2022-01-13 20:29:55 +08:00
|
|
|
|
---
|
2022-08-15 15:12:39 +08:00
|
|
|
|
title: 敏感词过滤方案总结
|
2022-01-13 20:29:55 +08:00
|
|
|
|
category: 系统设计
|
|
|
|
|
|
tag:
|
|
|
|
|
|
- 安全
|
|
|
|
|
|
---
|
|
|
|
|
|
|
2022-01-13 19:57:13 +08:00
|
|
|
|
系统需要对用户输入的文本进行敏感词过滤如色情、政治、暴力相关的词汇。
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
|
|
|
|
|
敏感词过滤用的使用比较多的 **Trie 树算法** 和 **DFA 算法**。
|
|
|
|
|
|
|
2022-01-13 17:57:27 +08:00
|
|
|
|
## 算法实现
|
|
|
|
|
|
|
|
|
|
|
|
### Trie 树
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2024-02-25 20:23:21 +08:00
|
|
|
|
**Trie 树** 也称为字典树、单词查找树,哈希树的一种变种,通常被用于字符串匹配,用来解决在一组字符串集合中快速查找某个字符串的问题。像浏览器搜索的关键词提示就可以基于 Trie 树来做的。
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2023-04-22 10:34:42 +08:00
|
|
|
|

|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
|
|
|
|
|
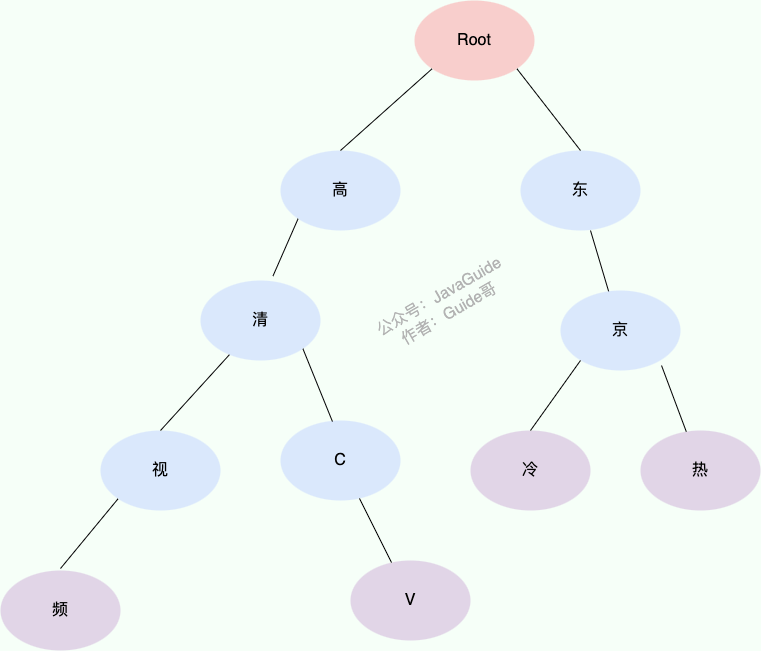
假如我们的敏感词库中有以下敏感词:
|
|
|
|
|
|
|
2023-04-21 18:51:32 +08:00
|
|
|
|
- 高清视频
|
2023-04-28 17:31:44 +08:00
|
|
|
|
- 高清 CV
|
2022-01-13 16:57:40 +08:00
|
|
|
|
- 东京冷
|
|
|
|
|
|
- 东京热
|
|
|
|
|
|
|
2022-01-13 17:57:27 +08:00
|
|
|
|
我们构造出来的敏感词 Trie 树就是下面这样的:
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2023-04-21 18:51:32 +08:00
|
|
|
|
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
|
|
|
|
|
当我们要查找对应的字符串“东京热”的话,我们会把这个字符串切割成单个的字符“东”、“京”、“热”,然后我们从 Trie 树的根节点开始匹配。
|
|
|
|
|
|
|
|
|
|
|
|
可以看出, **Trie 树的核心原理其实很简单,就是通过公共前缀来提高字符串匹配效率。**
|
|
|
|
|
|
|
2024-01-13 14:48:32 +08:00
|
|
|
|
[Apache Commons Collections](https://mvnrepository.com/artifact/org.apache.commons/commons-collections4) 这个库中就有 Trie 树实现:
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2024-01-13 14:48:32 +08:00
|
|
|
|
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
|
|
|
|
|
```java
|
|
|
|
|
|
Trie<String, String> trie = new PatriciaTrie<>();
|
|
|
|
|
|
trie.put("Abigail", "student");
|
|
|
|
|
|
trie.put("Abi", "doctor");
|
|
|
|
|
|
trie.put("Annabel", "teacher");
|
|
|
|
|
|
trie.put("Christina", "student");
|
|
|
|
|
|
trie.put("Chris", "doctor");
|
|
|
|
|
|
Assertions.assertTrue(trie.containsKey("Abigail"));
|
|
|
|
|
|
assertEquals("{Abi=doctor, Abigail=student}", trie.prefixMap("Abi").toString());
|
|
|
|
|
|
assertEquals("{Chris=doctor, Christina=student}", trie.prefixMap("Chr").toString());
|
|
|
|
|
|
```
|
|
|
|
|
|
|
2024-02-01 16:24:41 +08:00
|
|
|
|
Trie 树是一种利用空间换时间的数据结构,占用的内存会比较大。也正是因为这个原因,实际工程项目中都是使用的改进版 Trie 树例如双数组 Trie 树(Double-Array Trie,DAT)。
|
|
|
|
|
|
|
|
|
|
|
|
DAT 的设计者是日本的 Aoe Jun-ichi,Mori Akira 和 Sato Takuya,他们在 1989 年发表了一篇论文[《An Efficient Implementation of Trie Structures》](https://www.co-ding.com/assets/pdf/dat.pdf),详细介绍了 DAT 的构造和应用,原作者写的示例代码地址:<https://github.com/komiya-atsushi/darts-java/blob/e2986a55e648296cc0a6244ae4a2e457cd89fb82/src/main/java/darts/DoubleArrayTrie.java>。相比较于 Trie 树,DAT 的内存占用极低,可以达到 Trie 树内存的 1%左右。DAT 在中文分词、自然语言处理、信息检索等领域有广泛的应用,是一种非常优秀的数据结构。
|
|
|
|
|
|
|
|
|
|
|
|
### AC 自动机
|
|
|
|
|
|
|
2022-01-13 17:57:27 +08:00
|
|
|
|
Aho-Corasick(AC)自动机是一种建立在 Trie 树上的一种改进算法,是一种多模式匹配算法,由贝尔实验室的研究人员 Alfred V. Aho 和 Margaret J.Corasick 发明。
|
|
|
|
|
|
|
2024-02-01 16:24:41 +08:00
|
|
|
|
AC 自动机算法使用 Trie 树来存放模式串的前缀,通过失败匹配指针(失配指针)来处理匹配失败的跳转。关于 AC 自动机的详细介绍,可以查看这篇文章:[地铁十分钟 | AC 自动机](https://zhuanlan.zhihu.com/p/146369212)。
|
2022-01-13 17:57:27 +08:00
|
|
|
|
|
2024-02-01 16:24:41 +08:00
|
|
|
|
如果使用上面提到的 DAT 来表示 AC 自动机 ,就可以兼顾两者的优点,得到一种高效的多模式匹配算法。Github 上已经有了开源 Java 实现版本:<https://github.com/hankcs/AhoCorasickDoubleArrayTrie> 。
|
2022-01-13 17:57:27 +08:00
|
|
|
|
|
|
|
|
|
|
### DFA
|
|
|
|
|
|
|
2023-02-28 15:39:17 +08:00
|
|
|
|
**DFA**(Deterministic Finite Automata)即确定有穷自动机,与之对应的是 NFA(Non-Deterministic Finite Automata,不确定有穷自动机)。
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2022-01-13 17:57:27 +08:00
|
|
|
|
关于 DFA 的详细介绍可以看这篇文章:[有穷自动机 DFA&NFA (学习笔记) - 小蜗牛的文章 - 知乎](https://zhuanlan.zhihu.com/p/30009083) 。
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2022-01-13 17:57:27 +08:00
|
|
|
|
[Hutool](https://hutool.cn/docs/#/dfa/%E6%A6%82%E8%BF%B0) 提供了 DFA 算法的实现:
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2023-04-22 10:34:42 +08:00
|
|
|
|
|
2022-01-13 17:57:27 +08:00
|
|
|
|
|
|
|
|
|
|
```java
|
|
|
|
|
|
WordTree wordTree = new WordTree();
|
|
|
|
|
|
wordTree.addWord("大");
|
|
|
|
|
|
wordTree.addWord("大憨憨");
|
|
|
|
|
|
wordTree.addWord("憨憨");
|
|
|
|
|
|
String text = "那人真是个大憨憨!";
|
|
|
|
|
|
// 获得第一个匹配的关键字
|
|
|
|
|
|
String matchStr = wordTree.match(text);
|
|
|
|
|
|
System.out.println(matchStr);
|
|
|
|
|
|
// 标准匹配,匹配到最短关键词,并跳过已经匹配的关键词
|
|
|
|
|
|
List<String> matchStrList = wordTree.matchAll(text, -1, false, false);
|
|
|
|
|
|
System.out.println(matchStrList);
|
|
|
|
|
|
//匹配到最长关键词,跳过已经匹配的关键词
|
|
|
|
|
|
List<String> matchStrList2 = wordTree.matchAll(text, -1, false, true);
|
|
|
|
|
|
System.out.println(matchStrList2);
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
输出:
|
|
|
|
|
|
|
2023-10-10 14:43:53 +08:00
|
|
|
|
```plain
|
2022-01-13 17:57:27 +08:00
|
|
|
|
大
|
|
|
|
|
|
[大, 憨憨]
|
|
|
|
|
|
[大, 大憨憨]
|
|
|
|
|
|
```
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2022-01-13 17:57:27 +08:00
|
|
|
|
## 开源项目
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2023-05-05 12:39:01 +08:00
|
|
|
|
- [ToolGood.Words](https://github.com/toolgood/ToolGood.Words):一款高性能敏感词(非法词/脏字)检测过滤组件,附带繁体简体互换,支持全角半角互换,汉字转拼音,模糊搜索等功能。
|
|
|
|
|
|
- [sensitive-words-filter](https://github.com/hooj0/sensitive-words-filter):敏感词过滤项目,提供 TTMP、DFA、DAT、hash bucket、Tire 算法支持过滤。可以支持文本的高亮、过滤、判词、替换的接口支持。
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2022-01-13 17:57:27 +08:00
|
|
|
|
## 论文
|
2022-01-13 16:57:40 +08:00
|
|
|
|
|
2022-01-13 17:57:27 +08:00
|
|
|
|
- [一种敏感词自动过滤管理系统](https://patents.google.com/patent/CN101964000B)
|
2023-02-28 15:39:17 +08:00
|
|
|
|
- [一种网络游戏中敏感词过滤方法及系统](https://patents.google.com/patent/CN103714160A/zh)
|
2023-08-07 18:56:33 +08:00
|
|
|
|
|
2023-10-27 06:44:02 +08:00
|
|
|
|
<!-- @include: @article-footer.snippet.md -->
|