[docs add&update]新增内容访问网页的全过程(知识串联)&部分内容描述完善
This commit is contained in:
parent
ef7c74c2ce
commit
37a51a0e6f
|
|
@ -191,6 +191,7 @@ export default sidebar({
|
|||
collapsible: true,
|
||||
children: [
|
||||
"osi-and-tcp-ip-model",
|
||||
"the-whole-process-of-accessing-web-pages",
|
||||
"application-layer-protocol",
|
||||
"http-vs-https",
|
||||
"http1.0-vs-http1.1",
|
||||
|
|
|
|||
|
|
@ -14,14 +14,20 @@ Elasticsearch 在 Apache Lucene 的基础上开发而成,学习 ES 之前,
|
|||
|
||||
## Elasticsearch
|
||||
|
||||
极客时间的[《Elasticsearch 核心技术与实战》](http://gk.link/a/10bcT "《Elasticsearch 核心技术与实战》")这门课程基于 Elasticsearch 7.1 版本讲解,还算比较新。并且,作者是 eBay 资深技术专家,有 20 年的行业经验,课程质量有保障!
|
||||
**[《一本书讲透 Elasticsearch:原理、进阶与工程实践》](https://book.douban.com/subject/36716996/)**
|
||||
|
||||

|
||||
|
||||
基于 8.x 版本编写,目前全网最新的 Elasticsearch 讲解书籍。内容覆盖 Elastic 官方认证的核心知识点,源自真实项目案例和企业级问题解答。
|
||||
|
||||
**[《Elasticsearch 核心技术与实战》](http://gk.link/a/10bcT "《Elasticsearch 核心技术与实战》")**
|
||||
|
||||
极客时间的这门课程基于 Elasticsearch 7.1 版本讲解,还算比较新。并且,作者是 eBay 资深技术专家,有 20 年的行业经验,课程质量有保障!
|
||||
|
||||

|
||||
|
||||
如果你想看书的话,可以考虑一下 **[《Elasticsearch 实战》](https://book.douban.com/subject/30380439/)** 这本书。不过,需要说明的是,这本书中的 Elasticsearch 版本比较老,你可以将其作为一个参考书籍来看,有一些原理性的东西可以在上面找找答案。
|
||||
|
||||

|
||||
|
||||
如果你想进一步深入研究 Elasticsearch 原理的话,可以看看张超老师的 **[《Elasticsearch 源码解析与优化实战》](https://book.douban.com/subject/30386800/)** 这本书。这是市面上唯一一本写 Elasticsearch 源码的书。
|
||||
**[《Elasticsearch 源码解析与优化实战》](https://book.douban.com/subject/30386800/)**
|
||||
|
||||
|
||||
|
||||
如果你想进一步深入研究 Elasticsearch 原理的话,可以看看张超老师的这本书。这是市面上唯一一本写 Elasticsearch 源码的书。
|
||||
|
|
|
|||
|
|
@ -104,25 +104,17 @@ tag:
|
|||
|
||||
> 类似的问题:打开一个网页,整个过程会使用哪些协议?
|
||||
|
||||
图解(图片来源:《图解 HTTP》):
|
||||
总体来说分为以下几个步骤:
|
||||
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/url%E8%BE%93%E5%85%A5%E5%88%B0%E5%B1%95%E7%A4%BA%E5%87%BA%E6%9D%A5%E7%9A%84%E8%BF%87%E7%A8%8B.jpg" style="zoom:50%" />
|
||||
1. 在浏览器中输入指定网页的 URL。
|
||||
2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
|
||||
3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
|
||||
4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
|
||||
5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
|
||||
6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
|
||||
7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
|
||||
|
||||
> 上图有一个错误,请注意,是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
|
||||
|
||||
总体来说分为以下几个过程:
|
||||
|
||||
1. DNS 解析
|
||||
2. TCP 连接
|
||||
3. 发送 HTTP 请求
|
||||
4. 服务器处理请求并返回 HTTP 报文
|
||||
5. 浏览器解析渲染页面
|
||||
6. 连接结束
|
||||
|
||||
具体可以参考下面这两篇文章:
|
||||
|
||||
- [从输入 URL 到页面加载发生了什么?](https://segmentfault.com/a/1190000006879700)
|
||||
- [浏览器从输入网址到页面展示的过程](https://cloud.tencent.com/developer/article/1879758)
|
||||
详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](./the-whole-process-of-accessing-web-pages.md)(强烈推荐)。
|
||||
|
||||
### HTTP 状态码有哪些?
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,78 @@
|
|||
---
|
||||
title: 访问网页的全过程(知识串联)
|
||||
category: 计算机基础
|
||||
tag:
|
||||
- 计算机网络
|
||||
---
|
||||
|
||||
开发岗中总是会考很多计算机网络的知识点,但如果让面试官只靠一道题,便涵盖最多的计网知识点,那可能就是 **网页浏览的全过程** 了。本篇文章将带大家从头到尾过一遍这道被考烂的面试题,必会!!!
|
||||
|
||||
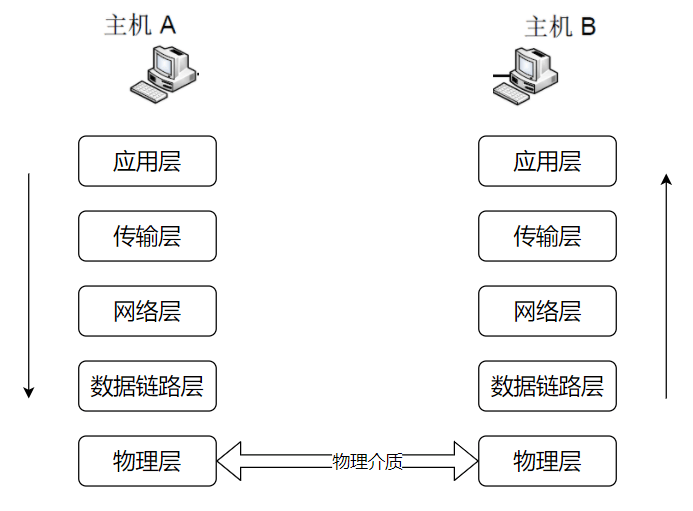
总的来说,网络通信模型可以用下图来表示,也就是大家只要熟记网络结构五层模型,按照这个体系,很多知识点都能顺出来了。访问网页的过程也是如此。
|
||||
|
||||
|
||||
|
||||
开始之前,我们先简单过一遍完整流程:
|
||||
|
||||
1. 在浏览器中输入指定网页的 URL。
|
||||
2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
|
||||
3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
|
||||
4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
|
||||
5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
|
||||
6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
|
||||
7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
|
||||
|
||||
## 应用层
|
||||
|
||||
一切的开始——打开浏览器,在地址栏输入 URL,回车确认。那么,什么是 URL?访问 URL 有什么用?
|
||||
|
||||
### URL
|
||||
|
||||
URL(Uniform Resource Locators),即统一资源定位器。网络上的所有资源都靠 URL 来定位,每一个文件就对应着一个 URL,就像是路径地址。理论上,文件资源和 URL 一一对应。实际上也有例外,比如某些 URL 指向的文件已经被重定位到另一个位置,这样就有多个 URL 指向同一个文件。
|
||||
|
||||
### URL 的组成结构
|
||||
|
||||

|
||||
|
||||
1. 协议。URL 的前缀通常表示了该网址采用了何种应用层协议,通常有两种——HTTP 和 HTTPS。当然也有一些不太常见的前缀头,比如文件传输时用到的`ftp:`。
|
||||
2. 域名。域名便是访问网址的通用名,这里也有可能是网址的 IP 地址,域名可以理解为 IP 地址的可读版本,毕竟绝大部分人都不会选择记住一个网址的 IP 地址。
|
||||
3. 端口。如果指明了访问网址的端口的话,端口会紧跟在域名后面,并用一个冒号隔开。
|
||||
4. 资源路径。域名(端口)后紧跟的就是资源路径,从第一个`/`开始,表示从服务器上根目录开始进行索引到的文件路径,上图中要访问的文件就是服务器根目录下`/path/to/myfile.html`。早先的设计是该文件通常物理存储于服务器主机上,但现在随着网络技术的进步,该文件不一定会物理存储在服务器主机上,有可能存放在云上,而文件路径也有可能是虚拟的(遵循某种规则)。
|
||||
5. 参数。参数是浏览器在向服务器提交请求时,在 URL 中附带的参数。服务器解析请求时,会提取这些参数。参数采用键值对的形式`key=value`,每一个键值对使用`&`隔开。参数的具体含义和请求操作的具体方法有关。
|
||||
6. 锚点。锚点顾名思义,是在要访问的页面上的一个锚。要访问的页面大部分都多于一页,如果指定了锚点,那么在客户端显示该网页是就会定位到锚点处,相当于一个小书签。值得一提的是,在 URL 中,锚点以`#`开头,并且**不会**作为请求的一部分发送给服务端。
|
||||
|
||||
### DNS
|
||||
|
||||
键入了 URL 之后,第一个重头戏登场——DNS 服务器解析。DNS(Domain Name System)域名系统,要解决的是 **域名和 IP 地址的映射问题** 。毕竟,域名只是一个网址便于记住的名字,而网址真正存在的地址其实是 IP 地址。
|
||||
|
||||
传送门:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html)
|
||||
|
||||
### HTTP/HTTPS
|
||||
|
||||
利用 DNS 拿到了目标主机的 IP 地址之后,浏览器便可以向目标 IP 地址发送 HTTP 报文,请求需要的资源了。在这里,根据目标网站的不同,请求报文可能是 HTTP 协议或安全性增强的 HTTPS 协议。
|
||||
|
||||
传送门:
|
||||
|
||||
- [HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html)
|
||||
- [HTTP 1.0 vs HTTP 1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html)
|
||||
|
||||
## 传输层
|
||||
|
||||
由于 HTTP 协议是基于 TCP 协议的,在应用层的数据封装好以后,要交给传输层,经 TCP 协议继续封装。
|
||||
|
||||
TCP 协议保证了数据传输的可靠性,是数据包传输的主力协议。
|
||||
|
||||
传送门:
|
||||
|
||||
- [TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html)
|
||||
- [TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
|
||||
|
||||
## 网络层
|
||||
|
||||
终于,来到网络层,此时我们的主机不再是和另一台主机进行交互了,而是在和中间系统进行交互。也就是说,应用层和传输层都是端到端的协议,而网络层及以下都是中间件的协议了。
|
||||
|
||||
**网络层的的核心功能——转发与路由**,必会!!!如果面试官问到了网络层,而你恰好又什么都不会的话,最最起码要说出这五个字——**转发与路由**。
|
||||
|
||||
- 转发:将分组从路由器的输入端口转移到合适的输出端口。
|
||||
- 路由:确定分组从源到目的经过的路径。
|
||||
|
||||
所以到目前为止,我们的数据包经过了应用层、传输层的封装,来到了网络层,终于开始准备在物理层面传输了,第一个要解决的问题就是——**往哪里传输?或者说,要把数据包发到哪个路由器上?**这便是 BGP 协议要解决的问题。
|
||||
|
|
@ -265,7 +265,7 @@ ZAB 协议包括两种基本的模式,分别是
|
|||
关于 **ZAB 协议&Paxos 算法** 需要讲和理解的东西太多了,具体可以看下面这几篇文章:
|
||||
|
||||
- [Paxos 算法详解](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)
|
||||
- [Zookeeper ZAB 协议分析](https://dbaplus.cn/news-141-1875-1.html)
|
||||
- [ZooKeeper 与 Zab 协议 · Analyze](https://wingsxdu.com/posts/database/zookeeper/)
|
||||
- [Raft 算法详解](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
|
||||
|
||||
## 总结
|
||||
|
|
|
|||
|
|
@ -66,7 +66,7 @@ icon: retry
|
|||
|
||||
重试的次数通常建议设为 3 次。大部分情况下,我们还是更建议使用梯度间隔重试策略,比如说我们要重试 3 次的话,第 1 次请求失败后,等待 1 秒再进行重试,第 2 次请求失败后,等待 2 秒再进行重试,第 3 次请求失败后,等待 3 秒再进行重试。
|
||||
|
||||
### 重试幂等
|
||||
### 什么是重试幂等?
|
||||
|
||||
超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。
|
||||
|
||||
|
|
@ -74,6 +74,10 @@ icon: retry
|
|||
|
||||
举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。
|
||||
|
||||
### Java 中如何实现重试?
|
||||
|
||||
如果要手动编写代码实现重试逻辑的话,可以通过循环(例如 while 或 for 循环)或者递归实现。不过,一般不建议自己动手实现,有很多第三方开源库提供了更完善的重试机制实现,例如 Spring Retry、Resilience4j、Guava Retrying。
|
||||
|
||||
## 参考
|
||||
|
||||
- 微服务之间调用超时的设置治理:<https://www.infoq.cn/article/eyrslar53l6hjm5yjgyx>
|
||||
|
|
|
|||
|
|
@ -55,17 +55,25 @@ SELECT * FROM t_order WHERE id >= (SELECT id FROM t_order limit 1000000, 1) LIMI
|
|||
|
||||
当然,我们也可以利用子查询先去获取目标分页的 ID 集合,然后再根据 ID 集合获取内容,但这种写法非常繁琐,不如使用 INNER JOIN 延迟关联。
|
||||
|
||||
### INNER JOIN 延迟关联
|
||||
### 延迟关联
|
||||
|
||||
延迟关联的优化思路,跟子查询的优化思路其实是一样的:都是把条件转移到主键索引树,然后减少回表。不同点是,延迟关联使用了 INNER JOIN 代替子查询。
|
||||
延迟关联的优化思路,跟子查询的优化思路其实是一样的:都是把条件转移到主键索引树,减少回表的次数。不同点是,延迟关联使用了 INNER JOIN(内连接) 包含子查询。
|
||||
|
||||
```sql
|
||||
SELECT t1.* FROM t_order t1
|
||||
INNER JOIN (SELECT id FROM t_order limit 1000000, 1) t2
|
||||
ON t1.id >= t2.id
|
||||
INNER JOIN (SELECT id FROM t_order limit 1000000, 10) t2
|
||||
ON t1.id = t2.id
|
||||
LIMIT 10;
|
||||
```
|
||||
|
||||
除了使用 INNER JOIN 之外,还可以使用逗号连接子查询。
|
||||
|
||||
```sql
|
||||
SELECT t1.* FROM t_order t1,
|
||||
(SELECT id FROM t_order limit 1000000, 10) t2
|
||||
WHERE t1.id = t2.id;
|
||||
```
|
||||
|
||||
### 覆盖索引
|
||||
|
||||
索引中已经包含了所有需要获取的字段的查询方式称为覆盖索引。
|
||||
|
|
|
|||
|
|
@ -439,10 +439,10 @@ private final Node<K,V>[] initTable() {
|
|||
}
|
||||
```
|
||||
|
||||
从源码中可以发现 `ConcurrentHashMap` 的初始化是通过**自旋和 CAS** 操作完成的。里面需要注意的是变量 `sizeCtl` ,它的值决定着当前的初始化状态。
|
||||
从源码中可以发现 `ConcurrentHashMap` 的初始化是通过**自旋和 CAS** 操作完成的。里面需要注意的是变量 `sizeCtl` (sizeControl 的缩写),它的值决定着当前的初始化状态。
|
||||
|
||||
1. -1 说明正在初始化
|
||||
2. -N 说明有 N-1 个线程正在进行扩容
|
||||
1. -1 说明正在初始化,其他线程需要自旋等待
|
||||
2. -N 说明 table 正在进行扩容,高 16 位表示扩容的标识戳,低 16 位减 1 为正在进行扩容的线程数
|
||||
3. 0 表示 table 初始化大小,如果 table 没有初始化
|
||||
4. \>0 表示 table 扩容的阈值,如果 table 已经初始化。
|
||||
|
||||
|
|
|
|||
|
|
@ -319,7 +319,7 @@ public ScheduledThreadPoolExecutor(int corePoolSize) {
|
|||
|
||||
### 线程池的饱和策略有哪些?
|
||||
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolTaskExecutor` 定义一些策略:
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolExecutor` 定义一些策略:
|
||||
|
||||
- **`ThreadPoolExecutor.AbortPolicy`:** 抛出 `RejectedExecutionException`来拒绝新任务的处理。
|
||||
- **`ThreadPoolExecutor.CallerRunsPolicy`:** 调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
|
||||
|
|
|
|||
|
|
@ -133,7 +133,7 @@ public class ScheduledThreadPoolExecutor
|
|||
|
||||
**`ThreadPoolExecutor` 饱和策略定义:**
|
||||
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolTaskExecutor` 定义一些策略:
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolExecutor` 定义一些策略:
|
||||
|
||||
- `ThreadPoolExecutor.AbortPolicy`:抛出 `RejectedExecutionException`来拒绝新任务的处理。
|
||||
- `ThreadPoolExecutor.CallerRunsPolicy`:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
|
||||
|
|
|
|||
|
|
@ -127,7 +127,7 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
|
|||
|
||||
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 S0 或者 S1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
|
||||
|
||||
> **🐛 修正(参见:[issue552](https://github.com/Snailclimb/JavaGuide/issues/552))**:“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值”。
|
||||
> **🐛 修正(参见:[issue552](https://github.com/Snailclimb/JavaGuide/issues/552))**:“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累加,当累加到某个年龄时,所累加的大小超过了 Survivor 区的一半,则取这个年龄和 `MaxTenuringThreshold` 中更小的一个值,作为新的晋升年龄阈值”。
|
||||
>
|
||||
> **动态年龄计算的代码如下**
|
||||
>
|
||||
|
|
@ -260,7 +260,7 @@ JDK1.4 中新加入的 **NIO(Non-Blocking I/O,也被称为 New I/O)**,
|
|||
|
||||
类似的概念还有 **堆外内存** 。在一些文章中将直接内存等价于堆外内存,个人觉得不是特别准确。
|
||||
|
||||
堆外内存就是把内存对象分配在堆(新生代+老年代+永久代)以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
|
||||
堆外内存就是把内存对象分配在堆外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
|
||||
|
||||
## HotSpot 虚拟机对象探秘
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue