节点的最长路径所包含的边数。
|
||||
- **节点的深度** :根节点到该节点的路径所包含的边数
|
||||
- **节点的层数** :节点的深度+1。
|
||||
- **树的高度** :根节点的高度。
|
||||
- **节点**:树中的每个元素都可以统称为节点。
|
||||
- **根节点**:顶层节点或者说没有父节点的节点。上图中 A 节点就是根节点。
|
||||
- **父节点**:若一个节点含有子节点,则这个节点称为其子节点的父节点。上图中的 B 节点是 D 节点、E 节点的父节点。
|
||||
- **子节点**:一个节点含有的子树的根节点称为该节点的子节点。上图中 D 节点、E 节点是 B 节点的子节点。
|
||||
- **兄弟节点**:具有相同父节点的节点互称为兄弟节点。上图中 D 节点、E 节点的共同父节点是 B 节点,故 D 和 E 为兄弟节点。
|
||||
- **叶子节点**:没有子节点的节点。上图中的 D、F、H、I 都是叶子节点。
|
||||
- **节点的高度**:该节点到叶子节点的最长路径所包含的边数。
|
||||
- **节点的深度**:根节点到该节点的路径所包含的边数
|
||||
- **节点的层数**:节点的深度+1。
|
||||
- **树的高度**:根节点的高度。
|
||||
|
||||
> 关于树的深度和高度的定义可以看 stackoverflow 上的这个问题:[What is the difference between tree depth and height?](https://stackoverflow.com/questions/2603692/what-is-the-difference-between-tree-depth-and-height) 。
|
||||
|
||||
|
|
|
|||
|
|
@ -98,8 +98,8 @@ RTP(Real-time Transport Protocol,实时传输协议)通常基于 UDP 协
|
|||
|
||||
RTP 协议分为两种子协议:
|
||||
|
||||
- **RTP(Real-time Transport Protocol,实时传输协议)** :传输具有实时特性的数据。
|
||||
- **RTCP(RTP Control Protocol,RTP 控制协议)** :提供实时传输过程中的统计信息(如网络延迟、丢包率等),WebRTC 正是根据这些信息处理丢包
|
||||
- **RTP(Real-time Transport Protocol,实时传输协议)**:传输具有实时特性的数据。
|
||||
- **RTCP(RTP Control Protocol,RTP 控制协议)**:提供实时传输过程中的统计信息(如网络延迟、丢包率等),WebRTC 正是根据这些信息处理丢包
|
||||
|
||||
## DNS:域名系统
|
||||
|
||||
|
|
|
|||
|
|
@ -15,41 +15,41 @@ tag:
|
|||
|
||||
### 1.1. 基本术语
|
||||
|
||||
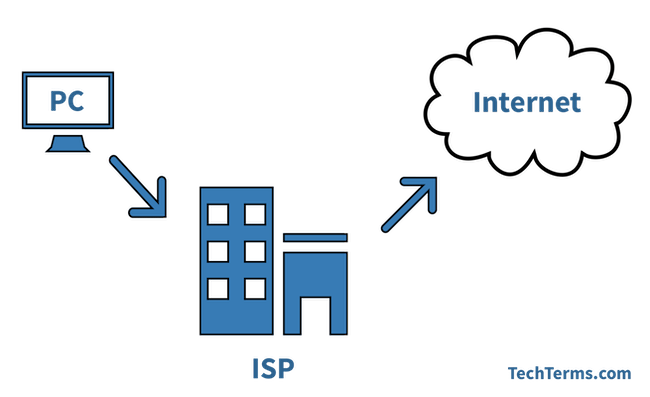
1. **结点 (node)** :网络中的结点可以是计算机,集线器,交换机或路由器等。
|
||||
1. **结点 (node)**:网络中的结点可以是计算机,集线器,交换机或路由器等。
|
||||
2. **链路(link )** : 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
|
||||
3. **主机(host)** :连接在因特网上的计算机。
|
||||
4. **ISP(Internet Service Provider)** :因特网服务提供者(提供商)。
|
||||
3. **主机(host)**:连接在因特网上的计算机。
|
||||
4. **ISP(Internet Service Provider)**:因特网服务提供者(提供商)。
|
||||
|
||||
|
||||
|
||||
5. **IXP(Internet eXchange Point)** : 互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
|
||||
5. **IXP(Internet eXchange Point)**:互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
|
||||
|
||||
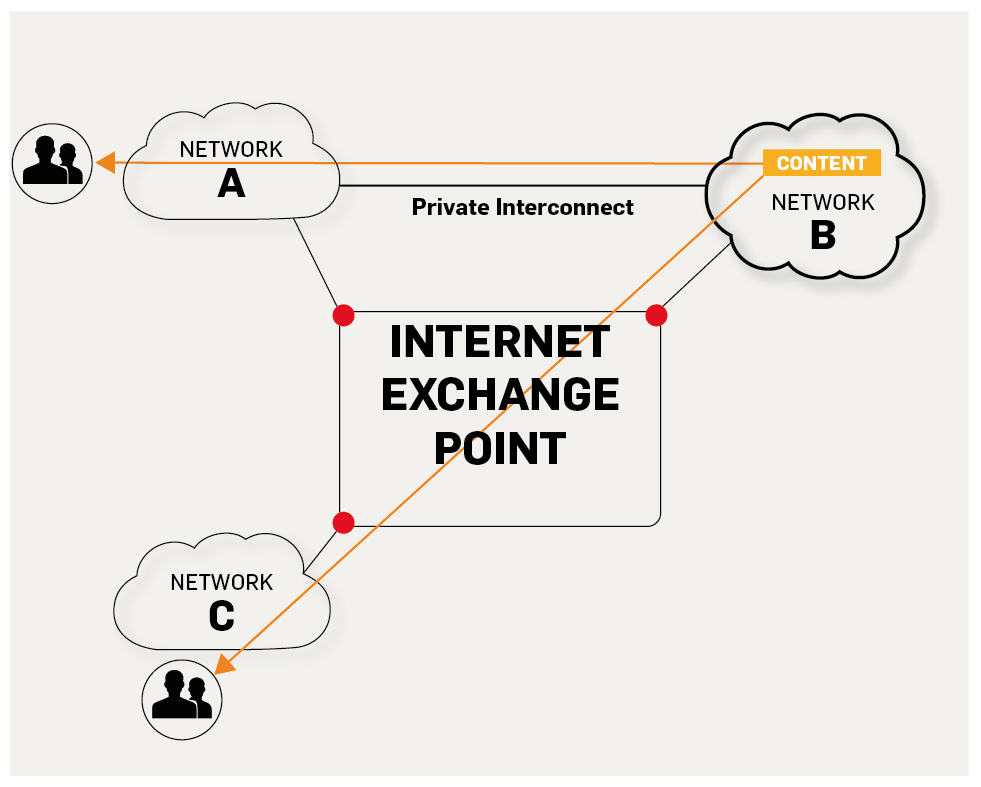
|
||||
|
||||
<p style="text-align:center;font-size:13px;color:gray">https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive</p>
|
||||
|
||||
6. **RFC(Request For Comments)** :意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
|
||||
7. **广域网 WAN(Wide Area Network)** :任务是通过长距离运送主机发送的数据。
|
||||
6. **RFC(Request For Comments)**:意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
|
||||
7. **广域网 WAN(Wide Area Network)**:任务是通过长距离运送主机发送的数据。
|
||||
8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
|
||||
9. **局域网 LAN(Local Area Network)** : 学校或企业大多拥有多个互连的局域网。
|
||||
9. **局域网 LAN(Local Area Network)**:学校或企业大多拥有多个互连的局域网。
|
||||
|
||||
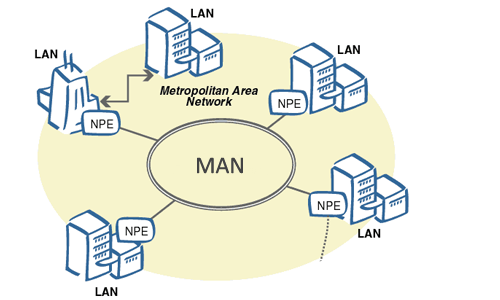
|
||||
|
||||
<p style="text-align:center;font-size:13px;color:gray">http://conexionesmanwman.blogspot.com/</p>
|
||||
|
||||
10. **个人区域网 PAN(Personal Area Network)** :在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
|
||||
10. **个人区域网 PAN(Personal Area Network)**:在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
|
||||
|
||||
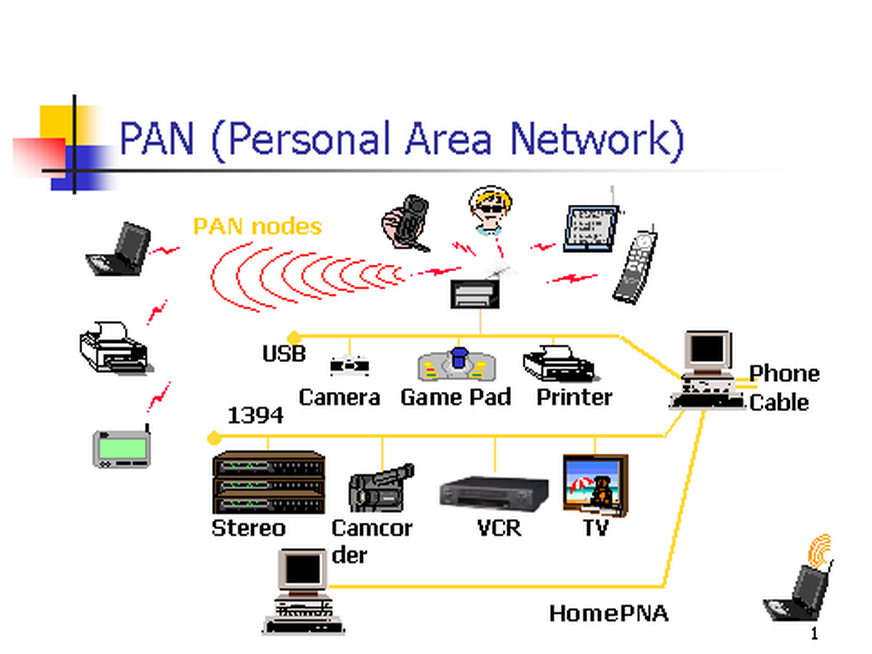
|
||||
|
||||
<p style="text-align:center;font-size:13px;color:gray">https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/</p>
|
||||
|
||||
12. **分组(packet )** :因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
|
||||
13. **存储转发(store and forward )** :路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
|
||||
12. **分组(packet )**:因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
|
||||
13. **存储转发(store and forward )**:路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
|
||||
|
||||
|
||||
|
||||
14. **带宽(bandwidth)** :在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
|
||||
15. **吞吐量(throughput )** :表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
|
||||
14. **带宽(bandwidth)**:在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
|
||||
15. **吞吐量(throughput )**:表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
|
||||
|
||||
### 1.2. 重要知识点总结
|
||||
|
||||
|
|
@ -75,10 +75,10 @@ tag:
|
|||
### 2.1. 基本术语
|
||||
|
||||
1. **数据(data)** :运送消息的实体。
|
||||
2. **信号(signal)** :数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
|
||||
3. **码元( code)** :在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
|
||||
2. **信号(signal)**:数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
|
||||
3. **码元( code)**:在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
|
||||
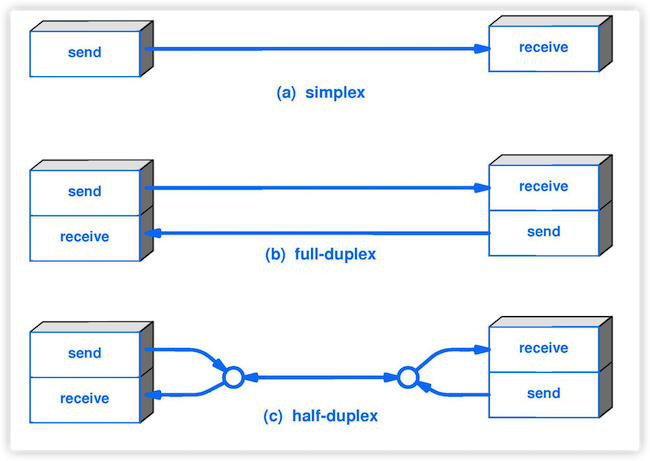
4. **单工(simplex )** : 只能有一个方向的通信而没有反方向的交互。
|
||||
5. **半双工(half duplex )** :通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
|
||||
5. **半双工(half duplex )**:通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
|
||||
6. **全双工(full duplex)** : 通信的双方可以同时发送和接收信息。
|
||||
|
||||
|
||||
|
|
@ -88,19 +88,19 @@ tag:
|
|||
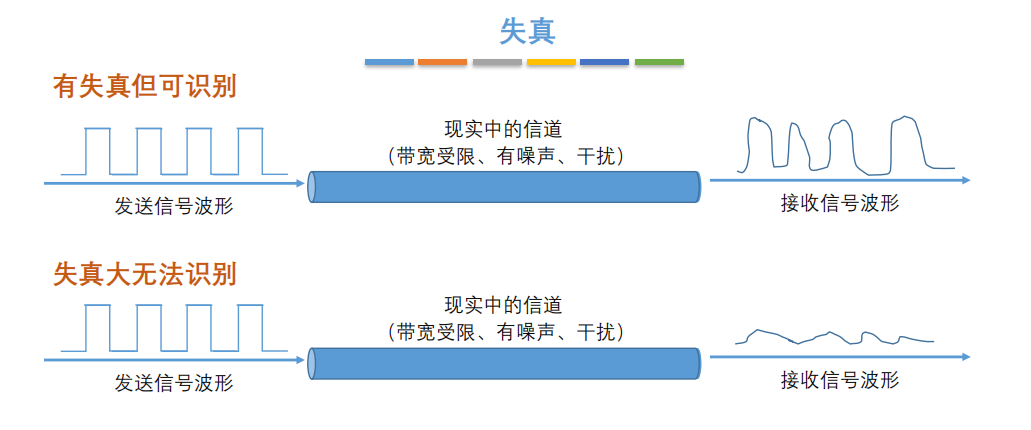
|
||||
|
||||
8. **奈氏准则** : 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
|
||||
9. **香农定理** :在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
|
||||
9. **香农定理**:在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
|
||||
10. **基带信号(baseband signal)** : 来自信源的信号。指没有经过调制的数字信号或模拟信号。
|
||||
11. **带通(频带)信号(bandpass signal)** :把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
|
||||
11. **带通(频带)信号(bandpass signal)**:把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
|
||||
12. **调制(modulation )** : 对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
|
||||
13. **信噪比(signal-to-noise ratio )** : 指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
|
||||
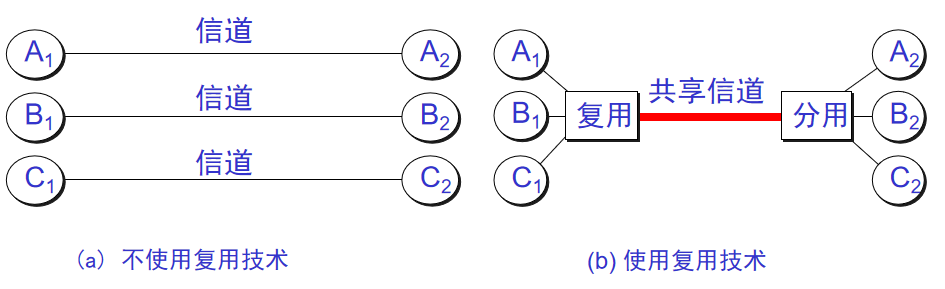
14. **信道复用(channel multiplexing )** :指多个用户共享同一个信道。(并不一定是同时)。
|
||||
14. **信道复用(channel multiplexing )**:指多个用户共享同一个信道。(并不一定是同时)。
|
||||
|
||||
|
||||
|
||||
15. **比特率(bit rate )** :单位时间(每秒)内传送的比特数。
|
||||
16. **波特率(baud rate)** :单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
|
||||
17. **复用(multiplexing)** :共享信道的方法。
|
||||
18. **ADSL(Asymmetric Digital Subscriber Line )** :非对称数字用户线。
|
||||
15. **比特率(bit rate )**:单位时间(每秒)内传送的比特数。
|
||||
16. **波特率(baud rate)**:单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
|
||||
17. **复用(multiplexing)**:共享信道的方法。
|
||||
18. **ADSL(Asymmetric Digital Subscriber Line )**:非对称数字用户线。
|
||||
19. **光纤同轴混合网(HFC 网)** :在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
|
||||
|
||||
### 2.2. 重要知识点总结
|
||||
|
|
@ -125,11 +125,11 @@ tag:
|
|||
|
||||
#### 2.3.2. 几种常用的信道复用技术
|
||||
|
||||
1. **频分复用(FDM)** :所有用户在同样的时间占用不同的带宽资源。
|
||||
2. **时分复用(TDM)** :所有用户在不同的时间占用同样的频带宽度(分时不分频)。
|
||||
3. **统计时分复用 (Statistic TDM)** :改进的时分复用,能够明显提高信道的利用率。
|
||||
4. **码分复用(CDM)** : 用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
|
||||
5. **波分复用( WDM)** :波分复用就是光的频分复用。
|
||||
1. **频分复用(FDM)**:所有用户在同样的时间占用不同的带宽资源。
|
||||
2. **时分复用(TDM)**:所有用户在不同的时间占用同样的频带宽度(分时不分频)。
|
||||
3. **统计时分复用 (Statistic TDM)**:改进的时分复用,能够明显提高信道的利用率。
|
||||
4. **码分复用(CDM)**:用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
|
||||
5. **波分复用( WDM)**:波分复用就是光的频分复用。
|
||||
|
||||
#### 2.3.3. 几种常用的宽带接入技术,主要是 ADSL 和 FTTx
|
||||
|
||||
|
|
@ -141,20 +141,20 @@ tag:
|
|||
|
||||
### 3.1. 基本术语
|
||||
|
||||
1. **链路(link)** :一个结点到相邻结点的一段物理链路。
|
||||
2. **数据链路(data link)** :把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
|
||||
3. **循环冗余检验 CRC(Cyclic Redundancy Check)** :为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
|
||||
4. **帧(frame)** :一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
|
||||
5. **MTU(Maximum Transfer Uint )** :最大传送单元。帧的数据部分的的长度上限。
|
||||
6. **误码率 BER(Bit Error Rate )** :在一段时间内,传输错误的比特占所传输比特总数的比率。
|
||||
7. **PPP(Point-to-Point Protocol )** :点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
|
||||
1. **链路(link)**:一个结点到相邻结点的一段物理链路。
|
||||
2. **数据链路(data link)**:把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
|
||||
3. **循环冗余检验 CRC(Cyclic Redundancy Check)**:为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
|
||||
4. **帧(frame)**:一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
|
||||
5. **MTU(Maximum Transfer Uint )**:最大传送单元。帧的数据部分的的长度上限。
|
||||
6. **误码率 BER(Bit Error Rate )**:在一段时间内,传输错误的比特占所传输比特总数的比率。
|
||||
7. **PPP(Point-to-Point Protocol )**:点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
|
||||
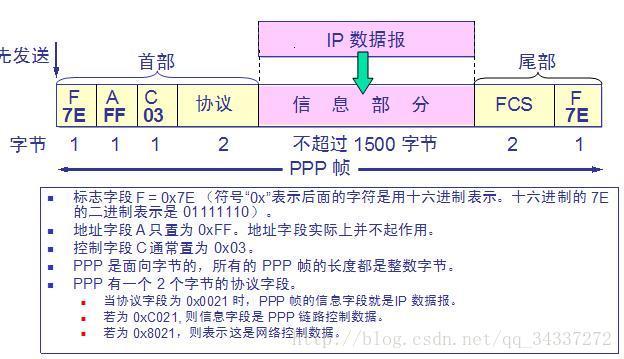
|
||||
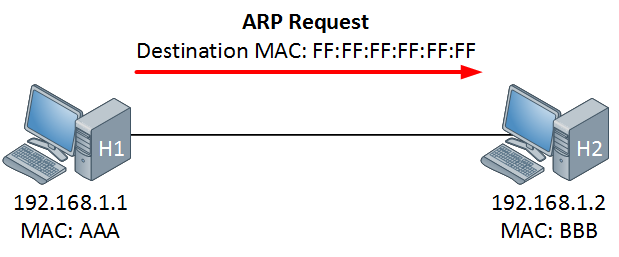
8. **MAC 地址(Media Access Control 或者 Medium Access Control)** :意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
|
||||
8. **MAC 地址(Media Access Control 或者 Medium Access Control)**:意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
|
||||
|
||||
|
||||
|
||||
9. **网桥(bridge)** :一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
|
||||
10. **交换机(switch )** :广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
|
||||
9. **网桥(bridge)**:一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
|
||||
10. **交换机(switch )**:广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
|
||||
|
||||
### 3.2. 重要知识点总结
|
||||
|
||||
|
|
@ -187,11 +187,11 @@ tag:
|
|||
1. **虚电路(Virtual Circuit)** : 在两个终端设备的逻辑或物理端口之间,通过建立的双向的透明传输通道。虚电路表示这只是一条逻辑上的连接,分组都沿着这条逻辑连接按照存储转发方式传送,而并不是真正建立了一条物理连接。
|
||||
2. **IP(Internet Protocol )** : 网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一,是 TCP/IP 体系结构网际层的核心。配套的有 ARP,RARP,ICMP,IGMP。
|
||||
3. **ARP(Address Resolution Protocol)** : 地址解析协议。地址解析协议 ARP 把 IP 地址解析为硬件地址。
|
||||
4. **ICMP(Internet Control Message Protocol )** :网际控制报文协议 (ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
|
||||
5. **子网掩码(subnet mask )** :它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
|
||||
4. **ICMP(Internet Control Message Protocol )**:网际控制报文协议 (ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
|
||||
5. **子网掩码(subnet mask )**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
|
||||
6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
|
||||
7. **默认路由(default route)** :当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
|
||||
8. **路由选择算法(Virtual Circuit)** :路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
|
||||
7. **默认路由(default route)**:当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
|
||||
8. **路由选择算法(Virtual Circuit)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
|
||||
|
||||
### 4.2. 重要知识点总结
|
||||
|
||||
|
|
@ -212,18 +212,18 @@ tag:
|
|||
|
||||
### 5.1. 基本术语
|
||||
|
||||
1. **进程(process)** :指计算机中正在运行的程序实体。
|
||||
2. **应用进程互相通信** :一台主机的进程和另一台主机中的一个进程交换数据的过程(另外注意通信真正的端点不是主机而是主机中的进程,也就是说端到端的通信是应用进程之间的通信)。
|
||||
3. **传输层的复用与分用** :复用指发送方不同的进程都可以通过同一个运输层协议传送数据。分用指接收方的运输层在剥去报文的首部后能把这些数据正确的交付到目的应用进程。
|
||||
4. **TCP(Transmission Control Protocol)** :传输控制协议。
|
||||
5. **UDP(User Datagram Protocol)** :用户数据报协议。
|
||||
1. **进程(process)**:指计算机中正在运行的程序实体。
|
||||
2. **应用进程互相通信**:一台主机的进程和另一台主机中的一个进程交换数据的过程(另外注意通信真正的端点不是主机而是主机中的进程,也就是说端到端的通信是应用进程之间的通信)。
|
||||
3. **传输层的复用与分用**:复用指发送方不同的进程都可以通过同一个运输层协议传送数据。分用指接收方的运输层在剥去报文的首部后能把这些数据正确的交付到目的应用进程。
|
||||
4. **TCP(Transmission Control Protocol)**:传输控制协议。
|
||||
5. **UDP(User Datagram Protocol)**:用户数据报协议。
|
||||
|
||||
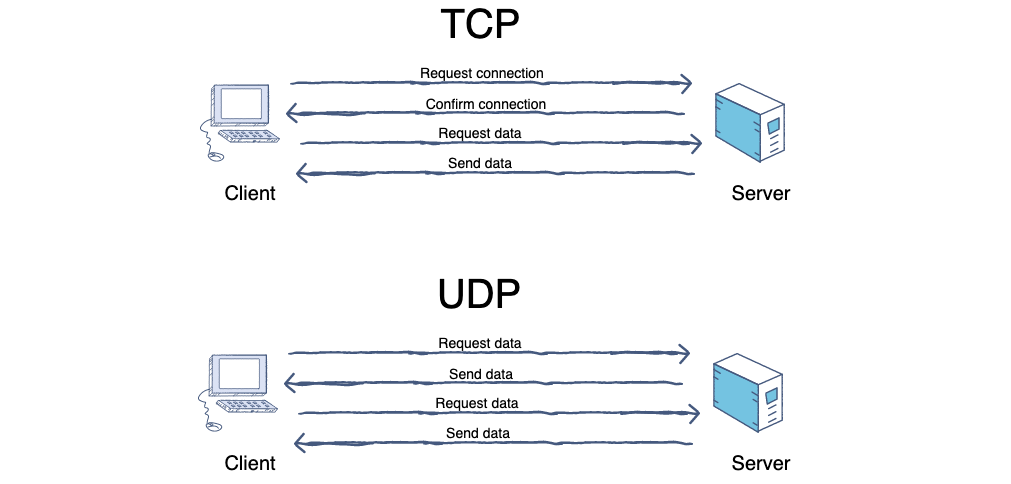
|
||||
|
||||
6. **端口(port)** :端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
|
||||
7. **停止等待协议(stop-and-wait)** :指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
|
||||
6. **端口(port)**:端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
|
||||
7. **停止等待协议(stop-and-wait)**:指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
|
||||
8. **流量控制** : 就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。
|
||||
9. **拥塞控制** :防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
|
||||
9. **拥塞控制**:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
|
||||
|
||||
### 5.2. 重要知识点总结
|
||||
|
||||
|
|
@ -265,31 +265,31 @@ tag:
|
|||
|
||||
### 6.1. 基本术语
|
||||
|
||||
1. **域名系统(DNS)** :域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
|
||||
1. **域名系统(DNS)**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
|
||||
|
||||
|
||||
|
||||
<p style="text-align:right;font-size:12px">https://www.seobility.net/en/wiki/HTTP_headers</p>
|
||||
|
||||
2. **文件传输协议(FTP)** :FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
|
||||
2. **文件传输协议(FTP)**:FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
|
||||
|
||||
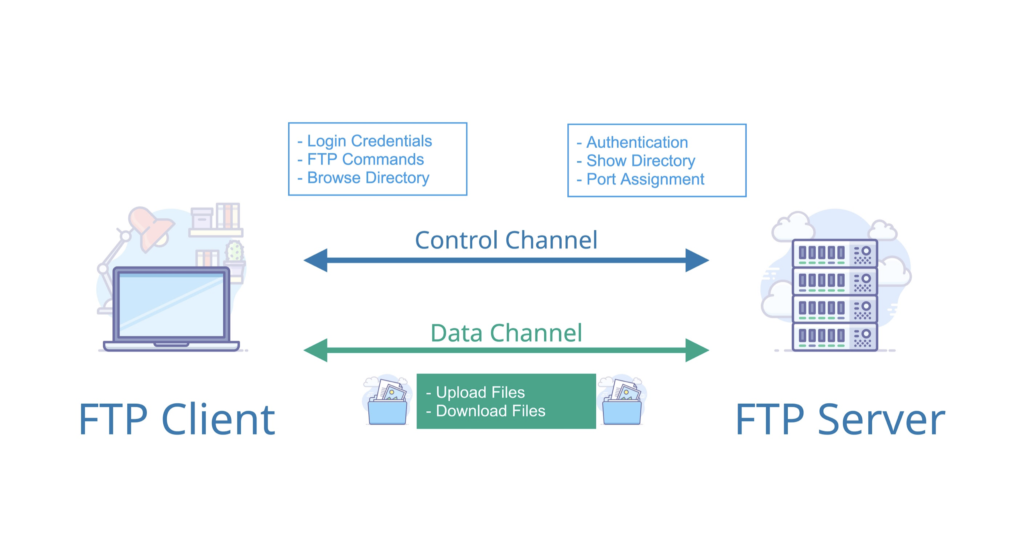
|
||||
|
||||
3. **简单文件传输协议(TFTP)** :TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
|
||||
4. **远程终端协议(TELNET)** :Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
|
||||
5. **万维网(WWW)** :WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
|
||||
3. **简单文件传输协议(TFTP)**:TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
|
||||
4. **远程终端协议(TELNET)**:Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
|
||||
5. **万维网(WWW)**:WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
|
||||
6. **万维网的大致工作工程:**
|
||||
|
||||
|
||||
|
||||
7. **统一资源定位符(URL)** :统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
|
||||
8. **超文本传输协议(HTTP)** :超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
|
||||
7. **统一资源定位符(URL)**:统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
|
||||
8. **超文本传输协议(HTTP)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
|
||||
|
||||
HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
|
||||
|
||||
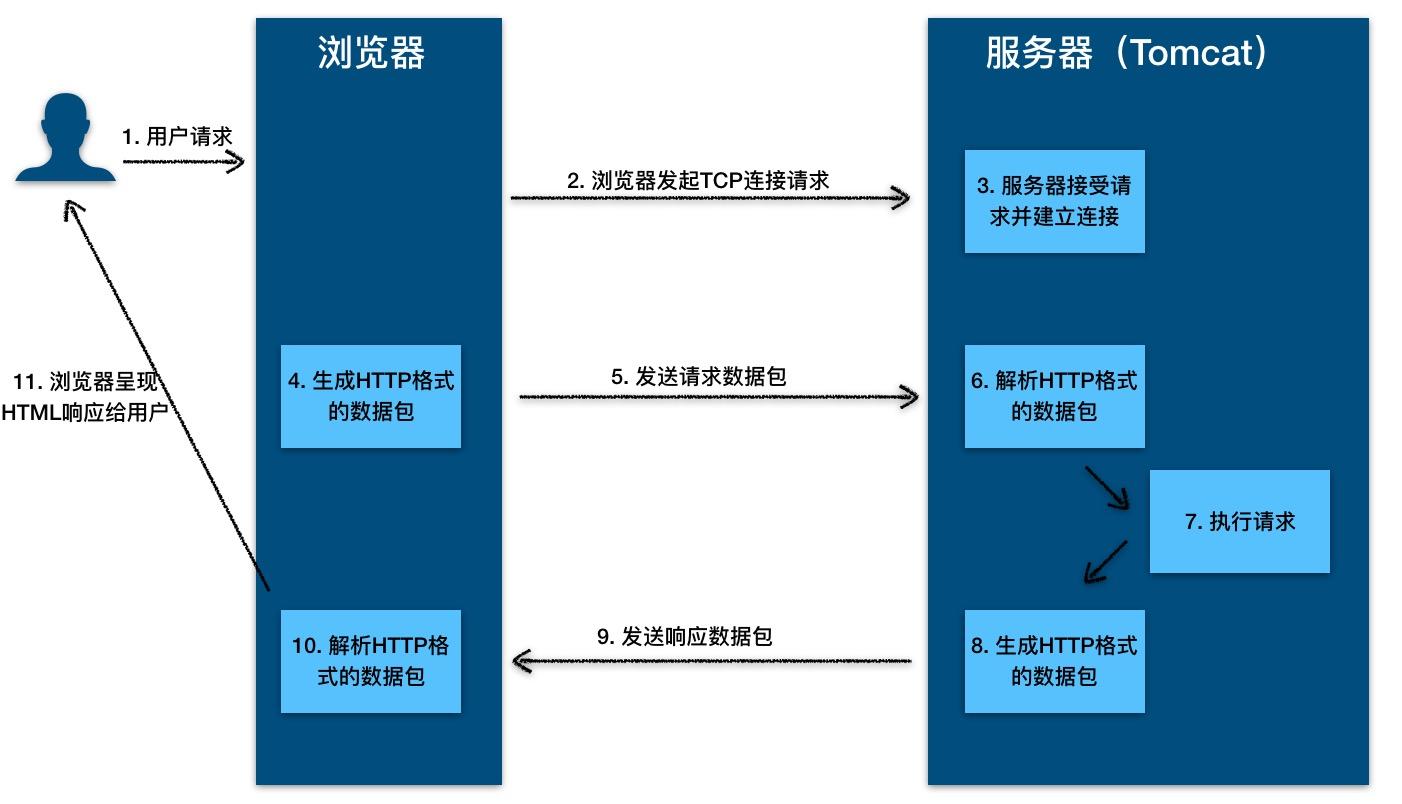
|
||||
|
||||
10. **代理服务器(Proxy Server)** : 代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
|
||||
10. **代理服务器(Proxy Server)**:代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
|
||||
11. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
|
||||
|
||||
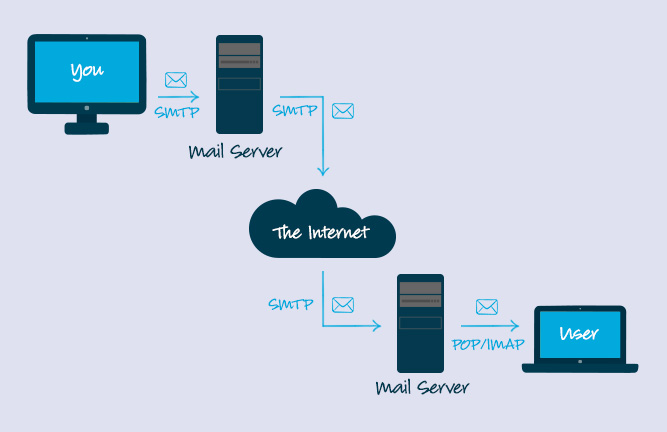
|
||||
|
|
@ -300,9 +300,9 @@ HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格
|
|||
|
||||

|
||||
|
||||
12. **垂直搜索引擎** :垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
|
||||
12. **垂直搜索引擎**:垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
|
||||
13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
|
||||
14. **目录索引** :目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
|
||||
14. **目录索引**:目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
|
||||
|
||||
### 6.2. 重要知识点总结
|
||||
|
||||
|
|
|
|||
|
|
@ -15,10 +15,10 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||
|
||||
### 2xx Success(成功状态码)
|
||||
|
||||
- **200 OK** :请求被成功处理。比如我们发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
|
||||
- **201 Created** :请求被成功处理并且在服务端创建了一个新的资源。比如我们通过 POST 请求创建一个新的用户。
|
||||
- **202 Accepted** :服务端已经接收到了请求,但是还未处理。
|
||||
- **204 No Content** : 服务端已经成功处理了请求,但是没有返回任何内容。
|
||||
- **200 OK**:请求被成功处理。比如我们发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
|
||||
- **201 Created**:请求被成功处理并且在服务端创建了一个新的资源。比如我们通过 POST 请求创建一个新的用户。
|
||||
- **202 Accepted**:服务端已经接收到了请求,但是还未处理。
|
||||
- **204 No Content**:服务端已经成功处理了请求,但是没有返回任何内容。
|
||||
|
||||
这里格外提一下 204 状态码,平时学习/工作中见到的次数并不多。
|
||||
|
||||
|
|
@ -46,21 +46,21 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||
|
||||
### 3xx Redirection(重定向状态码)
|
||||
|
||||
- **301 Moved Permanently** : 资源被永久重定向了。比如你的网站的网址更换了。
|
||||
- **302 Found** :资源被临时重定向了。比如你的网站的某些资源被暂时转移到另外一个网址。
|
||||
- **301 Moved Permanently**:资源被永久重定向了。比如你的网站的网址更换了。
|
||||
- **302 Found**:资源被临时重定向了。比如你的网站的某些资源被暂时转移到另外一个网址。
|
||||
|
||||
### 4xx Client Error(客户端错误状态码)
|
||||
|
||||
- **400 Bad Request** : 发送的 HTTP 请求存在问题。比如请求参数不合法、请求方法错误。
|
||||
- **401 Unauthorized** : 未认证却请求需要认证之后才能访问的资源。
|
||||
- **403 Forbidden** :直接拒绝 HTTP 请求,不处理。一般用来针对非法请求。
|
||||
- **404 Not Found** : 你请求的资源未在服务端找到。比如你请求某个用户的信息,服务端并没有找到指定的用户。
|
||||
- **409 Conflict** : 表示请求的资源与服务端当前的状态存在冲突,请求无法被处理。
|
||||
- **400 Bad Request**:发送的 HTTP 请求存在问题。比如请求参数不合法、请求方法错误。
|
||||
- **401 Unauthorized**:未认证却请求需要认证之后才能访问的资源。
|
||||
- **403 Forbidden**:直接拒绝 HTTP 请求,不处理。一般用来针对非法请求。
|
||||
- **404 Not Found**:你请求的资源未在服务端找到。比如你请求某个用户的信息,服务端并没有找到指定的用户。
|
||||
- **409 Conflict**:表示请求的资源与服务端当前的状态存在冲突,请求无法被处理。
|
||||
|
||||
### 5xx Server Error(服务端错误状态码)
|
||||
|
||||
- **500 Internal Server Error** : 服务端出问题了(通常是服务端出 Bug 了)。比如你服务端处理请求的时候突然抛出异常,但是异常并未在服务端被正确处理。
|
||||
- **502 Bad Gateway** :我们的网关将请求转发到服务端,但是服务端返回的却是一个错误的响应。
|
||||
- **500 Internal Server Error**:服务端出问题了(通常是服务端出 Bug 了)。比如你服务端处理请求的时候突然抛出异常,但是异常并未在服务端被正确处理。
|
||||
- **502 Bad Gateway**:我们的网关将请求转发到服务端,但是服务端返回的却是一个错误的响应。
|
||||
|
||||
### 参考
|
||||
|
||||
|
|
|
|||
|
|
@ -135,6 +135,6 @@ SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐
|
|||
|
||||
## 总结
|
||||
|
||||
- **端口号** :HTTP 默认是 80,HTTPS 默认是 443。
|
||||
- **URL 前缀** :HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
|
||||
- **安全性和资源消耗** : HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
|
||||
- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
|
||||
- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
|
||||
- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
|
||||
|
|
|
|||
|
|
@ -53,4 +53,4 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
|
|||
3. WAN 的 ISP 变更接口地址时,无需通告 LAN 内主机。
|
||||
4. LAN 主机对 WAN 不可见,不可直接寻址,可以保证一定程度的安全性。
|
||||
|
||||
然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的。**这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
|
||||
然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的。**这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
|
||||
|
|
|
|||
|
|
@ -77,7 +77,7 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
|
|||
|
||||
### SYN Flood 的常见形式有哪些?
|
||||
|
||||
**恶意用户可通过三种不同方式发起 SYN Flood 攻击** :
|
||||
**恶意用户可通过三种不同方式发起 SYN Flood 攻击**:
|
||||
|
||||
1. **直接攻击:**不伪造 IP 地址的 SYN 洪水攻击称为直接攻击。在此类攻击中,攻击者完全不屏蔽其 IP 地址。由于攻击者使用具有真实 IP 地址的单一源设备发起攻击,因此很容易发现并清理攻击者。为使目标机器呈现半开状态,黑客将阻止个人机器对服务器的 SYN-ACK 数据包做出响应。为此,通常采用以下两种方式实现:部署防火墙规则,阻止除 SYN 数据包以外的各类传出数据包;或者,对传入的所有 SYN-ACK 数据包进行过滤,防止其到达恶意用户机器。实际上,这种方法很少使用(即便使用过也不多见),因为此类攻击相当容易缓解 – 只需阻止每个恶意系统的 IP 地址。哪怕攻击者使用僵尸网络(如 [Mirai 僵尸网络](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/)),通常也不会刻意屏蔽受感染设备的 IP。
|
||||
2. **欺骗攻击:**恶意用户还可以伪造其发送的各个 SYN 数据包的 IP 地址,以便阻止缓解措施并加大身份暴露难度。虽然数据包可能经过伪装,但还是可以通过这些数据包追根溯源。此类检测工作很难开展,但并非不可实现;特别是,如果 Internet 服务提供商 (ISP) 愿意提供帮助,则更容易实现。
|
||||
|
|
@ -140,8 +140,8 @@ HTTP 洪水攻击是“第 7 层”DDoS 攻击的一种。第 7 层是 OSI 模
|
|||
|
||||
HTTP 洪水攻击有两种:
|
||||
|
||||
- **HTTP GET 攻击** :在这种攻击形式下,多台计算机或其他设备相互协调,向目标服务器发送对图像、文件或其他资产的多个请求。当目标被传入的请求和响应所淹没时,来自正常流量源的其他请求将被拒绝服务。
|
||||
- **HTTP POST 攻击** : 一般而言,在网站上提交表单时,服务器必须处理传入的请求并将数据推送到持久层(通常是数据库)。与发送 POST 请求所需的处理能力和带宽相比,处理表单数据和运行必要数据库命令的过程相对密集。这种攻击利用相对资源消耗的差异,直接向目标服务器发送许多 POST 请求,直到目标服务器的容量饱和并拒绝服务为止。
|
||||
- **HTTP GET 攻击**:在这种攻击形式下,多台计算机或其他设备相互协调,向目标服务器发送对图像、文件或其他资产的多个请求。当目标被传入的请求和响应所淹没时,来自正常流量源的其他请求将被拒绝服务。
|
||||
- **HTTP POST 攻击**:一般而言,在网站上提交表单时,服务器必须处理传入的请求并将数据推送到持久层(通常是数据库)。与发送 POST 请求所需的处理能力和带宽相比,处理表单数据和运行必要数据库命令的过程相对密集。这种攻击利用相对资源消耗的差异,直接向目标服务器发送许多 POST 请求,直到目标服务器的容量饱和并拒绝服务为止。
|
||||
|
||||
### 如何防护 HTTP Flood?
|
||||
|
||||
|
|
@ -330,7 +330,7 @@ DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实
|
|||
|
||||
之前几种都是国外的,我们国内自行研究了国密 **SM1 **和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可
|
||||
|
||||
**总结** :
|
||||
**总结**:
|
||||
|
||||

|
||||
|
||||
|
|
@ -369,7 +369,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
|
|||
|
||||
国密算法**SM3**。加密强度和 SHA-256 想不多。主要是收到国家的支持。
|
||||
|
||||
**总结** :
|
||||
**总结**:
|
||||
|
||||
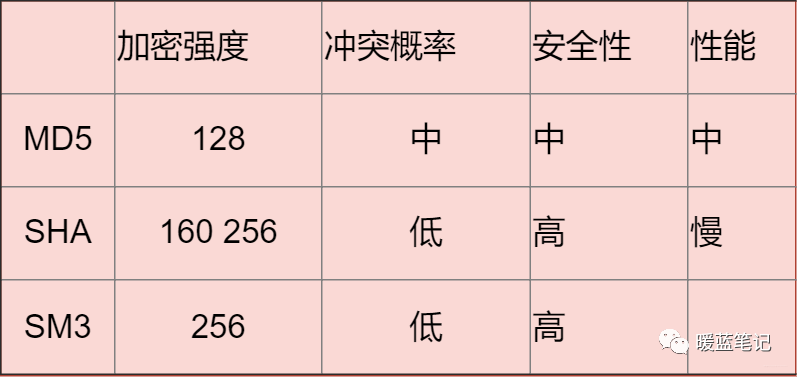
|
||||
|
||||
|
|
|
|||
|
|
@ -55,26 +55,26 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
|||
|
||||
应用层协议定义了网络通信规则,对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如支持 Web 应用的 HTTP 协议,支持电子邮件的 SMTP 协议等等。
|
||||
|
||||
**应用层常见协议** :
|
||||
**应用层常见协议**:
|
||||
|
||||
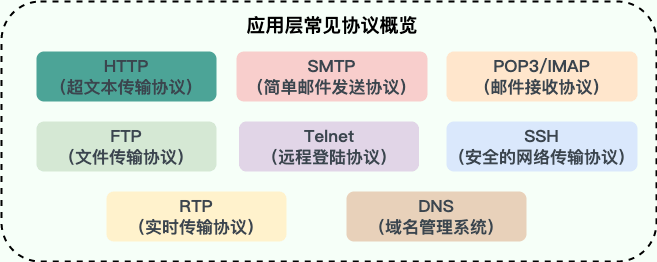
|
||||
|
||||
- **HTTP(Hypertext Transfer Protocol,超文本传输协议)** :基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)** :基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
|
||||
- **POP3/IMAP(邮件接收协议)** :基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
|
||||
- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
|
||||
- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
|
||||
- **FTP(File Transfer Protocol,文件传输协议)** : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
|
||||
- **Telnet(远程登陆协议)** :基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
|
||||
- **SSH(Secure Shell Protocol,安全的网络传输协议)** :基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
|
||||
- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
|
||||
- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
|
||||
- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
|
||||
- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
|
||||
|
||||
关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](https://javaguide.cn/cs-basics/network/application-layer-protocol.html) 这篇文章。
|
||||
关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](./application-layer-protocol.md) 这篇文章。
|
||||
|
||||
### 传输层(Transport layer)
|
||||
|
||||
**传输层的主要任务就是负责向两台终端设备进程之间的通信提供通用的数据传输服务。** 应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。
|
||||
|
||||
**传输层常见协议** :
|
||||
**传输层常见协议**:
|
||||
|
||||

|
||||
|
||||
|
|
@ -85,7 +85,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
|||
|
||||
**网络层负责为分组交换网上的不同主机提供通信服务。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 IP 协议,因此分组也叫 IP 数据报,简称数据报。
|
||||
|
||||
⚠️ 注意 :**不要把运输层的“用户数据报 UDP”和网络层的“IP 数据报”弄混**。
|
||||
⚠️ 注意:**不要把运输层的“用户数据报 UDP”和网络层的“IP 数据报”弄混**。
|
||||
|
||||
**网络层的还有一个任务就是选择合适的路由,使源主机运输层所传下来的分组,能通过网络层中的路由器找到目的主机。**
|
||||
|
||||
|
|
@ -93,17 +93,17 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
|||
|
||||
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Internet Protocol)和许多路由选择协议,因此互联网的网络层也叫做 **网际层** 或 **IP 层**。
|
||||
|
||||
**网络层常见协议** :
|
||||
**网络层常见协议**:
|
||||
|
||||

|
||||
|
||||
- **IP(Internet Protocol,网际协议)** :TCP/IP 协议中最重要的协议之一,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
|
||||
- **ARP(Address Resolution Protocol,地址解析协议)** :ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
|
||||
- **ICMP(Internet Control Message Protocol,互联网控制报文协议)** :一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
|
||||
- **NAT(Network Address Translation,网络地址转换协议)** :NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
|
||||
- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
|
||||
- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
|
||||
- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
|
||||
- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
|
||||
- **OSPF(Open Shortest Path First,开放式最短路径优先)** ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
|
||||
- **RIP(Routing Information Protocol,路由信息协议)** :一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
|
||||
- **BGP(Border Gateway Protocol,边界网关协议)** :一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
|
||||
- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
|
||||
- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
|
||||
|
||||
### 网络接口层(Network interface layer)
|
||||
|
||||
|
|
@ -180,8 +180,8 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
|||
好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
|
||||
|
||||
1. **各层之间相互独立**:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)**。这个和我们对开发时系统进行分层是一个道理。**
|
||||
2. **提高了整体灵活性** :每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
|
||||
3. **大问题化小** : 分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
|
||||
2. **提高了整体灵活性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
|
||||
3. **大问题化小**:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
|
||||
|
||||
我想到了计算机世界非常非常有名的一句话,这里分享一下:
|
||||
|
||||
|
|
|
|||
|
|
@ -40,7 +40,7 @@ tag:
|
|||
|
||||

|
||||
|
||||
关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](https://javaguide.cn/cs-basics/network/osi-and-tcp-ip-model.html) 这篇文章。
|
||||
关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](./osi-and-tcp-ip-model.md) 这篇文章。
|
||||
|
||||
#### 为什么网络要分层?
|
||||
|
||||
|
|
@ -55,8 +55,8 @@ tag:
|
|||
好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
|
||||
|
||||
1. **各层之间相互独立**:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)**。这个和我们对开发时系统进行分层是一个道理。**
|
||||
2. **提高了整体灵活性** :每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
|
||||
3. **大问题化小** : 分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
|
||||
2. **提高了整体灵活性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
|
||||
3. **大问题化小**:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
|
||||
|
||||
我想到了计算机世界非常非常有名的一句话,这里分享一下:
|
||||
|
||||
|
|
@ -68,12 +68,12 @@ tag:
|
|||
|
||||

|
||||
|
||||
- **HTTP(Hypertext Transfer Protocol,超文本传输协议)** :基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)** :基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
|
||||
- **POP3/IMAP(邮件接收协议)** :基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
|
||||
- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
|
||||
- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
|
||||
- **FTP(File Transfer Protocol,文件传输协议)** : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
|
||||
- **Telnet(远程登陆协议)** :基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
|
||||
- **SSH(Secure Shell Protocol,安全的网络传输协议)** :基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
|
||||
- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
|
||||
- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
|
||||
- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
|
||||
- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
|
||||
|
||||
|
|
@ -90,13 +90,13 @@ tag:
|
|||
|
||||

|
||||
|
||||
- **IP(Internet Protocol,网际协议)** : TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
|
||||
- **ARP(Address Resolution Protocol,地址解析协议)** :ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
|
||||
- **ICMP(Internet Control Message Protocol,互联网控制报文协议)** :一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
|
||||
- **NAT(Network Address Translation,网络地址转换协议)** :NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
|
||||
- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
|
||||
- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
|
||||
- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
|
||||
- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
|
||||
- **OSPF(Open Shortest Path First,开放式最短路径优先)** ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
|
||||
- **RIP(Routing Information Protocol,路由信息协议)** :一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
|
||||
- **BGP(Border Gateway Protocol,边界网关协议)** :一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
|
||||
- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
|
||||
- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
|
||||
|
||||
## HTTP
|
||||
|
||||
|
|
@ -173,10 +173,10 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||
|
||||

|
||||
|
||||
- **端口号** :HTTP 默认是 80,HTTPS 默认是 443。
|
||||
- **URL 前缀** :HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
|
||||
- **安全性和资源消耗** : HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
|
||||
- **SEO(搜索引擎优化)** :搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
|
||||
- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
|
||||
- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
|
||||
- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
|
||||
- **SEO(搜索引擎优化)**:搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
|
||||
|
||||
关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](./http-vs-https.md) 。
|
||||
|
||||
|
|
@ -187,7 +187,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||
- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。
|
||||
- **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
|
||||
- **缓存机制** : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
|
||||
- **带宽** :HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
|
||||
- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
|
||||
- **Host 头(Host Header)处理** :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
|
||||
|
||||
关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](./http1.0-vs-http1.1.md) 。
|
||||
|
|
@ -196,20 +196,20 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||
|
||||

|
||||
|
||||
- **IO 多路复用(Multiplexing)** :HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本)。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
|
||||
- **二进制帧(Binary Frames)** :HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
|
||||
- **头部压缩(Header Compression)** :HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,减少了网络开销。
|
||||
- **IO 多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本)。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
|
||||
- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
|
||||
- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,减少了网络开销。
|
||||
- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
|
||||
|
||||
### HTTP/2.0 和 HTTP/3.0 有什么区别?
|
||||
|
||||

|
||||
|
||||
- **传输协议** :HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
|
||||
- **连接建立** :HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
|
||||
- **队头阻塞** :HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
|
||||
- **错误恢复** :HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
|
||||
- **安全性** :HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
|
||||
- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
|
||||
- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
|
||||
- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
|
||||
- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
|
||||
- **安全性**:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
|
||||
|
||||
### HTTP 是不保存状态的协议, 如何保存用户状态?
|
||||
|
||||
|
|
@ -230,7 +230,7 @@ URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL
|
|||
|
||||
### Cookie 和 Session 有什么区别?
|
||||
|
||||
准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](https://javaguide.cn/system-design/security/basis-of-authority-certification.html) 这篇文章中找到详细的答案。
|
||||
准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](../../system-design/security/basis-of-authority-certification.md) 这篇文章中找到详细的答案。
|
||||
|
||||
## PING
|
||||
|
||||
|
|
@ -257,10 +257,10 @@ round-trip min/avg/max/stddev = 27.571/27.938/28.732/0.474 ms
|
|||
|
||||
PING 命令的输出结果通常包括以下几部分信息:
|
||||
|
||||
1. **ICMP Echo Request(请求报文)信息** :序列号、TTL(Time to Live)值。
|
||||
2. **目标主机的域名或 IP 地址** :输出结果的第一行。
|
||||
3. **往返时间(RTT,Round-Trip Time)** :从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
|
||||
4. **统计结果(Statistics)** :包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
|
||||
1. **ICMP Echo Request(请求报文)信息**:序列号、TTL(Time to Live)值。
|
||||
2. **目标主机的域名或 IP 地址**:输出结果的第一行。
|
||||
3. **往返时间(RTT,Round-Trip Time)**:从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
|
||||
4. **统计结果(Statistics)**:包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
|
||||
|
||||
如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题。如果往返时间(RTT)过高,则表明网络延迟过高。
|
||||
|
||||
|
|
@ -270,8 +270,8 @@ PING 基于网络层的 **ICMP(Internet Control Message Protocol,互联网
|
|||
|
||||
ICMP 报文中包含了类型字段,用于标识 ICMP 报文类型。ICMP 报文的类型有很多种,但大致可以分为两类:
|
||||
|
||||
- **查询报文类型** :向目标主机发送请求并期望得到响应。
|
||||
- **差错报文类型** :向源主机发送错误信息,用于报告网络中的错误情况。
|
||||
- **查询报文类型**:向目标主机发送请求并期望得到响应。
|
||||
- **差错报文类型**:向源主机发送错误信息,用于报告网络中的错误情况。
|
||||
|
||||
PING 用到的 ICMP Echo Request(类型为 8 ) 和 ICMP Echo Reply(类型为 0) 属于查询报文类型 。
|
||||
|
||||
|
|
|
|||
|
|
@ -11,13 +11,13 @@ tag:
|
|||
|
||||
### TCP 与 UDP 的区别(重要)
|
||||
|
||||
1. **是否面向连接** :UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。
|
||||
1. **是否面向连接**:UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。
|
||||
2. **是否是可靠传输**:远地主机在收到 UDP 报文后,不需要给出任何确认,并且不保证数据不丢失,不保证是否顺序到达。TCP 提供可靠的传输服务,TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制。通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达。
|
||||
3. **是否有状态** :这个和上面的“是否可靠传输”相对应。TCP 传输是有状态的,这个有状态说的是 TCP 会去记录自己发送消息的状态比如消息是否发送了、是否被接收了等等。为此 ,TCP 需要维持复杂的连接状态表。而 UDP 是无状态服务,简单来说就是不管发出去之后的事情了(**这很渣男!**)。
|
||||
4. **传输效率** :由于使用 TCP 进行传输的时候多了连接、确认、重传等机制,所以 TCP 的传输效率要比 UDP 低很多。
|
||||
5. **传输形式** : TCP 是面向字节流的,UDP 是面向报文的。
|
||||
6. **首部开销** :TCP 首部开销(20 ~ 60 字节)比 UDP 首部开销(8 字节)要大。
|
||||
7. **是否提供广播或多播服务** :TCP 只支持点对点通信,UDP 支持一对一、一对多、多对一、多对多;
|
||||
3. **是否有状态**:这个和上面的“是否可靠传输”相对应。TCP 传输是有状态的,这个有状态说的是 TCP 会去记录自己发送消息的状态比如消息是否发送了、是否被接收了等等。为此 ,TCP 需要维持复杂的连接状态表。而 UDP 是无状态服务,简单来说就是不管发出去之后的事情了(**这很渣男!**)。
|
||||
4. **传输效率**:由于使用 TCP 进行传输的时候多了连接、确认、重传等机制,所以 TCP 的传输效率要比 UDP 低很多。
|
||||
5. **传输形式**:TCP 是面向字节流的,UDP 是面向报文的。
|
||||
6. **首部开销**:TCP 首部开销(20 ~ 60 字节)比 UDP 首部开销(8 字节)要大。
|
||||
7. **是否提供广播或多播服务**:TCP 只支持点对点通信,UDP 支持一对一、一对多、多对一、多对多;
|
||||
8. ......
|
||||
|
||||
我把上面总结的内容通过表格形式展示出来了!确定不点个赞嘛?
|
||||
|
|
@ -34,7 +34,7 @@ tag:
|
|||
|
||||
### 什么时候选择 TCP,什么时候选 UDP?
|
||||
|
||||
- **UDP 一般用于即时通信**,比如: 语音、 视频 、直播等等。这些场景对传输数据的准确性要求不是特别高,比如你看视频即使少个一两帧,实际给人的感觉区别也不大。
|
||||
- **UDP 一般用于即时通信**,比如:语音、 视频、直播等等。这些场景对传输数据的准确性要求不是特别高,比如你看视频即使少个一两帧,实际给人的感觉区别也不大。
|
||||
- **TCP 用于对传输准确性要求特别高的场景**,比如文件传输、发送和接收邮件、远程登录等等。
|
||||
|
||||
### HTTP 基于 TCP 还是 UDP?
|
||||
|
|
@ -50,26 +50,26 @@ tag:
|
|||
|
||||
### 使用 TCP 的协议有哪些?使用 UDP 的协议有哪些?
|
||||
|
||||
**运行于 TCP 协议之上的协议** :
|
||||
**运行于 TCP 协议之上的协议**:
|
||||
|
||||
1. **HTTP 协议** :超文本传输协议(HTTP,HyperText Transfer Protocol)是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
2. **HTTPS 协议** :更安全的超文本传输协议(HTTPS,Hypertext Transfer Protocol Secure),身披 SSL 外衣的 HTTP 协议
|
||||
1. **HTTP 协议**:超文本传输协议(HTTP,HyperText Transfer Protocol)是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
2. **HTTPS 协议**:更安全的超文本传输协议(HTTPS,Hypertext Transfer Protocol Secure),身披 SSL 外衣的 HTTP 协议
|
||||
3. **FTP 协议**:文件传输协议 FTP(File Transfer Protocol)是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
|
||||
4. **SMTP 协议**:简单邮件传输协议(SMTP,Simple Mail Transfer Protocol)的缩写,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
|
||||
5. **POP3/IMAP 协议**: 两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
|
||||
5. **POP3/IMAP 协议**:两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
|
||||
6. **Telnet 协议**:用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
|
||||
7. **SSH 协议** : SSH( Secure Shell)是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH 建立在可靠的传输协议 TCP 之上。
|
||||
8. ......
|
||||
|
||||
**运行于 UDP 协议之上的协议** :
|
||||
**运行于 UDP 协议之上的协议**:
|
||||
|
||||
1. **DHCP 协议**:动态主机配置协议,动态配置 IP 地址
|
||||
2. **DNS** : **域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。** 我们可以将其理解为专为互联网设计的电话薄。实际上 DNS 同时支持 UDP 和 TCP 协议。
|
||||
2. **DNS**:**域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。** 我们可以将其理解为专为互联网设计的电话薄。实际上 DNS 同时支持 UDP 和 TCP 协议。
|
||||
3. ......
|
||||
|
||||
### TCP 三次握手和四次挥手(非常重要)
|
||||
|
||||
**相关面试题** :
|
||||
**相关面试题**:
|
||||
|
||||
- 为什么要三次握手?
|
||||
- 第 2 次握手传回了 ACK,为什么还要传回 SYN?
|
||||
|
|
@ -78,7 +78,7 @@ tag:
|
|||
- 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
|
||||
- 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
|
||||
|
||||
**参考答案** :[TCP 三次握手和四次挥手(传输层)](./tcp-connection-and-disconnection.md) 。
|
||||
**参考答案**:[TCP 三次握手和四次挥手(传输层)](./tcp-connection-and-disconnection.md) 。
|
||||
|
||||
### TCP 如何保证传输的可靠性?(重要)
|
||||
|
||||
|
|
@ -122,11 +122,11 @@ IP 地址过滤是一种简单的网络安全措施,实际应用中一般会
|
|||
|
||||
除了更大的地址空间之外,IPv6 的优势还包括:
|
||||
|
||||
- **无状态地址自动配置(Stateless Address Autoconfiguration,简称 SLAAC)** :主机可以直接通过根据接口标识和网络前缀生成全局唯一的 IPv6 地址,而无需依赖 DHCP(Dynamic Host Configuration Protocol)服务器,简化了网络配置和管理。
|
||||
- **NAT(Network Address Translation,网络地址转换) 成为可选项** :IPv6 地址资源充足,可以给全球每个设备一个独立的地址。
|
||||
- **对标头结构进行了改进** :IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
|
||||
- **可选的扩展头** :允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
|
||||
- **ICMPv6(Internet Control Message Protocol for IPv6)** :IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
|
||||
- **无状态地址自动配置(Stateless Address Autoconfiguration,简称 SLAAC)**:主机可以直接通过根据接口标识和网络前缀生成全局唯一的 IPv6 地址,而无需依赖 DHCP(Dynamic Host Configuration Protocol)服务器,简化了网络配置和管理。
|
||||
- **NAT(Network Address Translation,网络地址转换) 成为可选项**:IPv6 地址资源充足,可以给全球每个设备一个独立的地址。
|
||||
- **对标头结构进行了改进**:IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
|
||||
- **可选的扩展头**:允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
|
||||
- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
|
||||
- ......
|
||||
|
||||
### NAT 的作用是什么?
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ tag:
|
|||
|
||||
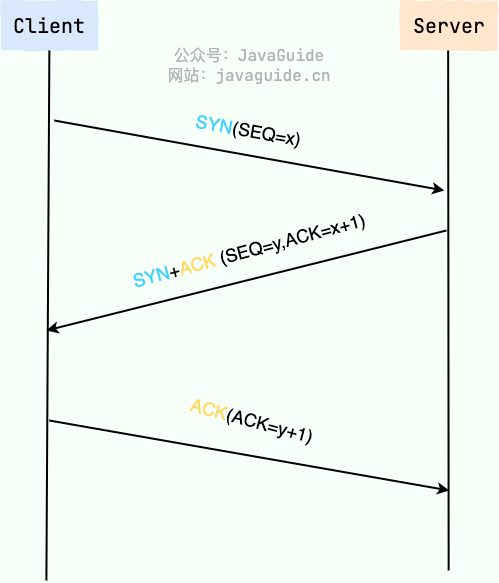
|
||||
|
||||
建立一个 TCP 连接需要“三次握手”,缺一不可 :
|
||||
建立一个 TCP 连接需要“三次握手”,缺一不可:
|
||||
|
||||
- **一次握手**:客户端发送带有 SYN(SEQ=x) 标志的数据包 -> 服务端,然后客户端进入 **SYN_SEND** 状态,等待服务器的确认;
|
||||
- **二次握手**:服务端发送带有 SYN+ACK(SEQ=y,ACK=x+1) 标志的数据包 –> 客户端,然后服务端进入 **SYN_RECV** 状态
|
||||
|
|
@ -23,9 +23,9 @@ tag:
|
|||
|
||||
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
|
||||
|
||||
1. **第一次握手** :Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
|
||||
2. **第二次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
|
||||
3. **第三次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
|
||||
1. **第一次握手**:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
|
||||
2. **第二次握手**:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
|
||||
3. **第三次握手**:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
|
||||
|
||||
三次握手就能确认双方收发功能都正常,缺一不可。
|
||||
|
||||
|
|
@ -41,12 +41,12 @@ tag:
|
|||
|
||||
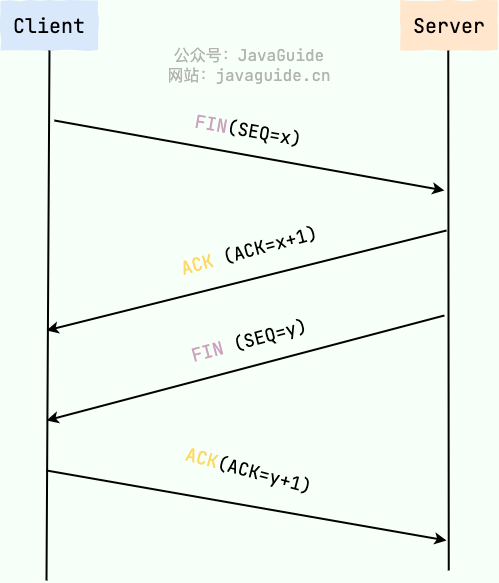
|
||||
|
||||
断开一个 TCP 连接则需要“四次挥手”,缺一不可 :
|
||||
断开一个 TCP 连接则需要“四次挥手”,缺一不可:
|
||||
|
||||
1. **第一次挥手** :客户端发送一个 FIN(SEQ=x) 标志的数据包->服务端,用来关闭客户端到服务器的数据传送。然后,客户端进入 **FIN-WAIT-1** 状态。
|
||||
2. **第二次挥手** :服务器收到这个 FIN(SEQ=X) 标志的数据包,它发送一个 ACK (ACK=x+1)标志的数据包->客户端 。然后,此时服务端进入 **CLOSE-WAIT** 状态,客户端进入 **FIN-WAIT-2** 状态。
|
||||
3. **第三次挥手** :服务端关闭与客户端的连接并发送一个 FIN (SEQ=y)标志的数据包->客户端请求关闭连接,然后,服务端进入 **LAST-ACK** 状态。
|
||||
4. **第四次挥手** :客户端发送 ACK (ACK=y+1)标志的数据包->服务端并且进入**TIME-WAIT**状态,服务端在收到 ACK (ACK=y+1)标志的数据包后进入 CLOSE 状态。此时,如果客户端等待 **2MSL** 后依然没有收到回复,就证明服务端已正常关闭,随后,客户端也可以关闭连接了。
|
||||
1. **第一次挥手**:客户端发送一个 FIN(SEQ=x) 标志的数据包->服务端,用来关闭客户端到服务器的数据传送。然后,客户端进入 **FIN-WAIT-1** 状态。
|
||||
2. **第二次挥手**:服务器收到这个 FIN(SEQ=X) 标志的数据包,它发送一个 ACK (ACK=x+1)标志的数据包->客户端 。然后,此时服务端进入 **CLOSE-WAIT** 状态,客户端进入 **FIN-WAIT-2** 状态。
|
||||
3. **第三次挥手**:服务端关闭与客户端的连接并发送一个 FIN (SEQ=y)标志的数据包->客户端请求关闭连接,然后,服务端进入 **LAST-ACK** 状态。
|
||||
4. **第四次挥手**:客户端发送 ACK (ACK=y+1)标志的数据包->服务端并且进入**TIME-WAIT**状态,服务端在收到 ACK (ACK=y+1)标志的数据包后进入 CLOSE 状态。此时,如果客户端等待 **2MSL** 后依然没有收到回复,就证明服务端已正常关闭,随后,客户端也可以关闭连接了。
|
||||
|
||||
**只要四次挥手没有结束,客户端和服务端就可以继续传输数据!**
|
||||
|
||||
|
|
@ -56,10 +56,10 @@ TCP 是全双工通信,可以双向传输数据。任何一方都可以在数
|
|||
|
||||
举个例子:A 和 B 打电话,通话即将结束后。
|
||||
|
||||
1. **第一次挥手** : A 说“我没啥要说的了”
|
||||
2. **第二次挥手** :B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话
|
||||
3. **第三次挥手** :于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”
|
||||
4. **第四次挥手** :A 回答“知道了”,这样通话才算结束。
|
||||
1. **第一次挥手**:A 说“我没啥要说的了”
|
||||
2. **第二次挥手**:B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话
|
||||
3. **第三次挥手**:于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”
|
||||
4. **第四次挥手**:A 回答“知道了”,这样通话才算结束。
|
||||
|
||||
### 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
|
||||
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ tag:
|
|||
|
||||
## TCP 如何保证传输的可靠性?
|
||||
|
||||
1. **基于数据块传输** :应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
|
||||
1. **基于数据块传输**:应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
|
||||
2. **对失序数据包重新排序以及去重**:TCP 为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据就可以实现数据包去重。
|
||||
3. **校验和** : TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
|
||||
4. **超时重传** : 当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为[已丢失](https://zh.wikipedia.org/wiki/丢包)并进行重传。
|
||||
|
|
@ -27,30 +27,30 @@ tag:
|
|||
|
||||
TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客户端和服务端既可能是发送端又可能是服务端。因此,两端各有一个发送缓冲区与接收缓冲区,两端都各自维护一个发送窗口和一个接收窗口。接收窗口大小取决于应用、系统、硬件的限制(TCP 传输速率不能大于应用的数据处理速率)。通信双方的发送窗口和接收窗口的要求相同
|
||||
|
||||
**TCP 发送窗口可以划分成四个部分** :
|
||||
**TCP 发送窗口可以划分成四个部分**:
|
||||
|
||||
1. 已经发送并且确认的 TCP 段(已经发送并确认);
|
||||
2. 已经发送但是没有确认的 TCP 段(已经发送未确认);
|
||||
3. 未发送但是接收方准备接收的 TCP 段(可以发送);
|
||||
4. 未发送并且接收方也并未准备接受的 TCP 段(不可发送)。
|
||||
|
||||
**TCP 发送窗口结构图示** :
|
||||
**TCP 发送窗口结构图示**:
|
||||
|
||||
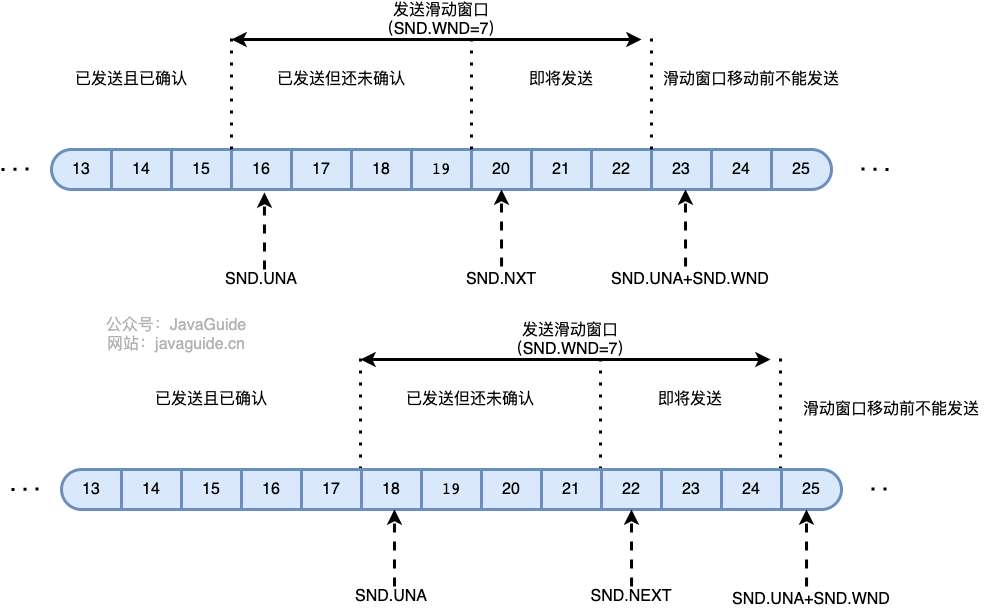
|
||||
|
||||
- **SND.WND** :发送窗口。
|
||||
- **SND.WND**:发送窗口。
|
||||
- **SND.UNA**:Send Unacknowledged 指针,指向发送窗口的第一个字节。
|
||||
- **SND.NXT**:Send Next 指针,指向可用窗口的第一个字节。
|
||||
|
||||
**可用窗口大小** = `SND.UNA + SND.WND - SND.NXT` 。
|
||||
|
||||
**TCP 接收窗口可以划分成三个部分** :
|
||||
**TCP 接收窗口可以划分成三个部分**:
|
||||
|
||||
1. 已经接收并且已经确认的 TCP 段(已经接收并确认);
|
||||
2. 等待接收且允许发送方发送 TCP 段(可以接收未确认);
|
||||
3. 不可接收且不允许发送方发送 TCP 段(不可接收)。
|
||||
|
||||
**TCP 接收窗口结构图示** :
|
||||
**TCP 接收窗口结构图示**:
|
||||
|
||||
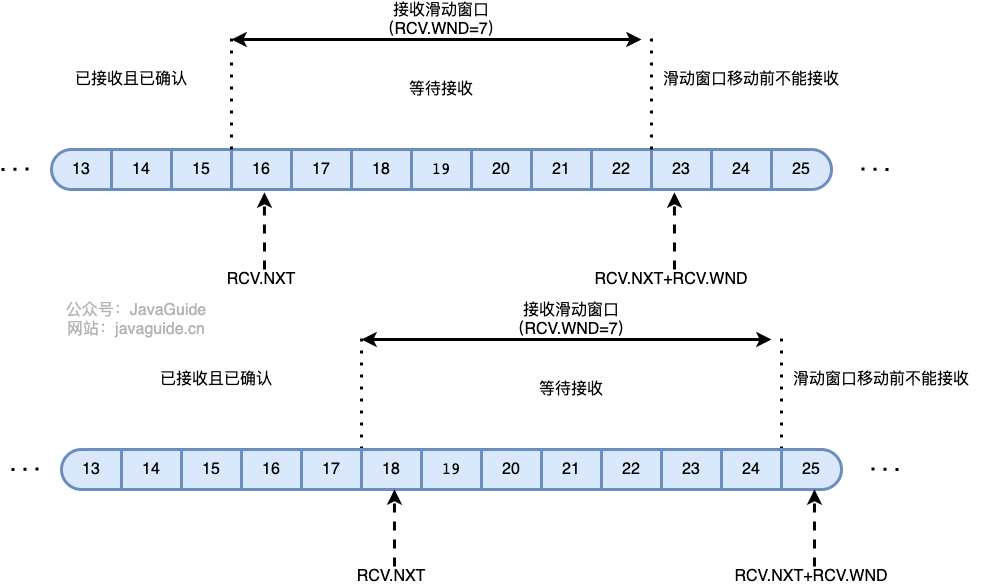
|
||||
|
||||
|
|
@ -66,7 +66,7 @@ TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客
|
|||
|
||||
为了进行拥塞控制,TCP 发送方要维持一个 **拥塞窗口(cwnd)** 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
|
||||
|
||||
TCP 的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免** 、**快重传** 和 **快恢复**。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
|
||||
TCP 的拥塞控制采用了四种算法,即 **慢开始**、 **拥塞避免**、**快重传** 和 **快恢复**。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
|
||||
|
||||
- **慢开始:** 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。
|
||||
- **拥塞避免:** 拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢增大,即每经过一个往返时间 RTT 就把发送方的 cwnd 加 1.
|
||||
|
|
@ -94,8 +94,8 @@ ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
|
|||
|
||||
**3) 确认丢失和确认迟到**
|
||||
|
||||
- **确认丢失** :确认消息在传输过程丢失。当 A 发送 M1 消息,B 收到后,B 向 A 发送了一个 M1 确认消息,但却在传输过程中丢失。而 A 并不知道,在超时计时过后,A 重传 M1 消息,B 再次收到该消息后采取以下两点措施:1. 丢弃这个重复的 M1 消息,不向上层交付。 2. 向 A 发送确认消息。(不会认为已经发送过了,就不再发送。A 能重传,就证明 B 的确认消息丢失)。
|
||||
- **确认迟到** :确认消息在传输过程中迟到。A 发送 M1 消息,B 收到并发送确认。在超时时间内没有收到确认消息,A 重传 M1 消息,B 仍然收到并继续发送确认消息(B 收到了 2 份 M1)。此时 A 收到了 B 第二次发送的确认消息。接着发送其他数据。过了一会,A 收到了 B 第一次发送的对 M1 的确认消息(A 也收到了 2 份确认消息)。处理如下:1. A 收到重复的确认后,直接丢弃。2. B 收到重复的 M1 后,也直接丢弃重复的 M1。
|
||||
- **确认丢失**:确认消息在传输过程丢失。当 A 发送 M1 消息,B 收到后,B 向 A 发送了一个 M1 确认消息,但却在传输过程中丢失。而 A 并不知道,在超时计时过后,A 重传 M1 消息,B 再次收到该消息后采取以下两点措施:1. 丢弃这个重复的 M1 消息,不向上层交付。 2. 向 A 发送确认消息。(不会认为已经发送过了,就不再发送。A 能重传,就证明 B 的确认消息丢失)。
|
||||
- **确认迟到**:确认消息在传输过程中迟到。A 发送 M1 消息,B 收到并发送确认。在超时时间内没有收到确认消息,A 重传 M1 消息,B 仍然收到并继续发送确认消息(B 收到了 2 份 M1)。此时 A 收到了 B 第二次发送的确认消息。接着发送其他数据。过了一会,A 收到了 B 第一次发送的对 M1 的确认消息(A 也收到了 2 份确认消息)。处理如下:1. A 收到重复的确认后,直接丢弃。2. B 收到重复的 M1 后,也直接丢弃重复的 M1。
|
||||
|
||||
### 连续 ARQ 协议
|
||||
|
||||
|
|
|
|||
|
|
@ -18,9 +18,9 @@ head:
|
|||
|
||||
通过以下三点可以概括 Linux 到底是什么:
|
||||
|
||||
- **类 Unix 系统** : Linux 是一种自由、开放源码的类似 Unix 的操作系统
|
||||
- **Linux 本质是指 Linux 内核** : 严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
|
||||
- **Linux 之父(林纳斯·本纳第克特·托瓦兹 Linus Benedict Torvalds)** : 一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
|
||||
- **类 Unix 系统**:Linux 是一种自由、开放源码的类似 Unix 的操作系统
|
||||
- **Linux 本质是指 Linux 内核**:严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
|
||||
- **Linux 之父(林纳斯·本纳第克特·托瓦兹 Linus Benedict Torvalds)**:一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
|
||||
|
||||

|
||||
|
||||
|
|
@ -44,8 +44,8 @@ Linus Torvalds 开源的只是 Linux 内核,我们上面也提到了操作系
|
|||
|
||||
Linux 的发行版本可以大体分为两类:
|
||||
|
||||
- **商业公司维护的发行版本** :比如 Red Hat 公司维护支持的 Red Hat Enterprise Linux (RHEL)。
|
||||
- **社区组织维护的发行版本** :比如基于 Red Hat Enterprise Linux(RHEL)的 CentOS、基于 Debian 的 Ubuntu。
|
||||
- **商业公司维护的发行版本**:比如 Red Hat 公司维护支持的 Red Hat Enterprise Linux (RHEL)。
|
||||
- **社区组织维护的发行版本**:比如基于 Red Hat Enterprise Linux(RHEL)的 CentOS、基于 Debian 的 Ubuntu。
|
||||
|
||||
对于初学者学习 Linux ,推荐选择 CentOS,原因如下:
|
||||
|
||||
|
|
@ -68,7 +68,7 @@ inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作
|
|||
|
||||
通过以下五点可以概括 inode 到底是什么:
|
||||
|
||||
1. 硬盘的最小存储单位是扇区(Sector),块(block)由多个扇区组成。文件数据存储在块中。块的最常见的大小是 4kb,约为 8 个连续的扇区组成(每个扇区存储 512 字节)。一个文件可能会占用多个 block,但是一个块只能存放一个文件。虽然,我们将文件存储在了块(block)中,但是我们还需要一个空间来存储文件的 **元信息 metadata** :如某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等。这种 **存储文件元信息的区域就叫 inode**,译为索引节点:**i(index)+node**。 **每个文件都有一个唯一的 inode,存储文件的元信息。**
|
||||
1. 硬盘的最小存储单位是扇区(Sector),块(block)由多个扇区组成。文件数据存储在块中。块的最常见的大小是 4kb,约为 8 个连续的扇区组成(每个扇区存储 512 字节)。一个文件可能会占用多个 block,但是一个块只能存放一个文件。虽然,我们将文件存储在了块(block)中,但是我们还需要一个空间来存储文件的 **元信息 metadata**:如某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等。这种 **存储文件元信息的区域就叫 inode**,译为索引节点:**i(index)+node**。 **每个文件都有一个唯一的 inode,存储文件的元信息。**
|
||||
2. inode 是一种固定大小的数据结构,其大小在文件系统创建时就确定了,并且在文件的生命周期内保持不变。
|
||||
3. inode 的访问速度非常快,因为系统可以直接通过 inode 号码定位到文件的元数据信息,无需遍历整个文件系统。
|
||||
4. inode 的数量是有限的,每个文件系统只能包含固定数量的 inode。这意味着当文件系统中的 inode 用完时,无法再创建新的文件或目录,即使磁盘上还有可用空间。因此,在创建文件系统时,需要根据文件和目录的预期数量来合理分配 inode 的数量。
|
||||
|
|
@ -78,8 +78,8 @@ inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作
|
|||
|
||||
再总结一下 inode 和 block:
|
||||
|
||||
- **inode** :记录文件的属性信息,可以使用 `stat` 命令查看 inode 信息。
|
||||
- **block** :实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
|
||||
- **inode**:记录文件的属性信息,可以使用 `stat` 命令查看 inode 信息。
|
||||
- **block**:实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
|
||||
|
||||

|
||||
|
||||
|
|
@ -116,13 +116,13 @@ inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作
|
|||
|
||||
Linux 支持很多文件类型,其中非常重要的文件类型有: **普通文件**,**目录文件**,**链接文件**,**设备文件**,**管道文件**,**Socket 套接字文件** 等。
|
||||
|
||||
- **普通文件(-)** : 用于存储信息和数据, Linux 用户可以根据访问权限对普通文件进行查看、更改和删除。比如:图片、声音、PDF、text、视频、源代码等等。
|
||||
- **目录文件(d,directory file)** :目录也是文件的一种,用于表示和管理系统中的文件,目录文件中包含一些文件名和子目录名。打开目录事实上就是打开目录文件。
|
||||
- **符号链接文件(l,symbolic link)** :保留了指向文件的地址而不是文件本身。
|
||||
- **字符设备(c,char)** :用来访问字符设备比如键盘。
|
||||
- **设备文件(b,block)** : 用来访问块设备比如硬盘、软盘。
|
||||
- **普通文件(-)**:用于存储信息和数据, Linux 用户可以根据访问权限对普通文件进行查看、更改和删除。比如:图片、声音、PDF、text、视频、源代码等等。
|
||||
- **目录文件(d,directory file)**:目录也是文件的一种,用于表示和管理系统中的文件,目录文件中包含一些文件名和子目录名。打开目录事实上就是打开目录文件。
|
||||
- **符号链接文件(l,symbolic link)**:保留了指向文件的地址而不是文件本身。
|
||||
- **字符设备(c,char)**:用来访问字符设备比如键盘。
|
||||
- **设备文件(b,block)**:用来访问块设备比如硬盘、软盘。
|
||||
- **管道文件(p,pipe)** : 一种特殊类型的文件,用于进程之间的通信。
|
||||
- **套接字文件(s,socket)** :用于进程间的网络通信,也可以用于本机之间的非网络通信。
|
||||
- **套接字文件(s,socket)**:用于进程间的网络通信,也可以用于本机之间的非网络通信。
|
||||
|
||||
每种文件类型都有不同的用途和属性,可以通过命令如`ls`、`file`等来查看文件的类型信息。
|
||||
|
||||
|
|
@ -147,7 +147,7 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
|
|||
- **/bin:** 存放二进制可执行文件(ls、cat、mkdir 等),常用命令一般都在这里;
|
||||
- **/etc:** 存放系统管理和配置文件;
|
||||
- **/home:** 存放所有用户文件的根目录,是用户主目录的基点,比如用户 user 的主目录就是/home/user,可以用~user 表示;
|
||||
- **/usr :** 用于存放系统应用程序;
|
||||
- **/usr:** 用于存放系统应用程序;
|
||||
- **/opt:** 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把 tomcat 等都安装到这里;
|
||||
- **/proc:** 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
|
||||
- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
|
||||
|
|
@ -155,7 +155,7 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
|
|||
- **/dev:** 用于存放设备文件;
|
||||
- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
|
||||
- **/boot:** 存放用于系统引导时使用的各种文件;
|
||||
- **/lib 和/lib64 :** 存放着和系统运行相关的库文件 ;
|
||||
- **/lib 和/lib64:** 存放着和系统运行相关的库文件 ;
|
||||
- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
|
||||
- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
|
||||
- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows 下叫什么.chk)就在这里。
|
||||
|
|
@ -174,10 +174,10 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
|
|||
|
||||
### 目录切换
|
||||
|
||||
- `cd usr`: 切换到该目录下 usr 目录
|
||||
- `cd ..(或cd../)`: 切换到上一层目录
|
||||
- `cd /`: 切换到系统根目录
|
||||
- `cd ~`: 切换到用户主目录
|
||||
- `cd usr`:切换到该目录下 usr 目录
|
||||
- `cd ..(或cd../)`:切换到上一层目录
|
||||
- `cd /`:切换到系统根目录
|
||||
- `cd ~`:切换到用户主目录
|
||||
- **`cd -`:** 切换到上一个操作所在目录
|
||||
|
||||
### 目录操作
|
||||
|
|
@ -198,8 +198,8 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
|
|||
|
||||
- `touch [选项] 文件名..`:创建新文件或更新已存在文件(增)。例如:`touch file1.txt file2.txt file3.txt` ,创建 3 个文件。
|
||||
- `ln [选项] <源文件> <硬链接/软链接文件>`:创建硬链接/软链接。例如:`ln -s file.txt file_link`,创建名为 `file_link` 的软链接,指向 `file.txt` 文件。`-s` 选项代表的就是创建软链接,s 即 symbolic(软链接又名符号链接) 。
|
||||
- `cat/more/less/tail 文件名` :文件的查看(查) 。命令 `tail -f 文件` 可以对某个文件进行动态监控,例如 Tomcat 的日志文件, 会随着程序的运行,日志会变化,可以使用 `tail -f catalina-2016-11-11.log` 监控 文 件的变化 。
|
||||
- `vim 文件名`: 修改文件的内容(改)。vim 编辑器是 Linux 中的强大组件,是 vi 编辑器的加强版,vim 编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用 vim 编辑修改文件的方式基本会使用就可以了。在实际开发中,使用 vim 编辑器主要作用就是修改配置文件,下面是一般步骤: `vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q!` (输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存)。
|
||||
- `cat/more/less/tail 文件名`:文件的查看(查) 。命令 `tail -f 文件` 可以对某个文件进行动态监控,例如 Tomcat 的日志文件, 会随着程序的运行,日志会变化,可以使用 `tail -f catalina-2016-11-11.log` 监控 文 件的变化 。
|
||||
- `vim 文件名`:修改文件的内容(改)。vim 编辑器是 Linux 中的强大组件,是 vi 编辑器的加强版,vim 编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用 vim 编辑修改文件的方式基本会使用就可以了。在实际开发中,使用 vim 编辑器主要作用就是修改配置文件,下面是一般步骤:`vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q!` (输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存)。
|
||||
|
||||
### 文件压缩
|
||||
|
||||
|
|
@ -214,7 +214,7 @@ Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是
|
|||
- v:显示运行过程
|
||||
- f:指定文件名
|
||||
|
||||
比如:假如 test 目录下有三个文件分别是:`aaa.txt`、 `bbb.txt` 、`ccc.txt`,如果我们要打包 `test` 目录并指定压缩后的压缩包名称为 `test.tar.gz` 可以使用命令:`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt` 或 `tar -zcvf test.tar.gz /test/` 。
|
||||
比如:假如 test 目录下有三个文件分别是:`aaa.txt`、 `bbb.txt`、`ccc.txt`,如果我们要打包 `test` 目录并指定压缩后的压缩包名称为 `test.tar.gz` 可以使用命令:`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt` 或 `tar -zcvf test.tar.gz /test/` 。
|
||||
|
||||
**2)解压压缩包:**
|
||||
|
||||
|
|
@ -251,9 +251,9 @@ Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是
|
|||
|
||||
**文件的类型:**
|
||||
|
||||
- d: 代表目录
|
||||
- -: 代表文件
|
||||
- l: 代表软链接(可以认为是 window 中的快捷方式)
|
||||
- d:代表目录
|
||||
- -:代表文件
|
||||
- l:代表软链接(可以认为是 window 中的快捷方式)
|
||||
|
||||
**Linux 中权限分为以下几种:**
|
||||
|
||||
|
|
@ -281,13 +281,13 @@ Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是
|
|||
| w | 可以创建和删除目录下文件 |
|
||||
| x | 可以使用 cd 进入目录 |
|
||||
|
||||
需要注意的是: **超级用户可以无视普通用户的权限,即使文件目录权限是 000,依旧可以访问。**
|
||||
需要注意的是:**超级用户可以无视普通用户的权限,即使文件目录权限是 000,依旧可以访问。**
|
||||
|
||||
**在 linux 中的每个用户必须属于一个组,不能独立于组外。在 linux 中每个文件有所有者、所在组、其它组的概念。**
|
||||
|
||||
- **所有者(u)** :一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
|
||||
- **文件所在组(g)** :当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
|
||||
- **其它组(o)** :除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
|
||||
- **所有者(u)**:一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
|
||||
- **文件所在组(g)**:当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
|
||||
- **其它组(o)**:除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
|
||||
|
||||
> 我们再来看看如何修改文件/目录的权限。
|
||||
|
||||
|
|
@ -339,12 +339,12 @@ Linux 系统是一个多用户多任务的分时操作系统,任何一个要
|
|||
- `top [选项]`:用于实时查看系统的 CPU 使用率、内存使用率、进程信息等。
|
||||
- `htop [选项]`:类似于 `top`,但提供了更加交互式和友好的界面,可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
|
||||
- `uptime [选项]`:用于查看系统总共运行了多长时间、系统的平均负载等信息。
|
||||
- `vmstat [间隔时间] [重复次数]` :vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O 等系统整体运行状态。
|
||||
- `vmstat [间隔时间] [重复次数]`:vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O 等系统整体运行状态。
|
||||
- `free [选项]`:用于查看系统的内存使用情况,包括已用内存、可用内存、缓冲区和缓存等。
|
||||
- `df [选项] [文件系统]`:用于查看系统的磁盘空间使用情况,包括磁盘空间的总量、已使用量和可用量等,可以指定文件系统上。例如:`df -a`,查看全部文件系统。
|
||||
- `du [选项] [文件]`:用于查看指定目录或文件的磁盘空间使用情况,可以指定不同的选项来控制输出格式和单位。
|
||||
- `sar [选项] [时间间隔] [重复次数]`:用于收集、报告和分析系统的性能统计信息,包括系统的 CPU 使用、内存使用、磁盘 I/O、网络活动等详细信息。它的特点是可以连续对系统取样,获得大量的取样数据。取样数据和分析的结果都可以存入文件,使用它时消耗的系统资源很小。
|
||||
- `ps [选项]`:用于查看系统中的进程信息,包括进程的 ID、状态、资源使用情况等。`ps -ef`/`ps -aux`: 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:`ps aux|grep redis` (查看包括 redis 字符串的进程),也可使用 `pgrep redis -a`。
|
||||
- `ps [选项]`:用于查看系统中的进程信息,包括进程的 ID、状态、资源使用情况等。`ps -ef`/`ps -aux`:这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:`ps aux|grep redis` (查看包括 redis 字符串的进程),也可使用 `pgrep redis -a`。
|
||||
- `systemctl [命令] [服务名称]`:用于管理系统的服务和单元,可以查看系统服务的状态、启动、停止、重启等。
|
||||
|
||||
### 网络通信
|
||||
|
|
@ -352,15 +352,15 @@ Linux 系统是一个多用户多任务的分时操作系统,任何一个要
|
|||
- `ping [选项] 目标主机`:测试与目标主机的网络连接。
|
||||
- `ifconfig` 或 `ip`:用于查看系统的网络接口信息,包括网络接口的 IP 地址、MAC 地址、状态等。
|
||||
- `netstat [选项]`:用于查看系统的网络连接状态和网络统计信息,可以查看当前的网络连接情况、监听端口、网络协议等。
|
||||
- `ss [选项]` :比 `netstat` 更好用,提供了更快速、更详细的网络连接信息。
|
||||
- `ss [选项]`:比 `netstat` 更好用,提供了更快速、更详细的网络连接信息。
|
||||
|
||||
### 其他
|
||||
|
||||
- `sudo + 其他命令`:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行。
|
||||
- `grep 要搜索的字符串 要搜索的文件 --color`: 搜索命令,--color 代表高亮显示。
|
||||
- `kill -9 进程的pid`: 杀死进程(-9 表示强制终止)先用 ps 查找进程,然后用 kill 杀掉。
|
||||
- `shutdown`: `shutdown -h now`: 指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定 5 分钟后关机,同时送出警告信息给登入用户。
|
||||
- `reboot`: `reboot`: 重开机。`reboot -w`: 做个重开机的模拟(只有纪录并不会真的重开机)。
|
||||
- `grep 要搜索的字符串 要搜索的文件 --color`:搜索命令,--color 代表高亮显示。
|
||||
- `kill -9 进程的pid`:杀死进程(-9 表示强制终止)先用 ps 查找进程,然后用 kill 杀掉。
|
||||
- `shutdown`:`shutdown -h now`:指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定 5 分钟后关机,同时送出警告信息给登入用户。
|
||||
- `reboot`:`reboot`:重开机。`reboot -w`:做个重开机的模拟(只有纪录并不会真的重开机)。
|
||||
|
||||
## Linux 环境变量
|
||||
|
||||
|
|
|
|||
|
|
@ -20,8 +20,8 @@ head:
|
|||
|
||||
开始本文的内容之前,我们先聊聊为什么要学习操作系统。
|
||||
|
||||
- **从对个人能力方面提升来说** :操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
|
||||
- **从面试角度来说** :尤其是校招,对于操作系统方面知识的考察是非常非常多的。
|
||||
- **从对个人能力方面提升来说**:操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
|
||||
- **从面试角度来说**:尤其是校招,对于操作系统方面知识的考察是非常非常多的。
|
||||
|
||||
**简单来说,学习操作系统能够提高自己思考的深度以及对技术的理解力,并且,操作系统方面的知识也是面试必备。**
|
||||
|
||||
|
|
@ -51,12 +51,12 @@ head:
|
|||
|
||||
从资源管理的角度来看,操作系统有 6 大功能:
|
||||
|
||||
1. **进程和线程的管理** :进程的创建、撤销、阻塞、唤醒,进程间的通信等。
|
||||
2. **存储管理** :内存的分配和管理、外存(磁盘等)的分配和管理等。
|
||||
3. **文件管理** :文件的读、写、创建及删除等。
|
||||
4. **设备管理** :完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
|
||||
5. **网络管理** :操作系统负责管理计算机网络的使用。网络是计算机系统中连接不同计算机的方式,操作系统需要管理计算机网络的配置、连接、通信和安全等,以提供高效可靠的网络服务。
|
||||
6. **安全管理** :用户的身份认证、访问控制、文件加密等,以防止非法用户对系统资源的访问和操作。
|
||||
1. **进程和线程的管理**:进程的创建、撤销、阻塞、唤醒,进程间的通信等。
|
||||
2. **存储管理**:内存的分配和管理、外存(磁盘等)的分配和管理等。
|
||||
3. **文件管理**:文件的读、写、创建及删除等。
|
||||
4. **设备管理**:完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
|
||||
5. **网络管理**:操作系统负责管理计算机网络的使用。网络是计算机系统中连接不同计算机的方式,操作系统需要管理计算机网络的配置、连接、通信和安全等,以提供高效可靠的网络服务。
|
||||
6. **安全管理**:用户的身份认证、访问控制、文件加密等,以防止非法用户对系统资源的访问和操作。
|
||||
|
||||
### 常见的操作系统有哪些?
|
||||
|
||||
|
|
@ -99,7 +99,7 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
|
|||
根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
|
||||
|
||||
- **用户态(User Mode)** : 用户态运行的进程可以直接读取用户程序的数据,拥有较低的权限。当应用程序需要执行某些需要特殊权限的操作,例如读写磁盘、网络通信等,就需要向操作系统发起系统调用请求,进入内核态。
|
||||
- **内核态(Kernel Mode)** :内核态运行的进程几乎可以访问计算机的任何资源包括系统的内存空间、设备、驱动程序等,不受限制,拥有非常高的权限。当操作系统接收到进程的系统调用请求时,就会从用户态切换到内核态,执行相应的系统调用,并将结果返回给进程,最后再从内核态切换回用户态。
|
||||
- **内核态(Kernel Mode)**:内核态运行的进程几乎可以访问计算机的任何资源包括系统的内存空间、设备、驱动程序等,不受限制,拥有非常高的权限。当操作系统接收到进程的系统调用请求时,就会从用户态切换到内核态,执行相应的系统调用,并将结果返回给进程,最后再从内核态切换回用户态。
|
||||
|
||||
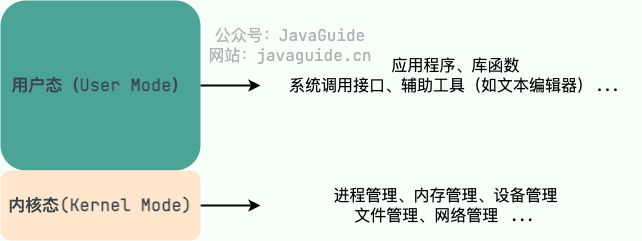
|
||||
|
||||
|
|
@ -118,8 +118,8 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
|
|||
|
||||
用户态切换到内核态的 3 种方式:
|
||||
|
||||
1. **系统调用(Trap)** :用户态进程 **主动** 要求切换到内核态的一种方式,主要是为了使用内核态才能做的事情比如读取磁盘资源。系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现。
|
||||
2. **中断(Interrupt)** :当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
|
||||
1. **系统调用(Trap)**:用户态进程 **主动** 要求切换到内核态的一种方式,主要是为了使用内核态才能做的事情比如读取磁盘资源。系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现。
|
||||
2. **中断(Interrupt)**:当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
|
||||
3. **异常(Exception)**:当 CPU 在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
|
||||
|
||||
在系统的处理上,中断和异常类似,都是通过中断向量表来找到相应的处理程序进行处理。区别在于,中断来自处理器外部,不是由任何一条专门的指令造成,而异常是执行当前指令的结果。
|
||||
|
|
@ -192,7 +192,7 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
|
|||
|
||||
再深入到计算机底层来探讨:
|
||||
|
||||
- **单核时代**: 在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
|
||||
- **单核时代**:在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
|
||||
- **多核时代**: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
|
||||
|
||||
### 线程间的同步的方式有哪些?
|
||||
|
|
@ -201,10 +201,10 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
|
|||
|
||||
下面是几种常见的线程同步的方式:
|
||||
|
||||
1. **互斥锁(Mutex)** :采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
|
||||
1. **互斥锁(Mutex)**:采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
|
||||
2. **读写锁(Read-Write Lock)**:允许多个线程同时读取共享资源,但只有一个线程可以对共享资源进行写操作。
|
||||
3. **信号量(Semaphore)** :它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
|
||||
4. **屏障(Barrier)** :屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
|
||||
3. **信号量(Semaphore)**:它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
|
||||
4. **屏障(Barrier)**:屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
|
||||
5. **事件(Event)** :Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作。
|
||||
|
||||
### PCB 是什么?包含哪些信息?
|
||||
|
|
@ -226,11 +226,11 @@ PCB 主要包含下面几部分的内容:
|
|||
|
||||
我们一般把进程大致分为 5 种状态,这一点和线程很像!
|
||||
|
||||
- **创建状态(new)** :进程正在被创建,尚未到就绪状态。
|
||||
- **就绪状态(ready)** :进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
|
||||
- **运行状态(running)** :进程正在处理器上运行(单核 CPU 下任意时刻只有一个进程处于运行状态)。
|
||||
- **阻塞状态(waiting)** :又称为等待状态,进程正在等待某一事件而暂停运行如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
|
||||
- **结束状态(terminated)** :进程正在从系统中消失。可能是进程正常结束或其他原因中断退出运行。
|
||||
- **创建状态(new)**:进程正在被创建,尚未到就绪状态。
|
||||
- **就绪状态(ready)**:进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
|
||||
- **运行状态(running)**:进程正在处理器上运行(单核 CPU 下任意时刻只有一个进程处于运行状态)。
|
||||
- **阻塞状态(waiting)**:又称为等待状态,进程正在等待某一事件而暂停运行如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
|
||||
- **结束状态(terminated)**:进程正在从系统中消失。可能是进程正常结束或其他原因中断退出运行。
|
||||
|
||||
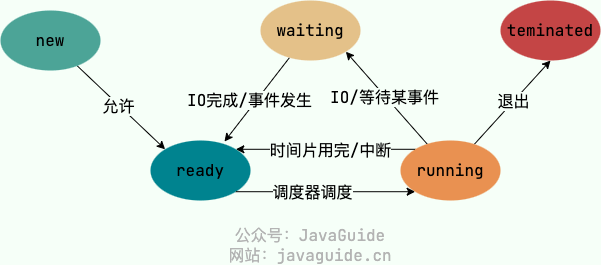
|
||||
|
||||
|
|
@ -238,12 +238,12 @@ PCB 主要包含下面几部分的内容:
|
|||
|
||||
> 下面这部分总结参考了:[《进程间通信 IPC (InterProcess Communication)》](https://www.jianshu.com/p/c1015f5ffa74) 这篇文章,推荐阅读,总结的非常不错。
|
||||
|
||||
1. **管道/匿名管道(Pipes)** :用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
|
||||
1. **管道/匿名管道(Pipes)**:用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
|
||||
2. **有名管道(Named Pipes)** : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循 **先进先出(First In First Out)** 。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
|
||||
3. **信号(Signal)** :信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
|
||||
4. **消息队列(Message Queuing)** :消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。**消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。**
|
||||
5. **信号量(Semaphores)** :信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
|
||||
6. **共享内存(Shared memory)** :使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
|
||||
3. **信号(Signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
|
||||
4. **消息队列(Message Queuing)**:消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。**消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。**
|
||||
5. **信号量(Semaphores)**:信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
|
||||
6. **共享内存(Shared memory)**:使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
|
||||
7. **套接字(Sockets)** : 此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
|
||||
|
||||
### 进程的调度算法有哪些?
|
||||
|
|
@ -255,8 +255,8 @@ PCB 主要包含下面几部分的内容:
|
|||
- **先到先服务调度算法(FCFS,First Come, First Served)** : 从就绪队列中选择一个最先进入该队列的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
|
||||
- **短作业优先的调度算法(SJF,Shortest Job First)** : 从就绪队列中选出一个估计运行时间最短的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
|
||||
- **时间片轮转调度算法(RR,Round-Robin)** : 时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
|
||||
- **多级反馈队列调度算法(MFQ,Multi-level Feedback Queue)** :前面介绍的几种进程调度的算法都有一定的局限性。如**短进程优先的调度算法,仅照顾了短进程而忽略了长进程** 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。,因而它是目前**被公认的一种较好的进程调度算法**,UNIX 操作系统采取的便是这种调度算法。
|
||||
- **优先级调度算法(Priority)** : 为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以 FCFS 方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
|
||||
- **多级反馈队列调度算法(MFQ,Multi-level Feedback Queue)**:前面介绍的几种进程调度的算法都有一定的局限性。如**短进程优先的调度算法,仅照顾了短进程而忽略了长进程** 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。,因而它是目前**被公认的一种较好的进程调度算法**,UNIX 操作系统采取的便是这种调度算法。
|
||||
- **优先级调度算法(Priority)**:为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以 FCFS 方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
|
||||
|
||||
### 什么是僵尸进程和孤儿进程?
|
||||
|
||||
|
|
@ -266,8 +266,8 @@ PCB 主要包含下面几部分的内容:
|
|||
|
||||
这样的设计可以让父进程在子进程结束时得到子进程的状态信息,并且可以防止出现“僵尸进程”(即子进程结束后 PCB 仍然存在但父进程无法得到状态信息的情况)。
|
||||
|
||||
- **僵尸进程** :子进程已经终止,但是其父进程仍在运行,且父进程没有调用 wait()或 waitpid()等系统调用来获取子进程的状态信息,释放子进程占用的资源,导致子进程的 PCB 依然存在于系统中,但无法被进一步使用。这种情况下,子进程被称为“僵尸进程”。避免僵尸进程的产生,父进程需要及时调用 wait()或 waitpid()系统调用来回收子进程。
|
||||
- **孤儿进程** :一个进程的父进程已经终止或者不存在,但是该进程仍在运行。这种情况下,该进程就是孤儿进程。孤儿进程通常是由于父进程意外终止或未及时调用 wait()或 waitpid()等系统调用来回收子进程导致的。为了避免孤儿进程占用系统资源,操作系统会将孤儿进程的父进程设置为 init 进程(进程号为 1),由 init 进程来回收孤儿进程的资源。
|
||||
- **僵尸进程**:子进程已经终止,但是其父进程仍在运行,且父进程没有调用 wait()或 waitpid()等系统调用来获取子进程的状态信息,释放子进程占用的资源,导致子进程的 PCB 依然存在于系统中,但无法被进一步使用。这种情况下,子进程被称为“僵尸进程”。避免僵尸进程的产生,父进程需要及时调用 wait()或 waitpid()系统调用来回收子进程。
|
||||
- **孤儿进程**:一个进程的父进程已经终止或者不存在,但是该进程仍在运行。这种情况下,该进程就是孤儿进程。孤儿进程通常是由于父进程意外终止或未及时调用 wait()或 waitpid()等系统调用来回收子进程导致的。为了避免孤儿进程占用系统资源,操作系统会将孤儿进程的父进程设置为 init 进程(进程号为 1),由 init 进程来回收孤儿进程的资源。
|
||||
|
||||
### 如何查看是否有僵尸进程?
|
||||
|
||||
|
|
@ -305,7 +305,7 @@ ps -A -ostat,ppid,pid,cmd |grep -e '^[Zz]'
|
|||
3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
|
||||
4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,......,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
|
||||
|
||||
**注意 ⚠️** :这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
|
||||
**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
|
||||
|
||||
下面是百度百科对必要条件的解释:
|
||||
|
||||
|
|
@ -384,7 +384,7 @@ Thread[线程 2,5,main]waiting get resource1
|
|||
|
||||
破坏第一个条件 **互斥条件**:使得资源是可以同时访问的,这是种简单的方法,磁盘就可以用这种方法管理,但是我们要知道,有很多资源 **往往是不能同时访问的** ,所以这种做法在大多数的场合是行不通的。
|
||||
|
||||
破坏第三个条件 **非抢占** :也就是说可以采用 **剥夺式调度算法**,但剥夺式调度方法目前一般仅适用于 **主存资源** 和 **处理器资源** 的分配,并不适用于所有的资源,会导致 **资源利用率下降**。
|
||||
破坏第三个条件 **非抢占**:也就是说可以采用 **剥夺式调度算法**,但剥夺式调度方法目前一般仅适用于 **主存资源** 和 **处理器资源** 的分配,并不适用于所有的资源,会导致 **资源利用率下降**。
|
||||
|
||||
所以一般比较实用的 **预防死锁的方法**,是通过考虑破坏第二个条件和第四个条件。
|
||||
|
||||
|
|
@ -444,10 +444,10 @@ Thread[线程 2,5,main]waiting get resource1
|
|||
|
||||
当死锁检测程序检测到存在死锁发生时,应设法让其解除,让系统从死锁状态中恢复过来,常用的解除死锁的方法有以下四种:
|
||||
|
||||
1. **立即结束所有进程的执行,重新启动操作系统** :这种方法简单,但以前所在的工作全部作废,损失很大。
|
||||
2. **撤销涉及死锁的所有进程,解除死锁后继续运行** :这种方法能彻底打破**死锁的循环等待**条件,但将付出很大代价,例如有些进程可能已经计算了很长时间,由于被撤销而使产生的部分结果也被消除了,再重新执行时还要再次进行计算。
|
||||
1. **立即结束所有进程的执行,重新启动操作系统**:这种方法简单,但以前所在的工作全部作废,损失很大。
|
||||
2. **撤销涉及死锁的所有进程,解除死锁后继续运行**:这种方法能彻底打破**死锁的循环等待**条件,但将付出很大代价,例如有些进程可能已经计算了很长时间,由于被撤销而使产生的部分结果也被消除了,再重新执行时还要再次进行计算。
|
||||
3. **逐个撤销涉及死锁的进程,回收其资源直至死锁解除。**
|
||||
4. **抢占资源** :从涉及死锁的一个或几个进程中抢占资源,把夺得的资源再分配给涉及死锁的进程直至死锁解除。
|
||||
4. **抢占资源**:从涉及死锁的一个或几个进程中抢占资源,把夺得的资源再分配给涉及死锁的进程直至死锁解除。
|
||||
|
||||
## 参考
|
||||
|
||||
|
|
|
|||
|
|
@ -20,20 +20,20 @@ head:
|
|||
|
||||
操作系统的内存管理非常重要,主要负责下面这些事情:
|
||||
|
||||
- **内存的分配与回收** :对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存。
|
||||
- **地址转换** :将程序中的虚拟地址转换成内存中的物理地址。
|
||||
- **内存扩充** :当系统没有足够的内存时,利用虚拟内存技术或自动覆盖技术,从逻辑上扩充内存。
|
||||
- **内存映射** :将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
|
||||
- **内存优化** :通过调整内存分配策略和回收算法来优化内存使用效率。
|
||||
- **内存安全** :保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
|
||||
- **内存的分配与回收**:对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存。
|
||||
- **地址转换**:将程序中的虚拟地址转换成内存中的物理地址。
|
||||
- **内存扩充**:当系统没有足够的内存时,利用虚拟内存技术或自动覆盖技术,从逻辑上扩充内存。
|
||||
- **内存映射**:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
|
||||
- **内存优化**:通过调整内存分配策略和回收算法来优化内存使用效率。
|
||||
- **内存安全**:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
|
||||
- ......
|
||||
|
||||
### 什么是内存碎片?
|
||||
|
||||
内存碎片是由内存的申请和释放产生的,通常分为下面两种:
|
||||
|
||||
- **内部内存碎片(Internal Memory Fragmentation,简称为内存碎片)** :已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片。
|
||||
- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)** :由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并为分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
|
||||
- **内部内存碎片(Internal Memory Fragmentation,简称为内存碎片)**:已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片。
|
||||
- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)**:由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并为分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
|
||||
|
||||
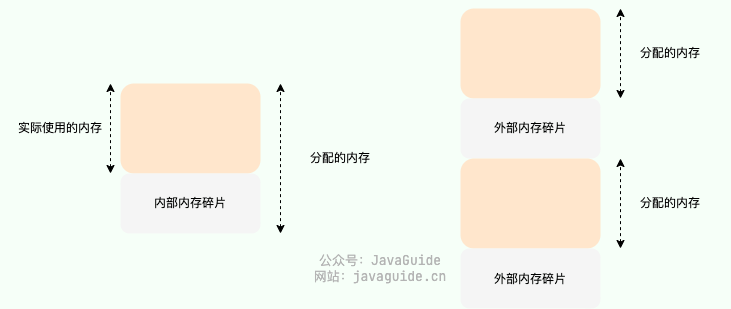
|
||||
|
||||
|
|
@ -43,8 +43,8 @@ head:
|
|||
|
||||
内存管理方式可以简单分为下面两种:
|
||||
|
||||
- **连续内存管理** :为一个用户程序分配一个连续的内存空间,内存利用率一般不高。
|
||||
- **非连续内存管理** :允许一个程序使用的内存分布在离散或者说不相邻的内存中,相对更加灵活一些。
|
||||
- **连续内存管理**:为一个用户程序分配一个连续的内存空间,内存利用率一般不高。
|
||||
- **非连续内存管理**:允许一个程序使用的内存分布在离散或者说不相邻的内存中,相对更加灵活一些。
|
||||
|
||||
#### 连续内存管理
|
||||
|
||||
|
|
@ -68,9 +68,9 @@ head:
|
|||
|
||||
非连续内存管理存在下面 3 种方式:
|
||||
|
||||
- **段式管理** :以段(—段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
|
||||
- **页式管理** :把物理内存分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页,现代操作系统广泛使用的一种内存管理方式。
|
||||
- **段页式管理机制** :结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
|
||||
- **段式管理**:以段(—段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
|
||||
- **页式管理**:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页,现代操作系统广泛使用的一种内存管理方式。
|
||||
- **段页式管理机制**:结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
|
||||
|
||||
### 虚拟内存
|
||||
|
||||
|
|
@ -82,12 +82,12 @@ head:
|
|||
|
||||
总结来说,虚拟内存主要提供了下面这些能力:
|
||||
|
||||
- **隔离进程** :物理内存通过虚拟地址空间访问,虚拟地址空间与进程一一对应。每个进程都认为自己拥有了整个物理内存,进程之间彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
|
||||
- **提升物理内存利用率** :有了虚拟地址空间后,操作系统只需要将进程当前正在使用的部分数据或指令加载入物理内存。
|
||||
- **简化内存管理** :进程都有一个一致且私有的虚拟地址空间,程序员不用和真正的物理内存打交道,而是借助虚拟地址空间访问物理内存,从而简化了内存管理。
|
||||
- **隔离进程**:物理内存通过虚拟地址空间访问,虚拟地址空间与进程一一对应。每个进程都认为自己拥有了整个物理内存,进程之间彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
|
||||
- **提升物理内存利用率**:有了虚拟地址空间后,操作系统只需要将进程当前正在使用的部分数据或指令加载入物理内存。
|
||||
- **简化内存管理**:进程都有一个一致且私有的虚拟地址空间,程序员不用和真正的物理内存打交道,而是借助虚拟地址空间访问物理内存,从而简化了内存管理。
|
||||
- **多个进程共享物理内存**:进程在运行过程中,会加载许多操作系统的动态库。这些库对于每个进程而言都是公用的,它们在内存中实际只会加载一份,这部分称为共享内存。
|
||||
- **提高内存使用安全性** :控制进程对物理内存的访问,隔离不同进程的访问权限,提高系统的安全性。
|
||||
- **提供更大的可使用内存空间** : 可以让程序拥有超过系统物理内存大小的可用内存空间。这是因为当物理内存不够用时,可以利用磁盘充当,将物理内存页(通常大小为 4 KB)保存到磁盘文件(会影响读写速度),数据或代码页会根据需要在物理内存与磁盘之间移动。
|
||||
- **提高内存使用安全性**:控制进程对物理内存的访问,隔离不同进程的访问权限,提高系统的安全性。
|
||||
- **提供更大的可使用内存空间**:可以让程序拥有超过系统物理内存大小的可用内存空间。这是因为当物理内存不够用时,可以利用磁盘充当,将物理内存页(通常大小为 4 KB)保存到磁盘文件(会影响读写速度),数据或代码页会根据需要在物理内存与磁盘之间移动。
|
||||
|
||||
#### 没有虚拟内存有什么问题?
|
||||
|
||||
|
|
@ -139,8 +139,8 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
|
|||
|
||||
分段机制下的虚拟地址由两部分组成:
|
||||
|
||||
- **段号** :标识着该虚拟地址属于整个虚拟地址空间中的哪一个段。
|
||||
- **段内偏移量** :相对于该段起始地址的偏移量。
|
||||
- **段号**:标识着该虚拟地址属于整个虚拟地址空间中的哪一个段。
|
||||
- **段内偏移量**:相对于该段起始地址的偏移量。
|
||||
|
||||
具体的地址翻译过程如下:
|
||||
|
||||
|
|
@ -156,8 +156,8 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
|
|||
|
||||
不一定。段表项可能并不存在:
|
||||
|
||||
- **段表项被删除** :软件错误、软件恶意行为等情况可能会导致段表项被删除。
|
||||
- **段表项还未创建** :如果系统内存不足或者无法分配到连续的物理内存块就会导致段表项无法被创建。
|
||||
- **段表项被删除**:软件错误、软件恶意行为等情况可能会导致段表项被删除。
|
||||
- **段表项还未创建**:如果系统内存不足或者无法分配到连续的物理内存块就会导致段表项无法被创建。
|
||||
|
||||
#### 分段机制为什么会导致内存外部碎片?
|
||||
|
||||
|
|
@ -192,8 +192,8 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
|
|||
|
||||
分页机制下的虚拟地址由两部分组成:
|
||||
|
||||
- **页号** :通过虚拟页号可以从页表中取出对应的物理页号;
|
||||
- **页内偏移量** :物理页起始地址+页内偏移量=物理内存地址。
|
||||
- **页号**:通过虚拟页号可以从页表中取出对应的物理页号;
|
||||
- **页内偏移量**:物理页起始地址+页内偏移量=物理内存地址。
|
||||
|
||||
具体的地址翻译过程如下:
|
||||
|
||||
|
|
@ -264,7 +264,7 @@ TLB 的设计思想非常简单,但命中率往往非常高,效果很好。
|
|||
|
||||
常见的页缺失有下面这两种:
|
||||
|
||||
- **硬性页缺失(Hard Page Fault)** :物理内存中没有对应的物理页。于是,Page Fault Handler 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系。
|
||||
- **硬性页缺失(Hard Page Fault)**:物理内存中没有对应的物理页。于是,Page Fault Handler 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系。
|
||||
- **软性页缺失(Soft Page Fault)**:物理内存中有对应的物理页,但虚拟页还未和物理页建立映射。于是,Page Fault Handler 会指示 MMU 建立相应的虚拟页和物理页的映射关系。
|
||||
|
||||
发生上面这两种缺页错误的时候,应用程序访问的是有效的物理内存,只是出现了物理页缺失或者虚拟页和物理页的映射关系未建立的问题。如果应用程序访问的是无效的物理内存的话,还会出现 **无效缺页错误(Invalid Page Fault)** 。
|
||||
|
|
@ -281,18 +281,18 @@ TLB 的设计思想非常简单,但命中率往往非常高,效果很好。
|
|||
|
||||
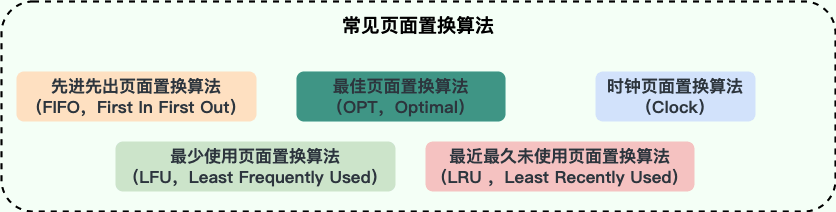
|
||||
|
||||
1. **最佳页面置换算法(OPT,Optimal)** :优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
|
||||
1. **最佳页面置换算法(OPT,Optimal)**:优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
|
||||
2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可需求。不过,它的性能并不是很好。
|
||||
3. **最近最久未使用页面置换算法(LRU ,Least Recently Used)** :LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
|
||||
3. **最近最久未使用页面置换算法(LRU ,Least Recently Used)**:LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
|
||||
4. **最少使用页面置换算法(LFU,Least Frequently Used)** : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页。
|
||||
5. **时钟页面置换算法(Clock)** :可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
|
||||
5. **时钟页面置换算法(Clock)**:可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
|
||||
|
||||
**FIFO 页面置换算法性能为何不好?**
|
||||
|
||||
主要原因主要有二:
|
||||
|
||||
1. **经常访问或者需要长期存在的页面会被频繁调入调出** :较早调入的页往往是经常被访问或者需要长期存在的页,这些页会被反复调入和调出。
|
||||
2. **存在 Belady 现象** :被置换的页面并不是进程不会访问的,有时就会出现分配的页面数增多但缺页率反而提高的异常现象。出现该异常的原因是因为 FIFO 算法只考虑了页面进入内存的顺序,而没有考虑页面访问的频率和紧迫性。
|
||||
1. **经常访问或者需要长期存在的页面会被频繁调入调出**:较早调入的页往往是经常被访问或者需要长期存在的页,这些页会被反复调入和调出。
|
||||
2. **存在 Belady 现象**:被置换的页面并不是进程不会访问的,有时就会出现分配的页面数增多但缺页率反而提高的异常现象。出现该异常的原因是因为 FIFO 算法只考虑了页面进入内存的顺序,而没有考虑页面访问的频率和紧迫性。
|
||||
|
||||
**哪一种页面置换算法实际用的比较多?**
|
||||
|
||||
|
|
@ -302,12 +302,12 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
|
|||
|
||||
### 分页机制和分段机制有哪些共同点和区别?
|
||||
|
||||
**共同点** :
|
||||
**共同点**:
|
||||
|
||||
- 都是非连续内存管理的方式。
|
||||
- 都采用了地址映射的方法,将虚拟地址映射到物理地址,以实现对内存的管理和保护。
|
||||
|
||||
**区别** :
|
||||
**区别**:
|
||||
|
||||
- 分页机制以页面为单位进行内存管理,而分段机制以段为单位进行内存管理。页的大小是固定的,由操作系统决定,通常为 2 的幂次方。而段的大小不固定,取决于我们当前运行的程序。
|
||||
- 页是物理单位,即操作系统将物理内存划分成固定大小的页面,每个页面的大小通常是 2 的幂次方,例如 4KB、8KB 等等。而段则是逻辑单位,是为了满足程序对内存空间的逻辑需求而设计的,通常根据程序中数据和代码的逻辑结构来划分。
|
||||
|
|
@ -332,8 +332,8 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
|
|||
|
||||
在分页机制中,页表的作用是将虚拟地址转换为物理地址,从而完成内存访问。在这个过程中,局部性原理的作用体现在两个方面:
|
||||
|
||||
- **时间局部性** :由于程序中存在一定的循环或者重复操作,因此会反复访问同一个页或一些特定的页,这就体现了时间局部性的特点。为了利用时间局部性,分页机制中通常采用缓存机制来提高页面的命中率,即将最近访问过的一些页放入缓存中,如果下一次访问的页已经在缓存中,就不需要再次访问内存,而是直接从缓存中读取。
|
||||
- **空间局部性** :由于程序中数据和指令的访问通常是具有一定的空间连续性的,因此当访问某个页时,往往会顺带访问其相邻的一些页。为了利用空间局部性,分页机制中通常采用预取技术来预先将相邻的一些页读入内存缓存中,以便在未来访问时能够直接使用,从而提高访问速度。
|
||||
- **时间局部性**:由于程序中存在一定的循环或者重复操作,因此会反复访问同一个页或一些特定的页,这就体现了时间局部性的特点。为了利用时间局部性,分页机制中通常采用缓存机制来提高页面的命中率,即将最近访问过的一些页放入缓存中,如果下一次访问的页已经在缓存中,就不需要再次访问内存,而是直接从缓存中读取。
|
||||
- **空间局部性**:由于程序中数据和指令的访问通常是具有一定的空间连续性的,因此当访问某个页时,往往会顺带访问其相邻的一些页。为了利用空间局部性,分页机制中通常采用预取技术来预先将相邻的一些页读入内存缓存中,以便在未来访问时能够直接使用,从而提高访问速度。
|
||||
|
||||
总之,局部性原理是计算机体系结构设计的重要原则之一,也是许多优化算法的基础。在分页机制中,利用时间局部性和空间局部性,采用缓存和预取技术,可以提高页面的命中率,从而提高内存访问效率
|
||||
|
||||
|
|
@ -343,10 +343,10 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
|
|||
|
||||
文件系统主要负责管理和组织计算机存储设备上的文件和目录,其功能包括以下几个方面:
|
||||
|
||||
1. **存储管理** :将文件数据存储到物理存储介质中,并且管理空间分配,以确保每个文件都有足够的空间存储,并避免文件之间发生冲突。
|
||||
2. **文件管理** :文件的创建、删除、移动、重命名、压缩、加密、共享等等。
|
||||
3. **目录管理** :目录的创建、删除、移动、重命名等等。
|
||||
4. **文件访问控制** :管理不同用户或进程对文件的访问权限,以确保用户只能访问其被授权访问的文件,以保证文件的安全性和保密性。
|
||||
1. **存储管理**:将文件数据存储到物理存储介质中,并且管理空间分配,以确保每个文件都有足够的空间存储,并避免文件之间发生冲突。
|
||||
2. **文件管理**:文件的创建、删除、移动、重命名、压缩、加密、共享等等。
|
||||
3. **目录管理**:目录的创建、删除、移动、重命名等等。
|
||||
4. **文件访问控制**:管理不同用户或进程对文件的访问权限,以确保用户只能访问其被授权访问的文件,以保证文件的安全性和保密性。
|
||||
|
||||
### 硬链接和软链接有什么区别?
|
||||
|
||||
|
|
@ -375,11 +375,11 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
|
|||
|
||||
### 提高文件系统性能的方式有哪些?
|
||||
|
||||
- **优化硬件** :使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
|
||||
- **选择合适的文件系统选型** :不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
|
||||
- **运用缓存** :访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
|
||||
- **避免磁盘过度使用** :注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
|
||||
- **对磁盘进行合理的分区** :合理的磁盘分区方案,能够使文件系统在不同的区域存储文件,从而减少文件碎片,提高文件读写性能。
|
||||
- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
|
||||
- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
|
||||
- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
|
||||
- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
|
||||
- **对磁盘进行合理的分区**:合理的磁盘分区方案,能够使文件系统在不同的区域存储文件,从而减少文件碎片,提高文件读写性能。
|
||||
|
||||
### 常见的磁盘调度算法有哪些?
|
||||
|
||||
|
|
@ -391,12 +391,12 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
|
|||
|
||||
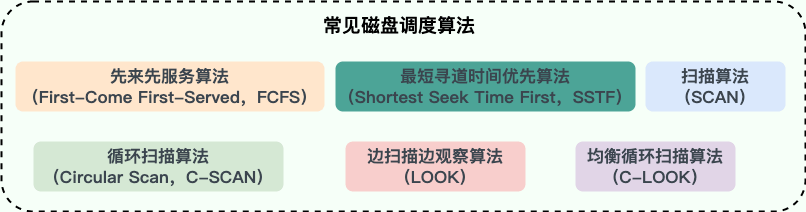
|
||||
|
||||
1. **先来先服务算法(First-Come First-Served,FCFS)** :按照请求到达磁盘调度器的顺序进行处理,先到达的请求的先被服务。FCFS 算法实现起来比较简单,不存在算法开销。不过,由于没有考虑磁头移动的路径和方向,平均寻道时间较长。同时,该算法容易出现饥饿问题,即一些后到的磁盘请求可能需要等待很长时间才能得到服务。
|
||||
2. **最短寻道时间优先算法(Shortest Seek Time First,SSTF)** :也被称为最佳服务优先(Shortest Service Time First,SSTF)算法,优先选择距离当前磁头位置最近的请求进行服务。SSTF 算法能够最小化磁头的寻道时间,但容易出现饥饿问题,即磁头附近的请求不断被服务,远离磁头的请求长时间得不到响应。实际应用中,需要优化一下该算法的实现,避免出现饥饿问题。
|
||||
3. **扫描算法(SCAN)** :也被称为电梯(Elevator)算法,基本思想和电梯非常类似。磁头沿着一个方向扫描磁盘,如果经过的磁道有请求就处理,直到到达磁盘的边界,然后改变移动方向,依此往复。SCAN 算法能够保证所有的请求得到服务,解决了饥饿问题。但是,如果磁头从一个方向刚扫描完,请求才到的话。这个请求就需要等到磁头从相反方向过来之后才能得到处理。
|
||||
4. **循环扫描算法(Circular Scan,C-SCAN)** :SCAN 算法的变体,只在磁盘的一侧进行扫描,并且只按照一个方向扫描,直到到达磁盘边界,然后回到磁盘起点,重新开始循环。
|
||||
5. **边扫描边观察算法(LOOK)** :SCAN 算法中磁头到了磁盘的边界才改变移动方向,这样可能会做很多无用功,因为磁头移动方向上可能已经没有请求需要处理了。LOOK 算法对 SCAN 算法进行了改进,如果磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向,依此往复。也就是边扫描边观察指定方向上还有无请求,因此叫 LOOK。
|
||||
6. **均衡循环扫描算法(C-LOOK)** :C-SCAN 只有到达磁盘边界时才能改变磁头移动方向,并且磁头返回时也需要返回到磁盘起点,这样可能会做很多无用功。C-LOOK 算法对 C-SCAN 算法进行了改进,如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。
|
||||
1. **先来先服务算法(First-Come First-Served,FCFS)**:按照请求到达磁盘调度器的顺序进行处理,先到达的请求的先被服务。FCFS 算法实现起来比较简单,不存在算法开销。不过,由于没有考虑磁头移动的路径和方向,平均寻道时间较长。同时,该算法容易出现饥饿问题,即一些后到的磁盘请求可能需要等待很长时间才能得到服务。
|
||||
2. **最短寻道时间优先算法(Shortest Seek Time First,SSTF)**:也被称为最佳服务优先(Shortest Service Time First,SSTF)算法,优先选择距离当前磁头位置最近的请求进行服务。SSTF 算法能够最小化磁头的寻道时间,但容易出现饥饿问题,即磁头附近的请求不断被服务,远离磁头的请求长时间得不到响应。实际应用中,需要优化一下该算法的实现,避免出现饥饿问题。
|
||||
3. **扫描算法(SCAN)**:也被称为电梯(Elevator)算法,基本思想和电梯非常类似。磁头沿着一个方向扫描磁盘,如果经过的磁道有请求就处理,直到到达磁盘的边界,然后改变移动方向,依此往复。SCAN 算法能够保证所有的请求得到服务,解决了饥饿问题。但是,如果磁头从一个方向刚扫描完,请求才到的话。这个请求就需要等到磁头从相反方向过来之后才能得到处理。
|
||||
4. **循环扫描算法(Circular Scan,C-SCAN)**:SCAN 算法的变体,只在磁盘的一侧进行扫描,并且只按照一个方向扫描,直到到达磁盘边界,然后回到磁盘起点,重新开始循环。
|
||||
5. **边扫描边观察算法(LOOK)**:SCAN 算法中磁头到了磁盘的边界才改变移动方向,这样可能会做很多无用功,因为磁头移动方向上可能已经没有请求需要处理了。LOOK 算法对 SCAN 算法进行了改进,如果磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向,依此往复。也就是边扫描边观察指定方向上还有无请求,因此叫 LOOK。
|
||||
6. **均衡循环扫描算法(C-LOOK)**:C-SCAN 只有到达磁盘边界时才能改变磁头移动方向,并且磁头返回时也需要返回到磁盘起点,这样可能会做很多无用功。C-LOOK 算法对 C-SCAN 算法进行了改进,如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。
|
||||
|
||||
## 参考
|
||||
|
||||
|
|
@ -404,7 +404,7 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
|
|||
- 《深入理解计算机系统》
|
||||
- 《重学操作系统》
|
||||
- 《现代操作系统原理与实现》
|
||||
- 王道考研操作系统知识点整理: https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html
|
||||
- 王道考研操作系统知识点整理:https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html
|
||||
- 内存管理之伙伴系统与 SLAB:https://blog.csdn.net/qq_44272681/article/details/124199068
|
||||
- 为什么 Linux 需要虚拟内存:https://draveness.me/whys-the-design-os-virtual-memory/
|
||||
- 程序员的自我修养(七):内存缺页错误:https://liam.page/2017/09/01/page-fault/
|
||||
|
|
|
|||
|
|
@ -69,7 +69,7 @@ shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会
|
|||
|
||||
1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
|
||||
2. **Linux 已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而 set 命令既可以查看环境变量也可以查看自定义变量。
|
||||
3. **Shell 变量** :Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
|
||||
3. **Shell 变量**:Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
|
||||
|
||||
**常用的环境变量:**
|
||||
|
||||
|
|
@ -242,7 +242,7 @@ echo $length2 #输出:5
|
|||
# 输出数组第三个元素
|
||||
echo ${array[2]} #输出:3
|
||||
unset array[1]# 删除下标为1的元素也就是删除第二个元素
|
||||
for i in ${array[@]};do echo $i ;done # 遍历数组,输出: 1 3 4 5
|
||||
for i in ${array[@]};do echo $i ;done # 遍历数组,输出:1 3 4 5
|
||||
unset array; # 删除数组中的所有元素
|
||||
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
|
||||
```
|
||||
|
|
|
|||
|
|
@ -16,12 +16,12 @@ tag:
|
|||
|
||||
## 什么是元组, 码, 候选码, 主码, 外码, 主属性, 非主属性?
|
||||
|
||||
- **元组** : 元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
|
||||
- **码** :码就是能唯一标识实体的属性,对应表中的列。
|
||||
- **候选码** : 若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
|
||||
- **元组**:元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
|
||||
- **码**:码就是能唯一标识实体的属性,对应表中的列。
|
||||
- **候选码**:若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
|
||||
- **主码** : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。
|
||||
- **外码** : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
|
||||
- **主属性** : 候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
|
||||
- **主属性**:候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
|
||||
- **非主属性:** 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
|
||||
|
||||
## 什么是 ER 图?
|
||||
|
|
@ -32,9 +32,9 @@ tag:
|
|||
|
||||
ER 图由下面 3 个要素组成:
|
||||
|
||||
- **实体** :通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
|
||||
- **属性** :即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
|
||||
- **联系** :即实体与实体之间的关系,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
|
||||
- **实体**:通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
|
||||
- **属性**:即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
|
||||
- **联系**:即实体与实体之间的关系,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
|
||||
|
||||
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
|
||||
|
||||
|
|
@ -60,10 +60,10 @@ ER 图由下面 3 个要素组成:
|
|||
|
||||
一些重要的概念:
|
||||
|
||||
- **函数依赖(functional dependency)** :若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
|
||||
- **部分函数依赖(partial functional dependency)** :如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
|
||||
- **完全函数依赖(Full functional dependency)** :在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
|
||||
- **传递函数依赖** : 在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
|
||||
- **函数依赖(functional dependency)**:若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
|
||||
- **部分函数依赖(partial functional dependency)**:如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
|
||||
- **完全函数依赖(Full functional dependency)**:在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
|
||||
- **传递函数依赖**:在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
|
||||
|
||||
### 3NF(第三范式)
|
||||
|
||||
|
|
@ -71,8 +71,8 @@ ER 图由下面 3 个要素组成:
|
|||
|
||||
## 主键和外键有什么区别?
|
||||
|
||||
- **主键(主码)** :主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
|
||||
- **外键(外码)** :外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
|
||||
- **主键(主码)**:主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
|
||||
- **外键(外码)**:外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
|
||||
|
||||
## 为什么不推荐使用外键与级联?
|
||||
|
||||
|
|
@ -85,8 +85,8 @@ ER 图由下面 3 个要素组成:
|
|||
为什么不要用外键呢?大部分人可能会这样回答:
|
||||
|
||||
1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
|
||||
2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
|
||||
3. **对分库分表不友好** :因为分库分表下外键是无法生效的。
|
||||
2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
|
||||
3. **对分库分表不友好**:因为分库分表下外键是无法生效的。
|
||||
4. ......
|
||||
|
||||
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
|
||||
|
|
|
|||
|
|
@ -76,7 +76,7 @@ BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
|
|||
|
||||
|
||||
|
||||
这样我们就搞懂了乱码的本质: **编码和解码时用了不同或者不兼容的字符集** 。
|
||||
这样我们就搞懂了乱码的本质:**编码和解码时用了不同或者不兼容的字符集** 。
|
||||
|
||||
|
||||
|
||||
|
|
@ -112,8 +112,8 @@ MySQL 支持很多种字符编码的方式,比如 UTF-8、GB2312、GBK、BIG5
|
|||
|
||||
MySQL 字符编码集中有两套 UTF-8 编码实现:
|
||||
|
||||
- **`utf8`** : `utf8`编码只支持`1-3`个字节 。 在 `utf8` 编码中,中文是占 3 个字节,其他数字、英文、符号占一个字节。但 emoji 符号占 4 个字节,一些较复杂的文字、繁体字也是 4 个字节。
|
||||
- **`utf8mb4`** : UTF-8 的完整实现,正版!最多支持使用 4 个字节表示字符,因此,可以用来存储 emoji 符号。
|
||||
- **`utf8`**:`utf8`编码只支持`1-3`个字节 。 在 `utf8` 编码中,中文是占 3 个字节,其他数字、英文、符号占一个字节。但 emoji 符号占 4 个字节,一些较复杂的文字、繁体字也是 4 个字节。
|
||||
- **`utf8mb4`**:UTF-8 的完整实现,正版!最多支持使用 4 个字节表示字符,因此,可以用来存储 emoji 符号。
|
||||
|
||||
**为什么有两套 UTF-8 编码实现呢?** 原因如下:
|
||||
|
||||
|
|
@ -151,7 +151,7 @@ Incorrect string value: '\xF0\x9F\x98\x98\xF0\x9F...' for column 'name' at row 1
|
|||
|
||||
## 参考
|
||||
|
||||
- 字符集和字符编码(Charset & Encoding): <https://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html>
|
||||
- 字符集和字符编码(Charset & Encoding):<https://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html>
|
||||
- 十分钟搞清字符集和字符编码:<http://cenalulu.github.io/linux/character-encoding/>
|
||||
- Unicode-维基百科:<https://zh.wikipedia.org/wiki/Unicode>
|
||||
- GB2312-维基百科:<https://zh.wikipedia.org/wiki/GB_2312>
|
||||
|
|
|
|||
|
|
@ -6,8 +6,8 @@ tag:
|
|||
- Elasticsearch
|
||||
---
|
||||
|
||||
**Elasticsearch** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中。
|
||||
**Elasticsearch** 相关的面试题为我的[知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
|
||||
|
||||
|
||||
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -20,13 +20,13 @@ MongoDB 是一个基于 **分布式文件存储** 的开源 NoSQL 数据库系
|
|||
|
||||
MongoDB 的存储结构区别于传统的关系型数据库,主要由如下三个单元组成:
|
||||
|
||||
- **文档(Document)** :MongoDB 中最基本的单元,由 BSON 键值对(key-value)组成,类似于关系型数据库中的行(Row)。
|
||||
- **集合(Collection)** :一个集合可以包含多个文档,类似于关系型数据库中的表(Table)。
|
||||
- **数据库(Database)** :一个数据库中可以包含多个集合,可以在 MongoDB 中创建多个数据库,类似于关系型数据库中的数据库(Database)。
|
||||
- **文档(Document)**:MongoDB 中最基本的单元,由 BSON 键值对(key-value)组成,类似于关系型数据库中的行(Row)。
|
||||
- **集合(Collection)**:一个集合可以包含多个文档,类似于关系型数据库中的表(Table)。
|
||||
- **数据库(Database)**:一个数据库中可以包含多个集合,可以在 MongoDB 中创建多个数据库,类似于关系型数据库中的数据库(Database)。
|
||||
|
||||
也就是说,MongoDB 将数据记录存储为文档 (更具体来说是[BSON 文档](https://www.mongodb.com/docs/manual/core/document/#std-label-bson-document-format)),这些文档在集合中聚集在一起,数据库中存储一个或多个文档集合。
|
||||
|
||||
**SQL 与 MongoDB 常见术语对比** :
|
||||
**SQL 与 MongoDB 常见术语对比**:
|
||||
|
||||
| SQL | MongoDB |
|
||||
| ------------------------ | ------------------------------- |
|
||||
|
|
@ -95,17 +95,17 @@ MongoDB 预留了几个特殊的数据库。
|
|||
|
||||
### MongoDB 有什么特点?
|
||||
|
||||
- **数据记录被存储为文档** :MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
|
||||
- **模式自由** :集合的概念类似 MySQL 里的表,但它不需要定义任何模式,能够用更少的数据对象表现复杂的领域模型对象。
|
||||
- **支持多种查询方式** :MongoDB 查询 API 支持读写操作 (CRUD)以及数据聚合、文本搜索和地理空间查询。
|
||||
- **支持 ACID 事务** :NoSQL 数据库通常不支持事务,为了可扩展和高性能进行了权衡。不过,也有例外,MongoDB 就支持事务。与关系型数据库一样,MongoDB 事务同样具有 ACID 特性。MongoDB 单文档原生支持原子性,也具备事务的特性。MongoDB 4.0 加入了对多文档事务的支持,但只支持复制集部署模式下的事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了分布式事务,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
|
||||
- **高效的二进制存储** :存储在集合中的文档,是以键值对的形式存在的。键用于唯一标识一个文档,一般是 ObjectId 类型,值是以 BSON 形式存在的。BSON = Binary JSON, 是在 JSON 基础上加了一些类型及元数据描述的格式。
|
||||
- **自带数据压缩功能** :存储同样的数据所需的资源更少。
|
||||
- **支持 mapreduce** :通过分治的方式完成复杂的聚合任务。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
|
||||
- **支持多种类型的索引** :MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
|
||||
- **支持 failover** :提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
|
||||
- **支持分片集群** :MongoDB 支持集群自动切分数据,让集群存储更多的数据,具备更强的性能。在数据插入和更新时,能够自动路由和存储。
|
||||
- **支持存储大文件** :MongoDB 的单文档存储空间要求不超过 16MB。对于超过 16MB 的大文件,MongoDB 提供了 GridFS 来进行存储,通过 GridFS,可以将大型数据进行分块处理,然后将这些切分后的小文档保存在数据库中。
|
||||
- **数据记录被存储为文档**:MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
|
||||
- **模式自由**:集合的概念类似 MySQL 里的表,但它不需要定义任何模式,能够用更少的数据对象表现复杂的领域模型对象。
|
||||
- **支持多种查询方式**:MongoDB 查询 API 支持读写操作 (CRUD)以及数据聚合、文本搜索和地理空间查询。
|
||||
- **支持 ACID 事务**:NoSQL 数据库通常不支持事务,为了可扩展和高性能进行了权衡。不过,也有例外,MongoDB 就支持事务。与关系型数据库一样,MongoDB 事务同样具有 ACID 特性。MongoDB 单文档原生支持原子性,也具备事务的特性。MongoDB 4.0 加入了对多文档事务的支持,但只支持复制集部署模式下的事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了分布式事务,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
|
||||
- **高效的二进制存储**:存储在集合中的文档,是以键值对的形式存在的。键用于唯一标识一个文档,一般是 ObjectId 类型,值是以 BSON 形式存在的。BSON = Binary JSON, 是在 JSON 基础上加了一些类型及元数据描述的格式。
|
||||
- **自带数据压缩功能**:存储同样的数据所需的资源更少。
|
||||
- **支持 mapreduce**:通过分治的方式完成复杂的聚合任务。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
|
||||
- **支持多种类型的索引**:MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
|
||||
- **支持 failover**:提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
|
||||
- **支持分片集群**:MongoDB 支持集群自动切分数据,让集群存储更多的数据,具备更强的性能。在数据插入和更新时,能够自动路由和存储。
|
||||
- **支持存储大文件**:MongoDB 的单文档存储空间要求不超过 16MB。对于超过 16MB 的大文件,MongoDB 提供了 GridFS 来进行存储,通过 GridFS,可以将大型数据进行分块处理,然后将这些切分后的小文档保存在数据库中。
|
||||
|
||||
### MongoDB 适合什么应用场景?
|
||||
|
||||
|
|
@ -132,8 +132,8 @@ MongoDB 预留了几个特殊的数据库。
|
|||
|
||||
现在主要有下面这两种存储引擎:
|
||||
|
||||
- **WiredTiger 存储引擎** :自 MongoDB 3.2 以后,默认的存储引擎为 [WiredTiger 存储引擎](https://www.mongodb.com/docs/manual/core/wiredtiger/) 。非常适合大多数工作负载,建议用于新部署。WiredTiger 提供文档级并发模型、检查点和数据压缩(后文会介绍到)等功能。
|
||||
- **In-Memory 存储引擎** :[In-Memory 存储引擎](https://www.mongodb.com/docs/manual/core/inmemory/)在 MongoDB Enterprise 中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中以获得更可预测的数据延迟。
|
||||
- **WiredTiger 存储引擎**:自 MongoDB 3.2 以后,默认的存储引擎为 [WiredTiger 存储引擎](https://www.mongodb.com/docs/manual/core/wiredtiger/) 。非常适合大多数工作负载,建议用于新部署。WiredTiger 提供文档级并发模型、检查点和数据压缩(后文会介绍到)等功能。
|
||||
- **In-Memory 存储引擎**:[In-Memory 存储引擎](https://www.mongodb.com/docs/manual/core/inmemory/)在 MongoDB Enterprise 中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中以获得更可预测的数据延迟。
|
||||
|
||||
此外,MongoDB 3.0 提供了 **可插拔的存储引擎 API** ,允许第三方为 MongoDB 开发存储引擎,这点和 MySQL 也比较类似。
|
||||
|
||||
|
|
@ -153,8 +153,8 @@ WiredTiger maintains a table's data in memory using a data structure called a B-
|
|||
|
||||
使用 B+ 树时,WiredTiger 以 **page** 为基本单位往磁盘读写数据。B+ 树的每个节点为一个 page,共有三种类型的 page:
|
||||
|
||||
- **root page(根节点)** : B+ 树的根节点。
|
||||
- **internal page(内部节点)** :不实际存储数据的中间索引节点。
|
||||
- **root page(根节点)**:B+ 树的根节点。
|
||||
- **internal page(内部节点)**:不实际存储数据的中间索引节点。
|
||||
- **leaf page(叶子节点)**:真正存储数据的叶子节点,包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的 checksum、块在磁盘上的寻址位置等信息。
|
||||
|
||||
其整体结构如下图所示:
|
||||
|
|
@ -179,8 +179,8 @@ WiredTiger maintains a table's data in memory using a data structure called a B-
|
|||
|
||||
MongoDB 提供了两种执行聚合的方法:
|
||||
|
||||
- **聚合管道(Aggregation Pipeline)** :执行聚合操作的首选方法。
|
||||
- **单一目的聚合方法(Single purpose aggregation methods)** :也就是单一作用的聚合函数比如 `count()`、`distinct()`、`estimatedDocumentCount()`。
|
||||
- **聚合管道(Aggregation Pipeline)**:执行聚合操作的首选方法。
|
||||
- **单一目的聚合方法(Single purpose aggregation methods)**:也就是单一作用的聚合函数比如 `count()`、`distinct()`、`estimatedDocumentCount()`。
|
||||
|
||||
绝大部分文章中还提到了 **map-reduce** 这种聚合方法。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
|
||||
|
||||
|
|
@ -194,7 +194,7 @@ MongoDB 聚合管道由多个阶段组成,每个阶段在文档通过管道时
|
|||
|
||||
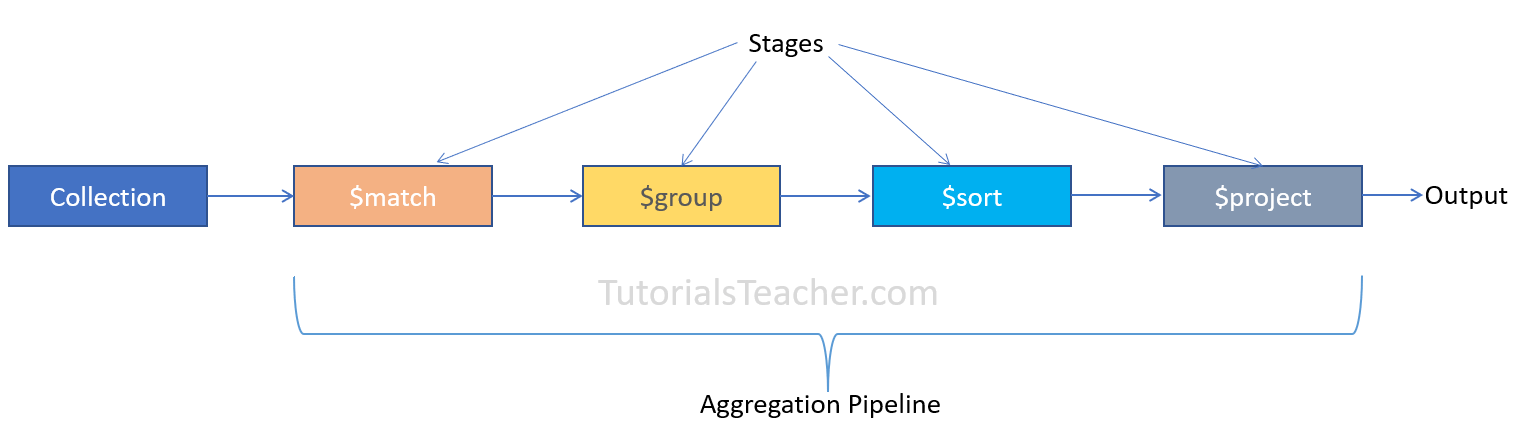
|
||||
|
||||
**常用阶段操作符** :
|
||||
**常用阶段操作符**:
|
||||
|
||||
| 操作符 | 简述 |
|
||||
| --------- | ---------------------------------------------------------------------------------------------------- |
|
||||
|
|
@ -208,7 +208,7 @@ MongoDB 聚合管道由多个阶段组成,每个阶段在文档通过管道时
|
|||
| \$unwind | 拆分操作符,用于将数组中的每一个值拆分为单独的文档 |
|
||||
| \$lookup | 连接操作符,用于连接同一个数据库中另一个集合,并获取指定的文档,类似于 populate |
|
||||
|
||||
更多操作符介绍详见官方文档:https://docs.mongodb.com/manual/reference/operator/aggregation/
|
||||
更多操作符介绍详见官方文档:<https://docs.mongodb.com/manual/reference/operator/aggregation/>
|
||||
|
||||
阶段操作符用于 `db.collection.aggregate` 方法里面,数组参数中的第一层。
|
||||
|
||||
|
|
@ -241,12 +241,12 @@ db.orders.aggregate([
|
|||
|
||||
与关系型数据库一样,MongoDB 事务同样具有 ACID 特性:
|
||||
|
||||
- **原子性**(`Atomicity`) : 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
- **一致性**(`Consistency`): 执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
|
||||
- **隔离性**(`Isolation`): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。WiredTiger 存储引擎支持读未提交( read-uncommitted )、读已提交( read-committed )和快照( snapshot )隔离,MongoDB 启动时默认选快照隔离。在不同隔离级别下,一个事务的生命周期内,可能出现脏读、不可重复读、幻读等现象。
|
||||
- **持久性**(`Durability`): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
- **原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
- **一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
|
||||
- **隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。WiredTiger 存储引擎支持读未提交( read-uncommitted )、读已提交( read-committed )和快照( snapshot )隔离,MongoDB 启动时默认选快照隔离。在不同隔离级别下,一个事务的生命周期内,可能出现脏读、不可重复读、幻读等现象。
|
||||
- **持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
|
||||
关于事务的详细介绍这篇文章就不多说了,感兴趣的可以看看我写的[MySQL 常见面试题总结](https://javaguide.cn/database/mysql/mysql-questions-01.html)这篇文章,里面有详细介绍到。
|
||||
关于事务的详细介绍这篇文章就不多说了,感兴趣的可以看看我写的[MySQL 常见面试题总结](../mysql/mysql-questions-01.md)这篇文章,里面有详细介绍到。
|
||||
|
||||
MongoDB 单文档原生支持原子性,也具备事务的特性。当谈论 MongoDB 事务的时候,通常指的是 **多文档** 。MongoDB 4.0 加入了对多文档 ACID 事务的支持,但只支持复制集部署模式下的 ACID 事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了 **分布式事务** ,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
|
||||
|
||||
|
|
@ -256,7 +256,7 @@ MongoDB 单文档原生支持原子性,也具备事务的特性。当谈论 Mo
|
|||
|
||||
在大多数情况下,多文档事务比单文档写入会产生更大的性能成本。对于大部分场景来说, [非规范化数据模型(嵌入式文档和数组)](https://www.mongodb.com/docs/upcoming/core/data-model-design/#std-label-data-modeling-embedding) 依然是最佳选择。也就是说,适当地对数据进行建模可以最大限度地减少对多文档事务的需求。
|
||||
|
||||
**注意** :
|
||||
**注意**:
|
||||
|
||||
- 从 MongoDB 4.2 开始,多文档事务支持副本集和分片集群,其中:主节点使用 WiredTiger 存储引擎,同时从节点使用 WiredTiger 存储引擎或 In-Memory 存储引擎。在 MongoDB 4.0 中,只有使用 WiredTiger 存储引擎的副本集支持事务。
|
||||
- 在 MongoDB 4.2 及更早版本中,你无法在事务中创建集合。从 MongoDB 4.4 开始,您可以在事务中创建集合和索引。有关详细信息,请参阅 [在事务中创建集合和索引](https://www.mongodb.com/docs/upcoming/core/transactions/#std-label-transactions-create-collections-indexes)。
|
||||
|
|
@ -276,9 +276,9 @@ WiredTiger 日志也会被压缩,默认使用的也是 Snappy 压缩算法。
|
|||
|
||||
## 参考
|
||||
|
||||
- MongoDB 官方文档(主要参考资料,以官方文档为准):https://www.mongodb.com/docs/manual/
|
||||
- MongoDB 官方文档(主要参考资料,以官方文档为准):<https://www.mongodb.com/docs/manual/>
|
||||
- 《MongoDB 权威指南》
|
||||
- 技术干货| MongoDB 事务原理 - MongoDB 中文社区:https://mongoing.com/archives/82187
|
||||
- Transactions - MongoDB 官方文档:https://www.mongodb.com/docs/manual/core/transactions/
|
||||
- WiredTiger Storage Engine - MongoDB 官方文档:https://www.mongodb.com/docs/manual/core/wiredtiger/
|
||||
- WiredTiger 存储引擎之一:基础数据结构分析:https://mongoing.com/topic/archives-35143
|
||||
- 技术干货| MongoDB 事务原理 - MongoDB 中文社区:<https://mongoing.com/archives/82187>
|
||||
- Transactions - MongoDB 官方文档:<https://www.mongodb.com/docs/manual/core/transactions/>
|
||||
- WiredTiger Storage Engine - MongoDB 官方文档:<https://www.mongodb.com/docs/manual/core/wiredtiger/>
|
||||
- WiredTiger 存储引擎之一:基础数据结构分析:<https://mongoing.com/topic/archives-35143>
|
||||
|
|
|
|||
|
|
@ -20,12 +20,12 @@ tag:
|
|||
|
||||
- **单字段索引:** 建立在单个字段上的索引,索引创建的排序顺序无所谓,MongoDB 可以头/尾开始遍历。
|
||||
- **复合索引:** 建立在多个字段上的索引,也可以称之为组合索引、联合索引。
|
||||
- **多键索引** :MongoDB 的一个字段可能是数组,在对这种字段创建索引时,就是多键索引。MongoDB 会为数组的每个值创建索引。就是说你可以按照数组里面的值做条件来查询,这个时候依然会走索引。
|
||||
- **哈希索引** :按数据的哈希值索引,用在哈希分片集群上。
|
||||
- **多键索引**:MongoDB 的一个字段可能是数组,在对这种字段创建索引时,就是多键索引。MongoDB 会为数组的每个值创建索引。就是说你可以按照数组里面的值做条件来查询,这个时候依然会走索引。
|
||||
- **哈希索引**:按数据的哈希值索引,用在哈希分片集群上。
|
||||
- **文本索引:** 支持对字符串内容的文本搜索查询。文本索引可以包含任何值为字符串或字符串元素数组的字段。一个集合只能有一个文本搜索索引,但该索引可以覆盖多个字段。MongoDB 虽然支持全文索引,但是性能低下,暂时不建议使用。
|
||||
- **地理位置索引:** 基于经纬度的索引,适合 2D 和 3D 的位置查询。
|
||||
- **唯一索引** :确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
|
||||
- **TTL 索引** :TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间,当一个文档达到预设的过期时间之后就会被删除。
|
||||
- **唯一索引**:确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
|
||||
- **TTL 索引**:TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间,当一个文档达到预设的过期时间之后就会被删除。
|
||||
- ......
|
||||
|
||||
### 复合索引中字段的顺序有影响吗?
|
||||
|
|
@ -62,7 +62,7 @@ db.s2.find().sort({"score": -1, "userid": 1}).explain()
|
|||
|
||||
### 复合索引遵循左前缀原则吗?
|
||||
|
||||
**MongoDB 的复合索引遵循左前缀原则** :拥有多个键的索引,可以同时得到所有这些键的前缀组成的索引,但不包括除左前缀之外的其他子集。比如说,有一个类似 `{a: 1, b: 1, c: 1, ..., z: 1}` 这样的索引,那么实际上也等于有了 `{a: 1}`、`{a: 1, b: 1}`、`{a: 1, b: 1, c: 1}` 等一系列索引,但是不会有 `{b: 1}` 这样的非左前缀的索引。
|
||||
**MongoDB 的复合索引遵循左前缀原则**:拥有多个键的索引,可以同时得到所有这些键的前缀组成的索引,但不包括除左前缀之外的其他子集。比如说,有一个类似 `{a: 1, b: 1, c: 1, ..., z: 1}` 这样的索引,那么实际上也等于有了 `{a: 1}`、`{a: 1, b: 1}`、`{a: 1, b: 1, c: 1}` 等一系列索引,但是不会有 `{b: 1}` 这样的非左前缀的索引。
|
||||
|
||||
### 什么是 TTL 索引?
|
||||
|
||||
|
|
@ -70,12 +70,12 @@ TTL 索引提供了一个过期机制,允许为每一个文档设置一个过
|
|||
|
||||
数据过期对于某些类型的信息很有用,比如机器生成的事件数据、日志和会话信息,这些信息只需要在数据库中保存有限的时间。
|
||||
|
||||
**TTL 索引运行原理** :
|
||||
**TTL 索引运行原理**:
|
||||
|
||||
- MongoDB 会开启一个后台线程读取该 TTL 索引的值来判断文档是否过期,但不会保证已过期的数据会立马被删除,因后台线程每 60 秒触发一次删除任务,且如果删除的数据量较大,会存在上一次的删除未完成,而下一次的任务已经开启的情况,导致过期的数据也会出现超过了数据保留时间 60 秒以上的现象。
|
||||
- 对于副本集而言,TTL 索引的后台进程只会在 Primary 节点开启,在从节点会始终处于空闲状态,从节点的数据删除是由主库删除后产生的 oplog 来做同步。
|
||||
|
||||
**TTL 索引限制** :
|
||||
**TTL 索引限制**:
|
||||
|
||||
- TTL 索引是单字段索引。复合索引不支持 TTL
|
||||
- `_id`字段不支持 TTL 索引。
|
||||
|
|
@ -131,9 +131,9 @@ MongoDB 的复制集群又称为副本集群,是一组维护相同数据集合
|
|||
|
||||
通常来说,一个复制集群包含 1 个主节点(Primary),多个从节点(Secondary)以及零个或 1 个仲裁节点(Arbiter)。
|
||||
|
||||
- **主节点** :整个集群的写操作入口,接收所有的写操作,并将集合所有的变化记录到操作日志中,即 oplog。主节点挂掉之后会自动选出新的主节点。
|
||||
- **从节点** :从主节点同步数据,在主节点挂掉之后选举新节点。不过,从节点可以配置成 0 优先级,阻止它在选举中成为主节点。
|
||||
- **仲裁节点** :这个是为了节约资源或者多机房容灾用,只负责主节点选举时投票不存数据,保证能有节点获得多数赞成票。
|
||||
- **主节点**:整个集群的写操作入口,接收所有的写操作,并将集合所有的变化记录到操作日志中,即 oplog。主节点挂掉之后会自动选出新的主节点。
|
||||
- **从节点**:从主节点同步数据,在主节点挂掉之后选举新节点。不过,从节点可以配置成 0 优先级,阻止它在选举中成为主节点。
|
||||
- **仲裁节点**:这个是为了节约资源或者多机房容灾用,只负责主节点选举时投票不存数据,保证能有节点获得多数赞成票。
|
||||
|
||||
下图是一个典型的三成员副本集群:
|
||||
|
||||
|
|
@ -151,8 +151,8 @@ MongoDB 的复制集群又称为副本集群,是一组维护相同数据集合
|
|||
|
||||
#### 为什么要用复制集群?
|
||||
|
||||
- **实现 failover** :提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
|
||||
- **实现读写分离** :我们可以设置从节点上可以读取数据,主节点负责写入数据,这样的话就实现了读写分离,减轻了主节点读写压力过大的问题。MongoDB 4.0 之前版本如果主库压力不大,不建议读写分离,因为写会阻塞读,除非业务对响应时间不是非常关注以及读取历史数据接受一定时间延迟。
|
||||
- **实现 failover**:提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
|
||||
- **实现读写分离**:我们可以设置从节点上可以读取数据,主节点负责写入数据,这样的话就实现了读写分离,减轻了主节点读写压力过大的问题。MongoDB 4.0 之前版本如果主库压力不大,不建议读写分离,因为写会阻塞读,除非业务对响应时间不是非常关注以及读取历史数据接受一定时间延迟。
|
||||
|
||||
### 分片集群
|
||||
|
||||
|
|
@ -207,14 +207,14 @@ MongoDB 的分片集群由如下三个部分组成(下图来源于[官方文
|
|||
|
||||
MongoDB 支持两种分片算法来满足不同的查询需求(摘自[MongoDB 分片集群介绍 - 阿里云文档](https://help.aliyun.com/document_detail/64561.html?spm=a2c4g.11186623.0.0.3121565eQhUGGB#h2--shard-key-3)):
|
||||
|
||||
**1、基于范围的分片** :
|
||||
**1、基于范围的分片**:
|
||||
|
||||
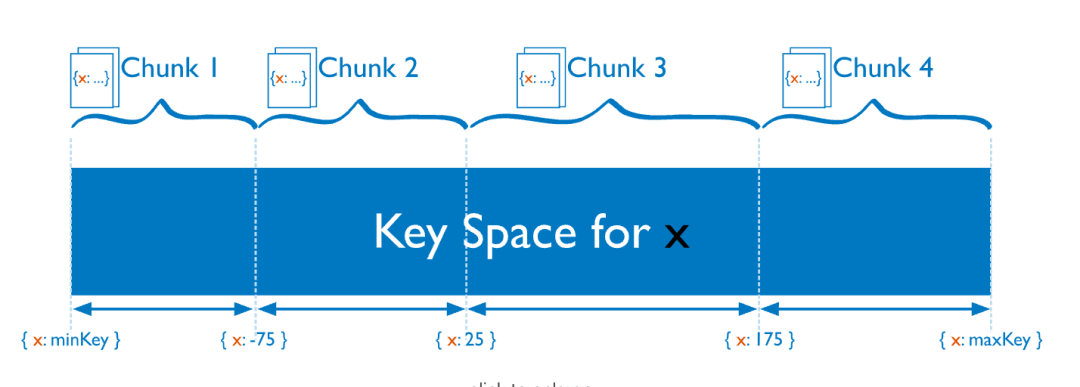
|
||||
|
||||
MongoDB 按照分片键(Shard Key)的值的范围将数据拆分为不同的块(Chunk),每个块包含了一段范围内的数据。当分片键的基数大、频率低且值非单调变更时,范围分片更高效。
|
||||
|
||||
- 优点: Mongos 可以快速定位请求需要的数据,并将请求转发到相应的 Shard 节点中。
|
||||
- 缺点: 可能导致数据在 Shard 节点上分布不均衡,容易造成读写热点,且不具备写分散性。
|
||||
- 优点:Mongos 可以快速定位请求需要的数据,并将请求转发到相应的 Shard 节点中。
|
||||
- 缺点:可能导致数据在 Shard 节点上分布不均衡,容易造成读写热点,且不具备写分散性。
|
||||
- 适用场景:分片键的值不是单调递增或单调递减、分片键的值基数大且重复的频率低、需要范围查询等业务场景。
|
||||
|
||||
**2、基于 Hash 值的分片**
|
||||
|
|
@ -259,15 +259,15 @@ Rebalance 操作是比较耗费系统资源的,我们可以通过在业务低
|
|||
|
||||
- [MongoDB 中文手册|官方文档中文版](https://docs.mongoing.com/)(推荐):基于 4.2 版本,不断与官方最新版保持同步。
|
||||
- [MongoDB 初学者教程——7 天学习 MongoDB](https://mongoing.com/archives/docs/mongodb%e5%88%9d%e5%ad%a6%e8%80%85%e6%95%99%e7%a8%8b/mongodb%e5%a6%82%e4%bd%95%e5%88%9b%e5%bb%ba%e6%95%b0%e6%8d%ae%e5%ba%93%e5%92%8c%e9%9b%86%e5%90%88):快速入门。
|
||||
- [SpringBoot 整合 MongoDB 实战 - 2022](https://www.cnblogs.com/dxflqm/p/16643981.html) :很不错的一篇 MongoDB 入门文章,主要围绕 MongoDB 的 Java 客户端使用进行基本的增删改查操作介绍。
|
||||
- [SpringBoot 整合 MongoDB 实战 - 2022](https://www.cnblogs.com/dxflqm/p/16643981.html):很不错的一篇 MongoDB 入门文章,主要围绕 MongoDB 的 Java 客户端使用进行基本的增删改查操作介绍。
|
||||
|
||||
## 参考
|
||||
|
||||
- MongoDB 官方文档(主要参考资料,以官方文档为准):https://www.mongodb.com/docs/manual/
|
||||
- MongoDB 官方文档(主要参考资料,以官方文档为准):<https://www.mongodb.com/docs/manual/>
|
||||
- 《MongoDB 权威指南》
|
||||
- Indexes - MongoDB 官方文档:https://www.mongodb.com/docs/manual/indexes/
|
||||
- MongoDB - 索引知识 - 程序员翔仔 - 2022:https://fatedeity.cn/posts/database/mongodb-index-knowledge.html
|
||||
- MongoDB - 索引: https://www.cnblogs.com/Neeo/articles/14325130.html
|
||||
- Sharding - MongoDB 官方文档:https://www.mongodb.com/docs/manual/sharding/
|
||||
- MongoDB 分片集群介绍 - 阿里云文档:https://help.aliyun.com/document_detail/64561.html
|
||||
- 分片集群使用注意事项 - - 腾讯云文档:https://cloud.tencent.com/document/product/240/44611
|
||||
- Indexes - MongoDB 官方文档:<https://www.mongodb.com/docs/manual/indexes/>
|
||||
- MongoDB - 索引知识 - 程序员翔仔 - 2022:<https://fatedeity.cn/posts/database/mongodb-index-knowledge.html>
|
||||
- MongoDB - 索引: <https://www.cnblogs.com/Neeo/articles/14325130.html>
|
||||
- Sharding - MongoDB 官方文档:<https://www.mongodb.com/docs/manual/sharding/>
|
||||
- MongoDB 分片集群介绍 - 阿里云文档:<https://help.aliyun.com/document_detail/64561.html>
|
||||
- 分片集群使用注意事项 - - 腾讯云文档:<https://cloud.tencent.com/document/product/240/44611>
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ tag:
|
|||
简单来说 MySQL 主要分为 Server 层和存储引擎层:
|
||||
|
||||
- **Server 层**:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binlog 日志模块。
|
||||
- **存储引擎**: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。**现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5 版本开始就被当做默认存储引擎了。**
|
||||
- **存储引擎**:主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。**现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5 版本开始就被当做默认存储引擎了。**
|
||||
|
||||
### 1.2 Server 层基本组件介绍
|
||||
|
||||
|
|
|
|||
|
|
@ -103,7 +103,7 @@ CALL pre_test1();
|
|||
|
||||
查阅 MySQL 相关文档发现是隐式转换造成的,看一下官方的描述:
|
||||
|
||||
> 官方文档: [12.2 Type Conversion in Expression Evaluation](https://dev.mysql.com/doc/refman/5.7/en/type-conversion.html?spm=5176.100239.blogcont47339.5.1FTben)
|
||||
> 官方文档:[12.2 Type Conversion in Expression Evaluation](https://dev.mysql.com/doc/refman/5.7/en/type-conversion.html?spm=5176.100239.blogcont47339.5.1FTben)
|
||||
>
|
||||
> 当操作符与不同类型的操作数一起使用时,会发生类型转换以使操作数兼容。某些转换是隐式发生的。例如,MySQL 会根据需要自动将字符串转换为数字,反之亦然。以下规则描述了比较操作的转换方式:
|
||||
>
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ tag:
|
|||
|
||||
### 一致性非锁定读
|
||||
|
||||
对于 [**一致性非锁定读(Consistent Nonlocking Reads)** ](https://dev.mysql.com/doc/refman/5.7/en/innodb-consistent-read.html)的实现,通常做法是加一个版本号或者时间戳字段,在更新数据的同时版本号 + 1 或者更新时间戳。查询时,将当前可见的版本号与对应记录的版本号进行比对,如果记录的版本小于可见版本,则表示该记录可见
|
||||
对于 [**一致性非锁定读(Consistent Nonlocking Reads)**](https://dev.mysql.com/doc/refman/5.7/en/innodb-consistent-read.html)的实现,通常做法是加一个版本号或者时间戳字段,在更新数据的同时版本号 + 1 或者更新时间戳。查询时,将当前可见的版本号与对应记录的版本号进行比对,如果记录的版本小于可见版本,则表示该记录可见
|
||||
|
||||
在 `InnoDB` 存储引擎中,[多版本控制 (multi versioning)](https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html) 就是对非锁定读的实现。如果读取的行正在执行 `DELETE` 或 `UPDATE` 操作,这时读取操作不会去等待行上锁的释放。相反地,`InnoDB` 存储引擎会去读取行的一个快照数据,对于这种读取历史数据的方式,我们叫它快照读 (snapshot read)
|
||||
|
||||
|
|
@ -83,15 +83,15 @@ private:
|
|||
- 当事务回滚时用于将数据恢复到修改前的样子
|
||||
- 另一个作用是 `MVCC` ,当读取记录时,若该记录被其他事务占用或当前版本对该事务不可见,则可以通过 `undo log` 读取之前的版本数据,以此实现非锁定读
|
||||
|
||||
**在 `InnoDB` 存储引擎中 `undo log` 分为两种: `insert undo log` 和 `update undo log`:**
|
||||
**在 `InnoDB` 存储引擎中 `undo log` 分为两种:`insert undo log` 和 `update undo log`:**
|
||||
|
||||
1. **`insert undo log`** :指在 `insert` 操作中产生的 `undo log`。因为 `insert` 操作的记录只对事务本身可见,对其他事务不可见,故该 `undo log` 可以在事务提交后直接删除。不需要进行 `purge` 操作
|
||||
1. **`insert undo log`**:指在 `insert` 操作中产生的 `undo log`。因为 `insert` 操作的记录只对事务本身可见,对其他事务不可见,故该 `undo log` 可以在事务提交后直接删除。不需要进行 `purge` 操作
|
||||
|
||||
**`insert` 时的数据初始状态:**
|
||||
|
||||

|
||||
|
||||
2. **`update undo log`** :`update` 或 `delete` 操作中产生的 `undo log`。该 `undo log`可能需要提供 `MVCC` 机制,因此不能在事务提交时就进行删除。提交时放入 `undo log` 链表,等待 `purge线程` 进行最后的删除
|
||||
2. **`update undo log`**:`update` 或 `delete` 操作中产生的 `undo log`。该 `undo log`可能需要提供 `MVCC` 机制,因此不能在事务提交时就进行删除。提交时放入 `undo log` 链表,等待 `purge线程` 进行最后的删除
|
||||
|
||||
**数据第一次被修改时:**
|
||||
|
||||
|
|
@ -190,7 +190,7 @@ private:
|
|||
|
||||

|
||||
|
||||
在 RR 级别下只会生成一次`Read View`,所以此时依然沿用 **`m_ids` :[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103
|
||||
在 RR 级别下只会生成一次`Read View`,所以此时依然沿用 **`m_ids`:[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103
|
||||
|
||||
- 最新记录的 `DB_TRX_ID` 为 102,m_up_limit_id <= 102 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
|
||||
|
||||
|
|
@ -204,7 +204,7 @@ private:
|
|||
|
||||

|
||||
|
||||
此时情况跟 T6 完全一样,由于已经生成了 `Read View`,此时依然沿用 **`m_ids` :[101,102]** ,所以查询结果依然是 `name = 菜花`
|
||||
此时情况跟 T6 完全一样,由于已经生成了 `Read View`,此时依然沿用 **`m_ids`:[101,102]** ,所以查询结果依然是 `name = 菜花`
|
||||
|
||||
## MVCC➕Next-key-Lock 防止幻读
|
||||
|
||||
|
|
|
|||
|
|
@ -32,7 +32,7 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
|
|||
参考文章:
|
||||
|
||||
- [MySQL 字符集不一致导致索引失效的一个真实案例](https://blog.csdn.net/horses/article/details/107243447)
|
||||
- [MySQL 字符集详解](https://javaguide.cn/database/character-set.html)
|
||||
- [MySQL 字符集详解](../character-set.md)
|
||||
|
||||
### 所有表和字段都需要添加注释
|
||||
|
||||
|
|
@ -90,7 +90,7 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
|
|||
|
||||
MySQL 提供了两个方法来处理 ip 地址
|
||||
|
||||
- `INET_ATON()` : 把 ip 转为无符号整型 (4-8 位)
|
||||
- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位)
|
||||
- `INET_NTOA()` :把整型的 ip 转为地址
|
||||
|
||||
插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
|
||||
|
|
@ -150,8 +150,8 @@ TIMESTAMP 占用 4 字节和 INT 相同,但比 INT 可读性高
|
|||
|
||||
### 同财务相关的金额类数据必须使用 decimal 类型
|
||||
|
||||
- **非精准浮点** :float,double
|
||||
- **精准浮点** :decimal
|
||||
- **非精准浮点**:float,double
|
||||
- **精准浮点**:decimal
|
||||
|
||||
decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据
|
||||
|
||||
|
|
|
|||
|
|
@ -21,12 +21,12 @@ tag:
|
|||
|
||||
## 索引的优缺点
|
||||
|
||||
**优点** :
|
||||
**优点**:
|
||||
|
||||
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
|
||||
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
|
||||
|
||||
**缺点** :
|
||||
**缺点**:
|
||||
|
||||
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
|
||||
- 索引需要使用物理文件存储,也会耗费一定空间。
|
||||
|
|
@ -131,11 +131,11 @@ MySQL 8.x 中实现的索引新特性:
|
|||
|
||||
PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
|
||||
|
||||
1. **唯一索引(Unique Key)** :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。** 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
|
||||
2. **普通索引(Index)** :**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。**
|
||||
3. **前缀索引(Prefix)** :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
|
||||
1. **唯一索引(Unique Key)**:唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。** 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
|
||||
2. **普通索引(Index)**:**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。**
|
||||
3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
|
||||
因为只取前几个字符。
|
||||
4. **全文索引(Full Text)** :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
|
||||
4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
|
||||
|
||||
二级索引:
|
||||
|
||||
|
|
@ -153,15 +153,15 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
|||
|
||||
#### 聚簇索引的优缺点
|
||||
|
||||
**优点** :
|
||||
**优点**:
|
||||
|
||||
- **查询速度非常快** :聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
|
||||
- **对排序查找和范围查找优化** :聚簇索引对于主键的排序查找和范围查找速度非常快。
|
||||
- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
|
||||
- **对排序查找和范围查找优化**:聚簇索引对于主键的排序查找和范围查找速度非常快。
|
||||
|
||||
**缺点** :
|
||||
**缺点**:
|
||||
|
||||
- **依赖于有序的数据** :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
|
||||
- **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
|
||||
- **依赖于有序的数据**:因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
|
||||
- **更新代价大**:如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
|
||||
|
||||
### 非聚簇索引(非聚集索引)
|
||||
|
||||
|
|
@ -173,14 +173,14 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
|||
|
||||
#### 非聚簇索引的优缺点
|
||||
|
||||
**优点** :
|
||||
**优点**:
|
||||
|
||||
更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的
|
||||
|
||||
**缺点** :
|
||||
**缺点**:
|
||||
|
||||
- **依赖于有序的数据** :跟聚簇索引一样,非聚簇索引也依赖于有序的数据
|
||||
- **可能会二次查询(回表)** :这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
|
||||
- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据
|
||||
- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
|
||||
|
||||
这是 MySQL 的表的文件截图:
|
||||
|
||||
|
|
@ -286,7 +286,7 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
|
|||
|
||||
通过 `Extra` 这一列的 `Using index` ,说明这条 SQL 语句成功使用了覆盖索引。
|
||||
|
||||
关于 `EXPLAIN` 命令的详细介绍请看:[MySQL 执行计划分析](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)这篇文章。
|
||||
关于 `EXPLAIN` 命令的详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
|
||||
|
||||
### 联合索引
|
||||
|
||||
|
|
@ -312,11 +312,11 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
|
|||
|
||||
### 选择合适的字段创建索引
|
||||
|
||||
- **不为 NULL 的字段** :索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
|
||||
- **被频繁查询的字段** :我们创建索引的字段应该是查询操作非常频繁的字段。
|
||||
- **被作为条件查询的字段** :被作为 WHERE 条件查询的字段,应该被考虑建立索引。
|
||||
- **频繁需要排序的字段** :索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
|
||||
- **被经常频繁用于连接的字段** :经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
|
||||
- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
|
||||
- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
|
||||
- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
|
||||
- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
|
||||
- **被经常频繁用于连接的字段**:经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
|
||||
|
||||
### 被频繁更新的字段应该慎重建立索引
|
||||
|
||||
|
|
@ -351,7 +351,7 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
|
|||
- 在索引列上进行计算、函数、类型转换等操作;
|
||||
- 以 `%` 开头的 LIKE 查询比如 `like '%abc'`;
|
||||
- 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
|
||||
- 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html);
|
||||
- 发生[隐式转换](./index-invalidation-caused-by-implicit-conversion.md);
|
||||
- ......
|
||||
|
||||
### 删除长期未使用的索引
|
||||
|
|
@ -395,4 +395,4 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
|
|||
| filtered | 按表条件过滤后,留存的记录数的百分比 |
|
||||
| Extra | 附加信息 |
|
||||
|
||||
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[MySQL 执行计划分析](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)这篇文章。
|
||||
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
|
||||
|
|
|
|||
|
|
@ -43,9 +43,9 @@ tag:
|
|||
|
||||
`InnoDB` 存储引擎为 `redo log` 的刷盘策略提供了 `innodb_flush_log_at_trx_commit` 参数,它支持三种策略:
|
||||
|
||||
- **0** :设置为 0 的时候,表示每次事务提交时不进行刷盘操作
|
||||
- **1** :设置为 1 的时候,表示每次事务提交时都将进行刷盘操作(默认值)
|
||||
- **2** :设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache
|
||||
- **0**:设置为 0 的时候,表示每次事务提交时不进行刷盘操作
|
||||
- **1**:设置为 1 的时候,表示每次事务提交时都将进行刷盘操作(默认值)
|
||||
- **2**:设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache
|
||||
|
||||
`innodb_flush_log_at_trx_commit` 参数默认为 1 ,也就是说当事务提交时会调用 `fsync` 对 redo log 进行刷盘
|
||||
|
||||
|
|
@ -118,7 +118,7 @@ tag:
|
|||
|
||||
相信大家都知道 `redo log` 的作用和它的刷盘时机、存储形式。
|
||||
|
||||
现在我们来思考一个问题: **只要每次把修改后的数据页直接刷盘不就好了,还有 `redo log` 什么事?**
|
||||
现在我们来思考一个问题:**只要每次把修改后的数据页直接刷盘不就好了,还有 `redo log` 什么事?**
|
||||
|
||||
它们不都是刷盘么?差别在哪里?
|
||||
|
||||
|
|
|
|||
|
|
@ -80,7 +80,7 @@ mysql> show variables like '%query_cache%';
|
|||
- **`query_cache_min_res_unit`:** 查询缓存分配的最小块的大小(字节)。当查询进行的时候,MySQL 把查询结果保存在查询缓存中,但如果要保存的结果比较大,超过 `query_cache_min_res_unit` 的值 ,这时候 MySQL 将一边检索结果,一边进行保存结果,也就是说,有可能在一次查询中,MySQL 要进行多次内存分配的操作。适当的调节 `query_cache_min_res_unit` 可以优化内存。
|
||||
- **`query_cache_size`:** 为缓存查询结果分配的内存的数量,单位是字节,且数值必须是 1024 的整数倍。默认值是 0,即禁用查询缓存。
|
||||
- **`query_cache_type`:** 设置查询缓存类型,默认为 ON。设置 GLOBAL 值可以设置后面的所有客户端连接的类型。客户端可以设置 SESSION 值以影响他们自己对查询缓存的使用。
|
||||
- **`query_cache_wlock_invalidate`** :如果某个表被锁住,是否返回缓存中的数据,默认关闭,也是建议的。
|
||||
- **`query_cache_wlock_invalidate`**:如果某个表被锁住,是否返回缓存中的数据,默认关闭,也是建议的。
|
||||
|
||||
`query_cache_type` 可能的值(修改 `query_cache_type` 需要重启 MySQL Server):
|
||||
|
||||
|
|
@ -88,7 +88,7 @@ mysql> show variables like '%query_cache%';
|
|||
- 1 或 ON:开启查询缓存功能,但不缓存 `Select SQL_NO_CACHE` 开头的查询。
|
||||
- 2 或 DEMAND:开启查询缓存功能,但仅缓存 `Select SQL_CACHE` 开头的查询。
|
||||
|
||||
**建议** :
|
||||
**建议**:
|
||||
|
||||
- `query_cache_size`不建议设置的过大。过大的空间不但挤占实例其他内存结构的空间,而且会增加在缓存中搜索的开销。建议根据实例规格,初始值设置为 10MB 到 100MB 之间的值,而后根据运行使用情况调整。
|
||||
- 建议通过调整 `query_cache_size` 的值来开启、关闭查询缓存,因为修改`query_cache_type` 参数需要重启 MySQL Server 生效。
|
||||
|
|
@ -109,7 +109,7 @@ set global query_cache_size=600000;
|
|||
|
||||
手动清理缓存可以使用下面三个 SQL:
|
||||
|
||||
- `flush query cache;` :清理查询缓存内存碎片。
|
||||
- `flush query cache;`:清理查询缓存内存碎片。
|
||||
- `reset query cache;`:从查询缓存中移除所有查询。
|
||||
- `flush tables;` 关闭所有打开的表,同时该操作会清空查询缓存中的内容。
|
||||
|
||||
|
|
@ -201,6 +201,6 @@ MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查
|
|||
## 参考
|
||||
|
||||
- 《高性能 MySQL》
|
||||
- MySQL 缓存机制:https://zhuanlan.zhihu.com/p/55947158
|
||||
- RDS MySQL 查询缓存(Query Cache)的设置和使用 - 阿里元云数据库 RDS 文档:https://help.aliyun.com/document_detail/41717.html
|
||||
- 8.10.3 The MySQL Query Cache - MySQL 官方文档:https://dev.mysql.com/doc/refman/5.7/en/query-cache.html
|
||||
- MySQL 缓存机制:<https://zhuanlan.zhihu.com/p/55947158>
|
||||
- RDS MySQL 查询缓存(Query Cache)的设置和使用 - 阿里元云数据库 RDS 文档:<https://help.aliyun.com/document_detail/41717.html>
|
||||
- 8.10.3 The MySQL Query Cache - MySQL 官方文档:<https://dev.mysql.com/doc/refman/5.7/en/query-cache.html>
|
||||
|
|
|
|||
|
|
@ -85,7 +85,7 @@ MySQL 主要具有下面这些优点:
|
|||
- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
|
||||
- **优化器:** 按照 MySQL 认为最优的方案去执行。
|
||||
- **执行器:** 执行语句,然后从存储引擎返回数据。 执行语句之前会先判断是否有权限,如果没有权限的话,就会报错。
|
||||
- **插件式存储引擎** : 主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。
|
||||
- **插件式存储引擎**:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。
|
||||
|
||||
## MySQL 存储引擎
|
||||
|
||||
|
|
@ -132,8 +132,8 @@ mysql> SHOW VARIABLES LIKE '%storage_engine%';
|
|||
|
||||
如果你想要深入了解每个存储引擎以及它们之间的区别,推荐你去阅读以下 MySQL 官方文档对应的介绍(面试不会问这么细,了解即可):
|
||||
|
||||
- InnoDB 存储引擎详细介绍:https://dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html 。
|
||||
- 其他存储引擎详细介绍:https://dev.mysql.com/doc/refman/8.0/en/storage-engines.html 。
|
||||
- InnoDB 存储引擎详细介绍:<https://dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html> 。
|
||||
- 其他存储引擎详细介绍:<https://dev.mysql.com/doc/refman/8.0/en/storage-engines.html> 。
|
||||
|
||||
|
||||
|
||||
|
|
@ -143,7 +143,7 @@ MySQL 存储引擎采用的是 **插件式架构** ,支持多种存储引擎
|
|||
|
||||
并且,你还可以根据 MySQL 定义的存储引擎实现标准接口来编写一个属于自己的存储引擎。这些非官方提供的存储引擎可以称为第三方存储引擎,区别于官方存储引擎。像目前最常用的 InnoDB 其实刚开始就是一个第三方存储引擎,后面由于过于优秀,其被 Oracle 直接收购了。
|
||||
|
||||
MySQL 官方文档也有介绍到如何编写一个自定义存储引擎,地址:https://dev.mysql.com/doc/internals/en/custom-engine.html 。
|
||||
MySQL 官方文档也有介绍到如何编写一个自定义存储引擎,地址:<https://dev.mysql.com/doc/internals/en/custom-engine.html> 。
|
||||
|
||||
### MyISAM 和 InnoDB 有什么区别?
|
||||
|
||||
|
|
@ -167,7 +167,7 @@ MyISAM 不提供事务支持。
|
|||
|
||||
InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别,具有提交(commit)和回滚(rollback)事务的能力。并且,InnoDB 默认使用的 REPEATABLE-READ(可重读)隔离级别是可以解决幻读问题发生的(基于 MVCC 和 Next-Key Lock)。
|
||||
|
||||
关于 MySQL 事务的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](https://javaguide.cn/database/mysql/transaction-isolation-level.html)。
|
||||
关于 MySQL 事务的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
|
||||
|
||||
**3.是否支持外键**
|
||||
|
||||
|
|
@ -201,7 +201,7 @@ MyISAM 不支持,而 InnoDB 支持。
|
|||
|
||||
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。
|
||||
|
||||
详细区别,推荐你看看我写的这篇文章:[MySQL 索引详解](https://javaguide.cn/database/mysql/mysql-index.html)。
|
||||
详细区别,推荐你看看我写的这篇文章:[MySQL 索引详解](./mysql-index.md)。
|
||||
|
||||
**7.性能有差别。**
|
||||
|
||||
|
|
@ -209,7 +209,7 @@ InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是
|
|||
|
||||
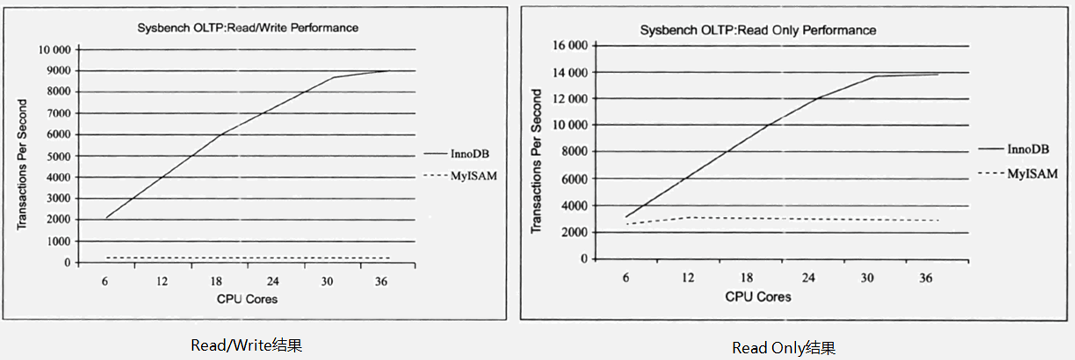
|
||||
|
||||
**总结** :
|
||||
**总结**:
|
||||
|
||||
- InnoDB 支持行级别的锁粒度,MyISAM 不支持,只支持表级别的锁粒度。
|
||||
- MyISAM 不提供事务支持。InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别。
|
||||
|
|
@ -237,7 +237,7 @@ InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是
|
|||
|
||||
## MySQL 索引
|
||||
|
||||
MySQL 索引相关的问题比较多,对于面试和工作都比较重要,于是,我单独抽了一篇文章专门来总结 MySQL 索引相关的知识点和问题: [MySQL 索引详解](https://javaguide.cn/database/mysql/mysql-index.html) 。
|
||||
MySQL 索引相关的问题比较多,对于面试和工作都比较重要,于是,我单独抽了一篇文章专门来总结 MySQL 索引相关的知识点和问题:[MySQL 索引详解](./mysql-index.md) 。
|
||||
|
||||
## MySQL 查询缓存
|
||||
|
||||
|
|
@ -282,7 +282,7 @@ SELECT sql_no_cache COUNT(*) FROM usr;
|
|||
- undo log 如何保证事务的原子性?
|
||||
- ......
|
||||
|
||||
上诉问题的答案可以在[《Java 面试指北》(付费)](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的 **「技术面试题篇」** 中找到。
|
||||
上诉问题的答案可以在[《Java 面试指北》(付费)](../../zhuanlan/java-mian-shi-zhi-bei.md) 的 **「技术面试题篇」** 中找到。
|
||||
|
||||

|
||||
|
||||
|
|
@ -335,10 +335,10 @@ COMMIT;
|
|||
|
||||
|
||||
|
||||
1. **原子性**(`Atomicity`) : 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **一致性**(`Consistency`): 执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
|
||||
3. **隔离性**(`Isolation`): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
4. **持久性**(`Durability`): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
1. **原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
|
||||
3. **隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
4. **持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
|
||||
🌈 这里要额外补充一点:**只有保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。也就是说 A、I、D 是手段,C 是目的!** 想必大家也和我一样,被 ACID 这个概念被误导了很久! 我也是看周志明老师的公开课[《周志明的软件架构课》](https://time.geekbang.org/opencourse/intro/100064201)才搞清楚的(多看好书!!!)。
|
||||
|
||||
|
|
@ -353,7 +353,7 @@ COMMIT;
|
|||
>
|
||||
> 翻译过来的意思是:原子性,隔离性和持久性是数据库的属性,而一致性(在 ACID 意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此,字母 C 不属于 ACID 。
|
||||
|
||||
《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 Github 开源,地址:[https://github.com/Vonng/ddia](https://github.com/Vonng/ddia) 。
|
||||
《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 GitHub 开源,地址:[https://github.com/Vonng/ddia](https://github.com/Vonng/ddia) 。
|
||||
|
||||

|
||||
|
||||
|
|
@ -408,8 +408,8 @@ MySQL 中并发事务的控制方式无非就两种:**锁** 和 **MVCC**。锁
|
|||
|
||||
**锁** 控制方式下会通过锁来显示控制共享资源而不是通过调度手段,MySQL 中主要是通过 **读写锁** 来实现并发控制。
|
||||
|
||||
- **共享锁(S 锁)** :又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
|
||||
- **排他锁(X 锁)** :又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条记录加任何类型的锁(锁不兼容)。
|
||||
- **共享锁(S 锁)**:又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
|
||||
- **排他锁(X 锁)**:又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条记录加任何类型的锁(锁不兼容)。
|
||||
|
||||
读写锁可以做到读读并行,但是无法做到写读、写写并行。另外,根据根据锁粒度的不同,又被分为 **表级锁(table-level locking)** 和 **行级锁(row-level locking)** 。InnoDB 不光支持表级锁,还支持行级锁,默认为行级锁。行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类。
|
||||
|
||||
|
|
@ -420,16 +420,16 @@ MVCC 在 MySQL 中实现所依赖的手段主要是: **隐藏字段、read view
|
|||
- undo log : undo log 用于记录某行数据的多个版本的数据。
|
||||
- read view 和 隐藏字段 : 用来判断当前版本数据的可见性。
|
||||
|
||||
关于 InnoDB 对 MVCC 的具体实现可以看这篇文章:[InnoDB 存储引擎对 MVCC 的实现](https://javaguide.cn/database/mysql/innodb-implementation-of-mvcc.html) 。
|
||||
关于 InnoDB 对 MVCC 的具体实现可以看这篇文章:[InnoDB 存储引擎对 MVCC 的实现](./innodb-implementation-of-mvcc.md) 。
|
||||
|
||||
### SQL 标准定义了哪些事务隔离级别?
|
||||
|
||||
SQL 标准定义了四个隔离级别:
|
||||
|
||||
- **READ-UNCOMMITTED(读取未提交)** : 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
|
||||
- **READ-COMMITTED(读取已提交)** : 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
|
||||
- **REPEATABLE-READ(可重复读)** : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
|
||||
- **SERIALIZABLE(可串行化)** : 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
|
||||
- **READ-UNCOMMITTED(读取未提交)**:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
|
||||
- **READ-COMMITTED(读取已提交)**:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
|
||||
- **REPEATABLE-READ(可重复读)**:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
|
||||
- **SERIALIZABLE(可串行化)**:最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
|
||||
|
||||
---
|
||||
|
||||
|
|
@ -459,7 +459,7 @@ mysql> SELECT @@tx_isolation;
|
|||
+-----------------+
|
||||
```
|
||||
|
||||
关于 MySQL 事务隔离级别的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](https://javaguide.cn/database/mysql/transaction-isolation-level.html)。
|
||||
关于 MySQL 事务隔离级别的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
|
||||
|
||||
## MySQL 锁
|
||||
|
||||
|
|
@ -471,7 +471,7 @@ MyISAM 仅仅支持表级锁(table-level locking),一锁就锁整张表,这
|
|||
|
||||
行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。
|
||||
|
||||
**表级锁和行级锁对比** :
|
||||
**表级锁和行级锁对比**:
|
||||
|
||||
- **表级锁:** MySQL 中锁定粒度最大的一种锁(全局锁除外),是针对非索引字段加的锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。不过,触发锁冲突的概率最高,高并发下效率极低。表级锁和存储引擎无关,MyISAM 和 InnoDB 引擎都支持表级锁。
|
||||
- **行级锁:** MySQL 中锁定粒度最小的一种锁,是 **针对索引字段加的锁** ,只针对当前操作的行记录进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。行级锁和存储引擎有关,是在存储引擎层面实现的。
|
||||
|
|
@ -486,9 +486,9 @@ InnoDB 的行锁是针对索引字段加的锁,表级锁是针对非索引字
|
|||
|
||||
InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL InnoDB 支持三种行锁定方式:
|
||||
|
||||
- **记录锁(Record Lock)** :也被称为记录锁,属于单个行记录上的锁。
|
||||
- **间隙锁(Gap Lock)** :锁定一个范围,不包括记录本身。
|
||||
- **临键锁(Next-Key Lock)** :Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
|
||||
- **记录锁(Record Lock)**:也被称为记录锁,属于单个行记录上的锁。
|
||||
- **间隙锁(Gap Lock)**:锁定一个范围,不包括记录本身。
|
||||
- **临键锁(Next-Key Lock)**:Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
|
||||
|
||||
**在 InnoDB 默认的隔离级别 REPEATABLE-READ 下,行锁默认使用的是 Next-Key Lock。但是,如果操作的索引是唯一索引或主键,InnoDB 会对 Next-Key Lock 进行优化,将其降级为 Record Lock,即仅锁住索引本身,而不是范围。**
|
||||
|
||||
|
|
@ -498,8 +498,8 @@ InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL Inno
|
|||
|
||||
不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类:
|
||||
|
||||
- **共享锁(S 锁)** :又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
|
||||
- **排他锁(X 锁)** :又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条事务加任何类型的锁(锁不兼容)。
|
||||
- **共享锁(S 锁)**:又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
|
||||
- **排他锁(X 锁)**:又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条事务加任何类型的锁(锁不兼容)。
|
||||
|
||||
排他锁与任何的锁都不兼容,共享锁仅和共享锁兼容。
|
||||
|
||||
|
|
@ -606,13 +606,13 @@ CREATE TABLE `sequence_id` (
|
|||
| 1 | 连续模式(MySQL 8.0 之前默认) |
|
||||
| 2 | 交错模式(MySQL 8.0 之后默认) |
|
||||
|
||||
交错模式下,所有的“INSERT-LIKE”语句(所有的插入语句,包括: `INSERT`、`REPLACE`、`INSERT…SELECT`、`REPLACE…SELECT`、`LOAD DATA`等)都不使用表级锁,使用的是轻量级互斥锁实现,多条插入语句可以并发执行,速度更快,扩展性也更好。
|
||||
交错模式下,所有的“INSERT-LIKE”语句(所有的插入语句,包括:`INSERT`、`REPLACE`、`INSERT…SELECT`、`REPLACE…SELECT`、`LOAD DATA`等)都不使用表级锁,使用的是轻量级互斥锁实现,多条插入语句可以并发执行,速度更快,扩展性也更好。
|
||||
|
||||
不过,如果你的 MySQL 数据库有主从同步需求并且 Binlog 存储格式为 Statement 的话,不要将 InnoDB 自增锁模式设置为交叉模式,不然会有数据不一致性问题。这是因为并发情况下插入语句的执行顺序就无法得到保障。
|
||||
|
||||
> 如果 MySQL 采用的格式为 Statement ,那么 MySQL 的主从同步实际上同步的就是一条一条的 SQL 语句。
|
||||
|
||||
最后,再推荐一篇文章: [为什么 MySQL 的自增主键不单调也不连续](https://draveness.me/whys-the-design-mysql-auto-increment/) 。
|
||||
最后,再推荐一篇文章:[为什么 MySQL 的自增主键不单调也不连续](https://draveness.me/whys-the-design-mysql-auto-increment/) 。
|
||||
|
||||
## MySQL 性能优化
|
||||
|
||||
|
|
@ -638,14 +638,14 @@ CREATE TABLE `sequence_id` (
|
|||
|
||||
MySQL 提供了两个方法来处理 ip 地址
|
||||
|
||||
- `INET_ATON()` : 把 ip 转为无符号整型 (4-8 位)
|
||||
- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位)
|
||||
- `INET_NTOA()` :把整型的 ip 转为地址
|
||||
|
||||
插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
|
||||
|
||||
### 有哪些常见的 SQL 优化手段?
|
||||
|
||||
[《Java 面试指北》(付费)](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的 **「技术面试题篇」** 有一篇文章详细介绍了常见的 SQL 优化手段,非常全面,清晰易懂!
|
||||
[《Java 面试指北》(付费)](../../zhuanlan/java-mian-shi-zhi-bei.md) 的 **「技术面试题篇」** 有一篇文章详细介绍了常见的 SQL 优化手段,非常全面,清晰易懂!
|
||||
|
||||

|
||||
|
||||
|
|
@ -688,15 +688,15 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
|
|||
| filtered | 按表条件过滤后,留存的记录数的百分比 |
|
||||
| Extra | 附加信息 |
|
||||
|
||||
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[SQL 的执行计划](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)这篇文章。
|
||||
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[SQL 的执行计划](./mysql-query-execution-plan.md)这篇文章。
|
||||
|
||||
### 读写分离和分库分表了解吗?
|
||||
|
||||
读写分离和分库分表相关的问题比较多,于是,我单独写了一篇文章来介绍: [读写分离和分库分表详解](https://javaguide.cn/high-performance/read-and-write-separation-and-library-subtable.html)。
|
||||
读写分离和分库分表相关的问题比较多,于是,我单独写了一篇文章来介绍:[读写分离和分库分表详解](../../high-performance/read-and-write-separation-and-library-subtable.md)。
|
||||
|
||||
## MySQL 学习资料推荐
|
||||
|
||||
**书籍推荐** :参见:[https://javaguide.cn/books/database.html#mysql](https://javaguide.cn/books/database.html#mysql) 。
|
||||
[**书籍推荐**](../../books/database.md#mysql) 。
|
||||
|
||||
**文章推荐** :
|
||||
|
||||
|
|
@ -711,12 +711,12 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
|
|||
|
||||
- 《高性能 MySQL》第 7 章 MySQL 高级特性
|
||||
- 《MySQL 技术内幕 InnoDB 存储引擎》第 6 章 锁
|
||||
- Relational Database:https://www.omnisci.com/technical-glossary/relational-database
|
||||
- 技术分享 | 隔离级别:正确理解幻读:https://opensource.actionsky.com/20210818-mysql/
|
||||
- MySQL Server Logs - MySQL 5.7 Reference Manual:https://dev.mysql.com/doc/refman/5.7/en/server-logs.html
|
||||
- Redo Log - MySQL 5.7 Reference Manual:https://dev.mysql.com/doc/refman/5.7/en/innodb-redo-log.html
|
||||
- Locking Reads - MySQL 5.7 Reference Manual:https://dev.mysql.com/doc/refman/5.7/en/innodb-locking-reads.html
|
||||
- 深入理解数据库行锁与表锁 https://zhuanlan.zhihu.com/p/52678870
|
||||
- 详解 MySQL InnoDB 中意向锁的作用:https://juejin.cn/post/6844903666332368909
|
||||
- 深入剖析 MySQL 自增锁:https://juejin.cn/post/6968420054287253540
|
||||
- 在数据库中不可重复读和幻读到底应该怎么分?:https://www.zhihu.com/question/392569386
|
||||
- Relational Database:<https://www.omnisci.com/technical-glossary/relational-database>
|
||||
- 技术分享 | 隔离级别:正确理解幻读:<https://opensource.actionsky.com/20210818-mysql/>
|
||||
- MySQL Server Logs - MySQL 5.7 Reference Manual:<https://dev.mysql.com/doc/refman/5.7/en/server-logs.html>
|
||||
- Redo Log - MySQL 5.7 Reference Manual:<https://dev.mysql.com/doc/refman/5.7/en/innodb-redo-log.html>
|
||||
- Locking Reads - MySQL 5.7 Reference Manual:<https://dev.mysql.com/doc/refman/5.7/en/innodb-locking-reads.html>
|
||||
- 深入理解数据库行锁与表锁 <https://zhuanlan.zhihu.com/p/52678870>
|
||||
- 详解 MySQL InnoDB 中意向锁的作用:<https://juejin.cn/post/6844903666332368909>
|
||||
- 深入剖析 MySQL 自增锁:<https://juejin.cn/post/6968420054287253540>
|
||||
- 在数据库中不可重复读和幻读到底应该怎么分?:<https://www.zhihu.com/question/392569386>
|
||||
|
|
|
|||
|
|
@ -102,8 +102,8 @@ SET GLOBAL time_zone = 'Europe/Helsinki';
|
|||
|
||||
Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
|
||||
|
||||
- DateTime :1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
|
||||
- Timestamp: 1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
|
||||
- DateTime:1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
|
||||
- Timestamp:1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
|
||||
|
||||
> Timestamp 在不同版本的 MySQL 中有细微差别。
|
||||
|
||||
|
|
|
|||
|
|
@ -13,10 +13,10 @@ tag:
|
|||
|
||||
SQL 标准定义了四个隔离级别:
|
||||
|
||||
- **READ-UNCOMMITTED(读取未提交)** : 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
|
||||
- **READ-COMMITTED(读取已提交)** : 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
|
||||
- **REPEATABLE-READ(可重复读)** : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
|
||||
- **SERIALIZABLE(可串行化)** : 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
|
||||
- **READ-UNCOMMITTED(读取未提交)**:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
|
||||
- **READ-COMMITTED(读取已提交)**:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
|
||||
- **REPEATABLE-READ(可重复读)**:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
|
||||
- **SERIALIZABLE(可串行化)**:最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
|
||||
|
||||
---
|
||||
|
||||
|
|
@ -42,8 +42,8 @@ MySQL> SELECT @@tx_isolation;
|
|||
|
||||
但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
|
||||
|
||||
- **快照读** :由 MVCC 机制来保证不出现幻读。
|
||||
- **当前读** : 使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
|
||||
- **快照读**:由 MVCC 机制来保证不出现幻读。
|
||||
- **当前读**:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
|
||||
|
||||
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ** 并不会有任何性能损失。
|
||||
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ NoSQL(Not Only SQL 的缩写)泛指非关系型的数据库,主要针对
|
|||
|
||||
一个常见的误解是 NoSQL 数据库或非关系型数据库不能很好地存储关系型数据。NoSQL 数据库可以存储关系型数据—它们与关系型数据库的存储方式不同。
|
||||
|
||||
NoSQL 数据库代表:HBase 、Cassandra、MongoDB、Redis。
|
||||
NoSQL 数据库代表:HBase、Cassandra、MongoDB、Redis。
|
||||
|
||||
|
||||
|
||||
|
|
@ -23,7 +23,7 @@ NoSQL 数据库代表:HBase 、Cassandra、MongoDB、Redis。
|
|||
| :----------- | -------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 数据存储模型 | 结构化存储,具有固定行和列的表格 | 非结构化存储。文档:JSON 文档,键值:键值对,宽列:包含行和动态列的表,图:节点和边 |
|
||||
| 发展历程 | 开发于 1970 年代,重点是减少数据重复 | 开发于 2000 年代后期,重点是提升可扩展性,减少大规模数据的存储成本 |
|
||||
| 例子 | Oracle、MySQL、Microsoft SQL Server 、PostgreSQL | 文档:MongoDB、CouchDB,键值:Redis 、DynamoDB,宽列:Cassandra 、 HBase,图表:Neo4j 、 Amazon Neptune、Giraph |
|
||||
| 例子 | Oracle、MySQL、Microsoft SQL Server、PostgreSQL | 文档:MongoDB、CouchDB,键值:Redis、DynamoDB,宽列:Cassandra、 HBase,图表:Neo4j、 Amazon Neptune、Giraph |
|
||||
| ACID 属性 | 提供原子性、一致性、隔离性和持久性 (ACID) 属性 | 通常不支持 ACID 事务,为了可扩展、高性能进行了权衡,少部分支持比如 MongoDB 。不过,MongoDB 对 ACID 事务 的支持和 MySQL 还是有所区别的。 |
|
||||
| 性能 | 性能通常取决于磁盘子系统。要获得最佳性能,通常需要优化查询、索引和表结构。 | 性能通常由底层硬件集群大小、网络延迟以及调用应用程序来决定。 |
|
||||
| 扩展 | 垂直(使用性能更强大的服务器进行扩展)、读写分离、分库分表 | 横向(增加服务器的方式横向扩展,通常是基于分片机制) |
|
||||
|
|
@ -43,10 +43,10 @@ NoSQL 数据库非常适合许多现代应用程序,例如移动、Web 和游
|
|||
|
||||
NoSQL 数据库主要可以分为下面四种类型:
|
||||
|
||||
- **键值** :键值数据库是一种较简单的数据库,其中每个项目都包含键和值。这是极为灵活的 NoSQL 数据库类型,因为应用可以完全控制 value 字段中存储的内容,没有任何限制。Redis 和 DynanoDB 是两款非常流行的键值数据库。
|
||||
- **文档** :文档数据库中的数据被存储在类似于 JSON(JavaScript 对象表示法)对象的文档中,非常清晰直观。每个文档包含成对的字段和值。这些值通常可以是各种类型,包括字符串、数字、布尔值、数组或对象等,并且它们的结构通常与开发者在代码中使用的对象保持一致。MongoDB 就是一款非常流行的文档数据库。
|
||||
- **图形** :图形数据库旨在轻松构建和运行与高度连接的数据集一起使用的应用程序。图形数据库的典型使用案例包括社交网络、推荐引擎、欺诈检测和知识图形。Neo4j 和 Giraph 是两款非常流行的图形数据库。
|
||||
- **宽列** :宽列存储数据库非常适合需要存储大量的数据。Cassandra 和 HBase 是两款非常流行的宽列存储数据库。
|
||||
- **键值**:键值数据库是一种较简单的数据库,其中每个项目都包含键和值。这是极为灵活的 NoSQL 数据库类型,因为应用可以完全控制 value 字段中存储的内容,没有任何限制。Redis 和 DynanoDB 是两款非常流行的键值数据库。
|
||||
- **文档**:文档数据库中的数据被存储在类似于 JSON(JavaScript 对象表示法)对象的文档中,非常清晰直观。每个文档包含成对的字段和值。这些值通常可以是各种类型,包括字符串、数字、布尔值、数组或对象等,并且它们的结构通常与开发者在代码中使用的对象保持一致。MongoDB 就是一款非常流行的文档数据库。
|
||||
- **图形**:图形数据库旨在轻松构建和运行与高度连接的数据集一起使用的应用程序。图形数据库的典型使用案例包括社交网络、推荐引擎、欺诈检测和知识图形。Neo4j 和 Giraph 是两款非常流行的图形数据库。
|
||||
- **宽列**:宽列存储数据库非常适合需要存储大量的数据。Cassandra 和 HBase 是两款非常流行的宽列存储数据库。
|
||||
|
||||
下面这张图片来源于 [微软的官方文档 | 关系数据与 NoSQL 数据](https://learn.microsoft.com/en-us/dotnet/architecture/cloud-native/relational-vs-nosql-data)。
|
||||
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
|
|||
|
||||
下面我们来看一下这个策略模式下的缓存读写步骤。
|
||||
|
||||
**写** :
|
||||
**写**:
|
||||
|
||||
- 先更新 db
|
||||
- 然后直接删除 cache 。
|
||||
|
|
@ -72,8 +72,8 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
|
|||
|
||||
解决办法:
|
||||
|
||||
- 数据库和缓存数据强一致场景 :更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
|
||||
- 可以短暂地允许数据库和缓存数据不一致的场景 :更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
|
||||
- 数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
|
||||
- 可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
|
||||
|
||||
### Read/Write Through Pattern(读写穿透)
|
||||
|
||||
|
|
|
|||
|
|
@ -5,8 +5,8 @@ tag:
|
|||
- Redis
|
||||
---
|
||||
|
||||
**缓存基础** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中。
|
||||
**缓存基础** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
|
||||
|
||||

|
||||
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -5,8 +5,8 @@ tag:
|
|||
- Redis
|
||||
---
|
||||
|
||||
**Redis 集群** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中。
|
||||
**Redis 集群** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
|
||||
|
||||
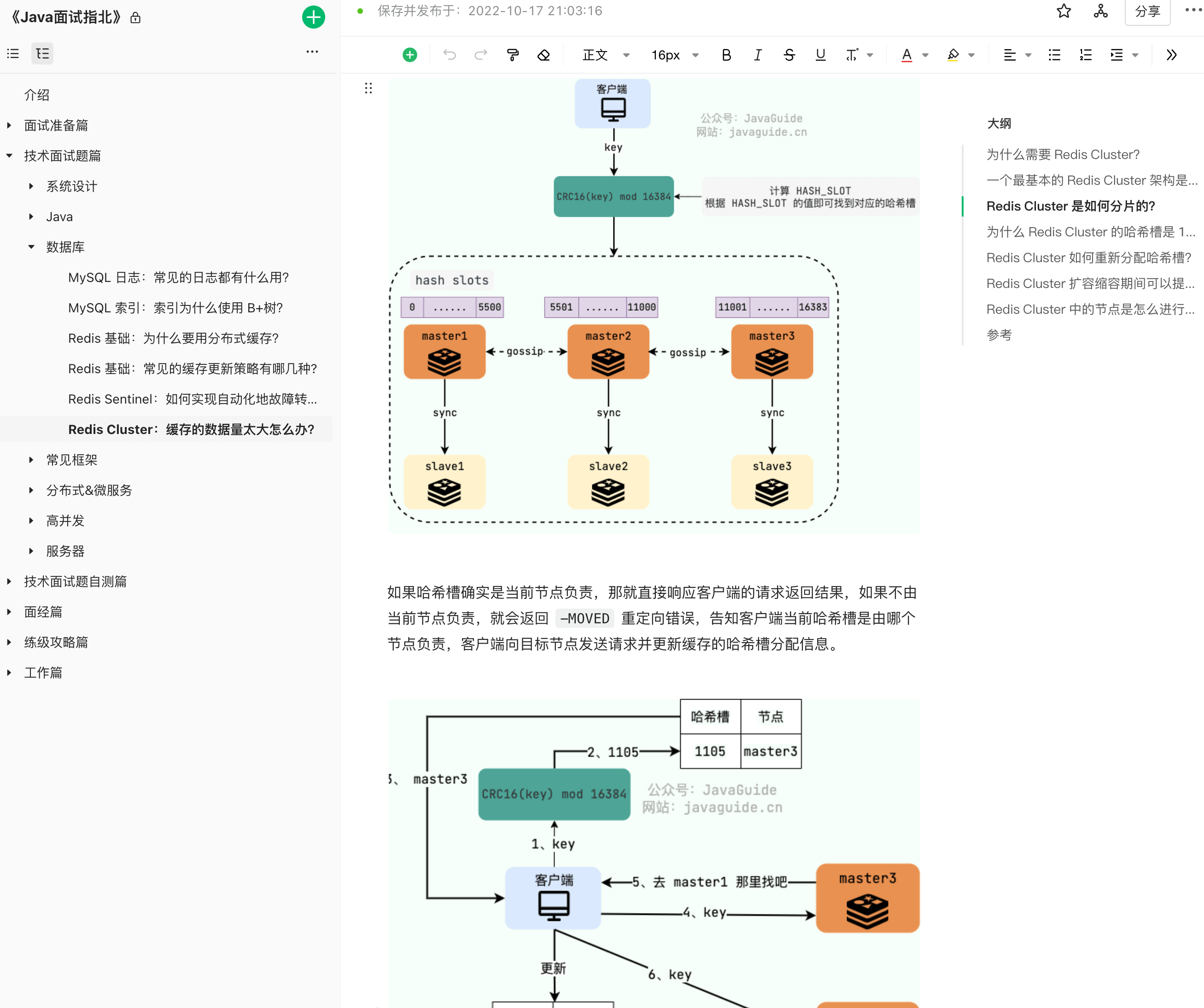
|
||||
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ tag:
|
|||
|
||||
## O(n) 命令
|
||||
|
||||
使用` O(n)` 命令可能会导致阻塞,例如`keys *` 、`hgetall`、`lrange`、`smembers`、`zrange`、`sinter` 、`sunion` 命令。这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大耗时也会越大从而导致客户端阻塞。
|
||||
使用` O(n)` 命令可能会导致阻塞,例如`keys *`、`hgetall`、`lrange`、`smembers`、`zrange`、`sinter`、`sunion` 命令。这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大耗时也会越大从而导致客户端阻塞。
|
||||
|
||||
不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。有遍历的需求可以使用 `hscan`、`sscan`、`zscan` 代替。
|
||||
|
||||
|
|
@ -49,8 +49,8 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
|
|||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
|
||||
|
||||
1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
|
||||
2. `appendfsync everysec` :主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
|
||||
3. `appendfsync no` :主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
|
||||
2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
|
||||
3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
|
||||
|
||||
当后台线程( `aof_fsync` 线程)调用 `fsync` 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 `fsync` 操作发生阻塞,主线程调用 `write` 函数时也会被阻塞。`fsync` 完成后,主线程执行 `write` 才能成功返回。
|
||||
|
||||
|
|
|
|||
|
|
@ -61,9 +61,9 @@ String 是一种二进制安全的数据结构,可以用来存储任何类型
|
|||
| DEL key(通用) | 删除指定的 key |
|
||||
| EXPIRE key seconds(通用) | 给指定 key 设置过期时间 |
|
||||
|
||||
更多 Redis String 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=string 。
|
||||
更多 Redis String 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=string> 。
|
||||
|
||||
**基本操作** :
|
||||
**基本操作**:
|
||||
|
||||
```bash
|
||||
> SET key value
|
||||
|
|
@ -80,7 +80,7 @@ OK
|
|||
(nil)
|
||||
```
|
||||
|
||||
**批量设置** :
|
||||
**批量设置**:
|
||||
|
||||
```bash
|
||||
> MSET key1 value1 key2 value2
|
||||
|
|
@ -120,13 +120,13 @@ OK
|
|||
|
||||
**需要存储常规数据的场景**
|
||||
|
||||
- 举例 :缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
|
||||
- 相关命令 : `SET`、`GET`。
|
||||
- 举例:缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
|
||||
- 相关命令:`SET`、`GET`。
|
||||
|
||||
**需要计数的场景**
|
||||
|
||||
- 举例 :用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
|
||||
- 相关命令 :`SET`、`GET`、 `INCR`、`DECR` 。
|
||||
- 举例:用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
|
||||
- 相关命令:`SET`、`GET`、 `INCR`、`DECR` 。
|
||||
|
||||
**分布式锁**
|
||||
|
||||
|
|
@ -154,9 +154,9 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
|||
| LLEN key | 获取列表元素数量 |
|
||||
| LRANGE key start end | 获取列表 start 和 end 之间 的元素 |
|
||||
|
||||
更多 Redis List 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=list 。
|
||||
更多 Redis List 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=list> 。
|
||||
|
||||
**通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`实现队列** :
|
||||
**通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`实现队列**:
|
||||
|
||||
```bash
|
||||
> RPUSH myList value1
|
||||
|
|
@ -173,7 +173,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
|||
2) "value3"
|
||||
```
|
||||
|
||||
**通过 `RPUSH/RPOP`或者`LPUSH/LPOP` 实现栈** :
|
||||
**通过 `RPUSH/RPOP`或者`LPUSH/LPOP` 实现栈**:
|
||||
|
||||
```bash
|
||||
> RPUSH myList2 value1 value2 value3
|
||||
|
|
@ -186,7 +186,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
|||
|
||||

|
||||
|
||||
**通过 `LRANGE` 查看对应下标范围的列表元素** :
|
||||
**通过 `LRANGE` 查看对应下标范围的列表元素**:
|
||||
|
||||
```bash
|
||||
> RPUSH myList value1 value2 value3
|
||||
|
|
@ -202,7 +202,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
|||
|
||||
通过 `LRANGE` 命令,你可以基于 List 实现分页查询,性能非常高!
|
||||
|
||||
**通过 `LLEN` 查看链表长度** :
|
||||
**通过 `LLEN` 查看链表长度**:
|
||||
|
||||
```bash
|
||||
> LLEN myList
|
||||
|
|
@ -213,8 +213,8 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
|||
|
||||
**信息流展示**
|
||||
|
||||
- 举例 :最新文章、最新动态。
|
||||
- 相关命令 : `LPUSH`、`LRANGE`。
|
||||
- 举例:最新文章、最新动态。
|
||||
- 相关命令:`LPUSH`、`LRANGE`。
|
||||
|
||||
**消息队列**
|
||||
|
||||
|
|
@ -247,9 +247,9 @@ Hash 类似于 JDK1.8 前的 `HashMap`,内部实现也差不多(数组 + 链
|
|||
| HLEN key | 获取指定哈希表中字段的数量 |
|
||||
| HINCRBY key field increment | 对指定哈希中的指定字段做运算操作(正数为加,负数为减) |
|
||||
|
||||
更多 Redis Hash 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=hash 。
|
||||
更多 Redis Hash 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=hash> 。
|
||||
|
||||
**模拟对象数据存储** :
|
||||
**模拟对象数据存储**:
|
||||
|
||||
```bash
|
||||
> HMSET userInfoKey name "guide" description "dev" age 24
|
||||
|
|
@ -278,8 +278,8 @@ OK
|
|||
|
||||
**对象数据存储场景**
|
||||
|
||||
- 举例 :用户信息、商品信息、文章信息、购物车信息。
|
||||
- 相关命令 :`HSET` (设置单个字段的值)、`HMSET`(设置多个字段的值)、`HGET`(获取单个字段的值)、`HMGET`(获取多个字段的值)。
|
||||
- 举例:用户信息、商品信息、文章信息、购物车信息。
|
||||
- 相关命令:`HSET` (设置单个字段的值)、`HMSET`(设置多个字段的值)、`HGET`(获取单个字段的值)、`HMGET`(获取多个字段的值)。
|
||||
|
||||
## Set(集合)
|
||||
|
||||
|
|
@ -308,9 +308,9 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
|||
| SPOP key count | 随机移除并获取指定集合中一个或多个元素 |
|
||||
| SRANDMEMBER key count | 随机获取指定集合中指定数量的元素 |
|
||||
|
||||
更多 Redis Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=set 。
|
||||
更多 Redis Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=set> 。
|
||||
|
||||
**基本操作** :
|
||||
**基本操作**:
|
||||
|
||||
```bash
|
||||
> SADD mySet value1 value2
|
||||
|
|
@ -329,9 +329,9 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
|||
```
|
||||
|
||||
- `mySet` : `value1`、`value2` 。
|
||||
- `mySet2` : `value2` 、`value3` 。
|
||||
- `mySet2`:`value2`、`value3` 。
|
||||
|
||||
**求交集** :
|
||||
**求交集**:
|
||||
|
||||
```bash
|
||||
> SINTERSTORE mySet3 mySet mySet2
|
||||
|
|
@ -340,7 +340,7 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
|||
1) "value2"
|
||||
```
|
||||
|
||||
**求并集** :
|
||||
**求并集**:
|
||||
|
||||
```bash
|
||||
> SUNION mySet mySet2
|
||||
|
|
@ -349,7 +349,7 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
|||
3) "value1"
|
||||
```
|
||||
|
||||
**求差集** :
|
||||
**求差集**:
|
||||
|
||||
```bash
|
||||
> SDIFF mySet mySet2 # 差集是由所有属于 mySet 但不属于 A 的元素组成的集合
|
||||
|
|
@ -367,14 +367,14 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
|||
|
||||
**需要获取多个数据源交集、并集和差集的场景**
|
||||
|
||||
- 举例 :共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集) 、订阅号推荐(差集+交集) 等场景。
|
||||
- 举例:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等场景。
|
||||
- 相关命令:`SINTER`(交集)、`SINTERSTORE` (交集)、`SUNION` (并集)、`SUNIONSTORE`(并集)、`SDIFF`(差集)、`SDIFFSTORE` (差集)。
|
||||
|
||||
|
||||
|
||||
**需要随机获取数据源中的元素的场景**
|
||||
|
||||
- 举例 :抽奖系统、随机点名等场景。
|
||||
- 举例:抽奖系统、随机点名等场景。
|
||||
- 相关命令:`SPOP`(随机获取集合中的元素并移除,适合不允许重复中奖的场景)、`SRANDMEMBER`(随机获取集合中的元素,适合允许重复中奖的场景)。
|
||||
|
||||
## Sorted Set(有序集合)
|
||||
|
|
@ -399,9 +399,9 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
|
|||
| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
|
||||
| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
|
||||
|
||||
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=sorted-set 。
|
||||
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=sorted-set> 。
|
||||
|
||||
**基本操作** :
|
||||
**基本操作**:
|
||||
|
||||
```bash
|
||||
> ZADD myZset 2.0 value1 1.0 value2
|
||||
|
|
@ -422,9 +422,9 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
|
|||
```
|
||||
|
||||
- `myZset` : `value1`(2.0)、`value2`(1.0) 。
|
||||
- `myZset2` : `value2` (4.0)、`value3`(3.0) 。
|
||||
- `myZset2`:`value2` (4.0)、`value3`(3.0) 。
|
||||
|
||||
**获取指定元素的排名** :
|
||||
**获取指定元素的排名**:
|
||||
|
||||
```bash
|
||||
> ZREVRANK myZset value1
|
||||
|
|
@ -433,7 +433,7 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
|
|||
1
|
||||
```
|
||||
|
||||
**求交集** :
|
||||
**求交集**:
|
||||
|
||||
```bash
|
||||
> ZINTERSTORE myZset3 2 myZset myZset2
|
||||
|
|
@ -443,7 +443,7 @@ value2
|
|||
5
|
||||
```
|
||||
|
||||
**求并集** :
|
||||
**求并集**:
|
||||
|
||||
```bash
|
||||
> ZUNIONSTORE myZset4 2 myZset myZset2
|
||||
|
|
@ -457,7 +457,7 @@ value2
|
|||
5
|
||||
```
|
||||
|
||||
**求差集** :
|
||||
**求差集**:
|
||||
|
||||
```bash
|
||||
> ZDIFF 2 myZset myZset2 WITHSCORES
|
||||
|
|
@ -469,8 +469,8 @@ value1
|
|||
|
||||
**需要随机获取数据源中的元素根据某个权重进行排序的场景**
|
||||
|
||||
- 举例 :各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||
- 相关命令 :`ZRANGE` (从小到大排序) 、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
- 举例:各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||
- 相关命令:`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
|
||||

|
||||
|
||||
|
|
@ -480,12 +480,12 @@ value1
|
|||
|
||||
**需要存储的数据有优先级或者重要程度的场景** 比如优先级任务队列。
|
||||
|
||||
- 举例 :优先级任务队列。
|
||||
- 相关命令 :`ZRANGE` (从小到大排序) 、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
- 举例:优先级任务队列。
|
||||
- 相关命令:`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
|
||||
## 参考
|
||||
|
||||
- Redis Data Structures :https://redis.com/redis-enterprise/data-structures/ 。
|
||||
- Redis Commands : https://redis.io/commands/ 。
|
||||
- Redis Data types tutorial:https://redis.io/docs/manual/data-types/data-types-tutorial/ 。
|
||||
- Redis 存储对象信息是用 Hash 还是 String : https://segmentfault.com/a/1190000040032006
|
||||
- Redis Data Structures:<https://redis.com/redis-enterprise/data-structures/> 。
|
||||
- Redis Commands:<https://redis.io/commands/> 。
|
||||
- Redis Data types tutorial:<https://redis.io/docs/manual/data-types/data-types-tutorial/> 。
|
||||
- Redis 存储对象信息是用 Hash 还是 String : <https://segmentfault.com/a/1190000040032006>
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ head:
|
|||
content: Redis特殊数据结构总结:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
|
||||
---
|
||||
|
||||
除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构 :Bitmap、HyperLogLog、GEO。
|
||||
除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构:Bitmap、HyperLogLog、GEO。
|
||||
|
||||
## Bitmap
|
||||
|
||||
|
|
@ -33,7 +33,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
|
|||
| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
|
||||
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
|
||||
|
||||
**Bitmap 基本操作演示** :
|
||||
**Bitmap 基本操作演示**:
|
||||
|
||||
```bash
|
||||
# SETBIT 会返回之前位的值(默认是 0)这里会生成 7 个位
|
||||
|
|
@ -56,8 +56,8 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
|
|||
|
||||
**需要保存状态信息(0/1 即可表示)的场景**
|
||||
|
||||
- 举例 :用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
|
||||
- 相关命令 :`SETBIT`、`GETBIT`、`BITCOUNT`、`BITOP`。
|
||||
- 举例:用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
|
||||
- 相关命令:`SETBIT`、`GETBIT`、`BITCOUNT`、`BITOP`。
|
||||
|
||||
## HyperLogLog
|
||||
|
||||
|
|
@ -67,8 +67,8 @@ HyperLogLog 是一种有名的基数计数概率算法 ,基于 LogLog Counting
|
|||
|
||||
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近`2^64`个不同元素。这是真的厉害,这就是数学的魅力么!并且,Redis 对 HyperLogLog 的存储结构做了优化,采用两种方式计数:
|
||||
|
||||
- **稀疏矩阵** :计数较少的时候,占用空间很小。
|
||||
- **稠密矩阵** :计数达到某个阈值的时候,占用 12k 的空间。
|
||||
- **稀疏矩阵**:计数较少的时候,占用空间很小。
|
||||
- **稠密矩阵**:计数达到某个阈值的时候,占用 12k 的空间。
|
||||
|
||||
Redis 官方文档中有对应的详细说明:
|
||||
|
||||
|
|
@ -92,7 +92,7 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
|
|||
| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
|
||||
| PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
|
||||
|
||||
**HyperLogLog 基本操作演示** :
|
||||
**HyperLogLog 基本操作演示**:
|
||||
|
||||
```bash
|
||||
> PFADD hll foo bar zap
|
||||
|
|
@ -117,8 +117,8 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
|
|||
|
||||
**数量量巨大(百万、千万级别以上)的计数场景**
|
||||
|
||||
- 举例 :热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
|
||||
- 相关命令 :`PFADD`、`PFCOUNT` 。
|
||||
- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
|
||||
- 相关命令:`PFADD`、`PFCOUNT` 。
|
||||
|
||||
## Geospatial index
|
||||
|
||||
|
|
@ -140,7 +140,7 @@ Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理
|
|||
| GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC(由近到远)、DESC(由远到近)、Count(数量) 等参数 |
|
||||
| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
|
||||
|
||||
**基本操作** :
|
||||
**基本操作**:
|
||||
|
||||
```bash
|
||||
> GEOADD personLocation 116.33 39.89 user1 116.34 39.90 user2 116.35 39.88 user3
|
||||
|
|
@ -158,7 +158,7 @@ GEO 中存储的地理位置信息的经纬度数据通过 GeoHash 算法转换
|
|||
|
||||
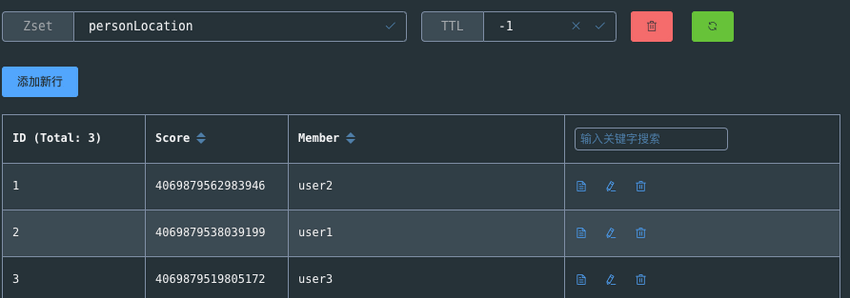
|
||||
|
||||
**获取指定位置范围内的其他元素** :
|
||||
**获取指定位置范围内的其他元素**:
|
||||
|
||||
```bash
|
||||
> GEORADIUS personLocation 116.33 39.87 3 km
|
||||
|
|
@ -180,7 +180,7 @@ user2
|
|||
|
||||
`GEORADIUS` 命令的底层原理解析可以看看阿里的这篇文章:[Redis 到底是怎么实现“附近的人”这个功能的呢?](https://juejin.cn/post/6844903966061363207) 。
|
||||
|
||||
**移除元素** :
|
||||
**移除元素**:
|
||||
|
||||
GEO 底层是 Sorted Set ,你可以对 GEO 使用 Sorted Set 相关的命令。
|
||||
|
||||
|
|
@ -203,6 +203,6 @@ user2
|
|||
|
||||
## 参考
|
||||
|
||||
- Redis Data Structures :https://redis.com/redis-enterprise/data-structures/ 。
|
||||
- Redis Data Structures:https://redis.com/redis-enterprise/data-structures/ 。
|
||||
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog
|
||||
- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html
|
||||
|
|
|
|||
|
|
@ -69,18 +69,18 @@ AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 `dir` 参
|
|||
|
||||
AOF 持久化功能的实现可以简单分为 5 步:
|
||||
|
||||
1. **命令追加(append)** :所有的写命令会追加到 AOF 缓冲区中。
|
||||
2. **文件写入(write)** :将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
|
||||
3. **文件同步(fsync)** :AOF 缓冲区根据对应的持久化方式( `fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用), `fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
|
||||
4. **文件重写(rewrite)** :随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
|
||||
5. **重启加载(load)** :当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
|
||||
1. **命令追加(append)**:所有的写命令会追加到 AOF 缓冲区中。
|
||||
2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
|
||||
3. **文件同步(fsync)**:AOF 缓冲区根据对应的持久化方式( `fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用), `fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
|
||||
4. **文件重写(rewrite)**:随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
|
||||
5. **重启加载(load)**:当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
|
||||
|
||||
> Linux 系统直接提供了一些函数用于对文件和设备进行访问和控制,这些函数被称为 **系统调用(syscall)**。
|
||||
|
||||
这里对上面提到的一些 Linux 系统调用再做一遍解释:
|
||||
|
||||
- `write` :写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
|
||||
- `fsync` : `fsync`用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
|
||||
- `write`:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
|
||||
- `fsync`:`fsync`用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
|
||||
|
||||
AOF 工作流程图如下:
|
||||
|
||||
|
|
@ -91,8 +91,8 @@ AOF 工作流程图如下:
|
|||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
|
||||
|
||||
1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
|
||||
2. `appendfsync everysec` :主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
|
||||
3. `appendfsync no` :主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
|
||||
2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
|
||||
3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
|
||||
|
||||
可以看出:**这 3 种持久化方式的主要区别在于 `fsync` 同步 AOF 文件的时机(刷盘)**。
|
||||
|
||||
|
|
@ -106,7 +106,7 @@ AOF 工作流程图如下:
|
|||
|
||||
Multi Part AOF 不是重点,了解即可,详细介绍可以看看阿里开发者的[Redis 7.0 Multi Part AOF 的设计和实现](https://zhuanlan.zhihu.com/p/467217082) 这篇文章。
|
||||
|
||||
**相关 issue** :[Redis 的 AOF 方式 #783](https://github.com/Snailclimb/JavaGuide/issues/783)。
|
||||
**相关 issue**:[Redis 的 AOF 方式 #783](https://github.com/Snailclimb/JavaGuide/issues/783)。
|
||||
|
||||
### AOF 为什么是在执行完命令之后记录日志?
|
||||
|
||||
|
|
@ -138,7 +138,7 @@ AOF 文件重写期间,Redis 还会维护一个 **AOF 重写缓冲区**,该
|
|||
|
||||
开启 AOF 重写功能,可以调用 `BGREWRITEAOF` 命令手动执行,也可以设置下面两个配置项,让程序自动决定触发时机:
|
||||
|
||||
- `auto-aof-rewrite-min-size` :如果 AOF 文件大小小于该值,则不会触发 AOF 重写。默认值为 64 MB;
|
||||
- `auto-aof-rewrite-min-size`:如果 AOF 文件大小小于该值,则不会触发 AOF 重写。默认值为 64 MB;
|
||||
- `auto-aof-rewrite-percentage`:执行 AOF 重写时,当前 AOF 大小(aof_current_size)和上一次重写时 AOF 大小(aof_base_size)的比值。如果当前 AOF 文件大小增加了这个百分比值,将触发 AOF 重写。将此值设置为 0 将禁用自动 AOF 重写。默认值为 100。
|
||||
|
||||
Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
|
||||
|
|
@ -149,7 +149,7 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
|
|||
>
|
||||
> 阿里云的 Redis 企业版在最初也遇到了这个问题,在内部经过多次迭代开发,实现了 Multi-part AOF 机制来解决,同时也贡献给了社区并随此次 7.0 发布。具体方法是采用 base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和 IO 资源的浪费,同时也支持对历史 AOF 文件的保存管理,结合 AOF 文件中的时间信息还可以实现 PITR 按时间点恢复(阿里云企业版 Tair 已支持),这进一步增强了 Redis 的数据可靠性,满足用户数据回档等需求。
|
||||
|
||||
**相关 issue** :[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)
|
||||
**相关 issue**:[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)
|
||||
|
||||
## Redis 4.0 对于持久化机制做了什么优化?
|
||||
|
||||
|
|
@ -165,18 +165,18 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
|
|||
|
||||
关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明[Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
|
||||
|
||||
**RDB 比 AOF 优秀的地方** :
|
||||
**RDB 比 AOF 优秀的地方**:
|
||||
|
||||
- RDB 文件存储的内容是经过压缩的二进制数据, 保存着某个时间点的数据集,文件很小,适合做数据的备份,灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会必 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF。新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过, Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
|
||||
- 使用 RDB 文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快。而 AOF 则需要依次执行每个写命令,速度非常慢。也就是说,与 AOF 相比,恢复大数据集的时候,RDB 速度更快。
|
||||
|
||||
**AOF 比 RDB 优秀的地方** :
|
||||
**AOF 比 RDB 优秀的地方**:
|
||||
|
||||
- RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。生成 RDB 文件的过程是比较繁重的, 虽然 BGSAVE 子进程写入 RDB 文件的工作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产生影响,严重的情况下甚至会直接把 Redis 服务干宕机。AOF 支持秒级数据丢失(取决 fsync 策略,如果是 everysec,最多丢失 1 秒的数据),仅仅是追加命令到 AOF 文件,操作轻量。
|
||||
- RDB 文件是以特定的二进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在老版本的 Redis 服务不兼容新版本的 RDB 格式的问题。
|
||||
- AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,你也可以直接操作 AOF 文件来解决一些问题。比如,如果执行`FLUSHALL`命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
|
||||
|
||||
**综上** :
|
||||
**综上**:
|
||||
|
||||
- Redis 保存的数据丢失一些也没什么影响的话,可以选择使用 RDB。
|
||||
- 不建议单独使用 AOF,因为时不时地创建一个 RDB 快照可以进行数据库备份、更快的重启以及解决 AOF 引擎错误。
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ head:
|
|||
|
||||
[Redis](https://redis.io/) 是一个基于 C 语言开发的开源数据库(BSD 许可),与传统数据库不同的是 Redis 的数据是存在内存中的(内存数据库),读写速度非常快,被广泛应用于缓存方向。并且,Redis 存储的是 KV 键值对数据。
|
||||
|
||||
为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务 、持久化、Lua 脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
|
||||
为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
|
||||
|
||||
Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两个操作系统,官方推荐生产环境使用 Linux 部署 Redis。
|
||||
|
||||
|
|
@ -52,19 +52,19 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
|||
|
||||
关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
|
||||
|
||||
从这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
|
||||
从这个项目的 GitHub 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
|
||||
|
||||
### 说一下 Redis 和 Memcached 的区别和共同点
|
||||
|
||||
现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
|
||||
|
||||
**共同点** :
|
||||
**共同点**:
|
||||
|
||||
1. 都是基于内存的数据库,一般都用来当做缓存使用。
|
||||
2. 都有过期策略。
|
||||
3. 两者的性能都非常高。
|
||||
|
||||
**区别** :
|
||||
**区别**:
|
||||
|
||||
1. **Redis 支持更丰富的数据类型(支持更复杂的应用场景)**。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
|
||||
2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。**
|
||||
|
|
@ -103,10 +103,10 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
|||
|
||||
### Redis 除了做缓存,还能做什么?
|
||||
|
||||
- **分布式锁** : 通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
|
||||
- **限流** :一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:[《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》](https://mp.weixin.qq.com/s/kyFAWH3mVNJvurQDt4vchA)。
|
||||
- **消息队列** :Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
|
||||
- **复杂业务场景** :通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
|
||||
- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
|
||||
- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:[《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》](https://mp.weixin.qq.com/s/kyFAWH3mVNJvurQDt4vchA)。
|
||||
- **消息队列**:Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
|
||||
- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
|
||||
- ......
|
||||
|
||||
### 如何基于 Redis 实现分布式锁?
|
||||
|
|
@ -121,7 +121,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
|||
|
||||
**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
|
||||
|
||||
通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`即可实现简易版消息队列 :
|
||||
通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`即可实现简易版消息队列:
|
||||
|
||||
```bash
|
||||
# 生产者生产消息
|
||||
|
|
@ -183,8 +183,8 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
|
|||
|
||||
### Redis 常用的数据结构有哪些?
|
||||
|
||||
- **5 种基础数据结构** :String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
|
||||
- **3 种特殊数据结构** :HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
|
||||
- **5 种基础数据结构**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
|
||||
- **3 种特殊数据结构**:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
|
||||
|
||||
### String 的应用场景有哪些?
|
||||
|
||||
|
|
@ -259,17 +259,17 @@ struct __attribute__ ((__packed__)) sdshdr64 {
|
|||
|
||||
对于后四种实现都包含了下面这 4 个属性:
|
||||
|
||||
- `len` :字符串的长度也就是已经使用的字节数
|
||||
- `len`:字符串的长度也就是已经使用的字节数
|
||||
- `alloc`:总共可用的字符空间大小,alloc-len 就是 SDS 剩余的空间大小
|
||||
- `buf[]` :实际存储字符串的数组
|
||||
- `flags` :低三位保存类型标志
|
||||
- `buf[]`:实际存储字符串的数组
|
||||
- `flags`:低三位保存类型标志
|
||||
|
||||
SDS 相比于 C 语言中的字符串有如下提升:
|
||||
|
||||
1. **可以避免缓冲区溢出** :C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
|
||||
2. **获取字符串长度的复杂度较低** : C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O(1)。
|
||||
3. **减少内存分配次数** : 为了避免修改(增加/减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了空间预分配和惰性空间释放两种优化策略。当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
|
||||
4. **二进制安全** :C 语言中的字符串以空字符 `\0` 作为字符串结束的标识,这存在一些问题,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 使用 len 属性判断字符串是否结束,不存在这个问题。
|
||||
1. **可以避免缓冲区溢出**:C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
|
||||
2. **获取字符串长度的复杂度较低**:C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O(1)。
|
||||
3. **减少内存分配次数**:为了避免修改(增加/减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了空间预分配和惰性空间释放两种优化策略。当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
|
||||
4. **二进制安全**:C 语言中的字符串以空字符 `\0` 作为字符串结束的标识,这存在一些问题,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 使用 len 属性判断字符串是否结束,不存在这个问题。
|
||||
|
||||
🤐 多提一嘴,很多文章里 SDS 的定义是下面这样的:
|
||||
|
||||
|
|
@ -306,7 +306,7 @@ struct sdshdr {
|
|||
|
||||
Redis 中有一个叫做 `sorted set` 的数据结构经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||
|
||||
相关的一些 Redis 命令: `ZRANGE` (从小到大排序) 、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
相关的一些 Redis 命令: `ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
|
||||

|
||||
|
||||
|
|
@ -321,7 +321,7 @@ Redis 中 `Set` 是一种无序集合,集合中的元素没有先后顺序但
|
|||
Set 的常见应用场景如下:
|
||||
|
||||
- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog`更适合一些)、文章点赞、动态点赞等等。
|
||||
- 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集) 、订阅号推荐(差集+交集) 等等。
|
||||
- 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等等。
|
||||
- 需要随机获取数据源中的元素的场景:抽奖系统、随机点名等等。
|
||||
|
||||
### 使用 Set 实现抽奖系统怎么做?
|
||||
|
|
@ -329,7 +329,7 @@ Set 的常见应用场景如下:
|
|||
如果想要使用 Set 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
|
||||
|
||||
- `SADD key member1 member2 ...`:向指定集合添加一个或多个元素。
|
||||
- `SPOP key count` : 随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
|
||||
- `SPOP key count`:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
|
||||
- `SRANDMEMBER key count` : 随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
|
||||
|
||||
### 使用 Bitmap 统计活跃用户怎么做?
|
||||
|
|
@ -392,7 +392,7 @@ PFCOUNT PAGE_1:UV
|
|||
|
||||
## Redis 持久化机制(重要)
|
||||
|
||||
Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持久化) 相关的问题比较多,也比较重要,于是我单独抽了一篇文章来总结 Redis 持久化机制相关的知识点和问题: [Redis 持久化机制详解](./redis-persistence.md) 。
|
||||
Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持久化) 相关的问题比较多,也比较重要,于是我单独抽了一篇文章来总结 Redis 持久化机制相关的知识点和问题:[Redis 持久化机制详解](./redis-persistence.md) 。
|
||||
|
||||
## Redis 线程模型(重要)
|
||||
|
||||
|
|
@ -415,7 +415,7 @@ Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持
|
|||
|
||||
Redis 通过 **IO 多路复用程序** 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
|
||||
|
||||
这样的好处非常明显: **I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗**(和 NIO 中的 `Selector` 组件很像)。
|
||||
这样的好处非常明显:**I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗**(和 NIO 中的 `Selector` 组件很像)。
|
||||
|
||||
文件事件处理器(file event handler)主要是包含 4 个部分:
|
||||
|
||||
|
|
@ -454,7 +454,7 @@ Redis 通过 **IO 多路复用程序** 来监听来自客户端的大量连接
|
|||
|
||||
虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了,执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
|
||||
|
||||
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要设置 IO 线程数 > 1,需要修改 redis 配置文件 `redis.conf` :
|
||||
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要设置 IO 线程数 > 1,需要修改 redis 配置文件 `redis.conf`:
|
||||
|
||||
```bash
|
||||
io-threads 4 #设置1的话只会开启主线程,官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
|
||||
|
|
@ -562,8 +562,8 @@ typedef struct redisDb {
|
|||
|
||||
常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
|
||||
|
||||
1. **惰性删除** :只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
|
||||
2. **定期删除** : 每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
|
||||
1. **惰性删除**:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
|
||||
2. **定期删除**:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
|
||||
|
||||
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
|
||||
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ head:
|
|||
|
||||
### 什么是 Redis 事务?
|
||||
|
||||
你可以将 Redis 中的事务理解为 :**Redis 事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
|
||||
你可以将 Redis 中的事务理解为:**Redis 事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
|
||||
|
||||
Redis 事务实际开发中使用的非常少,功能比较鸡肋,不要将其和我们平时理解的关系型数据库的事务混淆了。
|
||||
|
||||
|
|
@ -86,7 +86,7 @@ QUEUED
|
|||
"GoGuide"
|
||||
```
|
||||
|
||||
不过,如果 **WATCH** 与 **事务** 在同一个 Session 里,并且被 **WATCH** 监视的 Key 被修改的操作发生在事务内部,这个事务是可以被执行成功的(相关 issue :[WATCH 命令碰到 MULTI 命令时的不同效果](https://github.com/Snailclimb/JavaGuide/issues/1714))。
|
||||
不过,如果 **WATCH** 与 **事务** 在同一个 Session 里,并且被 **WATCH** 监视的 Key 被修改的操作发生在事务内部,这个事务是可以被执行成功的(相关 issue:[WATCH 命令碰到 MULTI 命令时的不同效果](https://github.com/Snailclimb/JavaGuide/issues/1714))。
|
||||
|
||||
事务内部修改 WATCH 监视的 Key:
|
||||
|
||||
|
|
@ -134,7 +134,7 @@ Redis 官网相关介绍 [https://redis.io/topics/transactions](https://redis.io
|
|||
|
||||
### Redis 事务支持原子性吗?
|
||||
|
||||
Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性: **1. 原子性**,**2. 隔离性**,**3. 持久性**,**4. 一致性**。
|
||||
Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性:**1. 原子性**,**2. 隔离性**,**3. 持久性**,**4. 一致性**。
|
||||
|
||||
1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
|
|
@ -168,7 +168,7 @@ appendfsync everysec #每秒钟调用fsync函数同步一次AOF文件
|
|||
appendfsync no #让操作系统决定何时进行同步,一般为30秒一次
|
||||
```
|
||||
|
||||
AOF 持久化的`fsync`策略为 no 、everysec 时都会存在数据丢失的情况 。always 下可以基本是可以满足持久性要求的,但性能太差,实际开发过程中不会使用。
|
||||
AOF 持久化的`fsync`策略为 no、everysec 时都会存在数据丢失的情况 。always 下可以基本是可以满足持久性要求的,但性能太差,实际开发过程中不会使用。
|
||||
|
||||
因此,Redis 事务的持久性也是没办法保证的。
|
||||
|
||||
|
|
@ -319,17 +319,17 @@ Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28
|
|||
|
||||
网上有现成的代码/工具可以直接拿来使用:
|
||||
|
||||
- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools) :Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
|
||||
- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools):Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
|
||||
- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys) : Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
|
||||
|
||||
### Redis 内存碎片
|
||||
|
||||
**相关问题** :
|
||||
**相关问题**:
|
||||
|
||||
1. 什么是内存碎片?为什么会有 Redis 内存碎片?
|
||||
2. 如何清理 Redis 内存碎片?
|
||||
|
||||
**参考答案** :[Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)。
|
||||
**参考答案**:[Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)。
|
||||
|
||||
## Redis 生产问题(重要)
|
||||
|
||||
|
|
@ -349,9 +349,9 @@ Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28
|
|||
|
||||
**1)缓存无效 key**
|
||||
|
||||
如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下: `SET key value EX 10086` 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
|
||||
如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086` 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
|
||||
|
||||
另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值` 。
|
||||
另外,这里多说一嘴,一般情况下我们是这样设计 key 的:`表名:列名:主键名:主键值` 。
|
||||
|
||||
如果用 Java 代码展示的话,差不多是下面这样的:
|
||||
|
||||
|
|
@ -386,7 +386,7 @@ public Object getObjectInclNullById(Integer id) {
|
|||
|
||||
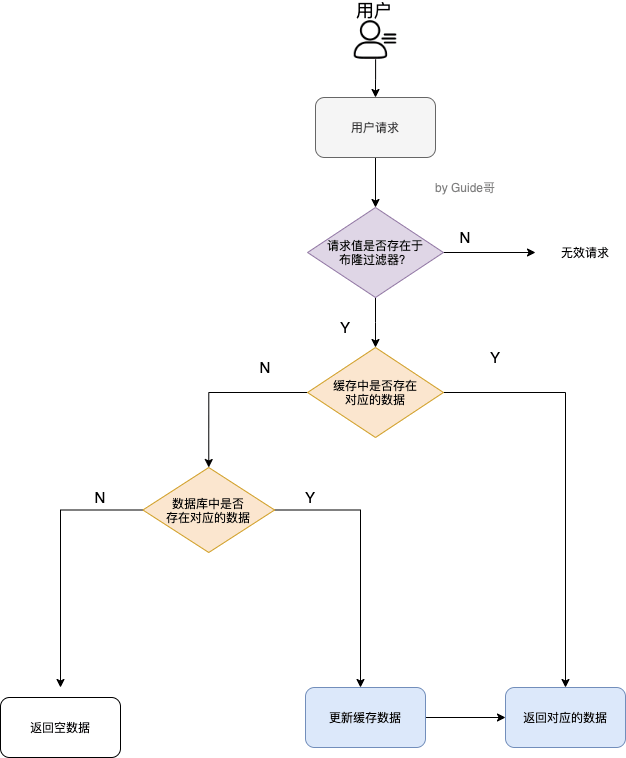
|
||||
|
||||
但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是: **布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
|
||||
但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
|
||||
|
||||
_为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理来说!_
|
||||
|
||||
|
|
@ -412,7 +412,7 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
|
|||
|
||||
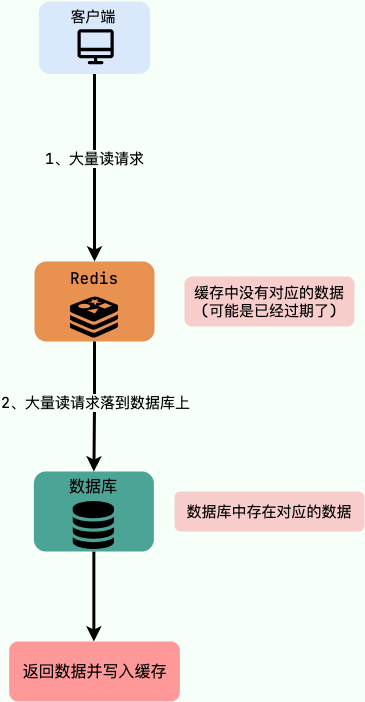
|
||||
|
||||
举个例子 :秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。
|
||||
举个例子:秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。
|
||||
|
||||
#### 有哪些解决办法?
|
||||
|
||||
|
|
@ -438,7 +438,7 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
|
|||
|
||||
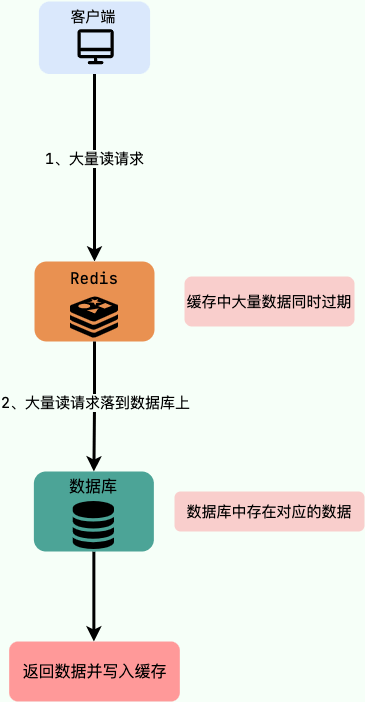
|
||||
|
||||
举个例子 :数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
|
||||
举个例子:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
|
||||
|
||||
#### 有哪些解决办法?
|
||||
|
||||
|
|
@ -467,8 +467,8 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
|
|||
|
||||
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
|
||||
|
||||
1. **缓存失效时间变短(不推荐,治标不治本)** :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
|
||||
2. **增加 cache 更新重试机制(常用)**: 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
|
||||
1. **缓存失效时间变短(不推荐,治标不治本)**:我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
|
||||
2. **增加 cache 更新重试机制(常用)**:如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
|
||||
|
||||
相关文章推荐:[缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹](https://mp.weixin.qq.com/s?__biz=MzIyOTYxNDI5OA==&mid=2247487312&idx=1&sn=fa19566f5729d6598155b5c676eee62d&chksm=e8beb8e5dfc931f3e35655da9da0b61c79f2843101c130cf38996446975014f958a6481aacf1&scene=178&cur_album_id=1699766580538032128#rd)。
|
||||
|
||||
|
|
@ -478,7 +478,7 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
|
|||
|
||||
## Redis 集群
|
||||
|
||||
**Redis Sentinel** :
|
||||
**Redis Sentinel**:
|
||||
|
||||
1. 什么是 Sentinel? 有什么用?
|
||||
2. Sentinel 如何检测节点是否下线?主观下线与客观下线的区别?
|
||||
|
|
@ -488,7 +488,7 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
|
|||
6. 如何从 Sentinel 集群中选择出 Leader ?
|
||||
7. Sentinel 可以防止脑裂吗?
|
||||
|
||||
**Redis Cluster** :
|
||||
**Redis Cluster**:
|
||||
|
||||
1. 为什么需要 Redis Cluster?解决了什么问题?有什么优势?
|
||||
2. Redis Cluster 是如何分片的?
|
||||
|
|
@ -498,21 +498,21 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
|
|||
6. Redis Cluster 扩容缩容期间可以提供服务吗?
|
||||
7. Redis Cluster 中的节点是怎么进行通信的?
|
||||
|
||||
**参考答案** :[Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html)。
|
||||
**参考答案**:[Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html)。
|
||||
|
||||
## Redis 使用规范
|
||||
|
||||
实际使用 Redis 的过程中,我们尽量要准守一些常见的规范,比如:
|
||||
|
||||
1. 使用连接池:避免频繁创建关闭客户端连接。
|
||||
2. 尽量不使用 O(n)指令,使用 O(N)命令时要关注 N 的数量 :例如 `hgetall`、`lrange`、`smembers`、`zrange`、`sinter` 、`sunion` 命令并非不能使用,但是需要明确 N 的值。有遍历的需求可以使用 `hscan`、`sscan`、`zscan` 代替。
|
||||
3. 使用批量操作减少网络传输 :原生批量操作命令(比如 `mget`、`mset`等等)、pipeline、Lua 脚本。
|
||||
2. 尽量不使用 O(n)指令,使用 O(N)命令时要关注 N 的数量:例如 `hgetall`、`lrange`、`smembers`、`zrange`、`sinter`、`sunion` 命令并非不能使用,但是需要明确 N 的值。有遍历的需求可以使用 `hscan`、`sscan`、`zscan` 代替。
|
||||
3. 使用批量操作减少网络传输:原生批量操作命令(比如 `mget`、`mset`等等)、pipeline、Lua 脚本。
|
||||
4. 尽量不适用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
|
||||
5. 禁止长时间开启 monitor:对性能影响比较大。
|
||||
6. 控制 key 的生命周期:避免 Redis 中存放了太多不经常被访问的数据。
|
||||
7. ......
|
||||
|
||||
相关文章推荐 :[阿里云 Redis 开发规范](https://developer.aliyun.com/article/531067) 。
|
||||
相关文章推荐:[阿里云 Redis 开发规范](https://developer.aliyun.com/article/531067) 。
|
||||
|
||||
## 参考
|
||||
|
||||
|
|
|
|||
|
|
@ -203,7 +203,7 @@ ORDER BY vend_name DESC
|
|||
|
||||
### 返回固定价格的产品
|
||||
|
||||
有表 `Products` :
|
||||
有表 `Products`:
|
||||
|
||||
| prod_id | prod_name | prod_price |
|
||||
| ------- | -------------- | ---------- |
|
||||
|
|
@ -223,7 +223,7 @@ WHERE prod_price = 9.49
|
|||
|
||||
### 返回更高价格的产品
|
||||
|
||||
有表 `Products` :
|
||||
有表 `Products`:
|
||||
|
||||
| prod_id | prod_name | prod_price |
|
||||
| ------- | -------------- | ---------- |
|
||||
|
|
@ -243,7 +243,7 @@ WHERE prod_price >= 9
|
|||
|
||||
### 返回产品并且按照价格排序
|
||||
|
||||
有表 `Products` :
|
||||
有表 `Products`:
|
||||
|
||||
| prod_id | prod_name | prod_price |
|
||||
| ------- | --------- | ---------- |
|
||||
|
|
@ -565,7 +565,7 @@ FROM Customers
|
|||
知识点:
|
||||
|
||||
- 截取函数`SUBSTRING()`:截取字符串,`substring(str ,n ,m)`:返回字符串 str 从第 n 个字符截取到第 m 个字符(左闭右闭);
|
||||
- 拼接函数`CONCAT()`:将两个或多个字符串连接成一个字符串,select concat(A,B) :连接字符串 A 和 B。
|
||||
- 拼接函数`CONCAT()`:将两个或多个字符串连接成一个字符串,select concat(A,B):连接字符串 A 和 B。
|
||||
|
||||
- 大写函数 `UPPER()`:将指定字符串转换为大写。
|
||||
|
||||
|
|
|
|||
|
|
@ -40,7 +40,7 @@ SQL 语法结构包括:
|
|||
|
||||
#### SQL 语法要点
|
||||
|
||||
- **SQL 语句不区分大小写**,但是数据库表名、列名和值是否区分,依赖于具体的 DBMS 以及配置。例如:`SELECT` 与 `select` 、`Select` 是相同的。
|
||||
- **SQL 语句不区分大小写**,但是数据库表名、列名和值是否区分,依赖于具体的 DBMS 以及配置。例如:`SELECT` 与 `select`、`Select` 是相同的。
|
||||
- **多条 SQL 语句必须以分号(`;`)分隔**。
|
||||
- 处理 SQL 语句时,**所有空格都被忽略**。
|
||||
|
||||
|
|
@ -171,8 +171,8 @@ TRUNCATE TABLE user;
|
|||
|
||||
`LIMIT` 限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。
|
||||
|
||||
- `ASC` :升序(默认)
|
||||
- `DESC` :降序
|
||||
- `ASC`:升序(默认)
|
||||
- `DESC`:降序
|
||||
|
||||
**查询单列**
|
||||
|
||||
|
|
@ -225,7 +225,7 @@ ORDER BY prod_price DESC, prod_name ASC;
|
|||
|
||||
## 分组
|
||||
|
||||
**`group by`** :
|
||||
**`group by`**:
|
||||
|
||||
- `group by` 子句将记录分组到汇总行中。
|
||||
- `group by` 为每个组返回一个记录。
|
||||
|
|
@ -264,7 +264,7 @@ GROUP BY cust_name
|
|||
HAVING COUNT(*) >= 1;
|
||||
```
|
||||
|
||||
**`having` vs `where`** :
|
||||
**`having` vs `where`**:
|
||||
|
||||
- `where`:过滤过滤指定的行,后面不能加聚合函数(分组函数)。`where` 在`group by` 前。
|
||||
- `having`:过滤分组,一般都是和 `group by` 连用,不能单独使用。`having` 在 `group by` 之后。
|
||||
|
|
@ -751,12 +751,12 @@ DROP VIEW top_10_user_view;
|
|||
|
||||
索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
|
||||
|
||||
**优点** :
|
||||
**优点**:
|
||||
|
||||
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
|
||||
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
|
||||
|
||||
**缺点** :
|
||||
**缺点**:
|
||||
|
||||
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
|
||||
- 索引需要使用物理文件存储,也会耗费一定空间。
|
||||
|
|
@ -1140,13 +1140,13 @@ MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储
|
|||
|
||||
但是,从 MySQL 版本 5.7.2+开始,可以为同一触发事件和操作时间定义多个触发器。
|
||||
|
||||
**`NEW` 和 `OLD`** :
|
||||
**`NEW` 和 `OLD`**:
|
||||
|
||||
- MySQL 中定义了 `NEW` 和 `OLD` 关键字,用来表示触发器的所在表中,触发了触发器的那一行数据。
|
||||
- 在 `INSERT` 型触发器中,`NEW` 用来表示将要(`BEFORE`)或已经(`AFTER`)插入的新数据;
|
||||
- 在 `UPDATE` 型触发器中,`OLD` 用来表示将要或已经被修改的原数据,`NEW` 用来表示将要或已经修改为的新数据;
|
||||
- 在 `DELETE` 型触发器中,`OLD` 用来表示将要或已经被删除的原数据;
|
||||
- 使用方法: `NEW.columnName` (columnName 为相应数据表某一列名)
|
||||
- 使用方法:`NEW.columnName` (columnName 为相应数据表某一列名)
|
||||
|
||||
### 创建触发器
|
||||
|
||||
|
|
@ -1169,7 +1169,7 @@ END;
|
|||
|
||||
说明:
|
||||
|
||||
- `trigger_name` :触发器名
|
||||
- `trigger_name`:触发器名
|
||||
- `trigger_time` : 触发器的触发时机。取值为 `BEFORE` 或 `AFTER`。
|
||||
- `trigger_event` : 触发器的监听事件。取值为 `INSERT`、`UPDATE` 或 `DELETE`。
|
||||
- `table_name` : 触发器的监听目标。指定在哪张表上建立触发器。
|
||||
|
|
|
|||
|
|
@ -23,20 +23,20 @@ category: 分布式
|
|||
|
||||
绝大部分网关可以提供下面这些功能:
|
||||
|
||||
- **请求转发** :将请求转发到目标微服务。
|
||||
- **负载均衡** :根据各个微服务实例的负载情况或者具体的负载均衡策略配置对请求实现动态的负载均衡。
|
||||
- **安全认证** :对用户请求进行身份验证并仅允许可信客户端访问 API,并且还能够使用类似 RBAC 等方式来授权。
|
||||
- **参数校验** :支持参数映射与校验逻辑。
|
||||
- **日志记录** :记录所有请求的行为日志供后续使用。
|
||||
- **监控告警** :从业务指标、机器指标、JVM 指标等方面进行监控并提供配套的告警机制。
|
||||
- **流量控制** :对请求的流量进行控制,也就是限制某一时刻内的请求数。
|
||||
- **请求转发**:将请求转发到目标微服务。
|
||||
- **负载均衡**:根据各个微服务实例的负载情况或者具体的负载均衡策略配置对请求实现动态的负载均衡。
|
||||
- **安全认证**:对用户请求进行身份验证并仅允许可信客户端访问 API,并且还能够使用类似 RBAC 等方式来授权。
|
||||
- **参数校验**:支持参数映射与校验逻辑。
|
||||
- **日志记录**:记录所有请求的行为日志供后续使用。
|
||||
- **监控告警**:从业务指标、机器指标、JVM 指标等方面进行监控并提供配套的告警机制。
|
||||
- **流量控制**:对请求的流量进行控制,也就是限制某一时刻内的请求数。
|
||||
- **熔断降级**:实时监控请求的统计信息,达到配置的失败阈值后,自动熔断,返回默认值。
|
||||
- **响应缓存**:当用户请求获取的是一些静态的或更新不频繁的数据时,一段时间内多次请求获取到的数据很可能是一样的。对于这种情况可以将响应缓存起来。这样用户请求可以直接在网关层得到响应数据,无需再去访问业务服务,减轻业务服务的负担。
|
||||
- **响应聚合**:某些情况下用户请求要获取的响应内容可能会来自于多个业务服务。网关作为业务服务的调用方,可以把多个服务的响应整合起来,再一并返回给用户。
|
||||
- **灰度发布** :将请求动态分流到不同的服务版本(最基本的一种灰度发布)。
|
||||
- **灰度发布**:将请求动态分流到不同的服务版本(最基本的一种灰度发布)。
|
||||
- **异常处理**:对于业务服务返回的异常响应,可以在网关层在返回给用户之前做转换处理。这样可以把一些业务侧返回的异常细节隐藏,转换成用户友好的错误提示返回。
|
||||
- **API 文档:** 如果计划将 API 暴露给组织以外的开发人员,那么必须考虑使用 API 文档,例如 Swagger 或 OpenAPI。
|
||||
- **协议转换** :通过协议转换整合后台基于 REST、AMQP、Dubbo 等不同风格和实现技术的微服务,面向 Web Mobile、开放平台等特定客户端提供统一服务。
|
||||
- **协议转换**:通过协议转换整合后台基于 REST、AMQP、Dubbo 等不同风格和实现技术的微服务,面向 Web Mobile、开放平台等特定客户端提供统一服务。
|
||||
|
||||
下图来源于[百亿规模 API 网关服务 Shepherd 的设计与实现 - 美团技术团队 - 2021](https://mp.weixin.qq.com/s/iITqdIiHi3XGKq6u6FRVdg)这篇文章。
|
||||
|
||||
|
|
@ -74,8 +74,8 @@ Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网
|
|||
|
||||
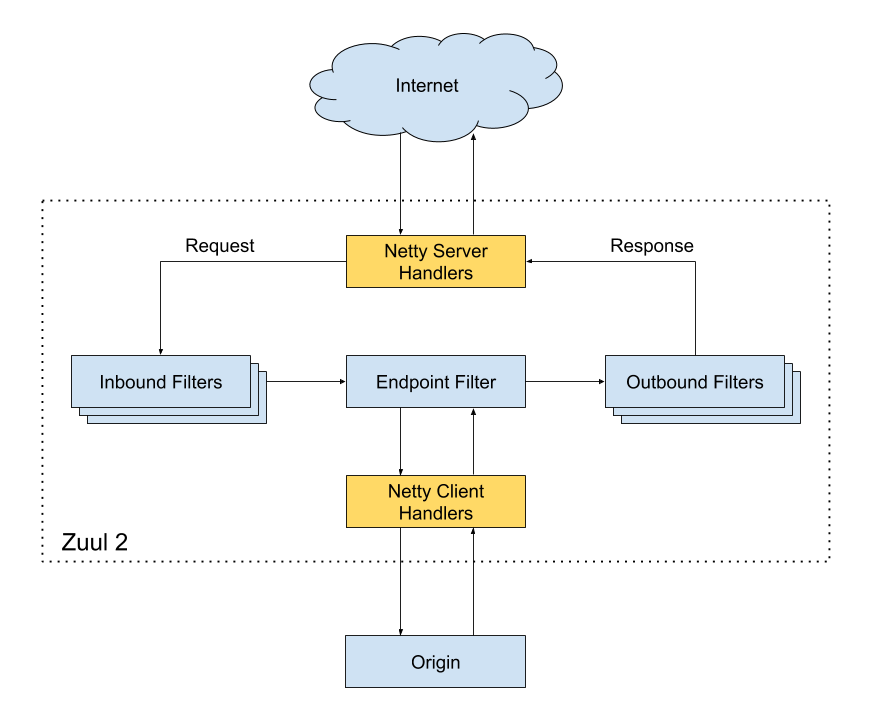
|
||||
|
||||
- Github 地址 : <https://github.com/Netflix/zuul>
|
||||
- 官方 Wiki : <https://github.com/Netflix/zuul/wiki>
|
||||
- GitHub 地址: <https://github.com/Netflix/zuul>
|
||||
- 官方 Wiki: <https://github.com/Netflix/zuul/wiki>
|
||||
|
||||
### Spring Cloud Gateway
|
||||
|
||||
|
|
@ -89,15 +89,15 @@ Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链
|
|||
|
||||
Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
|
||||
|
||||
- Github 地址 : <https://github.com/spring-cloud/spring-cloud-gateway>
|
||||
- 官网 : <https://spring.io/projects/spring-cloud-gateway>
|
||||
- Github 地址: <https://github.com/spring-cloud/spring-cloud-gateway>
|
||||
- 官网: <https://spring.io/projects/spring-cloud-gateway>
|
||||
|
||||
### Kong
|
||||
|
||||
Kong 是一款基于 [OpenResty](https://github.com/openresty/) (Nginx + Lua)的高性能、云原生、可扩展的网关系统,主要由 3 个组件组成:
|
||||
|
||||
- Kong Server :基于 Nginx 的服务器,用来接收 API 请求。
|
||||
- Apache Cassandra/PostgreSQL :用来存储操作数据。
|
||||
- Kong Server:基于 Nginx 的服务器,用来接收 API 请求。
|
||||
- Apache Cassandra/PostgreSQL:用来存储操作数据。
|
||||
- Kong Dashboard:官方推荐 UI 管理工具,当然,也可以使用 RESTful 方式 管理 Admin api。
|
||||
|
||||
> OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
|
||||
|
|
@ -118,7 +118,7 @@ $ curl -X POST http://kong:8001/services/{service}/plugins \
|
|||
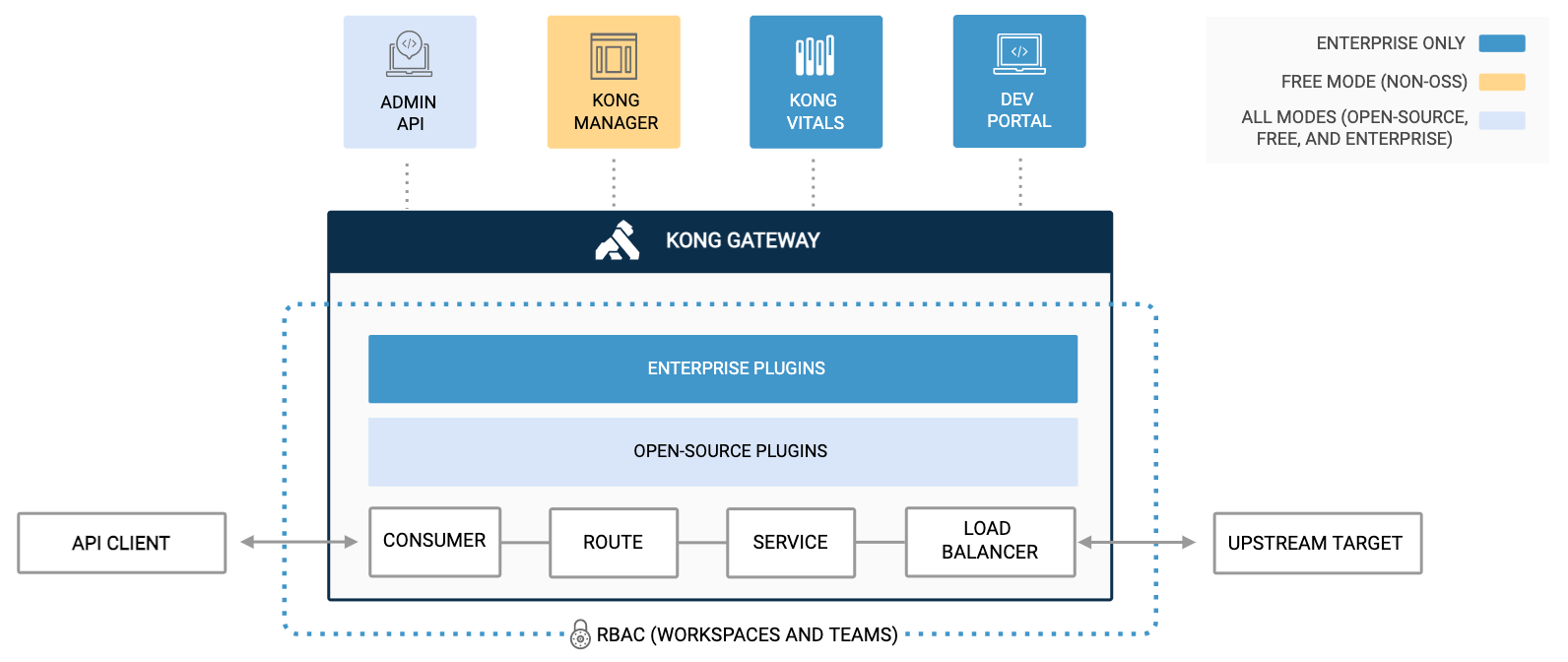
|
||||
|
||||
- Github 地址: <https://github.com/Kong/kong>
|
||||
- 官网地址 : <https://konghq.com/kong>
|
||||
- 官网地址: <https://konghq.com/kong>
|
||||
|
||||
### APISIX
|
||||
|
||||
|
|
@ -143,7 +143,7 @@ APISIX 同样支持定制化的插件开发。开发者除了能够使用 Lua
|
|||
|
||||

|
||||
|
||||
- Github 地址 :<https://github.com/apache/apisix>
|
||||
- Github 地址:<https://github.com/apache/apisix>
|
||||
- 官网地址: <https://apisix.apache.org/zh/>
|
||||
|
||||
相关阅读:
|
||||
|
|
@ -159,10 +159,10 @@ Shenyu 是一款基于 WebFlux 的可扩展、高性能、响应式网关,Apac
|
|||
|
||||
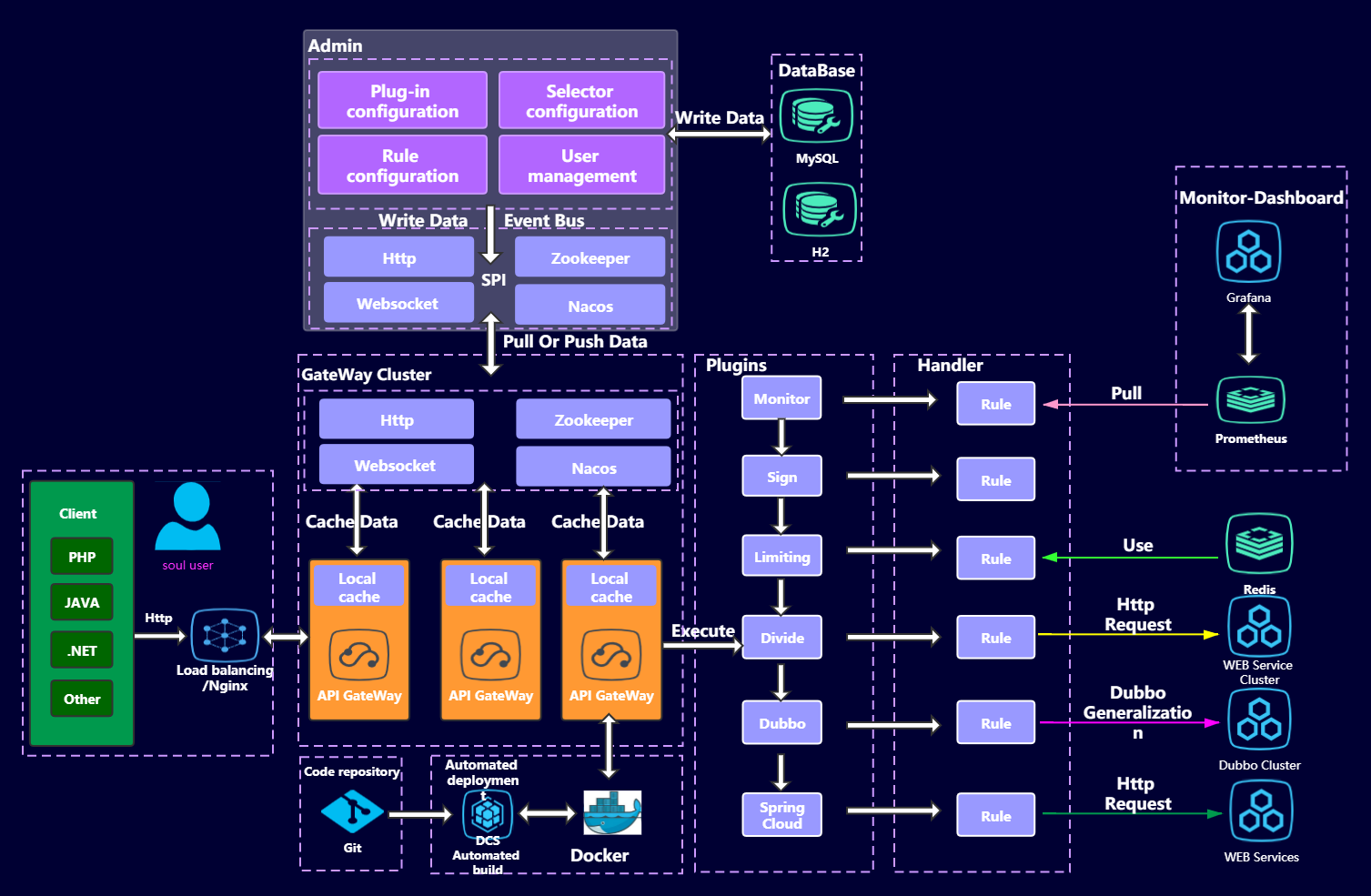
|
||||
|
||||
Shenyu 通过插件扩展功能,插件是 ShenYu 的灵魂,并且插件也是可扩展和热插拔的。不同的插件实现不同的功能。Shenyu 自带了诸如限流、熔断、转发 、重写、重定向、和路由监控等插件。
|
||||
Shenyu 通过插件扩展功能,插件是 ShenYu 的灵魂,并且插件也是可扩展和热插拔的。不同的插件实现不同的功能。Shenyu 自带了诸如限流、熔断、转发、重写、重定向、和路由监控等插件。
|
||||
|
||||
- Github 地址: <https://github.com/apache/incubator-shenyu>
|
||||
- 官网地址 : <https://shenyu.apache.org/>
|
||||
- 官网地址: <https://shenyu.apache.org/>
|
||||
|
||||
## 参考
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,173 @@
|
|||
---
|
||||
title: 分布式ID设计指南
|
||||
category: 分布式
|
||||
---
|
||||
|
||||
::: tip
|
||||
|
||||
看到百度 Geek 说的一篇结合具体场景聊分布式 ID 设计的文章,感觉挺不错的。于是,我将这篇文章的部分内容整理到了这里。原文传送门:[分布式 ID 生成服务的技术原理和项目实战](https://mp.weixin.qq.com/s/bFDLb6U6EgI-DvCdLTq_QA) 。
|
||||
|
||||
:::
|
||||
|
||||
网上绝大多数的分布式 ID 生成服务,一般着重于技术原理剖析,很少见到根据具体的业务场景去选型 ID 生成服务的文章。
|
||||
|
||||
本文结合一些使用场景,进一步探讨业务场景中对 ID 有哪些具体的要求。
|
||||
|
||||
## 场景一:订单系统
|
||||
|
||||
我们在商场买东西一码付二维码,下单生成的订单号,使用到的优惠券码,联合商品兑换券码,这些是在网上购物经常使用到的单号,那么为什么有些单号那么长,有些只有几位数?有些单号一看就知道年月日的信息,有些却看不出任何意义?下面展开分析下订单系统中不同场景的 id 服务的具体实现。
|
||||
|
||||
### 1、一码付
|
||||
|
||||
我们常见的一码付,指的是一个二维码可以使用支付宝或者微信进行扫码支付。
|
||||
|
||||
二维码的本质是一个字符串。聚合码的本质就是一个链接地址。用户使用支付宝微信直接扫一个码付钱,不用担心拿支付宝扫了微信的收款码或者用微信扫了支付宝的收款码,这极大减少了用户扫码支付的时间。
|
||||
|
||||
实现原理是当客户用 APP 扫码后,网站后台就会判断客户的扫码环境。(微信、支付宝、QQ 钱包、京东支付、云闪付等)。
|
||||
|
||||
判断扫码环境的原理就是根据打开链接浏览器的 HTTP header。任何浏览器打开 http 链接时,请求的 header 都会有 User-Agent(UA、用户代理)信息。
|
||||
|
||||
UA 是一个特殊字符串头,服务器依次可以识别出客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等很多信息。
|
||||
|
||||
各渠道对应支付产品的名称不一样,一定要仔细看各支付产品的 API 介绍。
|
||||
|
||||
1. 微信支付:JSAPI 支付支付
|
||||
2. 支付宝:手机网站支付
|
||||
3. QQ 钱包:公众号支付
|
||||
|
||||
其本质均为在 APP 内置浏览器中实现 HTML5 支付。
|
||||
|
||||
|
||||
|
||||
文库的研发同学在这个思路上,做了优化迭代。动态生成一码付的二维码预先绑定用户所选的商品信息和价格,根据用户所选的商品动态更新。这样不仅支持一码多平台调起支付,而且不用用户选择商品输入金额,即可完成订单支付的功能,很丝滑。用户在真正扫码后,服务端才通过前端获取用户 UID,结合二维码绑定的商品信息,真正的生成订单,发送支付信息到第三方(qq、微信、支付宝),第三方生成支付订单推给用户设备,从而调起支付。
|
||||
|
||||
区别于固定的一码付,在文库的应用中,使用到了动态二维码,二维码本质是一个短网址,ID 服务提供短网址的唯一标志参数。唯一的短网址映射的 ID 绑定了商品的订单信息,技术和业务的深度结合,缩短了支付流程,提升用户的支付体验。
|
||||
|
||||
### 2、订单号
|
||||
|
||||
订单号在实际的业务过程中作为一个订单的唯一标识码存在,一般实现以下业务场景:
|
||||
|
||||
1. 用户订单遇到问题,需要找客服进行协助;
|
||||
2. 对订单进行操作,如线下收款,订单核销;
|
||||
3. 下单,改单,成单,退单,售后等系统内部的订单流程处理和跟进。
|
||||
|
||||
很多时候搜索订单相关信息的时候都是以订单 ID 作为唯一标识符,这是由于订单号的生成规则的唯一性决定的。从技术角度看,除了 ID 服务必要的特性之外,在订单号的设计上需要体现几个特性:
|
||||
|
||||
**(1)信息安全**
|
||||
|
||||
编号不能透露公司的运营情况,比如日销、公司流水号等信息,以及商业信息和用户手机号,身份证等隐私信息。并且不能有明显的整体规律(可以有局部规律),任意修改一个字符就能查询到另一个订单信息,这也是不允许的。
|
||||
|
||||
类比于我们高考时候的考生编号的生成规则,一定不能是连号的,否则只需要根据顺序往下查询就能搜索到别的考生的成绩,这是绝对不可允许。
|
||||
|
||||
**(2)部分可读**
|
||||
|
||||
位数要便于操作,因此要求订单号的位数适中,且局部有规律。这样可以方便在订单异常,或者退货时客服查询。
|
||||
|
||||
过长的订单号或易读性差的订单号会导致客服输入困难且易错率较高,影响用户体验的售后体验。因此在实际的业务场景中,订单号的设计通常都会适当携带一些允许公开的对使用场景有帮助的信息,如时间,星期,类型等等,这个主要根据所涉及的编号对应的使用场景来。
|
||||
|
||||
而且像时间、星期这些自增长的属于作为订单号的设计的一部分元素,有助于解决业务累积而导致的订单号重复的问题。
|
||||
|
||||
**(3)查询效率**
|
||||
|
||||
常见的电商平台订单号大多是纯数字组成,兼具可读性的同时,int 类型相对 varchar 类型的查询效率更高,对在线业务更加友好。
|
||||
|
||||
### 3、优惠券和兑换券
|
||||
|
||||
优惠券、兑换券是运营推广最常用的促销工具之一,合理使用它们,可以让买家得到实惠,商家提升商品销量。常见场景有:
|
||||
|
||||
1. 在文库购买【文库 VIP+QQ 音乐年卡】联合商品,支付成功后会得到 QQ 音乐年卡的兑换码,可以去 QQ 音乐 App 兑换音乐会员年卡;
|
||||
2. 疫情期间,部分地方政府发放的消费券;
|
||||
3. 瓶装饮料经常会出现输入优惠编码兑换奖品。
|
||||
|
||||
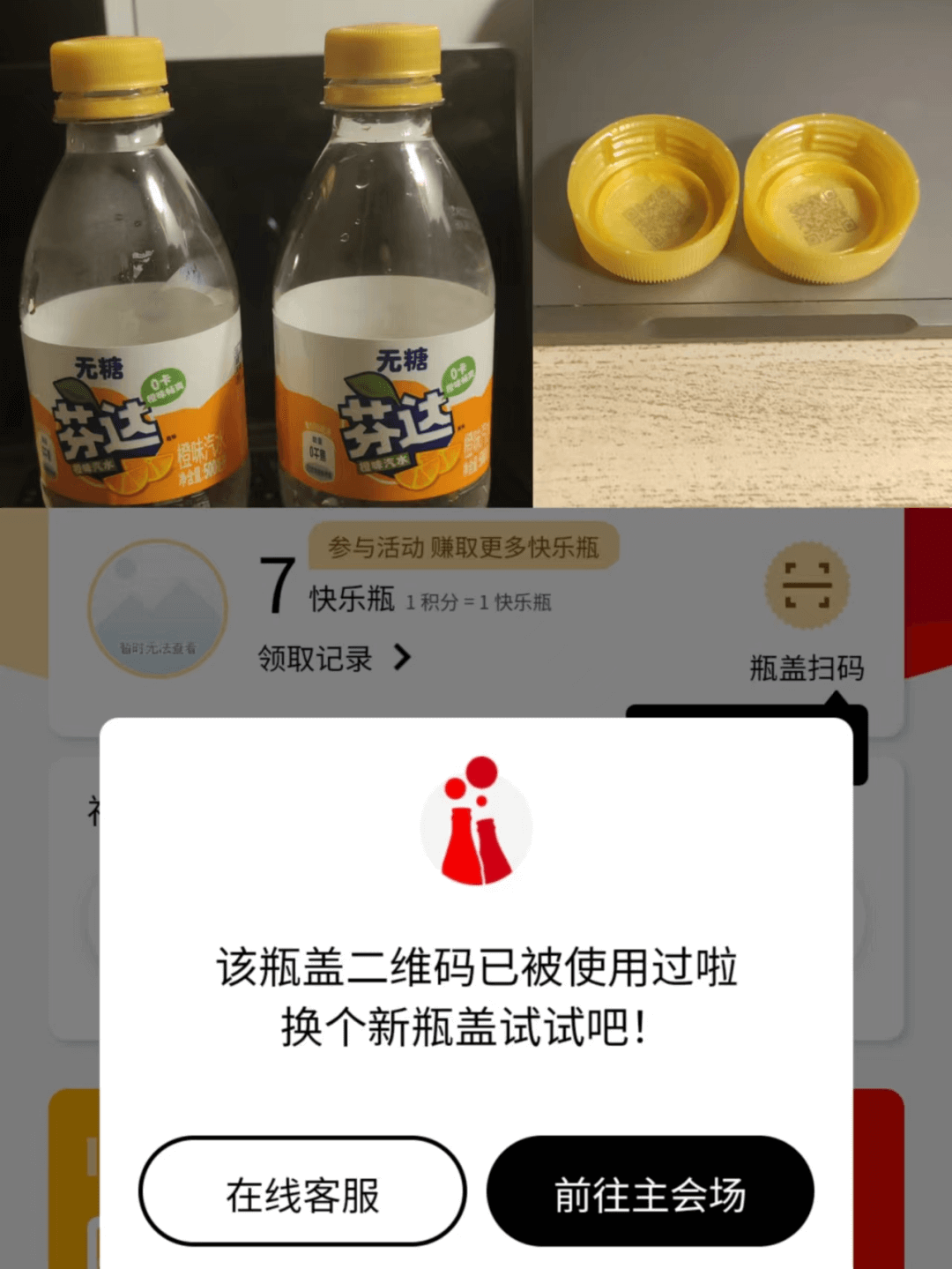
|
||||
|
||||
从技术角度看,有些场景适合 ID 即时生成,比如电商平台购物领取的优惠券,只需要在用户领取时分配优惠券信息即可。有些线上线下结合的场景,比如疫情优惠券,瓶盖开奖,京东卡,超市卡这种,则需要预先生成,预先生成的券码具备以下特性:
|
||||
|
||||
1.预先生成,在活动正式开始前提供出来进行活动预热;
|
||||
|
||||
2.优惠券体量大,以万为单位,通常在 10 万级别以上;
|
||||
|
||||
3.不可破解、仿制券码;
|
||||
|
||||
4.支持用后核销;
|
||||
|
||||
5.优惠券、兑换券属于广撒网的策略,所以利用率低,也就不适合使用数据。
|
||||
|
||||
**库进行存储(占空间,有效的数据有少)**
|
||||
|
||||
设计思路上,需要设计一种有效的兑换码生成策略,支持预先生成,支持校验,内容简洁,生成的兑换码都具有唯一性,那么这种策略就是一种特殊的编解码策略,按照约定的编解码规则支撑上述需求。
|
||||
|
||||
既然是一种编解码规则,那么需要约定编码空间(也就是用户看到的组成兑换码的字符),编码空间由字符 a-z,A-Z,数字 0-9 组成,为了增强兑换码的可识别度,剔除大写字母 O 以及 I,可用字符如下所示,共 60 个字符:
|
||||
|
||||
abcdefghijklmnopqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXZY0123456789
|
||||
|
||||
之前说过,兑换码要求近可能简洁,那么设计时就需要考虑兑换码的字符数,假设上限为 12 位,而字符空间有 60 位,那么可以表示的空间范围为 60^12=130606940160000000000000(也就是可以 12 位的兑换码可以生成天量,应该够运营同学挥霍了),转换成 2 进制:
|
||||
|
||||
1001000100000000101110011001101101110011000000000000000000000(61 位)
|
||||
|
||||
**兑换码组成成分分析**
|
||||
|
||||
兑换码可以预先生成,并且不需要额外的存储空间保存这些信息,每一个优惠方案都有独立的一组兑换码(指运营同学组织的每一场运营活动都有不同的兑换码,不能混合使用, 例如双 11 兑换码不能使用在双 12 活动上),每个兑换码有自己的编号,防止重复,为了保证兑换码的有效性,对兑换码的数据需要进行校验,当前兑换码的数据组成如下所示:
|
||||
|
||||
优惠方案 ID + 兑换码序列号 i + 校验码
|
||||
|
||||
**编码方案**
|
||||
|
||||
1. 兑换码序列号 i,代表当前兑换码是当前活动中第 i 个兑换码,兑换码序列号的空间范围决定了优惠活动可以发行的兑换码数目,当前采用 30 位 bit 位表示,可表示范围:1073741824(10 亿个券码)。
|
||||
2. 优惠方案 ID, 代表当前优惠方案的 ID 号,优惠方案的空间范围决定了可以组织的优惠活动次数,当前采用 15 位表示,可以表示范围:32768(考虑到运营活动的频率,以及 ID 的初始值 10000,15 位足够,365 天每天有运营活动,可以使用 54 年)。
|
||||
3. 校验码,校验兑换码是否有效,主要为了快捷的校验兑换码信息的是否正确,其次可以起到填充数据的目的,增强数据的散列性,使用 13 位表示校验位,其中分为两部分,前 6 位和后 7 位。
|
||||
|
||||
深耕业务还会有区分通用券和单独券的情况,分别具备以下特点,技术实现需要因地制宜地思考。
|
||||
|
||||
1. 通用券:多个玩家都可以输入兑换,然后有总量限制,期限限制。
|
||||
2. 单独券:运营同学可以在后台设置兑换码的奖励物品、期限、个数,然后由后台生成兑换码的列表,兑换之后核销。
|
||||
|
||||
## 场景二:Tracing
|
||||
|
||||
### 1、日志跟踪
|
||||
|
||||
在分布式服务架构下,一个 Web 请求从网关流入,有可能会调用多个服务对请求进行处理,拿到最终结果。这个过程中每个服务之间的通信又是单独的网络请求,无论请求经过的哪个服务出了故障或者处理过慢都会对前端造成影响。
|
||||
|
||||
处理一个 Web 请求要调用的多个服务,为了能更方便的查询哪个环节的服务出现了问题,现在常用的解决方案是为整个系统引入分布式链路跟踪。
|
||||
|
||||

|
||||
|
||||
在分布式链路跟踪中有两个重要的概念:跟踪(trace)和 跨度( span)。trace 是请求在分布式系统中的整个链路视图,span 则代表整个链路中不同服务内部的视图,span 组合在一起就是整个 trace 的视图。
|
||||
|
||||
在整个请求的调用链中,请求会一直携带 traceid 往下游服务传递,每个服务内部也会生成自己的 spanid 用于生成自己的内部调用视图,并和 traceid 一起传递给下游服务。
|
||||
|
||||
### 2、TraceId 生成规则
|
||||
|
||||
这种场景下,生成的 ID 除了要求唯一之外,还要求生成的效率高、吞吐量大。traceid 需要具备接入层的服务器实例自主生成的能力,如果每个 trace 中的 ID 都需要请求公共的 ID 服务生成,纯纯的浪费网络带宽资源。且会阻塞用户请求向下游传递,响应耗时上升,增加了没必要的风险。所以需要服务器实例最好可以自行计算 tracid,spanid,避免依赖外部服务。
|
||||
|
||||
产生规则:服务器 IP + ID 产生的时间 + 自增序列 + 当前进程号 ,比如:
|
||||
|
||||
0ad1348f1403169275002100356696
|
||||
|
||||
前 8 位 0ad1348f 即产生 TraceId 的机器的 IP,这是一个十六进制的数字,每两位代表 IP 中的一段,我们把这个数字,按每两位转成 10 进制即可得到常见的 IP 地址表示方式 10.209.52.143,您也可以根据这个规律来查找到请求经过的第一个服务器。
|
||||
|
||||
后面的 13 位 1403169275002 是产生 TraceId 的时间。之后的 4 位 1003 是一个自增的序列,从 1000 涨到 9000,到达 9000 后回到 1000 再开始往上涨。最后的 5 位 56696 是当前的进程 ID,为了防止单机多进程出现 TraceId 冲突的情况,所以在 TraceId 末尾添加了当前的进程 ID。
|
||||
|
||||
### 3、SpanId 生成规则
|
||||
|
||||
span 是层的意思,比如在第一个实例算是第一层, 请求代理或者分流到下一个实例处理,就是第二层,以此类推。通过层,SpanId 代表本次调用在整个调用链路树中的位置。
|
||||
|
||||
假设一个 服务器实例 A 接收了一次用户请求,代表是整个调用的根节点,那么 A 层处理这次请求产生的非服务调用日志记录 spanid 的值都是 0,A 层需要通过 RPC 依次调用 B、C、D 三个服务器实例,那么在 A 的日志中,SpanId 分别是 0.1,0.2 和 0.3,在 B、C、D 中,SpanId 也分别是 0.1,0.2 和 0.3;如果 C 系统在处理请求的时候又调用了 E,F 两个服务器实例,那么 C 系统中对应的 spanid 是 0.2.1 和 0.2.2,E、F 两个系统对应的日志也是 0.2.1 和 0.2.2。
|
||||
|
||||
根据上面的描述可以知道,如果把一次调用中所有的 SpanId 收集起来,可以组成一棵完整的链路树。
|
||||
|
||||
**spanid 的生成本质:在跨层传递透传的同时,控制大小版本号的自增来实现的。**
|
||||
|
||||
## 场景三:短网址
|
||||
|
||||
短网址主要功能包括网址缩短与还原两大功能。相对于长网址,短网址可以更方便地在电子邮件,社交网络,微博和手机上传播,例如原来很长的网址通过短网址服务即可生成相应的短网址,避免折行或超出字符限制。
|
||||
|
||||
|
||||
|
||||
常用的 ID 生成服务比如:MySQL ID 自增、 Redis 键自增、号段模式,生成的 ID 都是一串数字。短网址服务把客户的长网址转换成短网址,
|
||||
|
||||
实际是在 dwz.cn 域名后面拼接新产生的数字类型 ID,直接用数字 ID,网址长度也有些长,服务可以通过数字 ID 转更高进制的方式压缩长度。这种算法在短网址的技术实现上越来越多了起来,它可以进一步压缩网址长度。转进制的压缩算法在生活中有广泛的应用场景,举例:
|
||||
|
||||
- 客户的长网址:<https://wenku.baidu.com/ndbusiness/browse/wenkuvipcashier?cashier_code=PCoperatebanner>
|
||||
- ID 映射的短网址:<https://dwz.cn/2047601319t66> (演示使用,可能无法正确打开)
|
||||
- 转进制后的短网址:<https://dwz.cn/2ezwDJ0> (演示使用,可能无法正确打开)
|
||||
|
|
@ -35,17 +35,17 @@ category: 分布式
|
|||
|
||||
一个最基本的分布式 ID 需要满足下面这些要求:
|
||||
|
||||
- **全局唯一** :ID 的全局唯一性肯定是首先要满足的!
|
||||
- **高性能** : 分布式 ID 的生成速度要快,对本地资源消耗要小。
|
||||
- **高可用** :生成分布式 ID 的服务要保证可用性无限接近于 100%。
|
||||
- **方便易用** :拿来即用,使用方便,快速接入!
|
||||
- **全局唯一**:ID 的全局唯一性肯定是首先要满足的!
|
||||
- **高性能**:分布式 ID 的生成速度要快,对本地资源消耗要小。
|
||||
- **高可用**:生成分布式 ID 的服务要保证可用性无限接近于 100%。
|
||||
- **方便易用**:拿来即用,使用方便,快速接入!
|
||||
|
||||
除了这些之外,一个比较好的分布式 ID 还应保证:
|
||||
|
||||
- **安全** :ID 中不包含敏感信息。
|
||||
- **有序递增** :如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
|
||||
- **有具体的业务含义** :生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
|
||||
- **独立部署** :也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
|
||||
- **安全**:ID 中不包含敏感信息。
|
||||
- **有序递增**:如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
|
||||
- **有具体的业务含义**:生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
|
||||
- **独立部署**:也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
|
||||
|
||||
## 分布式 ID 常见解决方案
|
||||
|
||||
|
|
@ -83,14 +83,14 @@ COMMIT;
|
|||
|
||||
插入数据这里,我们没有使用 `insert into` 而是使用 `replace into` 来插入数据,具体步骤是这样的:
|
||||
|
||||
- 第一步: 尝试把数据插入到表中。
|
||||
- 第一步:尝试把数据插入到表中。
|
||||
|
||||
- 第二步: 如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
|
||||
- 第二步:如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
|
||||
|
||||
这种方式的优缺点也比较明显:
|
||||
|
||||
- **优点** :实现起来比较简单、ID 有序递增、存储消耗空间小
|
||||
- **缺点** : 支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
|
||||
- **优点**:实现起来比较简单、ID 有序递增、存储消耗空间小
|
||||
- **缺点**:支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
|
||||
|
||||
#### 数据库号段模式
|
||||
|
||||
|
|
@ -115,7 +115,7 @@ CREATE TABLE `sequence_id_generator` (
|
|||
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
|
||||
```
|
||||
|
||||
`current_max_id` 字段和`step`字段主要用于获取批量 ID,获取的批量 id 为: `current_max_id ~ current_max_id+step`。
|
||||
`current_max_id` 字段和`step`字段主要用于获取批量 ID,获取的批量 id 为:`current_max_id ~ current_max_id+step`。
|
||||
|
||||
|
||||
|
||||
|
|
@ -162,8 +162,8 @@ id current_max_id step version biz_type
|
|||
|
||||
**数据库号段模式的优缺点:**
|
||||
|
||||
- **优点** :ID 有序递增、存储消耗空间小
|
||||
- **缺点** :存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
|
||||
- **优点**:ID 有序递增、存储消耗空间小
|
||||
- **缺点**:存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
|
||||
|
||||
#### NoSQL
|
||||
|
||||
|
|
@ -190,8 +190,8 @@ OK
|
|||
|
||||
**Redis 方案的优缺点:**
|
||||
|
||||
- **优点** : 性能不错并且生成的 ID 是有序递增的
|
||||
- **缺点** : 和数据库主键自增方案的缺点类似
|
||||
- **优点**:性能不错并且生成的 ID 是有序递增的
|
||||
- **缺点**:和数据库主键自增方案的缺点类似
|
||||
|
||||
除了 Redis 之外,MongoDB ObjectId 经常也会被拿来当做分布式 ID 的解决方案。
|
||||
|
||||
|
|
@ -200,14 +200,14 @@ OK
|
|||
MongoDB ObjectId 一共需要 12 个字节存储:
|
||||
|
||||
- 0~3:时间戳
|
||||
- 3~6: 代表机器 ID
|
||||
- 3~6:代表机器 ID
|
||||
- 7~8:机器进程 ID
|
||||
- 9~11 :自增值
|
||||
- 9~11:自增值
|
||||
|
||||
**MongoDB 方案的优缺点:**
|
||||
|
||||
- **优点** : 性能不错并且生成的 ID 是有序递增的
|
||||
- **缺点** : 需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID) 、有安全性问题(ID 生成有规律性)
|
||||
- **优点**:性能不错并且生成的 ID 是有序递增的
|
||||
- **缺点**:需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)、有安全性问题(ID 生成有规律性)
|
||||
|
||||
### 算法
|
||||
|
||||
|
|
@ -261,17 +261,17 @@ int version = uuid.version();// 4
|
|||
|
||||
最后,我们再简单分析一下 **UUID 的优缺点** (面试的时候可能会被问到的哦!) :
|
||||
|
||||
- **优点** :生成速度比较快、简单易用
|
||||
- **缺点** : 存储消耗空间大(32 个字符串,128 位) 、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
|
||||
- **优点**:生成速度比较快、简单易用
|
||||
- **缺点**:存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
|
||||
|
||||
#### Snowflake(雪花算法)
|
||||
|
||||
Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit 的二进制数字组成,这 64bit 的二进制被分成了几部分,每一部分存储的数据都有特定的含义:
|
||||
|
||||
- **第 0 位**: 符号位(标识正负),始终为 0,没有用,不用管。
|
||||
- **第 1~41 位** :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
|
||||
- **第 42~52 位** :一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
|
||||
- **第 53~64 位** :一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
|
||||
- **第 0 位**:符号位(标识正负),始终为 0,没有用,不用管。
|
||||
- **第 1~41 位**:一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
|
||||
- **第 42~52 位**:一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
|
||||
- **第 53~64 位**:一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
|
||||
|
||||

|
||||
|
||||
|
|
@ -279,10 +279,10 @@ Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit
|
|||
|
||||
另外,在实际项目中,我们一般也会对 Snowflake 算法进行改造,最常见的就是在 Snowflake 算法生成的 ID 中加入业务类型信息。
|
||||
|
||||
我们再来看看 Snowflake 算法的优缺点 :
|
||||
我们再来看看 Snowflake 算法的优缺点:
|
||||
|
||||
- **优点** :生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
|
||||
- **缺点** : 需要解决重复 ID 问题(依赖时间,当机器时间不对的情况下,可能导致会产生重复 ID)。
|
||||
- **优点**:生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
|
||||
- **缺点**:需要解决重复 ID 问题(依赖时间,当机器时间不对的情况下,可能导致会产生重复 ID)。
|
||||
|
||||
### 开源框架
|
||||
|
||||
|
|
@ -304,7 +304,7 @@ UidGenerator 官方文档中的介绍如下:
|
|||
|
||||
#### Leaf(美团)
|
||||
|
||||
**[Leaf](https://github.com/Meituan-Dianping/Leaf)** 是美团开源的一个分布式 ID 解决方案 。这个项目的名字 Leaf(树叶) 起源于德国哲学家、数学家莱布尼茨的一句话: “There are no two identical leaves in the world”(世界上没有两片相同的树叶) 。这名字起得真心挺不错的,有点文艺青年那味了!
|
||||
**[Leaf](https://github.com/Meituan-Dianping/Leaf)** 是美团开源的一个分布式 ID 解决方案 。这个项目的名字 Leaf(树叶) 起源于德国哲学家、数学家莱布尼茨的一句话:“There are no two identical leaves in the world”(世界上没有两片相同的树叶) 。这名字起得真心挺不错的,有点文艺青年那味了!
|
||||
|
||||
Leaf 提供了 **号段模式** 和 **Snowflake(雪花算法)** 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper 。
|
||||
|
||||
|
|
@ -341,9 +341,9 @@ Tinyid 的原理比较简单,其架构如下图所示:
|
|||
|
||||
相比于基于数据库号段模式的简单架构方案,Tinyid 方案主要做了下面这些优化:
|
||||
|
||||
- **双号段缓存** :为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。 Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
|
||||
- **增加多 db 支持** :支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
|
||||
- **增加 tinyid-client** :纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
|
||||
- **双号段缓存**:为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。 Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
|
||||
- **增加多 db 支持**:支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
|
||||
- **增加 tinyid-client**:纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
|
||||
|
||||
Tinyid 的优缺点这里就不分析了,结合数据库号段模式的优缺点和 Tinyid 的原理就能知道。
|
||||
|
||||
|
|
@ -352,3 +352,5 @@ Tinyid 的优缺点这里就不分析了,结合数据库号段模式的优缺
|
|||
通过这篇文章,我基本上已经把最常见的分布式 ID 生成方案都总结了一波。
|
||||
|
||||
除了上面介绍的方式之外,像 ZooKeeper 这类中间件也可以帮助我们生成唯一 ID。**没有银弹,一定要结合实际项目来选择最适合自己的方案。**
|
||||
|
||||
不过,本文主要介绍的是分布式 ID 的理论知识。在实际的面试中,面试官可能会结合具体的业务场景来考察你对分布式 ID 的设计,你可以参考这篇文章:[分布式 ID 设计指南](https://chat.yqcloud.top/distributed-id-design.md)(对于实际工作中分布式 ID 的设计也非常有帮助)。
|
||||
|
|
|
|||
|
|
@ -27,8 +27,8 @@ category: 分布式
|
|||
|
||||
一个最基本的分布式锁需要满足:
|
||||
|
||||
- **互斥** :任意一个时刻,锁只能被一个线程持有;
|
||||
- **高可用** :锁服务是高可用的。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。
|
||||
- **互斥**:任意一个时刻,锁只能被一个线程持有;
|
||||
- **高可用**:锁服务是高可用的。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。
|
||||
- **可重入**:一个节点获取了锁之后,还可以再次获取锁。
|
||||
|
||||
通常情况下,我们一般会选择基于 Redis 或者 ZooKeeper 实现分布式锁,Redis 用的要更多一点,我这里也以 Redis 为例介绍分布式锁的实现。
|
||||
|
|
@ -74,23 +74,23 @@ end
|
|||
|
||||
### 为什么要给锁设置一个过期时间?
|
||||
|
||||
为了避免锁无法被释放,我们可以想到的一个解决办法就是: **给这个 key(也就是锁) 设置一个过期时间** 。
|
||||
为了避免锁无法被释放,我们可以想到的一个解决办法就是:**给这个 key(也就是锁) 设置一个过期时间** 。
|
||||
|
||||
```bash
|
||||
127.0.0.1:6379> SET lockKey uniqueValue EX 3 NX
|
||||
OK
|
||||
```
|
||||
|
||||
- **lockKey** :加锁的锁名;
|
||||
- **uniqueValue** :能够唯一标示锁的随机字符串;
|
||||
- **NX** :只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
|
||||
- **EX** :过期时间设置(秒为单位)EX 3 标示这个锁有一个 3 秒的自动过期时间。与 EX 对应的是 PX(毫秒为单位),这两个都是过期时间设置。
|
||||
- **lockKey**:加锁的锁名;
|
||||
- **uniqueValue**:能够唯一标示锁的随机字符串;
|
||||
- **NX**:只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
|
||||
- **EX**:过期时间设置(秒为单位)EX 3 标示这个锁有一个 3 秒的自动过期时间。与 EX 对应的是 PX(毫秒为单位),这两个都是过期时间设置。
|
||||
|
||||
**一定要保证设置指定 key 的值和过期时间是一个原子操作!!!** 不然的话,依然可能会出现锁无法被释放的问题。
|
||||
|
||||
这样确实可以解决问题,不过,这种解决办法同样存在漏洞:**如果操作共享资源的时间大于过期时间,就会出现锁提前过期的问题,进而导致分布式锁直接失效。如果锁的超时时间设置过长,又会影响到性能。**
|
||||
|
||||
你或许在想: **如果操作共享资源的操作还未完成,锁过期时间能够自己续期就好了!**
|
||||
你或许在想:**如果操作共享资源的操作还未完成,锁过期时间能够自己续期就好了!**
|
||||
|
||||
### 如何实现锁的优雅续期?
|
||||
|
||||
|
|
@ -98,7 +98,7 @@ OK
|
|||
|
||||

|
||||
|
||||
Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,不仅仅包括多种分布式锁的实现。并且,Redisson 还支持 Redis 单机、Redis Sentinel 、Redis Cluster 等多种部署架构。
|
||||
Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,不仅仅包括多种分布式锁的实现。并且,Redisson 还支持 Redis 单机、Redis Sentinel、Redis Cluster 等多种部署架构。
|
||||
|
||||
Redisson 中的分布式锁自带自动续期机制,使用起来非常简单,原理也比较简单,其提供了一个专门用来监控和续期锁的 **Watch Dog( 看门狗)**,如果操作共享资源的线程还未执行完成的话,Watch Dog 会不断地延长锁的过期时间,进而保证锁不会因为超时而被释放。
|
||||
|
||||
|
|
@ -298,10 +298,10 @@ client.close();
|
|||
|
||||
我们通常是将 znode 分为 4 大类:
|
||||
|
||||
- **持久(PERSISTENT)节点** :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点** :临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点** :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001` 、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点** :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
|
||||
- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
|
||||
|
||||
可以看出,临时节点相比持久节点,最主要的是对会话失效的情况处理不一样,临时节点会话消失则对应的节点消失。这样的话,如果客户端发生异常导致没来得及释放锁也没关系,会话失效节点自动被删除,不会发生死锁的问题。
|
||||
|
||||
|
|
@ -315,7 +315,7 @@ client.close();
|
|||
|
||||
同一时间段内,可能会有很多客户端同时获取锁,但只有一个可以获取成功。如果获取锁失败,则说明有其他的客户端已经成功获取锁。获取锁失败的客户端并不会不停地循环去尝试加锁,而是在前一个节点注册一个事件监听器。
|
||||
|
||||
这个事件监听器的作用是: **当前一个节点对应的客户端释放锁之后(也就是前一个节点被删除之后,监听的是删除事件),通知获取锁失败的客户端(唤醒等待的线程,Java 中的 `wait/notifyAll` ),让它尝试去获取锁,然后就成功获取锁了。**
|
||||
这个事件监听器的作用是:**当前一个节点对应的客户端释放锁之后(也就是前一个节点被删除之后,监听的是删除事件),通知获取锁失败的客户端(唤醒等待的线程,Java 中的 `wait/notifyAll` ),让它尝试去获取锁,然后就成功获取锁了。**
|
||||
|
||||
### 如何实现可重入锁?
|
||||
|
||||
|
|
|
|||
|
|
@ -206,9 +206,9 @@ zkClient.start();
|
|||
对于一些基本参数的说明:
|
||||
|
||||
- `baseSleepTimeMs`:重试之间等待的初始时间
|
||||
- `maxRetries` :最大重试次数
|
||||
- `connectString` :要连接的服务器列表
|
||||
- `retryPolicy` :重试策略
|
||||
- `maxRetries`:最大重试次数
|
||||
- `connectString`:要连接的服务器列表
|
||||
- `retryPolicy`:重试策略
|
||||
|
||||
### 数据节点的增删改查
|
||||
|
||||
|
|
@ -216,10 +216,10 @@ zkClient.start();
|
|||
|
||||
我们在 [ZooKeeper 常见概念解读](./zookeeper-intro.md) 中介绍到,我们通常是将 znode 分为 4 大类:
|
||||
|
||||
- **持久(PERSISTENT)节点** :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点** :临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,临时节点 **只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点** :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001` 、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点** :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
|
||||
- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,临时节点 **只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
|
||||
|
||||
你在使用的 ZooKeeper 的时候,会发现 `CreateMode` 类中实际有 7 种 znode 类型 ,但是用的最多的还是上面介绍的 4 种。
|
||||
|
||||
|
|
|
|||
|
|
@ -55,7 +55,7 @@ ZooKeeper 将数据保存在内存中,性能是不错的。 在“读”多于
|
|||
|
||||
- **顺序一致性:** 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
|
||||
- **原子性:** 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
|
||||
- **单一系统映像 :** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
|
||||
- **单一系统映像:** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
|
||||
- **可靠性:** 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
|
||||
|
||||
### ZooKeeper 应用场景
|
||||
|
|
@ -64,9 +64,9 @@ ZooKeeper 概览中,我们介绍到使用其通常被用于实现诸如数据
|
|||
|
||||
下面选 3 个典型的应用场景来专门说说:
|
||||
|
||||
1. **命名服务** :可以通过 ZooKeeper 的顺序节点生成全局唯一 ID。
|
||||
2. **数据发布/订阅** :通过 **Watcher 机制** 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
|
||||
3. **分布式锁** : 通过创建唯一节点获得分布式锁,当获得锁的一方执行完相关代码或者是挂掉之后就释放锁。分布式锁的实现也需要用到 **Watcher 机制** ,我在 [分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 这篇文章中有详细介绍到如何基于 ZooKeeper 实现分布式锁。
|
||||
1. **命名服务**:可以通过 ZooKeeper 的顺序节点生成全局唯一 ID。
|
||||
2. **数据发布/订阅**:通过 **Watcher 机制** 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
|
||||
3. **分布式锁**:通过创建唯一节点获得分布式锁,当获得锁的一方执行完相关代码或者是挂掉之后就释放锁。分布式锁的实现也需要用到 **Watcher 机制** ,我在 [分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 这篇文章中有详细介绍到如何基于 ZooKeeper 实现分布式锁。
|
||||
|
||||
实际上,这些功能的实现基本都得益于 ZooKeeper 可以保存数据的功能,但是 ZooKeeper 不适合保存大量数据,这一点需要注意。
|
||||
|
||||
|
|
@ -90,15 +90,15 @@ ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都
|
|||
|
||||
我们通常是将 znode 分为 4 大类:
|
||||
|
||||
- **持久(PERSISTENT)节点** :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点** :临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点** :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001` 、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点** :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
|
||||
- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
|
||||
|
||||
每个 znode 由 2 部分组成:
|
||||
|
||||
- **stat** :状态信息
|
||||
- **data** : 节点存放的数据的具体内容
|
||||
- **stat**:状态信息
|
||||
- **data**:节点存放的数据的具体内容
|
||||
|
||||
如下所示,我通过 get 命令来获取 根目录下的 dubbo 节点的内容。(get 命令在下面会介绍到)。
|
||||
|
||||
|
|
@ -122,7 +122,7 @@ numChildren = 1
|
|||
|
||||
Stat 类中包含了一个数据节点的所有状态信息的字段,包括事务 ID(cZxid)、节点创建时间(ctime) 和子节点个数(numChildren) 等等。
|
||||
|
||||
下面我们来看一下每个 znode 状态信息究竟代表的是什么吧!(下面的内容来源于《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》,因为 Guide 确实也不是特别清楚,要学会参考资料的嘛! ) :
|
||||
下面我们来看一下每个 znode 状态信息究竟代表的是什么吧!(下面的内容来源于《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》,因为 Guide 确实也不是特别清楚,要学会参考资料的嘛! ):
|
||||
|
||||
| znode 状态信息 | 解释 |
|
||||
| -------------- | --------------------------------------------------------------------------------------------------- |
|
||||
|
|
@ -142,9 +142,9 @@ Stat 类中包含了一个数据节点的所有状态信息的字段,包括事
|
|||
|
||||
在前面我们已经提到,对应于每个 znode,ZooKeeper 都会为其维护一个叫作 **Stat** 的数据结构,Stat 中记录了这个 znode 的三个相关的版本:
|
||||
|
||||
- **dataVersion** :当前 znode 节点的版本号
|
||||
- **cversion** : 当前 znode 子节点的版本
|
||||
- **aclVersion** : 当前 znode 的 ACL 的版本。
|
||||
- **dataVersion**:当前 znode 节点的版本号
|
||||
- **cversion**:当前 znode 子节点的版本
|
||||
- **aclVersion**:当前 znode 的 ACL 的版本。
|
||||
|
||||
### ACL(权限控制)
|
||||
|
||||
|
|
@ -153,7 +153,7 @@ ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似
|
|||
对于 znode 操作的权限,ZooKeeper 提供了以下 5 种:
|
||||
|
||||
- **CREATE** : 能创建子节点
|
||||
- **READ** :能获取节点数据和列出其子节点
|
||||
- **READ**:能获取节点数据和列出其子节点
|
||||
- **WRITE** : 能设置/更新节点数据
|
||||
- **DELETE** : 能删除子节点
|
||||
- **ADMIN** : 能设置节点 ACL 的权限
|
||||
|
|
@ -162,9 +162,9 @@ ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似
|
|||
|
||||
对于身份认证,提供了以下几种方式:
|
||||
|
||||
- **world** : 默认方式,所有用户都可无条件访问。
|
||||
- **world**:默认方式,所有用户都可无条件访问。
|
||||
- **auth** :不使用任何 id,代表任何已认证的用户。
|
||||
- **digest** :用户名:密码认证方式: _username:password_ 。
|
||||
- **digest** :用户名:密码认证方式:_username:password_ 。
|
||||
- **ip** : 对指定 ip 进行限制。
|
||||
|
||||
### Watcher(事件监听器)
|
||||
|
|
@ -191,7 +191,7 @@ Session 有一个属性叫做:`sessionTimeout` ,`sessionTimeout` 代表会
|
|||
|
||||
上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
|
||||
|
||||
**最典型集群模式: Master/Slave 模式(主备模式)**。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
|
||||
**最典型集群模式:Master/Slave 模式(主备模式)**。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
|
||||
|
||||
### ZooKeeper 集群角色
|
||||
|
||||
|
|
@ -214,16 +214,16 @@ ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定
|
|||
这个过程大致是这样的:
|
||||
|
||||
1. **Leader election(选举阶段)**:节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
|
||||
2. **Discovery(发现阶段)** :在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
|
||||
2. **Discovery(发现阶段)**:在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
|
||||
3. **Synchronization(同步阶段)** :同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
|
||||
4. **Broadcast(广播阶段)** :到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
|
||||
|
||||
ZooKeeper 集群中的服务器状态有下面几种:
|
||||
|
||||
- **LOOKING** :寻找 Leader。
|
||||
- **LEADING** :Leader 状态,对应的节点为 Leader。
|
||||
- **FOLLOWING** :Follower 状态,对应的节点为 Follower。
|
||||
- **OBSERVING** :Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
|
||||
- **LOOKING**:寻找 Leader。
|
||||
- **LEADING**:Leader 状态,对应的节点为 Leader。
|
||||
- **FOLLOWING**:Follower 状态,对应的节点为 Follower。
|
||||
- **OBSERVING**:Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
|
||||
|
||||
### ZooKeeper 集群为啥最好奇数台?
|
||||
|
||||
|
|
@ -258,8 +258,8 @@ ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服
|
|||
|
||||
ZAB 协议包括两种基本的模式,分别是
|
||||
|
||||
- **崩溃恢复** :当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致**。
|
||||
- **消息广播** :**当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。** 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
|
||||
- **崩溃恢复**:当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致**。
|
||||
- **消息广播**:**当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。** 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
|
||||
|
||||
关于 **ZAB 协议&Paxos 算法** 需要讲和理解的东西太多了,具体可以看下面这几篇文章:
|
||||
|
||||
|
|
|
|||
|
|
@ -156,9 +156,9 @@ tag:
|
|||
|
||||
和介绍 `Paxos` 一样,在介绍 `ZAB` 协议之前,我们首先来了解一下在 `ZAB` 中三个主要的角色,`Leader 领导者`、`Follower跟随者`、`Observer观察者` 。
|
||||
|
||||
- `Leader` :集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
|
||||
- `Leader`:集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
|
||||
- `Follower`:能够接收客户端的请求,如果是读请求则可以自己处理,**如果是写请求则要转发给 `Leader`** 。在选举过程中会参与投票,**有选举权和被选举权** 。
|
||||
- `Observer` :就是没有选举权和被选举权的 `Follower` 。
|
||||
- `Observer`:就是没有选举权和被选举权的 `Follower` 。
|
||||
|
||||
在 `ZAB` 协议中对 `zkServer`(即上面我们说的三个角色的总称) 还有两种模式的定义,分别是 **消息广播** 和 **崩溃恢复** 。
|
||||
|
||||
|
|
@ -230,7 +230,7 @@ tag:
|
|||
|
||||
了解了 `ZAB` 协议还不够,它仅仅是 `Zookeeper` 内部实现的一种方式,而我们如何通过 `Zookeeper` 去做一些典型的应用场景呢?比如说集群管理,分布式锁,`Master` 选举等等。
|
||||
|
||||
这就涉及到如何使用 `Zookeeper` 了,但在使用之前我们还需要掌握几个概念。比如 `Zookeeper` 的 **数据模型** 、**会话机制**、**ACL**、**Watcher 机制** 等等。
|
||||
这就涉及到如何使用 `Zookeeper` 了,但在使用之前我们还需要掌握几个概念。比如 `Zookeeper` 的 **数据模型**、**会话机制**、**ACL**、**Watcher 机制** 等等。
|
||||
|
||||
### 数据模型
|
||||
|
||||
|
|
@ -247,12 +247,12 @@ tag:
|
|||
- 临时节点:临时节点的生命周期是与 **客户端会话** 绑定的,**会话消失则节点消失** 。临时节点 **只能做叶子节点** ,不能创建子节点。
|
||||
- 临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
|
||||
|
||||
节点状态中包含了很多节点的属性比如 `czxid` 、`mzxid` 等等,在 `zookeeper` 中是使用 `Stat` 这个类来维护的。下面我列举一些属性解释。
|
||||
节点状态中包含了很多节点的属性比如 `czxid`、`mzxid` 等等,在 `zookeeper` 中是使用 `Stat` 这个类来维护的。下面我列举一些属性解释。
|
||||
|
||||
- `czxid`:`Created ZXID`,该数据节点被 **创建** 时的事务 ID。
|
||||
- `mzxid`:`Modified ZXID`,节点 **最后一次被更新时** 的事务 ID。
|
||||
- `ctime`:`Created Time`,该节点被创建的时间。
|
||||
- `mtime`: `Modified Time`,该节点最后一次被修改的时间。
|
||||
- `mtime`:`Modified Time`,该节点最后一次被修改的时间。
|
||||
- `version`:节点的版本号。
|
||||
- `cversion`:**子节点** 的版本号。
|
||||
- `aversion`:节点的 `ACL` 版本号。
|
||||
|
|
@ -265,13 +265,13 @@ tag:
|
|||
|
||||
我想这个对于后端开发的朋友肯定不陌生,不就是 `session` 吗?只不过 `zk` 客户端和服务端是通过 **`TCP` 长连接** 维持的会话机制,其实对于会话来说你可以理解为 **保持连接状态** 。
|
||||
|
||||
在 `zookeeper` 中,会话还有对应的事件,比如 `CONNECTION_LOSS 连接丢失事件` 、`SESSION_MOVED 会话转移事件` 、`SESSION_EXPIRED 会话超时失效事件` 。
|
||||
在 `zookeeper` 中,会话还有对应的事件,比如 `CONNECTION_LOSS 连接丢失事件`、`SESSION_MOVED 会话转移事件`、`SESSION_EXPIRED 会话超时失效事件` 。
|
||||
|
||||
### ACL
|
||||
|
||||
`ACL` 为 `Access Control Lists` ,它是一种权限控制。在 `zookeeper` 中定义了 5 种权限,它们分别为:
|
||||
|
||||
- `CREATE` :创建子节点的权限。
|
||||
- `CREATE`:创建子节点的权限。
|
||||
- `READ`:获取节点数据和子节点列表的权限。
|
||||
- `WRITE`:更新节点数据的权限。
|
||||
- `DELETE`:删除子节点的权限。
|
||||
|
|
@ -305,7 +305,7 @@ tag:
|
|||
|
||||
### 分布式锁
|
||||
|
||||
分布式锁的实现方式有很多种,比如 `Redis` 、数据库 、`zookeeper` 等。个人认为 `zookeeper` 在实现分布式锁这方面是非常非常简单的。
|
||||
分布式锁的实现方式有很多种,比如 `Redis`、数据库、`zookeeper` 等。个人认为 `zookeeper` 在实现分布式锁这方面是非常非常简单的。
|
||||
|
||||
上面我们已经提到过了 **zk 在高并发的情况下保证节点创建的全局唯一性**,这玩意一看就知道能干啥了。实现互斥锁呗,又因为能在分布式的情况下,所以能实现分布式锁呗。
|
||||
|
||||
|
|
@ -359,7 +359,7 @@ tag:
|
|||
|
||||
- 分布式与集群的区别
|
||||
|
||||
- `2PC` 、`3PC` 以及 `paxos` 算法这些一致性框架的原理和实现。
|
||||
- `2PC`、`3PC` 以及 `paxos` 算法这些一致性框架的原理和实现。
|
||||
|
||||
- `zookeeper` 专门的一致性算法 `ZAB` 原子广播协议的内容(`Leader` 选举、崩溃恢复、消息广播)。
|
||||
|
||||
|
|
|
|||
|
|
@ -53,7 +53,7 @@ CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细
|
|||
|
||||
**选择 CP 还是 AP 的关键在于当前的业务场景,没有定论,比如对于需要确保强一致性的场景如银行一般会选择保证 CP 。**
|
||||
|
||||
另外,需要补充说明的一点是: **如果网络分区正常的话(系统在绝大部分时候所处的状态),也就说不需要保证 P 的时候,C 和 A 能够同时保证。**
|
||||
另外,需要补充说明的一点是:**如果网络分区正常的话(系统在绝大部分时候所处的状态),也就说不需要保证 P 的时候,C 和 A 能够同时保证。**
|
||||
|
||||
### CAP 实际应用案例
|
||||
|
||||
|
|
@ -93,7 +93,7 @@ CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细
|
|||
|
||||
### 简介
|
||||
|
||||
**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
|
||||
**BASE** 是 **Basically Available(基本可用)**、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
|
||||
|
||||
### BASE 理论的核心思想
|
||||
|
||||
|
|
@ -134,11 +134,11 @@ CAP 理论这节我们也说过了:
|
|||
|
||||
> 分布式一致性的 3 种级别:
|
||||
>
|
||||
> 1. **强一致性** :系统写入了什么,读出来的就是什么。
|
||||
> 1. **强一致性**:系统写入了什么,读出来的就是什么。
|
||||
>
|
||||
> 2. **弱一致性** :不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
|
||||
> 2. **弱一致性**:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
|
||||
>
|
||||
> 3. **最终一致性** :弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
|
||||
> 3. **最终一致性**:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
|
||||
>
|
||||
> **业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。**
|
||||
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@ Gossip 协议最早是在 ACM 上的一篇 1987 年发表的论文 [《Epidemic
|
|||
|
||||
在 Gossip 协议下,没有所谓的中心节点,每个节点周期性地随机找一个节点互相同步彼此的信息,理论上来说,各个节点的状态最终会保持一致。
|
||||
|
||||
下面我们来对 Gossip 协议的定义做一个总结: **Gossip 协议是一种允许在分布式系统中共享状态的去中心化通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。**
|
||||
下面我们来对 Gossip 协议的定义做一个总结:**Gossip 协议是一种允许在分布式系统中共享状态的去中心化通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。**
|
||||
|
||||
## Gossip 协议应用
|
||||
|
||||
|
|
@ -44,9 +44,9 @@ Redis Cluster 是一个典型的分布式系统,分布式系统中的各个节
|
|||
|
||||
Redis Cluster 的节点之间会相互发送多种 Gossip 消息:
|
||||
|
||||
- **MEET** :在 Redis Cluster 中的某个 Redis 节点上执行 `CLUSTER MEET ip port` 命令,可以向指定的 Redis 节点发送一条 MEET 信息,用于将其添加进 Redis Cluster 成为新的 Redis 节点。
|
||||
- **PING/PONG** :Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。
|
||||
- **FAIL** :Redis Cluster 中的节点 A 发现 B 节点 PFAIL ,并且在下线报告的有效期限内集群中半数以上的节点将 B 节点标记为 PFAIL,节点 A 就会向集群广播一条 FAIL 消息,通知其他节点将故障节点 B 标记为 FAIL 。
|
||||
- **MEET**:在 Redis Cluster 中的某个 Redis 节点上执行 `CLUSTER MEET ip port` 命令,可以向指定的 Redis 节点发送一条 MEET 信息,用于将其添加进 Redis Cluster 成为新的 Redis 节点。
|
||||
- **PING/PONG**:Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。
|
||||
- **FAIL**:Redis Cluster 中的节点 A 发现 B 节点 PFAIL ,并且在下线报告的有效期限内集群中半数以上的节点将 B 节点标记为 PFAIL,节点 A 就会向集群广播一条 FAIL 消息,通知其他节点将故障节点 B 标记为 FAIL 。
|
||||
- ......
|
||||
|
||||
下图就是主从架构的 Redis Cluster 的示意图,图中的虚线代表的就是各个节点之间使用 Gossip 进行通信 ,实线表示主从复制。
|
||||
|
|
@ -133,7 +133,7 @@ Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)**
|
|||
## 总结
|
||||
|
||||
- Gossip 协议是一种允许在分布式系统中共享状态的通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。
|
||||
- Gossip 协议被 Redis 、Apache Cassandra、Consul 等项目应用。
|
||||
- Gossip 协议被 Redis、Apache Cassandra、Consul 等项目应用。
|
||||
- 谣言传播(Rumor-Mongering)比较适合节点数量比较多或者节点动态变化的场景。
|
||||
|
||||
## 参考
|
||||
|
|
|
|||
|
|
@ -36,14 +36,14 @@ Paxos 算法是第一个被证明完备的分布式系统共识算法。共识
|
|||
|
||||
兰伯特当时提出的 Paxos 算法主要包含 2 个部分:
|
||||
|
||||
- **Basic Paxos 算法** : 描述的是多节点之间如何就某个值(提案 Value)达成共识。
|
||||
- **Multi-Paxos 思想** : 描述的是执行多个 Basic Paxos 实例,就一系列值达成共识。Multi-Paxos 说白了就是执行多次 Basic Paxos ,核心还是 Basic Paxos 。
|
||||
- **Basic Paxos 算法**:描述的是多节点之间如何就某个值(提案 Value)达成共识。
|
||||
- **Multi-Paxos 思想**:描述的是执行多个 Basic Paxos 实例,就一系列值达成共识。Multi-Paxos 说白了就是执行多次 Basic Paxos ,核心还是 Basic Paxos 。
|
||||
|
||||
由于 Paxos 算法在国际上被公认的非常难以理解和实现,因此不断有人尝试简化这一算法。到了 2013 年才诞生了一个比 Paxos 算法更易理解和实现的共识算法—[Raft 算法](https://javaguide.cn/distributed-system/theorem&algorithm&protocol/raft-algorithm.html) 。更具体点来说,Raft 是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现。
|
||||
|
||||
针对没有恶意节点的情况,除了 Raft 算法之外,当前最常用的一些共识算法比如 **ZAB 协议** 、 **Fast Paxos** 算法都是基于 Paxos 算法改进的。
|
||||
针对没有恶意节点的情况,除了 Raft 算法之外,当前最常用的一些共识算法比如 **ZAB 协议**、 **Fast Paxos** 算法都是基于 Paxos 算法改进的。
|
||||
|
||||
针对存在恶意节点的情况,一般使用的是 **工作量证明(POW,Proof-of-Work)** 、 **权益证明(PoS,Proof-of-Stake )** 等共识算法。这类共识算法最典型的应用就是区块链,就比如说前段时间以太坊官方宣布其共识机制正在从工作量证明(PoW)转变为权益证明(PoS)。
|
||||
针对存在恶意节点的情况,一般使用的是 **工作量证明(POW,Proof-of-Work)**、 **权益证明(PoS,Proof-of-Stake )** 等共识算法。这类共识算法最典型的应用就是区块链,就比如说前段时间以太坊官方宣布其共识机制正在从工作量证明(PoW)转变为权益证明(PoS)。
|
||||
|
||||
区块链系统使用的共识算法需要解决的核心问题是 **拜占庭将军问题** ,这和我们日常接触到的 ZooKeeper、Etcd、Consul 等分布式中间件不太一样。
|
||||
|
||||
|
|
@ -69,7 +69,7 @@ Basic Paxos 中存在 3 个重要的角色:
|
|||
|
||||
Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Basic Paxos 思想。
|
||||
|
||||
⚠️**注意** : Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
|
||||
⚠️**注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
|
||||
|
||||
由于兰伯特提到的 Multi-Paxos 思想缺少代码实现的必要细节(比如怎么选举领导者),所以在理解和实现上比较困难。
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ tag:
|
|||
- rpc
|
||||
---
|
||||
|
||||
> 说明: Dubbo3 已经发布,这篇文章是基于 Dubbo2 写的。Dubbo3 基于 Dubbo2 演进而来,在保持原有核心功能特性的同时, Dubbo3 在易用性、超大规模微服务实践、云原生基础设施适配、安全设计等几大方向上进行了全面升级。
|
||||
> 说明:Dubbo3 已经发布,这篇文章是基于 Dubbo2 写的。Dubbo3 基于 Dubbo2 演进而来,在保持原有核心功能特性的同时, Dubbo3 在易用性、超大规模微服务实践、云原生基础设施适配、安全设计等几大方向上进行了全面升级。
|
||||
|
||||
这篇文章是我根据官方文档以及自己平时的使用情况,对 Dubbo 所做的一个总结。欢迎补充!
|
||||
|
||||
|
|
@ -28,7 +28,7 @@ tag:
|
|||
|
||||

|
||||
|
||||
简单来说就是: **Dubbo 不光可以帮助我们调用远程服务,还提供了一些其他开箱即用的功能比如智能负载均衡。**
|
||||
简单来说就是:**Dubbo 不光可以帮助我们调用远程服务,还提供了一些其他开箱即用的功能比如智能负载均衡。**
|
||||
|
||||
Dubbo 目前已经有接近 34.4 k 的 Star 。
|
||||
|
||||
|
|
@ -40,7 +40,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
|
|||
|
||||
### 为什么要用 Dubbo?
|
||||
|
||||
随着互联网的发展,网站的规模越来越大,用户数量越来越多。单一应用架构 、垂直应用架构无法满足我们的需求,这个时候分布式服务架构就诞生了。
|
||||
随着互联网的发展,网站的规模越来越大,用户数量越来越多。单一应用架构、垂直应用架构无法满足我们的需求,这个时候分布式服务架构就诞生了。
|
||||
|
||||
分布式服务架构下,系统被拆分成不同的服务比如短信服务、安全服务,每个服务独立提供系统的某个核心服务。
|
||||
|
||||
|
|
@ -48,9 +48,9 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
|
|||
|
||||
不过,Dubbo 的出现让上述问题得到了解决。**Dubbo 帮助我们解决了什么问题呢?**
|
||||
|
||||
1. **负载均衡** : 同一个服务部署在不同的机器时该调用哪一台机器上的服务。
|
||||
2. **服务调用链路生成** : 随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
|
||||
3. **服务访问压力以及时长统计、资源调度和治理** :基于访问压力实时管理集群容量,提高集群利用率。
|
||||
1. **负载均衡**:同一个服务部署在不同的机器时该调用哪一台机器上的服务。
|
||||
2. **服务调用链路生成**:随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
|
||||
3. **服务访问压力以及时长统计、资源调度和治理**:基于访问压力实时管理集群容量,提高集群利用率。
|
||||
4. ......
|
||||
|
||||
|
||||
|
|
@ -120,7 +120,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
|
|||
- **protocol 远程调用层**:封装 RPC 调用,以 `Invocation`, `Result` 为中心。
|
||||
- **exchange 信息交换层**:封装请求响应模式,同步转异步,以 `Request`, `Response` 为中心。
|
||||
- **transport 网络传输层**:抽象 mina 和 netty 为统一接口,以 `Message` 为中心。
|
||||
- **serialize 数据序列化层** :对需要在网络传输的数据进行序列化。
|
||||
- **serialize 数据序列化层**:对需要在网络传输的数据进行序列化。
|
||||
|
||||
### Dubbo 的 SPI 机制了解么? 如何扩展 Dubbo 中的默认实现?
|
||||
|
||||
|
|
@ -190,7 +190,7 @@ Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来
|
|||
|
||||
正是因为 Dubbo 基于微内核架构,才使得我们可以随心所欲替换 Dubbo 的功能点。比如你觉得 Dubbo 的序列化模块实现的不满足自己要求,没关系啊!你自己实现一个序列化模块就好了啊!
|
||||
|
||||
通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自己造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件 :**JDK 标准的 SPI 扩展机制** (`java.util.ServiceLoader`)。
|
||||
通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自己造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件:**JDK 标准的 SPI 扩展机制** (`java.util.ServiceLoader`)。
|
||||
|
||||
### 关于 Dubbo 架构的一些自测小问题
|
||||
|
||||
|
|
@ -441,7 +441,7 @@ Dubbo 默认使用的序列化方式是 hessian2。
|
|||
一般我们不会直接使用 JDK 自带的序列化方式。主要原因有两个:
|
||||
|
||||
1. **不支持跨语言调用** : 如果调用的是其他语言开发的服务的时候就不支持了。
|
||||
2. **性能差** :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
|
||||
2. **性能差**:相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
|
||||
|
||||
JSON 序列化由于性能问题,我们一般也不会考虑使用。
|
||||
|
||||
|
|
|
|||
|
|
@ -23,11 +23,11 @@ tag:
|
|||
|
||||
为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC 的 核心功能看作是下面 👇 5 个部分实现的:
|
||||
|
||||
1. **客户端(服务消费端)** :调用远程方法的一端。
|
||||
1. **客户端 Stub(桩)** : 这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
|
||||
1. **网络传输** : 网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
|
||||
1. **服务端 Stub(桩)** :这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
|
||||
1. **服务端(服务提供端)** :提供远程方法的一端。
|
||||
1. **客户端(服务消费端)**:调用远程方法的一端。
|
||||
1. **客户端 Stub(桩)**:这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
|
||||
1. **网络传输**:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
|
||||
1. **服务端 Stub(桩)**:这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
|
||||
1. **服务端(服务提供端)**:提供远程方法的一端。
|
||||
|
||||
具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
|
||||
|
||||
|
|
@ -66,7 +66,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
|
|||
|
||||
Dubbo 算的是比较优秀的国产开源项目了,它的源码也是非常值得学习和阅读的!
|
||||
|
||||
- Github :[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo "https://github.com/apache/incubator-dubbo")
|
||||
- GitHub:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo "https://github.com/apache/incubator-dubbo")
|
||||
- 官网:https://dubbo.apache.org/zh/
|
||||
|
||||
### Motan
|
||||
|
|
@ -94,7 +94,7 @@ gRPC 是 Google 开源的一个高性能、通用的开源 RPC 框架。其由
|
|||
|
||||
不过,gRPC 的设计导致其几乎没有服务治理能力。如果你想要解决这个问题的话,就需要依赖其他组件比如腾讯的 PolarisMesh(北极星)了。
|
||||
|
||||
- Github:[https://github.com/grpc/grpc](https://github.com/grpc/grpc "https://github.com/grpc/grpc")
|
||||
- GitHub:[https://github.com/grpc/grpc](https://github.com/grpc/grpc "https://github.com/grpc/grpc")
|
||||
- 官网:[https://grpc.io/](https://grpc.io/ "https://grpc.io/")
|
||||
|
||||
### Thrift
|
||||
|
|
@ -130,7 +130,7 @@ Dubbo 也是 Spring Cloud Alibaba 里面的一个组件。
|
|||
|
||||
麻雀虽小五脏俱全,项目代码注释详细,结构清晰,并且集成了 Check Style 规范代码结构,非常适合阅读和学习。
|
||||
|
||||
**内容概览** :
|
||||
**内容概览**:
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -17,8 +17,8 @@ Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链
|
|||
|
||||
Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
|
||||
|
||||
- Github 地址 : <https://github.com/spring-cloud/spring-cloud-gateway>
|
||||
- 官网 : <https://spring.io/projects/spring-cloud-gateway>
|
||||
- GitHub 地址: <https://github.com/spring-cloud/spring-cloud-gateway>
|
||||
- 官网: <https://spring.io/projects/spring-cloud-gateway>
|
||||
|
||||
## Spring Cloud Gateway 的工作流程?
|
||||
|
||||
|
|
@ -30,7 +30,7 @@ Spring Cloud Gateway 的工作流程如下图所示:
|
|||
|
||||
具体的流程分析:
|
||||
|
||||
1. **路由判断** :客户端的请求到达网关后,先经过 Gateway Handler Mapping 处理,这里面会做断言(Predicate)判断,看下符合哪个路由规则,这个路由映射后端的某个服务。
|
||||
1. **路由判断**:客户端的请求到达网关后,先经过 Gateway Handler Mapping 处理,这里面会做断言(Predicate)判断,看下符合哪个路由规则,这个路由映射后端的某个服务。
|
||||
2. **请求过滤**:然后请求到达 Gateway Web Handler,这里面有很多过滤器,组成过滤器链(Filter Chain),这些过滤器可以对请求进行拦截和修改,比如添加请求头、参数校验等等,有点像净化污水。然后将请求转发到实际的后端服务。这些过滤器逻辑上可以称作 Pre-Filters,Pre 可以理解为“在...之前”。
|
||||
3. **服务处理**:后端服务会对请求进行处理。
|
||||
4. **响应过滤**:后端处理完结果后,返回给 Gateway 的过滤器再次做处理,逻辑上可以称作 Post-Filters,Post 可以理解为“在...之后”。
|
||||
|
|
@ -94,7 +94,7 @@ Spring Cloud Gateway 作为微服务的入口,需要尽量避免重启,而
|
|||
|
||||
```yaml
|
||||
filters: #过滤器
|
||||
- RewritePath=/api/(?<segment>.*),/$\{segment} # 将跳转路径中包含的 “api” 替换成空
|
||||
- RewritePath=/api/(?<segment>.*),/$\{segment} # 将跳转路径中包含的 “api” 替换成空
|
||||
```
|
||||
|
||||
当然我们也可以自定义过滤器,本篇不做展开。
|
||||
|
|
@ -152,4 +152,4 @@ public class GlobalErrorWebExceptionHandler implements ErrorWebExceptionHandler
|
|||
|
||||
- Spring Cloud Gateway 官方文档:<https://cloud.spring.io/spring-cloud-gateway/reference/html/>
|
||||
- Creating a custom Spring Cloud Gateway Filter:<https://spring.io/blog/2022/08/26/creating-a-custom-spring-cloud-gateway-filter>
|
||||
- 全局异常处理: <https://zhuanlan.zhihu.com/p/347028665>
|
||||
- 全局异常处理: <https://zhuanlan.zhihu.com/p/347028665>
|
||||
|
|
|
|||
|
|
@ -188,15 +188,15 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
|
|||
|
||||
分布式限流常见的方案:
|
||||
|
||||
- **借助中间件架限流** :可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
|
||||
- **网关层限流** :比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现`RedisRateLimiter`就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
|
||||
- **借助中间件架限流**:可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
|
||||
- **网关层限流**:比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现`RedisRateLimiter`就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
|
||||
|
||||
如果你要基于 Redis 来手动实现限流逻辑的话,建议配合 Lua 脚本来做。
|
||||
|
||||
**为什么建议 Redis+Lua 的方式?** 主要有两点原因:
|
||||
|
||||
- **减少了网络开销** :我们可以利用 Lua 脚本来批量执行多条 Redis 命令,这些 Redis 命令会被提交到 Redis 服务器一次性执行完成,大幅减小了网络开销。
|
||||
- **原子性** :一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
|
||||
- **减少了网络开销**:我们可以利用 Lua 脚本来批量执行多条 Redis 命令,这些 Redis 命令会被提交到 Redis 服务器一次性执行完成,大幅减小了网络开销。
|
||||
- **原子性**:一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
|
||||
|
||||
我这里就不放具体的限流脚本代码了,网上也有很多现成的优秀的限流脚本供你参考,就比如 Apache 网关项目 ShenYu 的 RateLimiter 限流插件就基于 Redis + Lua 实现了令牌桶算法/并发令牌桶算法、漏桶算法、滑动窗口算法。
|
||||
|
||||
|
|
@ -206,6 +206,6 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
|
|||
|
||||
## 相关阅读
|
||||
|
||||
- 服务治理之轻量级熔断框架 Resilience4j :<https://xie.infoq.cn/article/14786e571c1a4143ad1ef8f19>
|
||||
- 服务治理之轻量级熔断框架 Resilience4j:<https://xie.infoq.cn/article/14786e571c1a4143ad1ef8f19>
|
||||
- 超详细的 Guava RateLimiter 限流原理解析:<https://cloud.tencent.com/developer/article/1408819>
|
||||
- 实战 Spring Cloud Gateway 之限流篇 👍:<https://www.aneasystone.com/archives/2020/08/spring-cloud-gateway-current-limiting.html>
|
||||
|
|
|
|||
|
|
@ -80,7 +80,7 @@ category: 高可用
|
|||
1. QPS(Query Per Second):服务器每秒可以执行的查询次数;
|
||||
2. TPS(Transaction Per Second):服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
|
||||
3. 并发数;系统能同时处理请求的数目即同时提交请求的用户数目。
|
||||
4. 响应时间: 一般取多次请求的平均响应时间
|
||||
4. 响应时间:一般取多次请求的平均响应时间
|
||||
|
||||
理清他们的概念,就很容易搞清楚他们之间的关系了。
|
||||
|
||||
|
|
@ -125,10 +125,10 @@ category: 高可用
|
|||
|
||||
没记错的话,除了 LoadRunner 其他几款性能测试工具都是开源免费的。
|
||||
|
||||
1. Jmeter :Apache JMeter 是 JAVA 开发的性能测试工具。
|
||||
1. Jmeter:Apache JMeter 是 JAVA 开发的性能测试工具。
|
||||
2. LoadRunner:一款商业的性能测试工具。
|
||||
3. Galtling :一款基于 Scala 开发的高性能服务器性能测试工具。
|
||||
4. ab :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
|
||||
3. Galtling:一款基于 Scala 开发的高性能服务器性能测试工具。
|
||||
4. ab:全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
|
||||
|
||||
### 5.2 前端常用
|
||||
|
||||
|
|
|
|||
|
|
@ -11,14 +11,14 @@ category: 高可用
|
|||
|
||||
实际上,日常生活中就有非常多的冗余思想的应用。
|
||||
|
||||
拿我自己来说,我对于重要文件的保存方法就是冗余思想的应用。我日常所使用的重要文件都会同步一份在 Github 以及个人云盘上,这样就可以保证即使电脑硬盘损坏,我也可以通过 Github 或者个人云盘找回自己的重要文件。
|
||||
拿我自己来说,我对于重要文件的保存方法就是冗余思想的应用。我日常所使用的重要文件都会同步一份在 GitHub 以及个人云盘上,这样就可以保证即使电脑硬盘损坏,我也可以通过 GitHub 或者个人云盘找回自己的重要文件。
|
||||
|
||||
高可用集群(High Availability Cluster,简称 HA Cluster)、同城灾备、异地灾备、同城多活和异地多活是冗余思想在高可用系统设计中最典型的应用。
|
||||
|
||||
- **高可用集群** : 同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。
|
||||
- **同城灾备** :一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。
|
||||
- **异地灾备** :类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中
|
||||
- **同城多活** :类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。
|
||||
- **同城灾备**:一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。
|
||||
- **异地灾备**:类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中
|
||||
- **同城多活**:类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。
|
||||
- **异地多活** : 将服务部署在异地的不同机房中,并且,它们可以同时对外提供服务。
|
||||
|
||||
高可用集群单纯是服务的冗余,并没有强调地域。同城灾备、异地灾备、同城多活和异地多活实现了地域上的冗余。
|
||||
|
|
|
|||
|
|
@ -19,8 +19,8 @@ category: 高可用
|
|||
|
||||
我们平时接触到的超时可以简单分为下面 2 种:
|
||||
|
||||
- **连接超时(ConnectTimeout)** :客户端与服务端建立连接的最长等待时间。
|
||||
- **读取超时(ReadTimeout)** :客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。
|
||||
- **连接超时(ConnectTimeout)**:客户端与服务端建立连接的最长等待时间。
|
||||
- **读取超时(ReadTimeout)**:客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。
|
||||
|
||||
一些连接池客户端框架中可能还会有获取连接超时和空闲连接清理超时。
|
||||
|
||||
|
|
|
|||
|
|
@ -16,8 +16,8 @@ head:
|
|||
|
||||
我们可以将内容分发网络拆开来看:
|
||||
|
||||
- 内容 :指的是静态资源比如图片、视频、文档、JS、CSS、HTML。
|
||||
- 分发网络 :指的是将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,这样,就可以实现静态资源的就近访问比如北京的用户直接访问北京机房的数据。
|
||||
- 内容:指的是静态资源比如图片、视频、文档、JS、CSS、HTML。
|
||||
- 分发网络:指的是将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,这样,就可以实现静态资源的就近访问比如北京的用户直接访问北京机房的数据。
|
||||
|
||||
所以,简单来说,**CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。**
|
||||
|
||||
|
|
@ -99,7 +99,7 @@ CDN 服务提供商几乎都提供了这种比较基础的防盗链机制。
|
|||
http://cdn.wangsu.com/4/123.mp3? wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312
|
||||
```
|
||||
|
||||
- `wsSecret` :签名字符串。
|
||||
- `wsSecret`:签名字符串。
|
||||
- `wsTime`: 过期时间。
|
||||
|
||||
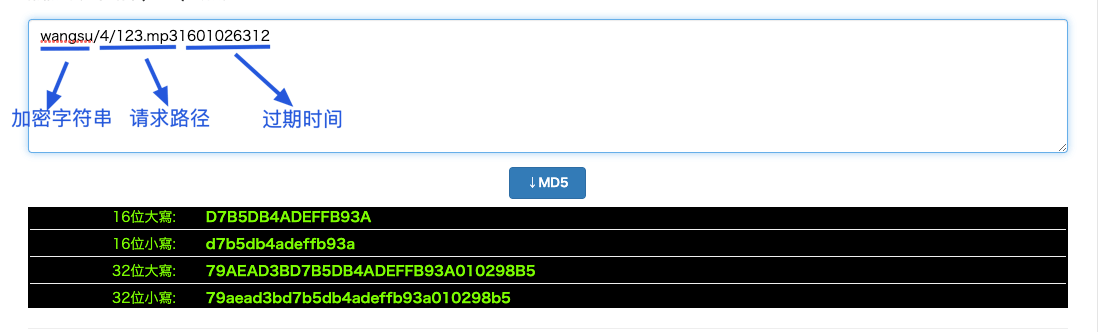
|
||||
|
|
|
|||
|
|
@ -161,18 +161,18 @@ Ribbon 是老牌负载均衡组件,由 Netflix 开发,功能比较全面,
|
|||
|
||||
Ribbon 支持的 7 种负载均衡策略:
|
||||
|
||||
- `RandomRule` :随机策略。
|
||||
- `RoundRobinRule`(默认) :轮询策略
|
||||
- `WeightedResponseTimeRule` :权重(根据响应时间决定权重)策略
|
||||
- `BestAvailableRule` :最小连接数策略
|
||||
- `RandomRule`:随机策略。
|
||||
- `RoundRobinRule`(默认):轮询策略
|
||||
- `WeightedResponseTimeRule`:权重(根据响应时间决定权重)策略
|
||||
- `BestAvailableRule`:最小连接数策略
|
||||
- `RetryRule`:重试策略(按照轮询策略来获取服务,如果获取的服务实例为 null 或已经失效,则在指定的时间之内不断地进行重试来获取服务,如果超过指定时间依然没获取到服务实例则返回 null)
|
||||
- `AvailabilityFilteringRule` :可用敏感性策略(先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例)
|
||||
- `ZoneAvoidanceRule` :区域敏感性策略(根据服务所在区域的性能和服务的可用性来选择服务实例)
|
||||
- `AvailabilityFilteringRule`:可用敏感性策略(先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例)
|
||||
- `ZoneAvoidanceRule`:区域敏感性策略(根据服务所在区域的性能和服务的可用性来选择服务实例)
|
||||
|
||||
Spring Cloud Load Balancer 支持的 2 种负载均衡策略:
|
||||
|
||||
- `RandomLoadBalancer` :随机策略
|
||||
- `RoundRobinLoadBalancer`(默认) :轮询策略
|
||||
- `RandomLoadBalancer`:随机策略
|
||||
- `RoundRobinLoadBalancer`(默认):轮询策略
|
||||
|
||||
```java
|
||||
public class CustomLoadBalancerConfiguration {
|
||||
|
|
@ -192,8 +192,8 @@ public class CustomLoadBalancerConfiguration {
|
|||
|
||||
这里举两个官方的例子:
|
||||
|
||||
- `ZonePreferenceServiceInstanceListSupplier` :实现基于区域的负载平衡
|
||||
- `HintBasedServiceInstanceListSupplier` :实现基于 hint 提示的负载均衡
|
||||
- `ZonePreferenceServiceInstanceListSupplier`:实现基于区域的负载平衡
|
||||
- `HintBasedServiceInstanceListSupplier`:实现基于 hint 提示的负载均衡
|
||||
|
||||
```java
|
||||
public class CustomLoadBalancerConfiguration {
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@ Disruptor 是一个相对冷门一些的知识点,不过,如果你的项目
|
|||
|
||||
Disruptor 是一个开源的高性能内存队列,诞生初衷是为了解决内存队列的性能和内存安全问题,由英国外汇交易公司 LMAX 开发。
|
||||
|
||||
根据 Disruptor 官方介绍,基于 Disruptor 开发的系统 LMAX(新的零售金融交易平台),单线程就能支撑每秒 600 万订单。Martin Fowler 在 2011年写的一篇文章 [The LMAX Architecture](https://martinfowler.com/articles/lmax.html) 中专门介绍过这个 LMAX 系统的架构,感兴趣的可以看看这篇文章。。
|
||||
根据 Disruptor 官方介绍,基于 Disruptor 开发的系统 LMAX(新的零售金融交易平台),单线程就能支撑每秒 600 万订单。Martin Fowler 在 2011 年写的一篇文章 [The LMAX Architecture](https://martinfowler.com/articles/lmax.html) 中专门介绍过这个 LMAX 系统的架构,感兴趣的可以看看这篇文章。。
|
||||
|
||||
LMAX 公司 2010 年在 QCon 演讲后,Disruptor 获得了业界关注,并获得了 2011 年的 Oracle 官方的 Duke's Choice Awards(Duke 选择大奖)。
|
||||
|
||||
|
|
@ -25,7 +25,7 @@ LMAX 公司 2010 年在 QCon 演讲后,Disruptor 获得了业界关注,并
|
|||
|
||||
> “Duke 选择大奖”旨在表彰过去一年里全球个人或公司开发的、最具影响力的 Java 技术应用,由甲骨文公司主办。含金量非常高!
|
||||
|
||||
我专门找到了 Oracle 官方当年颁布获得 Duke's Choice Awards 项目的那篇文章(文章地址:https://blogs.oracle.com/java/post/and-the-winners-arethe-dukes-choice-award) 。从文中可以看出,同年获得此大奖荣誉的还有大名鼎鼎的 Netty 、JRebel 等项目。
|
||||
我专门找到了 Oracle 官方当年颁布获得 Duke's Choice Awards 项目的那篇文章(文章地址:https://blogs.oracle.com/java/post/and-the-winners-arethe-dukes-choice-award) 。从文中可以看出,同年获得此大奖荣誉的还有大名鼎鼎的 Netty、JRebel 等项目。
|
||||
|
||||
|
||||
|
||||
|
|
@ -40,7 +40,7 @@ Disruptor 提供的功能优点类似于 Kafka、RocketMQ 这类分布式队列
|
|||
|
||||
Disruptor 主要解决了 JDK 内置线程安全队列的性能和内存安全问题。
|
||||
|
||||
**JDK 中常见的线程安全的队列如下** :
|
||||
**JDK 中常见的线程安全的队列如下**:
|
||||
|
||||
| 队列名字 | 锁 | 是否有界 |
|
||||
| ----------------------- | ----------------------- | -------- |
|
||||
|
|
@ -65,33 +65,33 @@ Disruptor 真的很快,关于它为什么这么快这个问题,会在后文
|
|||
|
||||
## Kafka 和 Disruptor 什么区别?
|
||||
|
||||
- **Kafka** :分布式消息队列,一般用在系统或者服务之间的消息传递,还可以被用作流式处理平台。
|
||||
- **Disruptor** :内存级别的消息队列,一般用在系统内部中线程间的消息传递。
|
||||
- **Kafka**:分布式消息队列,一般用在系统或者服务之间的消息传递,还可以被用作流式处理平台。
|
||||
- **Disruptor**:内存级别的消息队列,一般用在系统内部中线程间的消息传递。
|
||||
|
||||
## 哪些组件用到了 Disruptor?
|
||||
|
||||
用到 Disruptor 的开源项目还是挺多的,这里简单举几个例子:
|
||||
|
||||
- **Log4j2** :Log4j2 是一款常用的日志框架,它基于 Disruptor 来实现异步日志。
|
||||
- **SOFATracer** :SOFATracer 是蚂蚁金服开源的分布式应用链路追踪工具,它基于 Disruptor 来实现异步日志。
|
||||
- **Log4j2**:Log4j2 是一款常用的日志框架,它基于 Disruptor 来实现异步日志。
|
||||
- **SOFATracer**:SOFATracer 是蚂蚁金服开源的分布式应用链路追踪工具,它基于 Disruptor 来实现异步日志。
|
||||
- **Storm** : Storm 是一个开源的分布式实时计算系统,它基于 Disruptor 来实现工作进程内发生的消息传递(同一 Storm 节点上的线程间,无需网络通信)。
|
||||
- **HBase** :HBase 是一个分布式列存储数据库系统,它基于 Disruptor 来提高写并发性能。
|
||||
- **HBase**:HBase 是一个分布式列存储数据库系统,它基于 Disruptor 来提高写并发性能。
|
||||
- ......
|
||||
|
||||
## Disruptor 核心概念有哪些?
|
||||
|
||||
- **Event** :你可以把 Event 理解为存放在队列中等待消费的消息对象。
|
||||
- **EventFactory** :事件工厂用于生产事件,我们在初始化 `Disruptor` 类的时候需要用到。
|
||||
- **EventHandler** :Event 在对应的 Handler 中被处理,你可以将其理解为生产消费者模型中的消费者。
|
||||
- **EventProcessor** :EventProcessor 持有特定消费者(Consumer)的 Sequence,并提供用于调用事件处理实现的事件循环(Event Loop)。
|
||||
- **Disruptor** :事件的生产和消费需要用到 `Disruptor` 对象。
|
||||
- **RingBuffer** :RingBuffer(环形数组)用于保存事件。
|
||||
- **WaitStrategy** :等待策略。决定了没有事件可以消费的时候,事件消费者如何等待新事件的到来。
|
||||
- **Producer** :生产者,只是泛指调用 `Disruptor` 对象发布事件的用户代码,Disruptor 没有定义特定接口或类型。
|
||||
- **ProducerType** :指定是单个事件发布者模式还是多个事件发布者模式(发布者和生产者的意思类似,我个人比较喜欢用发布者)。
|
||||
- **Sequencer** :Sequencer 是 Disruptor 的真正核心。此接口有两个实现类 `SingleProducerSequencer`、`MultiProducerSequencer` ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。
|
||||
- **Event**:你可以把 Event 理解为存放在队列中等待消费的消息对象。
|
||||
- **EventFactory**:事件工厂用于生产事件,我们在初始化 `Disruptor` 类的时候需要用到。
|
||||
- **EventHandler**:Event 在对应的 Handler 中被处理,你可以将其理解为生产消费者模型中的消费者。
|
||||
- **EventProcessor**:EventProcessor 持有特定消费者(Consumer)的 Sequence,并提供用于调用事件处理实现的事件循环(Event Loop)。
|
||||
- **Disruptor**:事件的生产和消费需要用到 `Disruptor` 对象。
|
||||
- **RingBuffer**:RingBuffer(环形数组)用于保存事件。
|
||||
- **WaitStrategy**:等待策略。决定了没有事件可以消费的时候,事件消费者如何等待新事件的到来。
|
||||
- **Producer**:生产者,只是泛指调用 `Disruptor` 对象发布事件的用户代码,Disruptor 没有定义特定接口或类型。
|
||||
- **ProducerType**:指定是单个事件发布者模式还是多个事件发布者模式(发布者和生产者的意思类似,我个人比较喜欢用发布者)。
|
||||
- **Sequencer**:Sequencer 是 Disruptor 的真正核心。此接口有两个实现类 `SingleProducerSequencer`、`MultiProducerSequencer` ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。
|
||||
|
||||
下面这张图摘自Disruptor 官网,展示了 LMAX 系统使用 Disruptor 的示例。
|
||||
下面这张图摘自 Disruptor 官网,展示了 LMAX 系统使用 Disruptor 的示例。
|
||||
|
||||
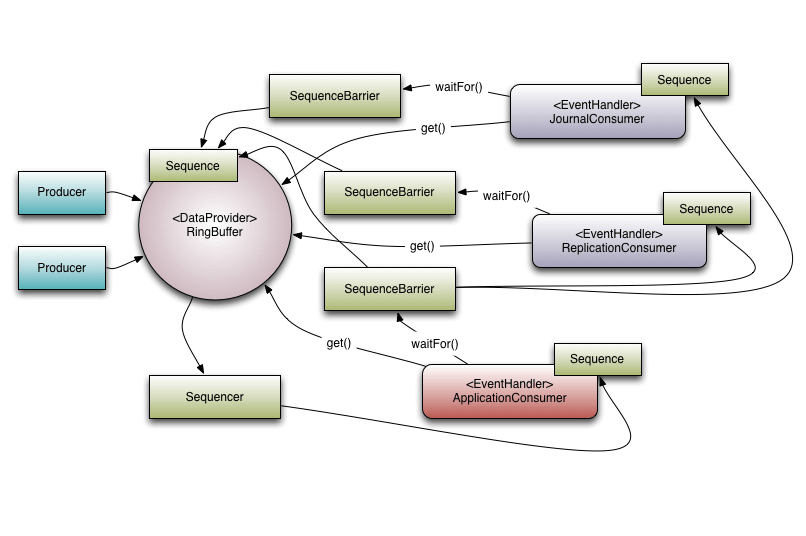
|
||||
|
||||
|
|
@ -115,18 +115,18 @@ Disruptor 真的很快,关于它为什么这么快这个问题,会在后文
|
|||
## Disruptor 为什么这么快?
|
||||
|
||||
- **RingBuffer(环形数组)** : Disruptor 内部的 RingBuffer 是通过数组实现的。由于这个数组中的所有元素在初始化时一次性全部创建,因此这些元素的内存地址一般来说是连续的。这样做的好处是,当生产者不断往 RingBuffer 中插入新的事件对象时,这些事件对象的内存地址就能够保持连续,从而利用 CPU 缓存的局部性原理,将相邻的事件对象一起加载到缓存中,提高程序的性能。这类似于 MySQL 的预读机制,将连续的几个页预读到内存里。除此之外,RingBuffer 基于数组还支持批量操作(一次处理多个元素)、还可以避免频繁的内存分配和垃圾回收(RingBuffer 是一个固定大小的数组,当向数组中添加新元素时,如果数组已满,则新元素将覆盖掉最旧的元素)。
|
||||
- **避免了伪共享问题** :CPU 缓存内部是按照 Cache Line(缓存行)管理的,一般的 Cache Line 大小在 64 字节左右。Disruptor 为了确保目标字段独占一个 Cache Line,会在目标字段前后增加了 64 个字节的填充(前 56 个字节和后 8 个字节),这样可以避免 Cache Line 的伪共享(False Sharing)问题。
|
||||
- **无锁设计** :Disruptor 采用无锁设计,避免了传统锁机制带来的竞争和延迟。Disruptor 的无锁实现起来比较复杂,主要是基于 CAS 、内存屏障(Memory Barrier)、RingBuffer 等技术实现的。
|
||||
- **避免了伪共享问题**:CPU 缓存内部是按照 Cache Line(缓存行)管理的,一般的 Cache Line 大小在 64 字节左右。Disruptor 为了确保目标字段独占一个 Cache Line,会在目标字段前后增加了 64 个字节的填充(前 56 个字节和后 8 个字节),这样可以避免 Cache Line 的伪共享(False Sharing)问题。
|
||||
- **无锁设计**:Disruptor 采用无锁设计,避免了传统锁机制带来的竞争和延迟。Disruptor 的无锁实现起来比较复杂,主要是基于 CAS、内存屏障(Memory Barrier)、RingBuffer 等技术实现的。
|
||||
|
||||
综上所述,Disruptor 之所以能够如此快,是基于一系列优化策略的综合作用,既充分利用了现代 CPU 缓存结构的特点,又避免了常见的并发问题和性能瓶颈。
|
||||
|
||||
关于 Disruptor 高性能队列原理的详细介绍,可以查看这篇文章:[Disruptor 高性能队列原理浅析](https://qin.news/disruptor/) (参考了美团技术团队的[高性能队列——Disruptor](https://tech.meituan.com/2016/11/18/disruptor.html)这篇文章)。
|
||||
|
||||
🌈 这里额外补充一点 : **数组中对象元素地址连续为什么可以提高性能?**
|
||||
🌈 这里额外补充一点:**数组中对象元素地址连续为什么可以提高性能?**
|
||||
|
||||
CPU 缓存是通过将最近使用的数据存储在高速缓存中来实现更快的读取速度,并使用预取机制提前加载相邻内存的数据以利用局部性原理。
|
||||
|
||||
在计算机系统中,CPU 主要访问高速缓存和内存。高速缓存是一种速度非常快、容量相对较小的内存,通常被分为多级缓存,其中L1、L2、L3 分别表示一级缓存、二级缓存、三级缓存。越靠近 CPU 的缓存,速度越快,容量也越小。相比之下,内存容量相对较大,但速度较慢。
|
||||
在计算机系统中,CPU 主要访问高速缓存和内存。高速缓存是一种速度非常快、容量相对较小的内存,通常被分为多级缓存,其中 L1、L2、L3 分别表示一级缓存、二级缓存、三级缓存。越靠近 CPU 的缓存,速度越快,容量也越小。相比之下,内存容量相对较大,但速度较慢。
|
||||
|
||||
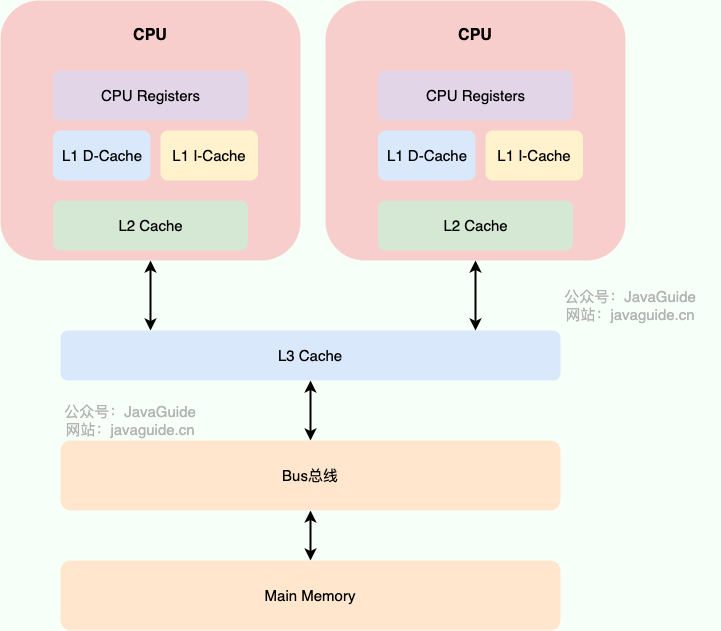
|
||||
|
||||
|
|
@ -135,4 +135,4 @@ CPU 缓存是通过将最近使用的数据存储在高速缓存中来实现更
|
|||
## 参考
|
||||
|
||||
- Disruptor 高性能之道-等待策略:<http://wuwenliang.net/2022/02/28/Disruptor高性能之道-等待策略/>
|
||||
- 《Java 并发编程实战》- 40 | 案例分析(三):高性能队列Disruptor:https://time.geekbang.org/column/article/98134
|
||||
- 《Java 并发编程实战》- 40 | 案例分析(三):高性能队列 Disruptor:https://time.geekbang.org/column/article/98134
|
||||
|
|
|
|||
|
|
@ -12,20 +12,20 @@ Kafka 是一个分布式流式处理平台。这到底是什么意思呢?
|
|||
流平台具有三个关键功能:
|
||||
|
||||
1. **消息队列**:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
|
||||
2. **容错的持久方式存储记录消息流**: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
|
||||
2. **容错的持久方式存储记录消息流**:Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
|
||||
3. **流式处理平台:** 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
|
||||
|
||||
Kafka 主要有两大应用场景:
|
||||
|
||||
1. **消息队列** :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
|
||||
1. **消息队列**:建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
|
||||
2. **数据处理:** 构建实时的流数据处理程序来转换或处理数据流。
|
||||
|
||||
### 和其他消息队列相比,Kafka 的优势在哪里?
|
||||
|
||||
我们现在经常提到 Kafka 的时候就已经默认它是一个非常优秀的消息队列了,我们也会经常拿它跟 RocketMQ、RabbitMQ 对比。我觉得 Kafka 相比其他消息队列主要的优势如下:
|
||||
|
||||
1. **极致的性能** :基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
|
||||
2. **生态系统兼容性无可匹敌** :Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
|
||||
1. **极致的性能**:基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
|
||||
2. **生态系统兼容性无可匹敌**:Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
|
||||
|
||||
实际上在早期的时候 Kafka 并不是一个合格的消息队列,早期的 Kafka 在消息队列领域就像是一个衣衫褴褛的孩子一样,功能不完备并且有一些小问题比如丢失消息、不保证消息可靠性等等。当然,这也和 LinkedIn 最早开发 Kafka 用于处理海量的日志有很大关系,哈哈哈,人家本来最开始就不是为了作为消息队列滴,谁知道后面误打误撞在消息队列领域占据了一席之地。
|
||||
|
||||
|
|
@ -103,9 +103,9 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
|
|||
|
||||
从图中我们可以看出,Zookeeper 主要为 Kafka 做了下面这些事情:
|
||||
|
||||
1. **Broker 注册** :在 Zookeeper 上会有一个专门**用来进行 Broker 服务器列表记录**的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 `/brokers/ids` 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
|
||||
2. **Topic 注册** : 在 Kafka 中,同一个**Topic 的消息会被分成多个分区**并将其分布在多个 Broker 上,**这些分区信息及与 Broker 的对应关系**也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:`/brokers/topics/my-topic/Partitions/0`、`/brokers/topics/my-topic/Partitions/1`
|
||||
3. **负载均衡** :上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
|
||||
1. **Broker 注册**:在 Zookeeper 上会有一个专门**用来进行 Broker 服务器列表记录**的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 `/brokers/ids` 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
|
||||
2. **Topic 注册**:在 Kafka 中,同一个**Topic 的消息会被分成多个分区**并将其分布在多个 Broker 上,**这些分区信息及与 Broker 的对应关系**也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:`/brokers/topics/my-topic/Partitions/0`、`/brokers/topics/my-topic/Partitions/1`
|
||||
3. **负载均衡**:上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
|
||||
4. ......
|
||||
|
||||
### Kafka 如何保证消息的消费顺序?
|
||||
|
|
@ -220,5 +220,5 @@ acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后
|
|||
|
||||
### Reference
|
||||
|
||||
- Kafka 官方文档: https://kafka.apache.org/documentation/
|
||||
- Kafka 官方文档:https://kafka.apache.org/documentation/
|
||||
- 极客时间—《Kafka 核心技术与实战》第 11 节:无消息丢失配置怎么实现?
|
||||
|
|
|
|||
|
|
@ -31,11 +31,11 @@ tag:
|
|||
|
||||
> 中间件(英语:Middleware),又译中间件、中介层,是一类提供系统软件和应用软件之间连接、便于软件各部件之间的沟通的软件,应用软件可以借助中间件在不同的技术架构之间共享信息与资源。中间件位于客户机服务器的操作系统之上,管理着计算资源和网络通信。
|
||||
|
||||
简单来说: **中间件就是一类为应用软件服务的软件,应用软件是为用户服务的,用户不会接触或者使用到中间件。**
|
||||
简单来说:**中间件就是一类为应用软件服务的软件,应用软件是为用户服务的,用户不会接触或者使用到中间件。**
|
||||
|
||||
除了消息队列之外,常见的中间件还有 RPC 框架、分布式组件、HTTP 服务器、任务调度框架、配置中心、数据库层的分库分表工具和数据迁移工具等等。
|
||||
|
||||
关于中间件比较详细的介绍可以参考阿里巴巴淘系技术的一篇回答: https://www.zhihu.com/question/19730582/answer/1663627873 。
|
||||
关于中间件比较详细的介绍可以参考阿里巴巴淘系技术的一篇回答:https://www.zhihu.com/question/19730582/answer/1663627873 。
|
||||
|
||||
随着分布式和微服务系统的发展,消息队列在系统设计中有了更大的发挥空间,使用消息队列可以降低系统耦合性、实现任务异步、有效地进行流量削峰,是分布式和微服务系统中重要的组件之一。
|
||||
|
||||
|
|
@ -85,7 +85,7 @@ tag:
|
|||
|
||||
我们知道分布式事务的解决方案之一就是 MQ 事务。
|
||||
|
||||
RocketMQ 、 Kafka、Pulsar 、QMQ 都提供了事务相关的功能。事务允许事件流应用将消费,处理,生产消息整个过程定义为一个原子操作。
|
||||
RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允许事件流应用将消费,处理,生产消息整个过程定义为一个原子操作。
|
||||
|
||||
详细介绍可以查看 [分布式事务详解(付费)](https://javaguide.cn/distributed-system/distributed-transaction.html) 这篇文章。
|
||||
|
||||
|
|
@ -153,10 +153,10 @@ AMQP,即 Advanced Message Queuing Protocol,一个提供统一消息服务的
|
|||
|
||||
RPC 和消息队列都是分布式微服务系统中重要的组件之一,下面我们来简单对比一下两者:
|
||||
|
||||
- **从用途来看** :RPC 主要用来解决两个服务的远程通信问题,不需要了解底层网络的通信机制。通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。消息队列主要用来降低系统耦合性、实现任务异步、有效地进行流量削峰。
|
||||
- **从通信方式来看** :RPC 是双向直接网络通讯,消息队列是单向引入中间载体的网络通讯。
|
||||
- **从架构上来看** :消息队列需要把消息存储起来,RPC 则没有这个要求,因为前面也说了 RPC 是双向直接网络通讯。
|
||||
- **从请求处理的时效性来看** :通过 RPC 发出的调用一般会立即被处理,存放在消息队列中的消息并不一定会立即被处理。
|
||||
- **从用途来看**:RPC 主要用来解决两个服务的远程通信问题,不需要了解底层网络的通信机制。通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。消息队列主要用来降低系统耦合性、实现任务异步、有效地进行流量削峰。
|
||||
- **从通信方式来看**:RPC 是双向直接网络通讯,消息队列是单向引入中间载体的网络通讯。
|
||||
- **从架构上来看**:消息队列需要把消息存储起来,RPC 则没有这个要求,因为前面也说了 RPC 是双向直接网络通讯。
|
||||
- **从请求处理的时效性来看**:通过 RPC 发出的调用一般会立即被处理,存放在消息队列中的消息并不一定会立即被处理。
|
||||
|
||||
RPC 和消息队列本质上是网络通讯的两种不同的实现机制,两者的用途不同,万不可将两者混为一谈。
|
||||
|
||||
|
|
@ -173,7 +173,7 @@ Kafka 是 LinkedIn 开源的一个分布式流式处理平台,已经成为 Apa
|
|||
流式处理平台具有三个关键功能:
|
||||
|
||||
1. **消息队列**:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
|
||||
2. **容错的持久方式存储记录消息流**: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
|
||||
2. **容错的持久方式存储记录消息流**:Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
|
||||
3. **流式处理平台:** 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
|
||||
|
||||
Kafka 是一个分布式系统,由通过高性能 TCP 网络协议进行通信的服务器和客户端组成,可以部署在在本地和云环境中的裸机硬件、虚拟机和容器上。
|
||||
|
|
@ -276,7 +276,7 @@ Pulsar 更新记录(可以直观看到项目是否还在维护):https://gi
|
|||
**总结:**
|
||||
|
||||
- ActiveMQ 的社区算是比较成熟,但是较目前来说,ActiveMQ 的性能比较差,而且版本迭代很慢,不推荐使用,已经被淘汰了。
|
||||
- RabbitMQ 在吞吐量方面虽然稍逊于 Kafka 、RocketMQ 和 Pulsar,但是由于它基于 Erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。但是也因为 RabbitMQ 基于 Erlang 开发,所以国内很少有公司有实力做 Erlang 源码级别的研究和定制。如果业务场景对并发量要求不是太高(十万级、百万级),那这几种消息队列中,RabbitMQ 或许是你的首选。
|
||||
- RabbitMQ 在吞吐量方面虽然稍逊于 Kafka、RocketMQ 和 Pulsar,但是由于它基于 Erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。但是也因为 RabbitMQ 基于 Erlang 开发,所以国内很少有公司有实力做 Erlang 源码级别的研究和定制。如果业务场景对并发量要求不是太高(十万级、百万级),那这几种消息队列中,RabbitMQ 或许是你的首选。
|
||||
- RocketMQ 和 Pulsar 支持强一致性,对消息一致性要求比较高的场景可以使用。
|
||||
- RocketMQ 阿里出品,Java 系开源项目,源代码我们可以直接阅读,然后可以定制自己公司的 MQ,并且 RocketMQ 有阿里巴巴的实际业务场景的实战考验。
|
||||
- Kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 Kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。Kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
|
||||
|
|
|
|||
|
|
@ -138,17 +138,17 @@ RabbitMQ 就是 AMQP 协议的 `Erlang` 的实现(当然 RabbitMQ 还支持 `STO
|
|||
|
||||
RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。目前 RabbitMQ 最新版本默认支持的是 AMQP 0-9-1。
|
||||
|
||||
**AMQP 协议的三层** :
|
||||
**AMQP 协议的三层**:
|
||||
|
||||
- **Module Layer**:协议最高层,主要定义了一些客户端调用的命令,客户端可以用这些命令实现自己的业务逻辑。
|
||||
- **Session Layer**:中间层,主要负责客户端命令发送给服务器,再将服务端应答返回客户端,提供可靠性同步机制和错误处理。
|
||||
- **TransportLayer**:最底层,主要传输二进制数据流,提供帧的处理、信道服用、错误检测和数据表示等。
|
||||
|
||||
**AMQP 模型的三大组件** :
|
||||
**AMQP 模型的三大组件**:
|
||||
|
||||
- **交换器 (Exchange)** :消息代理服务器中用于把消息路由到队列的组件。
|
||||
- **队列 (Queue)** :用来存储消息的数据结构,位于硬盘或内存中。
|
||||
- **绑定 (Binding)** :一套规则,告知交换器消息应该将消息投递给哪个队列。
|
||||
- **交换器 (Exchange)**:消息代理服务器中用于把消息路由到队列的组件。
|
||||
- **队列 (Queue)**:用来存储消息的数据结构,位于硬盘或内存中。
|
||||
- **绑定 (Binding)**:一套规则,告知交换器消息应该将消息投递给哪个队列。
|
||||
|
||||
## **说说生产者 Producer 和消费者 Consumer?**
|
||||
|
||||
|
|
@ -157,14 +157,14 @@ RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都
|
|||
- 消息生产者,就是投递消息的一方。
|
||||
- 消息一般包含两个部分:消息体(`payload`)和标签(`Label`)。
|
||||
|
||||
**消费者** :
|
||||
**消费者**:
|
||||
|
||||
- 消费消息,也就是接收消息的一方。
|
||||
- 消费者连接到 RabbitMQ 服务器,并订阅到队列上。消费消息时只消费消息体,丢弃标签。
|
||||
|
||||
## 说说 Broker 服务节点、Queue 队列、Exchange 交换器?
|
||||
|
||||
- **Broker** : 可以看做 RabbitMQ 的服务节点。一般请下一个 Broker 可以看做一个 RabbitMQ 服务器。
|
||||
- **Broker**:可以看做 RabbitMQ 的服务节点。一般请下一个 Broker 可以看做一个 RabbitMQ 服务器。
|
||||
- **Queue** :RabbitMQ 的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
|
||||
- **Exchange** : 生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
|
||||
|
||||
|
|
|
|||
|
|
@ -154,7 +154,7 @@ tag:
|
|||
|
||||
的确,早期的消息中间件是通过 **队列** 这一模型来实现的,可能是历史原因,我们都习惯把消息中间件成为消息队列。
|
||||
|
||||
但是,如今例如 `RocketMQ` 、`Kafka` 这些优秀的消息中间件不仅仅是通过一个 **队列** 来实现消息存储的。
|
||||
但是,如今例如 `RocketMQ`、`Kafka` 这些优秀的消息中间件不仅仅是通过一个 **队列** 来实现消息存储的。
|
||||
|
||||
### 队列模型
|
||||
|
||||
|
|
@ -188,11 +188,11 @@ tag:
|
|||
|
||||
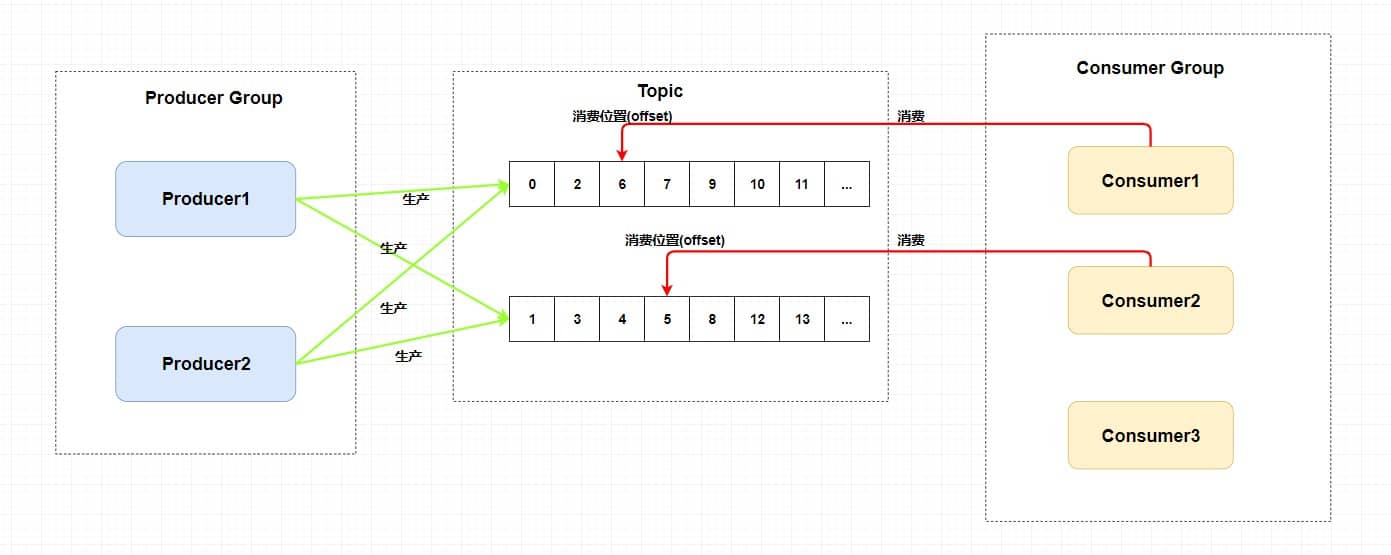
|
||||
|
||||
我们可以看到在整个图中有 `Producer Group` 、`Topic` 、`Consumer Group` 三个角色,我来分别介绍一下他们。
|
||||
我们可以看到在整个图中有 `Producer Group`、`Topic`、`Consumer Group` 三个角色,我来分别介绍一下他们。
|
||||
|
||||
- `Producer Group` 生产者组: 代表某一类的生产者,比如我们有多个秒杀系统作为生产者,这多个合在一起就是一个 `Producer Group` 生产者组,它们一般生产相同的消息。
|
||||
- `Consumer Group` 消费者组: 代表某一类的消费者,比如我们有多个短信系统作为消费者,这多个合在一起就是一个 `Consumer Group` 消费者组,它们一般消费相同的消息。
|
||||
- `Topic` 主题: 代表一类消息,比如订单消息,物流消息等等。
|
||||
- `Producer Group` 生产者组:代表某一类的生产者,比如我们有多个秒杀系统作为生产者,这多个合在一起就是一个 `Producer Group` 生产者组,它们一般生产相同的消息。
|
||||
- `Consumer Group` 消费者组:代表某一类的消费者,比如我们有多个短信系统作为消费者,这多个合在一起就是一个 `Consumer Group` 消费者组,它们一般消费相同的消息。
|
||||
- `Topic` 主题:代表一类消息,比如订单消息,物流消息等等。
|
||||
|
||||
你可以看到图中生产者组中的生产者会向主题发送消息,而 **主题中存在多个队列**,生产者每次生产消息之后是指定主题中的某个队列发送消息的。
|
||||
|
||||
|
|
@ -222,11 +222,11 @@ tag:
|
|||
|
||||
讲完了消息模型,我们理解起 `RocketMQ` 的技术架构起来就容易多了。
|
||||
|
||||
`RocketMQ` 技术架构中有四大角色 `NameServer` 、`Broker` 、`Producer` 、`Consumer` 。我来向大家分别解释一下这四个角色是干啥的。
|
||||
`RocketMQ` 技术架构中有四大角色 `NameServer`、`Broker`、`Producer`、`Consumer` 。我来向大家分别解释一下这四个角色是干啥的。
|
||||
|
||||
- `Broker`: 主要负责消息的存储、投递和查询以及服务高可用保证。说白了就是消息队列服务器嘛,生产者生产消息到 `Broker` ,消费者从 `Broker` 拉取消息并消费。
|
||||
- `Broker`:主要负责消息的存储、投递和查询以及服务高可用保证。说白了就是消息队列服务器嘛,生产者生产消息到 `Broker` ,消费者从 `Broker` 拉取消息并消费。
|
||||
|
||||
这里,我还得普及一下关于 `Broker` 、`Topic` 和 队列的关系。上面我讲解了 `Topic` 和队列的关系——一个 `Topic` 中存在多个队列,那么这个 `Topic` 和队列存放在哪呢?
|
||||
这里,我还得普及一下关于 `Broker`、`Topic` 和 队列的关系。上面我讲解了 `Topic` 和队列的关系——一个 `Topic` 中存在多个队列,那么这个 `Topic` 和队列存放在哪呢?
|
||||
|
||||
**一个 `Topic` 分布在多个 `Broker`上,一个 `Broker` 可以配置多个 `Topic` ,它们是多对多的关系**。
|
||||
|
||||
|
|
@ -238,17 +238,17 @@ tag:
|
|||
|
||||
> 所以说我们需要配置多个 Broker。
|
||||
|
||||
- `NameServer`: 不知道你们有没有接触过 `ZooKeeper` 和 `Spring Cloud` 中的 `Eureka` ,它其实也是一个 **注册中心** ,主要提供两个功能:**Broker 管理** 和 **路由信息管理** 。说白了就是 `Broker` 会将自己的信息注册到 `NameServer` 中,此时 `NameServer` 就存放了很多 `Broker` 的信息(Broker 的路由表),消费者和生产者就从 `NameServer` 中获取路由表然后照着路由表的信息和对应的 `Broker` 进行通信(生产者和消费者定期会向 `NameServer` 去查询相关的 `Broker` 的信息)。
|
||||
- `NameServer`:不知道你们有没有接触过 `ZooKeeper` 和 `Spring Cloud` 中的 `Eureka` ,它其实也是一个 **注册中心** ,主要提供两个功能:**Broker 管理** 和 **路由信息管理** 。说白了就是 `Broker` 会将自己的信息注册到 `NameServer` 中,此时 `NameServer` 就存放了很多 `Broker` 的信息(Broker 的路由表),消费者和生产者就从 `NameServer` 中获取路由表然后照着路由表的信息和对应的 `Broker` 进行通信(生产者和消费者定期会向 `NameServer` 去查询相关的 `Broker` 的信息)。
|
||||
|
||||
- `Producer`: 消息发布的角色,支持分布式集群方式部署。说白了就是生产者。
|
||||
- `Producer`:消息发布的角色,支持分布式集群方式部署。说白了就是生产者。
|
||||
|
||||
- `Consumer`: 消息消费的角色,支持分布式集群方式部署。支持以 push 推,pull 拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制。说白了就是消费者。
|
||||
- `Consumer`:消息消费的角色,支持分布式集群方式部署。支持以 push 推,pull 拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制。说白了就是消费者。
|
||||
|
||||
听完了上面的解释你可能会觉得,这玩意好简单。不就是这样的么?
|
||||
|
||||
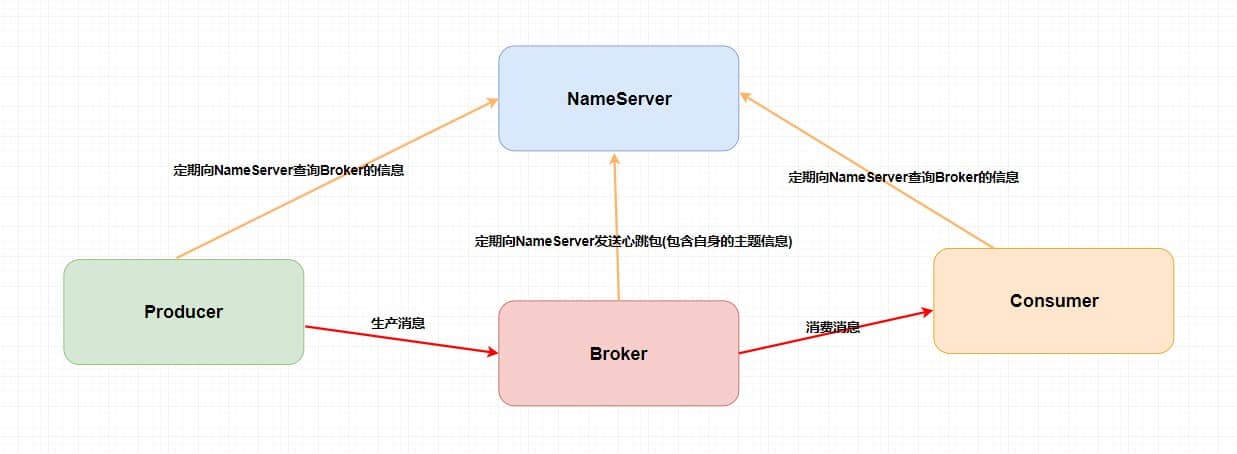
|
||||
|
||||
嗯?你可能会发现一个问题,这老家伙 `NameServer` 干啥用的,这不多余吗?直接 `Producer` 、`Consumer` 和 `Broker` 直接进行生产消息,消费消息不就好了么?
|
||||
嗯?你可能会发现一个问题,这老家伙 `NameServer` 干啥用的,这不多余吗?直接 `Producer`、`Consumer` 和 `Broker` 直接进行生产消息,消费消息不就好了么?
|
||||
|
||||
但是,我们上文提到过 `Broker` 是需要保证高可用的,如果整个系统仅仅靠着一个 `Broker` 来维持的话,那么这个 `Broker` 的压力会不会很大?所以我们需要使用多个 `Broker` 来保证 **负载均衡** 。
|
||||
|
||||
|
|
@ -276,7 +276,7 @@ tag:
|
|||
|
||||
在上面我介绍 `RocketMQ` 的技术架构的时候我已经向你展示了 **它是如何保证高可用的** ,这里不涉及运维方面的搭建,如果你感兴趣可以自己去官网上照着例子搭建属于你自己的 `RocketMQ` 集群。
|
||||
|
||||
> 其实 `Kafka` 的架构基本和 `RocketMQ` 类似,只是它注册中心使用了 `Zookeeper` 、它的 **分区** 就相当于 `RocketMQ` 中的 **队列** 。还有一些小细节不同会在后面提到。
|
||||
> 其实 `Kafka` 的架构基本和 `RocketMQ` 类似,只是它注册中心使用了 `Zookeeper`、它的 **分区** 就相当于 `RocketMQ` 中的 **队列** 。还有一些小细节不同会在后面提到。
|
||||
|
||||
### 顺序消费
|
||||
|
||||
|
|
@ -380,8 +380,8 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
|||
|
||||
上面的同步刷盘和异步刷盘是在单个结点层面的,而同步复制和异步复制主要是指的 `Borker` 主从模式下,主节点返回消息给客户端的时候是否需要同步从节点。
|
||||
|
||||
- 同步复制: 也叫 “同步双写”,也就是说,**只有消息同步双写到主从节点上时才返回写入成功** 。
|
||||
- 异步复制: **消息写入主节点之后就直接返回写入成功** 。
|
||||
- 同步复制:也叫 “同步双写”,也就是说,**只有消息同步双写到主从节点上时才返回写入成功** 。
|
||||
- 异步复制:**消息写入主节点之后就直接返回写入成功** 。
|
||||
|
||||
然而,很多事情是没有完美的方案的,就比如我们进行消息写入的节点越多就更能保证消息的可靠性,但是随之的性能也会下降,所以需要程序员根据特定业务场景去选择适应的主从复制方案。
|
||||
|
||||
|
|
@ -405,11 +405,11 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
|||
|
||||
还记得上面我们一开始的三个问题吗?到这里第三个问题已经解决了。
|
||||
|
||||
但是,在 `Topic` 中的 **队列是以什么样的形式存在的?队列中的消息又是如何进行存储持久化的呢?** 还未解决,其实这里涉及到了 `RocketMQ` 是如何设计它的存储结构了。我首先想大家介绍 `RocketMQ` 消息存储架构中的三大角色——`CommitLog` 、`ConsumeQueue` 和 `IndexFile` 。
|
||||
但是,在 `Topic` 中的 **队列是以什么样的形式存在的?队列中的消息又是如何进行存储持久化的呢?** 还未解决,其实这里涉及到了 `RocketMQ` 是如何设计它的存储结构了。我首先想大家介绍 `RocketMQ` 消息存储架构中的三大角色——`CommitLog`、`ConsumeQueue` 和 `IndexFile` 。
|
||||
|
||||
- `CommitLog`: **消息主体以及元数据的存储主体**,存储 `Producer` 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认 1G ,文件名长度为 20 位,左边补零,剩余为起始偏移量,比如 00000000000000000000 代表了第一个文件,起始偏移量为 0,文件大小为 1G=1073741824;当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。消息主要是**顺序写入日志文件**,当文件满了,写入下一个文件。
|
||||
- `ConsumeQueue`: 消息消费队列,**引入的目的主要是提高消息消费的性能**(我们再前面也讲了),由于`RocketMQ` 是基于主题 `Topic` 的订阅模式,消息消费是针对主题进行的,如果要遍历 `commitlog` 文件中根据 `Topic` 检索消息是非常低效的。`Consumer` 即可根据 `ConsumeQueue` 来查找待消费的消息。其中,`ConsumeQueue`(逻辑消费队列)**作为消费消息的索引**,保存了指定 `Topic` 下的队列消息在 `CommitLog` 中的**起始物理偏移量 `offset` **,消息大小 `size` 和消息 `Tag` 的 `HashCode` 值。**`consumequeue` 文件可以看成是基于 `topic` 的 `commitlog` 索引文件**,故 `consumequeue` 文件夹的组织方式如下:topic/queue/file 三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样 `consumequeue` 文件采取定长设计,每一个条目共 20 个字节,分别为 8 字节的 `commitlog` 物理偏移量、4 字节的消息长度、8 字节 tag `hashcode`,单个文件由 30W 个条目组成,可以像数组一样随机访问每一个条目,每个 `ConsumeQueue`文件大小约 5.72M;
|
||||
- `IndexFile`: `IndexFile`(索引文件)提供了一种可以通过 key 或时间区间来查询消息的方法。这里只做科普不做详细介绍。
|
||||
- `CommitLog`:**消息主体以及元数据的存储主体**,存储 `Producer` 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认 1G ,文件名长度为 20 位,左边补零,剩余为起始偏移量,比如 00000000000000000000 代表了第一个文件,起始偏移量为 0,文件大小为 1G=1073741824;当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。消息主要是**顺序写入日志文件**,当文件满了,写入下一个文件。
|
||||
- `ConsumeQueue`:消息消费队列,**引入的目的主要是提高消息消费的性能**(我们再前面也讲了),由于`RocketMQ` 是基于主题 `Topic` 的订阅模式,消息消费是针对主题进行的,如果要遍历 `commitlog` 文件中根据 `Topic` 检索消息是非常低效的。`Consumer` 即可根据 `ConsumeQueue` 来查找待消费的消息。其中,`ConsumeQueue`(逻辑消费队列)**作为消费消息的索引**,保存了指定 `Topic` 下的队列消息在 `CommitLog` 中的**起始物理偏移量 `offset` **,消息大小 `size` 和消息 `Tag` 的 `HashCode` 值。**`consumequeue` 文件可以看成是基于 `topic` 的 `commitlog` 索引文件**,故 `consumequeue` 文件夹的组织方式如下:topic/queue/file 三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样 `consumequeue` 文件采取定长设计,每一个条目共 20 个字节,分别为 8 字节的 `commitlog` 物理偏移量、4 字节的消息长度、8 字节 tag `hashcode`,单个文件由 30W 个条目组成,可以像数组一样随机访问每一个条目,每个 `ConsumeQueue`文件大小约 5.72M;
|
||||
- `IndexFile`:`IndexFile`(索引文件)提供了一种可以通过 key 或时间区间来查询消息的方法。这里只做科普不做详细介绍。
|
||||
|
||||
总结来说,整个消息存储的结构,最主要的就是 `CommitLoq` 和 `ConsumeQueue` 。而 `ConsumeQueue` 你可以大概理解为 `Topic` 中的队列。
|
||||
|
||||
|
|
@ -431,7 +431,7 @@ emmm,是不是有一点复杂 🤣,看英文图片和英文文档的时候
|
|||
|
||||
首先,在最上面的那一块就是我刚刚讲的你现在可以直接 **把 `ConsumerQueue` 理解为 `Queue`**。
|
||||
|
||||
在图中最左边说明了红色方块代表被写入的消息,虚线方块代表等待被写入的。左边的生产者发送消息会指定 `Topic` 、`QueueId` 和具体消息内容,而在 `Broker` 中管你是哪门子消息,他直接 **全部顺序存储到了 CommitLog**。而根据生产者指定的 `Topic` 和 `QueueId` 将这条消息本身在 `CommitLog` 的偏移(offset),消息本身大小,和 tag 的 hash 值存入对应的 `ConsumeQueue` 索引文件中。而在每个队列中都保存了 `ConsumeOffset` 即每个消费者组的消费位置(我在架构那里提到了,忘了的同学可以回去看一下),而消费者拉取消息进行消费的时候只需要根据 `ConsumeOffset` 获取下一个未被消费的消息就行了。
|
||||
在图中最左边说明了红色方块代表被写入的消息,虚线方块代表等待被写入的。左边的生产者发送消息会指定 `Topic`、`QueueId` 和具体消息内容,而在 `Broker` 中管你是哪门子消息,他直接 **全部顺序存储到了 CommitLog**。而根据生产者指定的 `Topic` 和 `QueueId` 将这条消息本身在 `CommitLog` 的偏移(offset),消息本身大小,和 tag 的 hash 值存入对应的 `ConsumeQueue` 索引文件中。而在每个队列中都保存了 `ConsumeOffset` 即每个消费者组的消费位置(我在架构那里提到了,忘了的同学可以回去看一下),而消费者拉取消息进行消费的时候只需要根据 `ConsumeOffset` 获取下一个未被消费的消息就行了。
|
||||
|
||||
上述就是我对于整个消息存储架构的大概理解(这里不涉及到一些细节讨论,比如稀疏索引等等问题),希望对你有帮助。
|
||||
|
||||
|
|
@ -451,7 +451,7 @@ emmm,是不是有一点复杂 🤣,看英文图片和英文文档的时候
|
|||
2. 消息队列的作用(异步,解耦,削峰)
|
||||
3. 消息队列带来的一系列问题(消息堆积、重复消费、顺序消费、分布式事务等等)
|
||||
4. 消息队列的两种消息模型——队列和主题模式
|
||||
5. 分析了 `RocketMQ` 的技术架构(`NameServer` 、`Broker` 、`Producer` 、`Comsumer`)
|
||||
5. 分析了 `RocketMQ` 的技术架构(`NameServer`、`Broker`、`Producer`、`Comsumer`)
|
||||
6. 结合 `RocketMQ` 回答了消息队列副作用的解决方案
|
||||
7. 介绍了 `RocketMQ` 的存储机制和刷盘策略。
|
||||
|
||||
|
|
|
|||
|
|
@ -157,10 +157,10 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
|
|||
|
||||
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
|
||||
|
||||
- **哈希分片** :求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
|
||||
- **范围分片** :按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
|
||||
- **地理位置分片** :很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
|
||||
- **融合算法** :灵活组合多种分片算法,比如将哈希分片和范围分片组合。
|
||||
- **哈希分片**:求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
|
||||
- **范围分片**:按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
|
||||
- **地理位置分片**:很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
|
||||
- **融合算法**:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
|
||||
- ......
|
||||
|
||||
### 分库分表会带来什么问题呢?
|
||||
|
|
@ -169,9 +169,9 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
|
|||
|
||||
引入分库分表之后,会给系统带来什么挑战呢?
|
||||
|
||||
- **join 操作** : 同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。
|
||||
- **事务问题** :同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。
|
||||
- **分布式 id** :分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 id 了。
|
||||
- **join 操作**:同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。
|
||||
- **事务问题**:同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。
|
||||
- **分布式 id**:分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 id 了。
|
||||
- ......
|
||||
|
||||
另外,引入分库分表之后,一般需要 DBA 的参与,同时还需要更多的数据库服务器,这些都属于成本。
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ tag:
|
|||
- 练级攻略
|
||||
---
|
||||
|
||||
> **推荐语** : Kaito 大佬的一篇文章,很实用的建议!
|
||||
> **推荐语**:Kaito 大佬的一篇文章,很实用的建议!
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
|
|
|
|||
|
|
@ -6,9 +6,9 @@ tag:
|
|||
- 练级攻略
|
||||
---
|
||||
|
||||
> **推荐语** :普通程序员要想成长为高级程序员甚至是专家等更高级别,应该注意在哪些方面注意加强?开发内功修炼号主飞哥在这篇文章中就给出了七条实用的建议。
|
||||
> **推荐语**:普通程序员要想成长为高级程序员甚至是专家等更高级别,应该注意在哪些方面注意加强?开发内功修炼号主飞哥在这篇文章中就给出了七条实用的建议。
|
||||
>
|
||||
> **内容概览** :
|
||||
> **内容概览**:
|
||||
>
|
||||
> 1. 刻意加强需求评审能力
|
||||
> 2. 主动思考效率
|
||||
|
|
@ -18,7 +18,7 @@ tag:
|
|||
> 6. 关注全局
|
||||
> 7. 归纳总结能力
|
||||
>
|
||||
> **原文地址** :https://mp.weixin.qq.com/s/8lMGzBzXine-NAsqEaIE4g
|
||||
> **原文地址**:https://mp.weixin.qq.com/s/8lMGzBzXine-NAsqEaIE4g
|
||||
|
||||
### 建议 1:刻意加强需求评审能力
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ tag:
|
|||
- 练级攻略
|
||||
---
|
||||
|
||||
> **推荐语** : 波波老师的一篇文章,写的非常好,不光是对技术成长有帮助,其他领域也是同样适用的!建议反复阅读,形成一套自己的技术成长策略。
|
||||
> **推荐语**:波波老师的一篇文章,写的非常好,不光是对技术成长有帮助,其他领域也是同样适用的!建议反复阅读,形成一套自己的技术成长策略。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
|
|
@ -18,7 +18,7 @@ tag:
|
|||
|
||||
**技术人为啥焦虑?** 恕我直言,说白了是胆识不足格局太小。胆就是胆量,焦虑的人一般对未来的不确定性怀有恐惧。识就是见识,焦虑的人一般看不清楚周围世界,也看不清自己和适合自己的道路。格局也称志向,容易焦虑的人通常视野窄志向小。如果从战略和管理的视角来看,就是对自己和周围世界的认知不足,没有一个清晰和长期的学习成长战略,也没有可执行的阶段性目标计划+严格的执行。
|
||||
|
||||
因为问此类问题的学员很多,让我感觉有点烦了,为了避免重复回答,所以我专门总结梳理了这篇长文,试图统一来回答这类问题。如果后面还有学员问类似问题,我会引导他们来读这篇文章,然后让他们用三个月、一年甚至更长的时间,去思考和回答这样一个问题: **你的技术成长战略究竟是什么?** 如果你想清楚了这个问题,有清晰和可落地的答案,那么恭喜你,你只需按部就班执行就好,根本无需焦虑,你实现自己的战略目标并做出成就只是一个时间问题;否则,你仍然需要通过不断磨炼+思考,务必去搞清楚这个人生的大问题!!!
|
||||
因为问此类问题的学员很多,让我感觉有点烦了,为了避免重复回答,所以我专门总结梳理了这篇长文,试图统一来回答这类问题。如果后面还有学员问类似问题,我会引导他们来读这篇文章,然后让他们用三个月、一年甚至更长的时间,去思考和回答这样一个问题:**你的技术成长战略究竟是什么?** 如果你想清楚了这个问题,有清晰和可落地的答案,那么恭喜你,你只需按部就班执行就好,根本无需焦虑,你实现自己的战略目标并做出成就只是一个时间问题;否则,你仍然需要通过不断磨炼+思考,务必去搞清楚这个人生的大问题!!!
|
||||
|
||||
下面我们来看一些行业技术大牛是怎么做的。
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ tag:
|
|||
- 面试
|
||||
---
|
||||
|
||||
> **推荐语** :从面试官和面试者两个角度探讨了技术面试!非常不错!
|
||||
> **推荐语**:从面试官和面试者两个角度探讨了技术面试!非常不错!
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
|
|
@ -18,7 +18,7 @@ tag:
|
|||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址** :https://www.cnblogs.com/lovesqcc/p/15169365.html
|
||||
> **原文地址**:https://www.cnblogs.com/lovesqcc/p/15169365.html
|
||||
|
||||
## 灵魂三连问
|
||||
|
||||
|
|
@ -35,12 +35,12 @@ tag:
|
|||
|
||||
技术基础是基石(冰山之下的东西),占七分, 解决问题的思路和能力是落地(冰山之上露出的部分),占三分。 业务和技术基础考察,三七开。
|
||||
|
||||
核心考察目标: 分析和解决问题的能力。
|
||||
核心考察目标:分析和解决问题的能力。
|
||||
|
||||
技术层面:深度 + 应用能力 + 广度。 对于校招或社招 P6 级别以下,要多注重 深度 + 应用能力,广度是加分项; 在 P6 之上,可增加 广度。
|
||||
|
||||
- 校招: 基础扎实,思维敏捷。 主要考察内容:基础数据结构与算法、进程与并发、内存管理、系统调用与 IO 机制、网络协议、数据库范式与设计、设计模式、设计原则、编程习惯;
|
||||
- 社招: 经验丰富,里外兼修。 主要考察内容:有一定深度的基础技术机制,比如 Java 内存模型及内存泄露、 JVM 机制、类加载机制、数据库索引及查询优化、缓存、消息中间件、项目、架构设计、工程规范等。
|
||||
- 校招:基础扎实,思维敏捷。 主要考察内容:基础数据结构与算法、进程与并发、内存管理、系统调用与 IO 机制、网络协议、数据库范式与设计、设计模式、设计原则、编程习惯;
|
||||
- 社招:经验丰富,里外兼修。 主要考察内容:有一定深度的基础技术机制,比如 Java 内存模型及内存泄露、 JVM 机制、类加载机制、数据库索引及查询优化、缓存、消息中间件、项目、架构设计、工程规范等。
|
||||
|
||||
### 技术基础是什么?
|
||||
|
||||
|
|
@ -78,7 +78,7 @@ tag:
|
|||
|
||||
**引导-横向发问-深入发问**
|
||||
|
||||
引导性,比如 “你对 java 同步工具熟悉吗?” 作个试探,得到肯定答复后,可以进一步问: “你熟悉哪些同步工具类?” 了解候选者的广度;
|
||||
引导性,比如 “你对 java 同步工具熟悉吗?” 作个试探,得到肯定答复后,可以进一步问:“你熟悉哪些同步工具类?” 了解候选者的广度;
|
||||
|
||||
获取候选者的回答后,可以进一步问:“ 谈谈 ConcurrentHashMap 或 AQS 的实现原理?”
|
||||
|
||||
|
|
@ -313,7 +313,7 @@ tag:
|
|||
|
||||
如果候选人答不上,可以问:如果你来设计这样一个 XXX, 你会怎么做?
|
||||
|
||||
时间占比大概为 : 技术基础(25-30 分钟) + 项目(20-25 分钟) + 候选人提问(5-10 分钟)
|
||||
时间占比大概为:技术基础(25-30 分钟) + 项目(20-25 分钟) + 候选人提问(5-10 分钟)
|
||||
|
||||
## 给候选人的话
|
||||
|
||||
|
|
|
|||
|
|
@ -6,11 +6,11 @@ tag:
|
|||
- 面试
|
||||
---
|
||||
|
||||
> **推荐语** :这篇文章的作者校招最终去了飞书做开发。在这篇文章中,他分享了自己的校招经历以及个人经验。
|
||||
> **推荐语**:这篇文章的作者校招最终去了飞书做开发。在这篇文章中,他分享了自己的校招经历以及个人经验。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址** : https://www.ihewro.com/archives/1217/
|
||||
> **原文地址**:https://www.ihewro.com/archives/1217/
|
||||
|
||||
## 基本情况
|
||||
|
||||
|
|
|
|||
|
|
@ -6,11 +6,11 @@ tag:
|
|||
- 面试
|
||||
---
|
||||
|
||||
> **推荐语** :经常听到培训班待过的朋友给我说他们的老师是怎么教他们“包装”自己的,不光是培训班,我认识的很多朋友也都会在面试之前“包装”一下自己,所以这个现象是普遍存在的。但是面试官也不都是傻子,通过下面这篇文章来看看面试官是如何甄别应聘者的包装程度。
|
||||
> **推荐语**:经常听到培训班待过的朋友给我说他们的老师是怎么教他们“包装”自己的,不光是培训班,我认识的很多朋友也都会在面试之前“包装”一下自己,所以这个现象是普遍存在的。但是面试官也不都是傻子,通过下面这篇文章来看看面试官是如何甄别应聘者的包装程度。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
> **原文地址** : https://my.oschina.net/hooker/blog/3014656
|
||||
> **原文地址**:https://my.oschina.net/hooker/blog/3014656
|
||||
|
||||
## 前言
|
||||
|
||||
|
|
@ -113,6 +113,6 @@ tag:
|
|||
|
||||
大体上的套路便是如此:你说你杀过猪。那么你杀过几头猪,分别是啥时候,杀过多大的猪,有啥毛色。事实上对方可能给你的回答是:杀过、十几头、杀过五十斤的、杀过绿色、黄色、红色、蓝色的猪。那么问题就来了。
|
||||
|
||||
然而笔者碰到的问题是:使用 Git 两年却不知道 Github、使用 Redis 一年却不知道数据结构也不知道序列化、专业做爬虫却不懂 `content-type` 含义、使用搜索引擎技术却说不出两个分词插件、使用数据库读写分离却不知道同步延时等等。
|
||||
然而笔者碰到的问题是:使用 Git 两年却不知道 GitHub、使用 Redis 一年却不知道数据结构也不知道序列化、专业做爬虫却不懂 `content-type` 含义、使用搜索引擎技术却说不出两个分词插件、使用数据库读写分离却不知道同步延时等等。
|
||||
|
||||
写在最后,笔者认为在招聘途中,并不是不允许求职者包装,但是尽可能满足能筹平衡。虽然这篇文章没有完美的结尾,但是笔者提供了面试失败的各种经验。笔者最终招到了如意的小伙伴。也希望所有技术面试官早日找到符合自己产品发展的 IT 伙伴。
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ tag:
|
|||
- 面试
|
||||
---
|
||||
|
||||
> **推荐语** : 详细介绍了求职者在面试中应该具备哪些能力才会有更大概率脱颖而出。
|
||||
> **推荐语**:详细介绍了求职者在面试中应该具备哪些能力才会有更大概率脱颖而出。
|
||||
>
|
||||
> <br/>
|
||||
>
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue